




drjUnraid
Members
-
Joined
-
Last visited
-
I think I might take on this same build. Anything either of you would do differently?
-
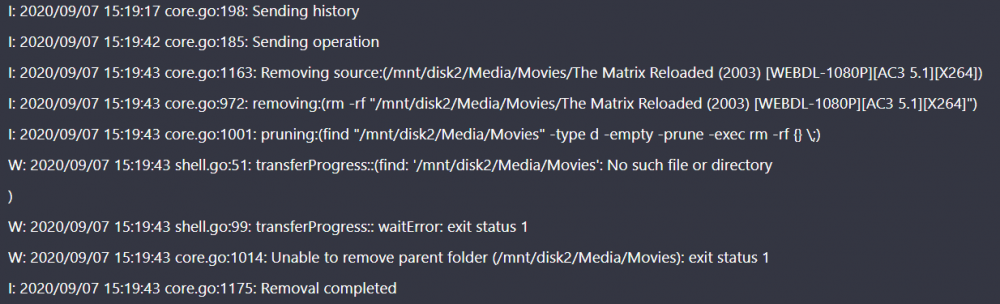
Thanks for the plugin, very cool. I just did a gather operation moving 714 folders and 7TB and ended up with 216 moves that resulted in "rmsrc button" appearing. I did have to do the docker safer permissions before I started. I show a log snippet below. Couple questions: Is it normal to get that many; anything I can do to minimize it? I basically moved all my data to disk 4. When I go and look for the data that genererated the "RSMC" I do not see it the original on Disk1, 2, or 3 anymore. Is there a chance it really did delete the source file already? Do I still need to click the RSMC button? Is there a faster way to click the RSMC button? Currently I go to the History tab of UnBalance, scroll down to find "RSMC", click it, then the webpage reloads. Navigate back to History tab, scroll down to find the next RSMC, click it. Rinse and repeat. Lost of clicking and scrolling. Here is a an example of an RSMC generated for Guardians of the Galaxy in the unbalance log. It processes the file then moves on to the next one: However about 1000 lines (and 