




Geck0
Members
-
Joined
-
Last visited
Everything posted by Geck0
-
Thanks JorgeB!
-
And yet, I've been using Ironwolf Pro for several years and I've returned at least 5. I've got some that have made it to the 6 year mark. As we I write this, my 18TB Ironwolf Pro has rising re-allocated sector count, its up to 113 at the moment. A 6 year old 14TB has been knocked off line, so dealing with both of those at the moment. I've also had DOAs from Amazon. I wanted to buy Toshiba Enterprise, here in Australia. They okay priced, but their return policy seems like it will come back to bite me. I've just received two 24 TB Ironwolf Pros this morning. They're larger than parity and I've got the faulty two drives in the Array. What could go wrong sticking those in?😂
-
I've recently moved and still unpacking. Turns out my BIOS battery is dead. Also turns out that an idiot decided that its best placed under the heatsinks of the motherboard. Its a complete removal of the motherboard to get to it for a replacement. So, I have to set up the bios each time I down the server. On top of this, one of my array's drives has gone offline and a second is reporting reallocated sectors, slowing increasing over the last few months. I can still access the offline drive fine. I'm backing it up at the moment. The server was unresponsive this morning, whilst doing the last backup. I think the C-state power setting in the bios was the culprit (owing to the bios resetting). However, I've come across this message below in the logs and I'm not quite sure what to do with it. Yes, I'm aware there are instructions, which may not be suitable in every case, I would rather ask. Apr 2 20:16:24 Nexus kernel: mdcmd (31): set md_num_stripes 1280 Apr 2 20:16:24 Nexus kernel: mdcmd (32): set md_queue_limit 80 Apr 2 20:16:24 Nexus kernel: mdcmd (33): set md_sync_limit 5 Apr 2 20:16:24 Nexus kernel: mdcmd (34): set md_write_method Apr 2 20:16:24 Nexus kernel: mdcmd (35): start STOPPED Apr 2 20:16:24 Nexus kernel: unraid: allocating 36230K for 1280 stripes (7 disks) Apr 2 20:16:24 Nexus kernel: md1p1: running, size: 17578328012 blocks Apr 2 20:16:24 Nexus kernel: md2p1: running, size: 5860522532 blocks Apr 2 20:16:24 Nexus kernel: md3p1: running, size: 13672382412 blocks Apr 2 20:16:24 Nexus kernel: md4p1: running, size: 13672382412 blocks Apr 2 20:16:24 Nexus kernel: md5p1: running, size: 17578328012 blocks Apr 2 20:16:24 Nexus emhttpd: shcmd (75): udevadm settle Apr 2 20:16:24 Nexus emhttpd: shcmd (81): xfs_admin -U generate /dev/md4p1 Apr 2 20:16:24 Nexus root: ERROR: The filesystem has valuable metadata changes in a log which needs to Apr 2 20:16:24 Nexus root: be replayed. Mount the filesystem to replay the log, and unmount it before Apr 2 20:16:24 Nexus root: re-running xfs_admin. If the filesystem is a snapshot of a mounted filesystem, Apr 2 20:16:24 Nexus root: you may need to give mount the nouuid option. If you are unable to mount Apr 2 20:16:24 Nexus root: the filesystem, then use the xfs_repair -L option to destroy the log and Apr 2 20:16:24 Nexus root: attempt a repair. Note that destroying the log may cause corruption -- I've received two Ironwolf 24TB drives today. Which are larger than my current drives. My intention is to: preclear both drives, whilst I re-add the offline drive (I think it could be a loose cable issue that seems to be okay). Hopefully, rebuilding this drive will be okay. Then replace the 20TB parity drive with a new 24TB drive. Use the 20TB to replace the offline drive. Add a new 24TB to replace the drive with re-allocated sector issues. Because of the size of the replacement drives, I cannot think of another way to do this. Unfortunately, drives are in such short supply in Australia, I was lucky to get these. However, I really need to know what to do with the file system xfs_admin issue? I don't want to start issuing these commands if there is a risk of further damage, especially when my drives are looking unreliable. Help appreciated. Diagnostics attached. I recognise its Easter, but help always appreciated. nexus-diagnostics-20260402-2114.zip
-
I'm based in Australia and buy from Amazon. The local suppliers don't understand customer service or warranty. Amazon will take faulty products back and hammer a supplier that doesn't honour warranty.
-
I posted an image on where it is, but it contained some info that shouldn't be public. Go to Admin / Settings / Office......Scroll down and you'll see the WOPI setting. The allow list should include the ip address of the collabora server, in my case its the unRaid server, as I haven't specified a separate address for the docker. Not a security setting per se', but you could also create groups in Nextcloud, assign users that should be able to use Collabora into that group and then assign the group on the same page, using the "restrict usage to specific groups" option. I suggest you google Nextcloud Collabora setup, there are settings you can add for Collabora. Collabora has a specific page help page for Nextcloud integration.