4 hours) later in the log I get this entry: Edit: I see in the screen shots the 2nd failed operation is referencing Disk2, vs Disk1 in the first operation. Edit2: When I do click the RSMC button it seems to be confirming that the data was in fact deleted?


-
I was able to solve this. 1st we repaired the XFS file system. Use Space Invaders XFS guide. Had to use -L while repairing. Then I tried to mount Disk 4, but it did not want to mount. So I added a new disk and rebuilt disk 4 using the parity and new disk.
-
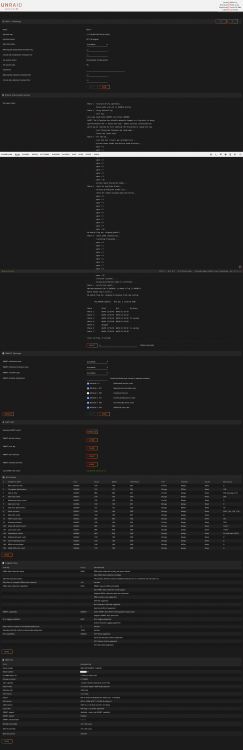
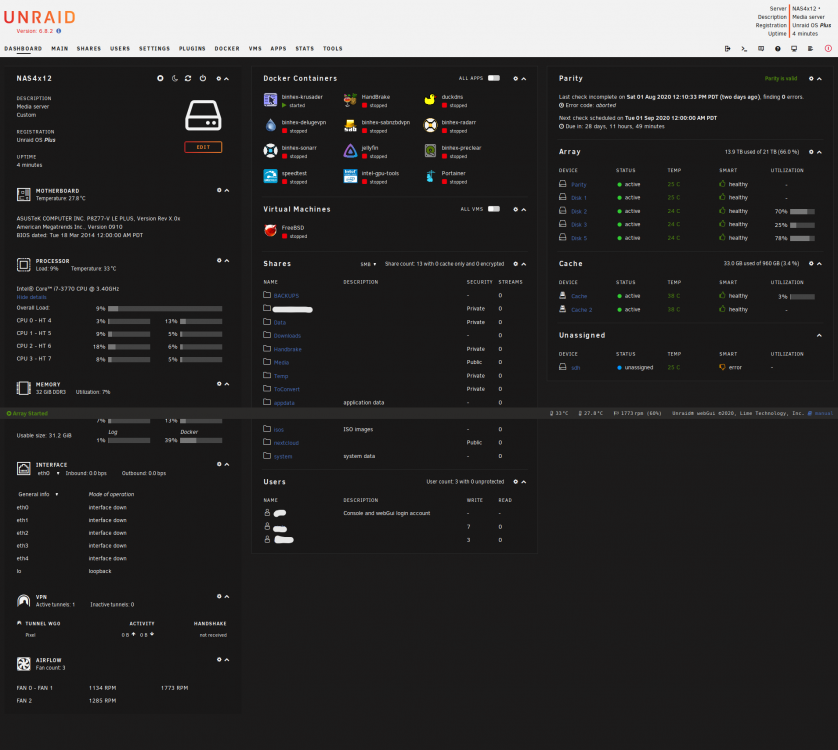
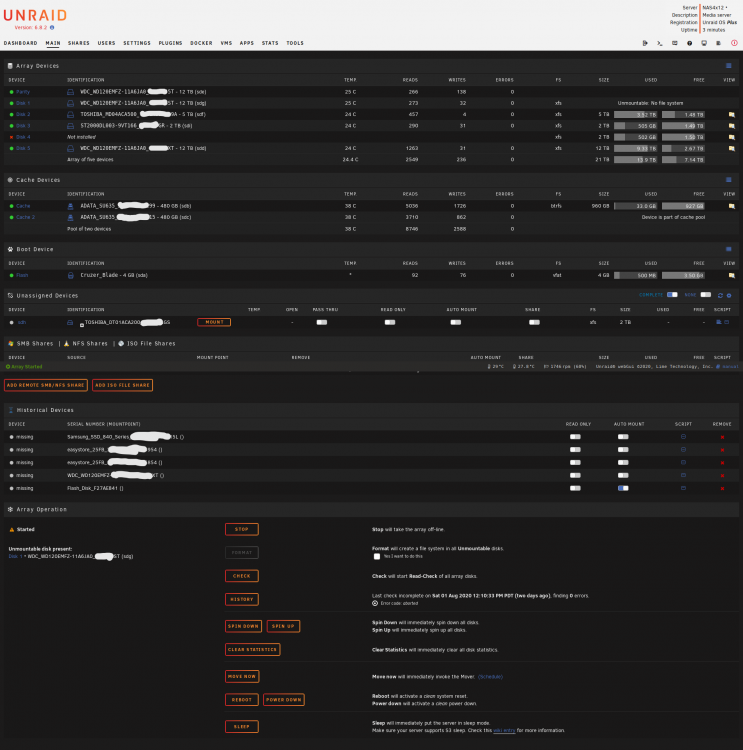
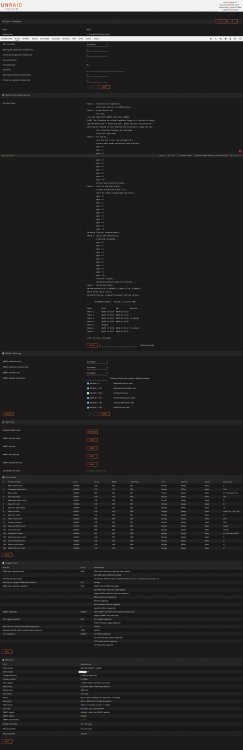
@trurl et all I redid all the screen shots here. Disk1 FileSystem Check is shown attached. (Screenshot_2020-08-03 NAS4x12 Device.png) The main and Dashboard screens are also captured. Before this boot I swapped the power cords and data cords for Disk 1 with another disk. I think I still heard the spindown/reset. It didn't change the file structure error status. Included latest diagnostic dump. I have additional 12TB HD's I can swap in if needed when it comes to recovery. nas4x12-diagnostics-20200803-1303Stop_Restart_MovedDisk1PowerAndDataCable.zip
-