-
Edit the container, select "Advanced View" on the top right hand side, scroll down to "privileged" and turn it off with the slider button.
-
There's the Collabora code instance from Collabora under the docker hub app install. I actually use the one you're trying to avoid using, my logs don't suggest there is anything wrong with it. I've used it for quite a while. But, you must be prepared to read the documentation. There's a couple of different ways to set it up, I haven't used unRaid's subnet, I gave it an ip address and reverse proxied it. But, I've tied it down for only Nextcloud to communicate with it.
-
Then, in an effort to be kind, I would suggest you don't open anything up to the internet until you have more experience.
-
Go to the App section of unRaid, type in Collabora Code and then click to search in Docker Hub. Use the official version from Collabora. Read Collabora security setup thoroughly, or you're going to expose your documents to the cloud.
-
Try removing the Theming App, under Apps / Customization. Restart your docker afterwards. Don't bother rebooting your server, it won't change anything, I'm still running 31.0.5-ls380, so I can't test it. Report back if the issue persists. I think something to take onboard, you don't need to upgrade everytime there is a release. Its not going to give your Nextcloud instance super powers. Unless its a bug fix, its likely to introduce an issue you didn't have before, ie. you were likely happier with your Nextcloud server before the upgrade.
-
Go to Google and type "linixserver.io nextcloud" it will take you to the repository for linuxserver.io. Look for the latest version that you want abd copy abd paste the label into the dockers edit section. Ie. Copy andd paste the title (lable) of the version, as per the image Ive attached. It would have been useful for you to copy and paste what you have in your dockers edit section, as its likely a pull issue with what you've edited. You may not want the latest version anyway, if you read above, two guys are reporting a problem.
-
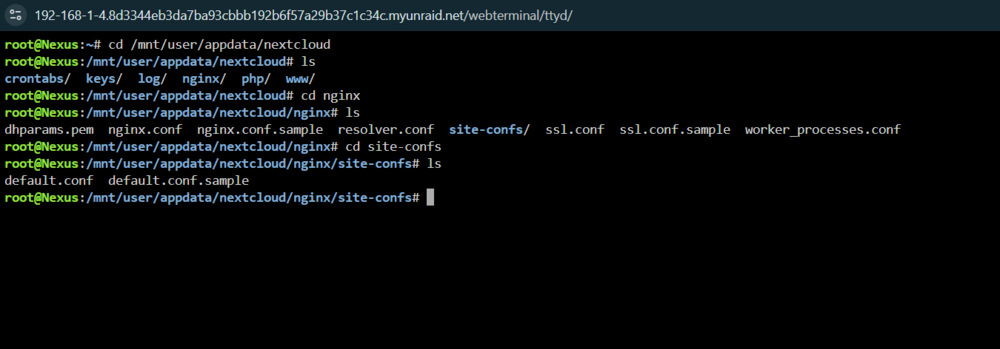
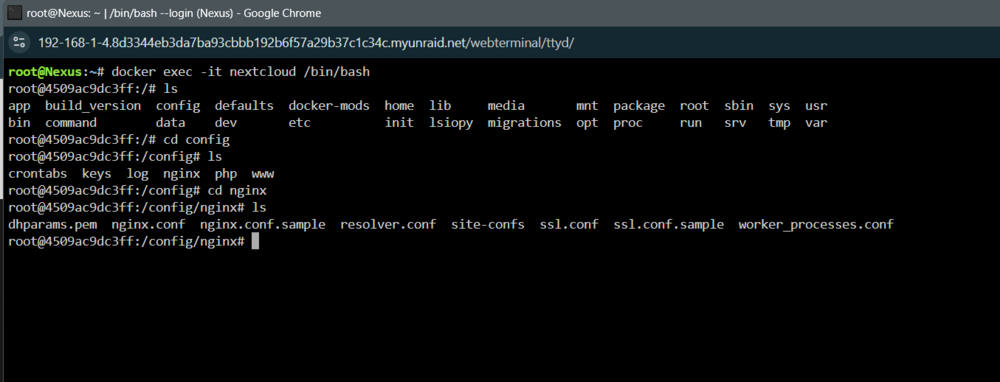
You can access it through your Nextcloud's appdata. The files that need adjusting are "default.conf" and "nginx.conf". I generally leave default.conf alone and adjust nginx.conf, in fact I haven't adjusted mine in years. When you upgrade Nextcloud, it will keep those files, your config.php file, etc. Its linked to its actual location inside Nextcloud's docker: But, you don't need to go into the docker itself. Since moving to opnSense (a few years ago), I set the majority of these settings in there. I suggest reading up on the different settings. There are some good books on ngxinx if you have a look online. I'm not an expert and used to know a lot more, but I've moved onto other thing. Again, I would recommend you introduce a reverse proxy into your eco-system, where ACME SSL can do the work for you for your certs and the nginx reverse proxy can manage your settings for Nextcloud and other hosted websites. It can also use different reverse proxy instead, like Traefik. Its more secure than doing a port forward, etc. In a port forward situation, your Nextcloud server can be exposed to a DDoS attack, which may affect your ability to manage your unRaid server. You would have to crash it to regain control. Although, I think in your message to me, you said you were using CloudFlare which will more than likely protect you from it. Anyway, moving on, hope that helps. You're going to have to do a lot of Googling and reading on nginx syntax, etc. if you want to do this properly. (Edit) I just saw your DM that you use Swag, ignore opnSense comments, although I still think its best to have a reverse proxy to the internet on a different machine, for several reasons. If you're using Swag, you can put those settings into Swag for SSL and Nextcloud and let it handle it. Nextcloud <-----------HTTP<---------Swag (SSL and Nextcloud protocols)<----------HTTPS<--------CLOUD Thats what I would do anyway. (Don't ask me about Swag, its popular, but I haven't implemented it. If I did, it would be for internal resolution).