@trurl and Unraiders: I got the a new SATA card installed. I can see Disk4 in the unassigned devices now, its the Toshiba 2TB drive. (I also figured out how to save screen shots in the console GUI to the unRaid flash drive). That made me realize that the log file I "thought" I saved was not correct as you suspected. I uploaded a new one to the OP and repeated it here as well. I booted, stoped array, did some check disk, started array in maintence mode, checked Disk1 XFS File System Repair "-nv" then I restarted the array and took the diagnostic. Not sure which problem to tackle first, Disk 4 or Disk 1. I notice that I can hear Disk1 clicking, like its resetting or spinning down abruptly. I changed the SATA data cable and switched to a different Sata Port on the Motherboard, but it didn't change the clicking/resetting sound. Thanks! nas4x12-diagnostics-20200802-2320_Stop_RestartArray.zip
-
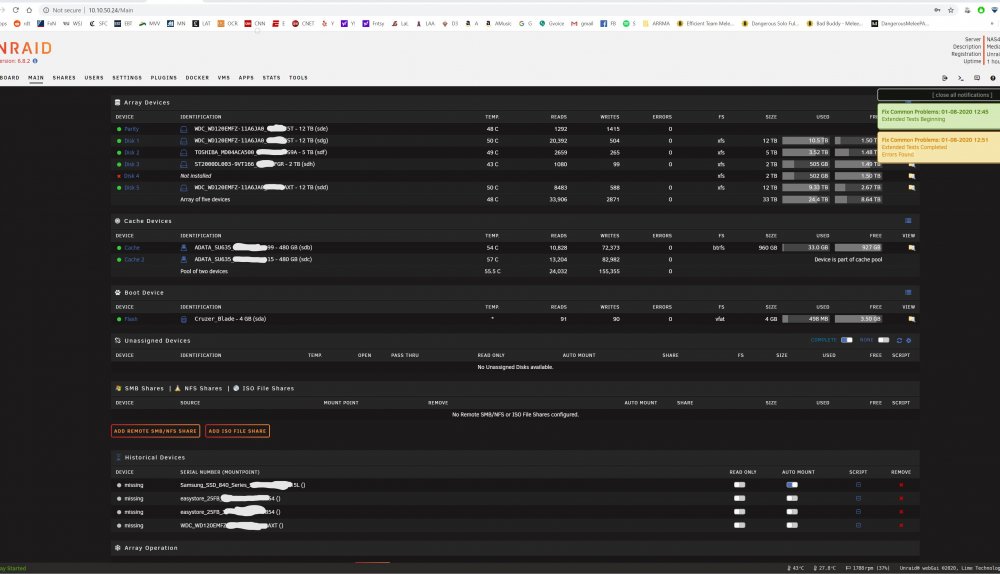
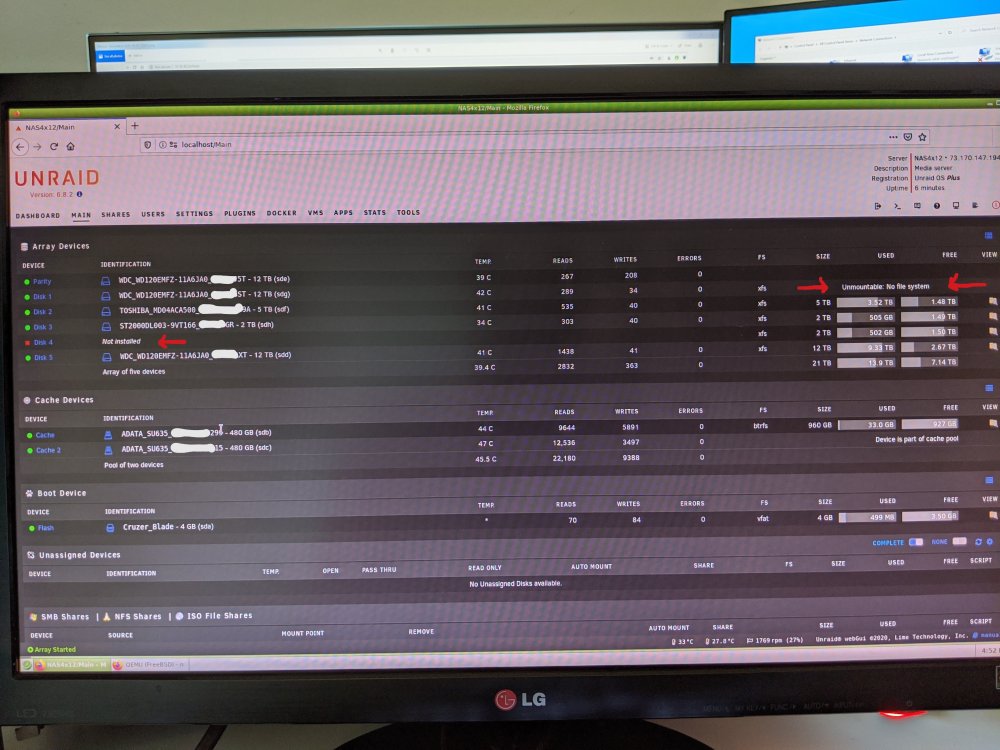
Sorry for photos. I lost the net login and had to plug in a monitor and keyboard to the server. Then take photos with my camera to post to forum. I'll do screen shots whenever possible. Thanks for the reply. The array size is much smaller now that it says Disk 1 is unmountable. Any advice on the order to try and recover my systems disks 4 and disk 1.
-
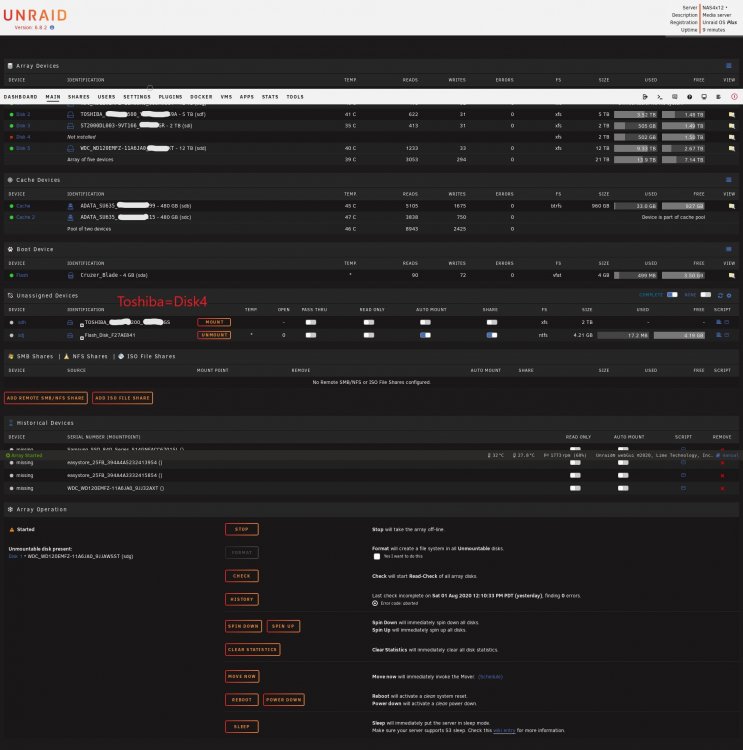
Hi All, I have an issue with my Unraid 6.8.2. I think its two issues that happened back to back. I hope I'm not screwed. Apologies for photos, lost my net connection and had to go log into unraid local GUI. After a server reboot my Disk 4 disappeared and came up as "Not Installed". I have a 4 port Sata 3 PCIE Card that uses a Marvell controller and it has issues occasionally being detected by Unraid. In the past I added "iommu=pt" in my syslinux and it fixed it mostly, but occasionally after a reboot it does still disappear and show as Not Installed. I decided to clean shut down my server again to see if Disk 4 will come back. Power back up After the reboot it takes forever to boot when I'm able to log in using the GUI Console I see a new Issue: Disk 1 says it's "Unmountable: No File System". It's giving me an option to Format it, which I don't believe I want to do. I stopped the array and clicked on Disk 1 and did a Files System Check "-nv", but not a repair. At this point I am stuck with my knowledge and need Google/Help. So thats the background, I've attached my diagnostic file, after