-
These are set in your nginx conf settings. Ideally, you should be running a reverse proxy. In which case set them there, instead of in the nginx.conf file. You'll find them easy to set if you're using opnSense as the revese proxy, as it can be done in the GUI.
-
This is unrelated to Nextcloud, but its clearly a DNS issue. I'll try to give some basic help, but there's a change in your network's DNS. When you say you tried to accesss Duck outside of the network, was this with your phone or your laptop Maybe move this to unRaid's Networking section. NC is impacted by this, but its not related to it. Message me afterwards and I'll try to respond. You're also missing out on help from people that are network strong but don't use NC.
-
Ive never used DUCKDNS, but they do support CNAME. There's plenty of videos on how to set up a CNAME. DUCKDNS would have some decent FAQ. Its beyond the scope of this thread. Make sure you have a decent firewall, like opnSense, with nginx reverse proxy (it does support others). Pihole is not meant for this. I think there is a lot you need to read up on. DNS Firewalling Reverse proxy ACME SSL (also supported in opnSense). Happy reading.
-
VMs as my daily driver, Linux and SteamOS gaming (for my daughter). Game dockers Local and remote use: Network storage running NextCloud. Jellyfin with remote streaming access. PiHole Torrenting Backup server List goes onYou cant access NC apps, like Tasks through the Desktop app. Its likely you're still being rejected because the nginx conf files are set up for SSL. Post your log file after you try again. The way you're trying to use it is not ideal though. For the sake of a few dollars per year, I'd suggest a domain name., although it needs to sit behind a good reversenproxy, like opnSense.Use a domain name. Use your reverse proxy to handle the certificates. So, web --> reverse proxy (http). Reverse proxy---> Unraid (http). Get that right first, before taking next steps. Sorry for the shortness of this, I'll reply again later.Just a thought. Post your config.php, Im wondering if brute force settings are causing the problem.Neither have I, but as a matter of process, I never authorise the app with the web interface, I always use a device ID..As Kilrah said, this is the wrong support thread. This thread is for LinuxServer's version, which uses nginx. I've not heard of this repository. Nextcloud have their own official docker and Linuxserver's repository makes all the options you need for a stable version available to you. I would consider changing to Linuxserver.io's version.Use the username and password to login to the web interface. Set up device passwords for devices, so you don't have to re-enter them.Sorry for the delay. That's the only one for IOMMU.Hi Gnix, Basically, I have this setup below. I think your problem is likely your BIOS version. The BIOS upgrades are mainly to resolve security flaws, but its possible that F39 broke your IOMMU. Can you post the IOMMU settings? Aorus Extreme X570 v1.1 Bios: F36D PCIe Slots x16 - Graphics Card RTX 3090 X8 - Empty X4 - LSI sits in this slot. m2 slots All three slots are used. LSI - I can't remember exactly the model, but it was ordered with IT mode already set. I'll look it up when I get a chance. BIOS settings See the beginning of this post I did on RTX 3090 passthrough, the beginning will tell you the settings that I did in the BIOS. The only difference I've just made this week, was to change to UEFI boot mode. But, my bifurcation is set to auto as well. So, I doubt its a bifurcation issue causing the problem.