all the reboots (sorry for that). I'd like to recover my data and array if possible. I've ordered a different SATA3 PCI card that uses a ASMEDIA chip, so hopefully that resolves the Disk 4 issue. How about disk 1 loss of file system? Can I get Disk 1 back? Is there a certain order I should try and recover my system? I'm about to embark on my own searching exercise. Thanks in advance. Edit1_20200802: I got a new Sata PCIe card and now Disk 4 is detected in Unassigned Devices. I uploaded a new Diagnostic as I realized my other one was not current. nas4x12-diagnostics-20200802-2320_Stop_RestartArray.zip
-
Yeah I read thru it again but that is mostly for nvidia gpu based transcode. Intel iGPU isn't covered in detail. I've tried installing intel-gpu-tools app but it just crashes when I launch it. Need to research more. My cpu is not best for iGPU anyway since its 3rd gen.
-
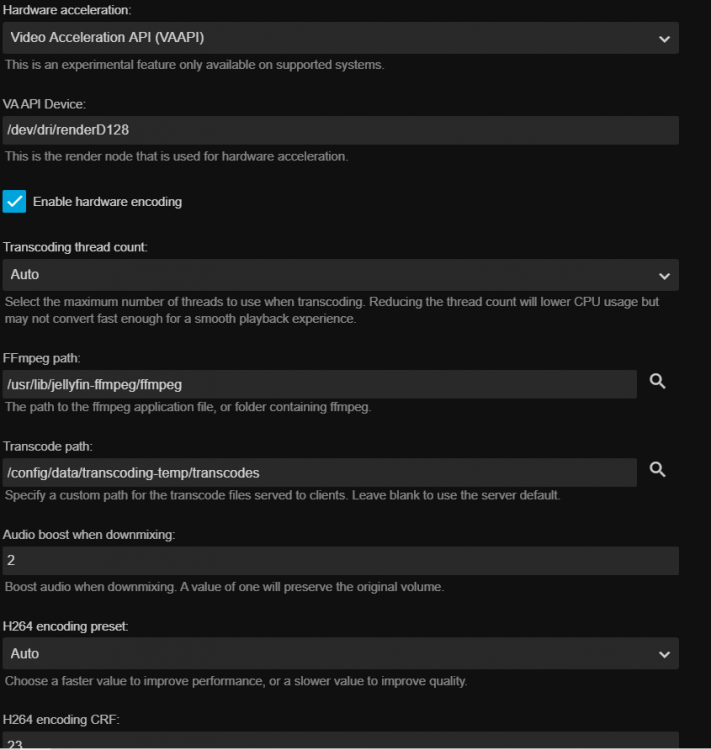
Is there a way to verify the iGPU is doing the transcoding? I adde "modprobe i915" to my go file and "--device=/dev/dri" to extra parameters. I've chosen VAPI and enabled, but it seems slow/buffery/etc.
-
Does the binhex version have the intel GPU support built in yet? Or is that still a linuxserver special?
-
I'm on latest release 6.8 using two ADATA SU635 480GB 3D-NAND SATA SSD's in a BTRFS pool and I also have this issue. i just built my server and read to avoid the Samsung Disks but seems I also get it with the Adata disk. Will try with COW/checksums disabled as @johnnie.black mentioned. nas4x12-diagnostics-20200102-1903.zip
-
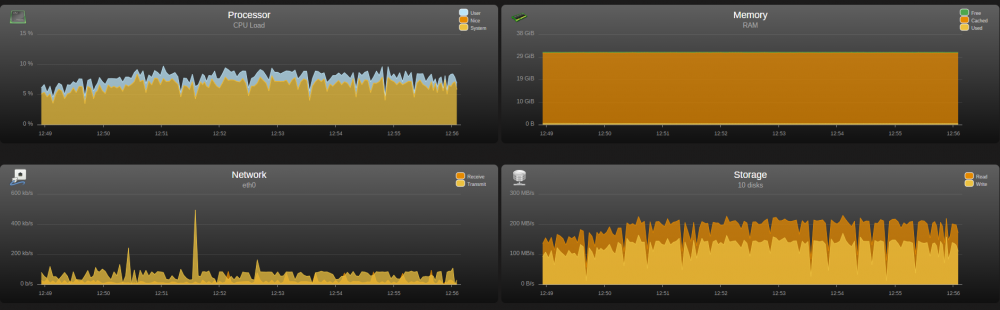
Yeah its attached to a USB3 slot. The USB external drive disk consistently got ~180Mbps on the same port under windows. Makes me think something is up with my setup.
.png.c813a1adea586cbf961cce2967e5f5d7.png)
-
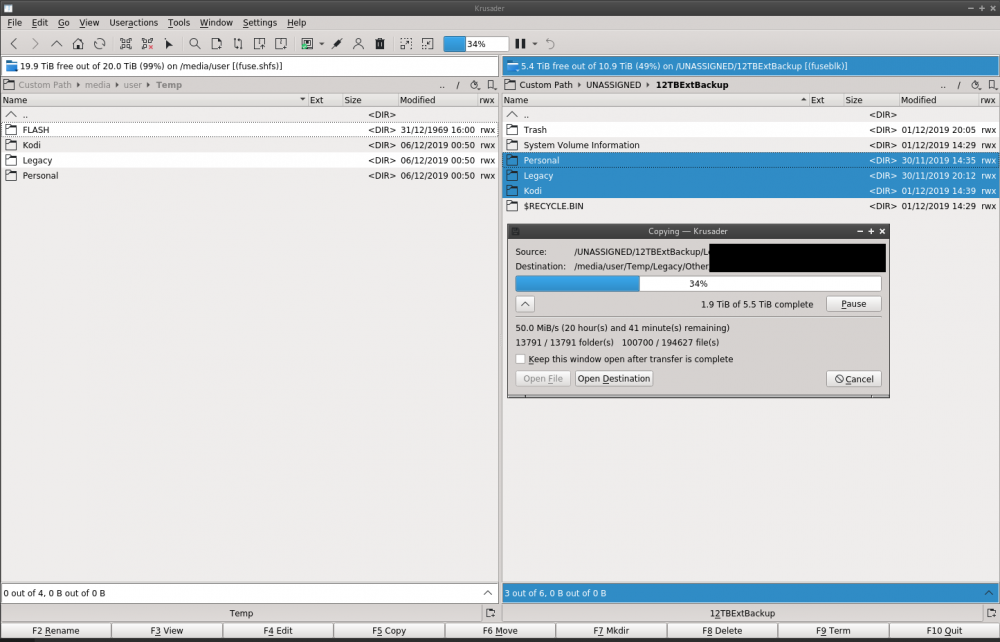
Noob here, I've done some reading but still not sure. What kind of speed should expect when copying data into my array from a USB external drive? When i built my ~20TB array it took about 30 hours and saw speeds from 100MB/s-200Mb/s. Copying data from the USB drive to the Array is about 40MB/s. Is this normal or have I screwed something up? Guess I thought it would be faster since each drive by itself is 100MB-200MB/s using Crystal Disk Mark in windows. Thanks in advance. nas4x12-diagnostics-20191206-2026.zip

-
What is the difference between binhex krusader vs krusader? https://forums.unraid.net/topic/71764-support-binhex-krusader/page/18/











.png.c813a1adea586cbf961cce2967e5f5d7.png)


