




RecycledBits
Members
-
Joined
-
Last visited
-
Is there anybody who has considered adding Audionet's Upload Assistant ( https://github.com/Audionut/Upload-Assistant ) to the list of dockers available in the Unraid GUI? Br,
-
I am currently using the PiKVM, but I will be changing to this one instead : https://www.blicube.com/blikvm-pcie/ for my unraid servers. The PiKVM works great, but I prefer to have the IPMI functionality inside the server instead of an external box.
-
Upgraded two servers from 6.9.2 to 6.10.0 - no problems so far.
-
I purchased a used nVidia P2000 GPU for my server to transcode 4K material. It works perfectly and really reduce the CPU usage. It handles everything I throw after it.
-
Is that something new? I have personally never experienced this with Seagate. They have always honored the 5 years warranty and I always just choose the cheapest supplier here in Denmark. The only time I have experienced something simular was with WD drives. It was impossible to see from the model number and it came as a very big surprise for me that the drive only came with 1 year warranty (and died after 1½ year). This was around the WD Red SMR scandal and I haven't purchased WD since.
-
For me it is mostly either Seagate Exos 18TB or Toshiba MG09 18TB Series of hard drives. Here in Europe they are priced very similar and they both comes with 5 years warranty. I prefer these larger drives for the same reasons as you and would like to add power consumption. Larger capacity = Less drives = Less hardware (HD's, HBA's, Cabinets etc) = Smaller electrical bill.
-
I have ~60 harddrives with 24 of them being 8TB Seagate Archive drives that is using SMR technology. They are all 8 years old and not a single one of them have failed so far, so I do not think SMR have a general failure problem. These Archive drives are actually the oldest drives I have. The rest of the drives is a mix of Western Digital Red, Seagate Ironwolf and Exos ranging from 8 to 18TB. I have had failures in all of these series of drives. but nothing out of the ordinary. In general I consider all of them quite stable. But it is a small sample size. Would be interesting to see some larger statistics on this.
-
You are right. I have no need for the 64GB in my server. The maximum I have used was around 32GB with alot of VM's running. The normal is closer to 16GB with both PLEX and a Windows 10 VM running. The only reason why I have it, is that I got a good deal on a used motherboard/CPU/RAM combo, that was too good to pass. Since it was ECC RAM I could not really use it in any of my other machines.
-
64GB I currently use aprox. 16GB with a couple of VM's and a few Dockers running.
-
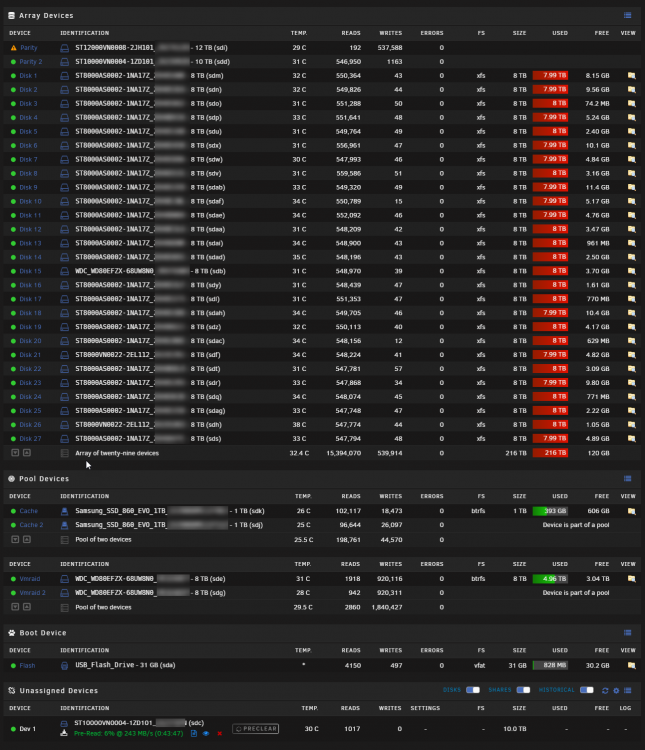
I got 24 8TB SMR drives for free some years back and began searching for a system that could handle them - and UNRAID was the answer. It was perfect for the role as NAS and media server here in my home. Compared to my existing NAS units I saved a lot of energi and wear on the drives because UNRAID only needed to spin up one drive and not 12 drives like on my existing NAS units. Since the start, I have upgraded motherboard, CPU, memory, HBA's and added both stronger GPU for Plex transcoding and added an external storage cabinet, but the SMR drives are still in there. The system currently runs on a ASUS ROG STRIX X399-E GAMING motherboard with a AMD Ryzen Threadripper 1920X 12-Core CPU with 64GB RAM. The GPU is a NVIDIA Quadro P2000 and the HBA's are LSI 9205-8e and LSI 9211-8i together with an HP expander. For cabinet I use an old Norco RPC-4020 and the external is an NetApp DS4246 (Cooling is terrible in the old Norco, so most drives are moved to the NetApp). I really hope we get support for extra array's soon, so I can migrate all data from my two Synology boxes as well. Besides this little setup I have approx- 160TB in each of the Synology 2412+ NAS units.

-
I have moved some existing 8-10TB disks from an old 8 bay USB cabinet (USB stuff disabled) to a NetApp DS4246 with two IOM. In the old cabinet the disks were connected to a LSI SAS 9207-8e card (in IT mode) using two Mini SAS to SATA cables and that has worked very stable for the last year. I connected the NetApp enclosure with a Mini SAS to QSFP cable from 10GTek ( QSFP to MiniSAS DDR Cable, 2 Metre 6.5ft: Amazon.de: Computer & Accessories ). After moving the disks I turned on the NetApp disk shelve and waited a few minutes. All lights are green on the back and the drives are turned on. No faults seem to be reported. - But the disks are not visible neither in the LSI BIOS and therefore neither in UNRAID. Is there anybody that has any hints to what the problem might be or what I can try out? Already tried: Changing the QSFP cable. Switching the IOM6 around. EDIT: It turned out to be an old firmware on the HBA and upgrading it solved the issues. The upgrade process however was a nightmare since it was a HP H221 variant, so I had to locate an old LSI firmware update program that allowed flashing of HP cards. During the update it came with an error. The error was about missing BIOS support for some DOS call, so had to use the UEFI version. Then it said something about the card being the wrong type - back to Google that kindly told me HP apparently sold two different cards under the same name, so my HBA wasn't a 9207-8e, but instead a 9205-8e. After locating that firmware it finally worked.
-
Is there anybody that recognizes this error? 2020-05-03 23:25:05,587 DEBG 'watchdog-script' stderr output: PHP Notice: Undefined index: name in /usr/share/webapps/rutorrent/plugins/_task/task.php on line 325 PHP Notice: Undefined index: requester in /usr/share/webapps/rutorrent/plugins/_task/task.php on line 326 It came after I cancelled a creation of a torrent. Rutorrent died and could not start afterwards. Each time I try to access the web interface it comes up with this error: 2020/05/03 23:31:42 [error] 1567#1567: *1 FastCGI sent in stderr: "PHP message: PHP Notice: Undefined index: name in /usr/share/webapps/rutorrent/plugins/_task/task.php on line 325PHP message: PHP Notice: Undefined index: requester in /usr/share/webapps/rutorrent/plugins/_task/task.php on line 326PHP message: PHP Notice: Undefined index: name in 2020/05/03 23:31:42 [error] 1567#1567: *1 upstream sent too big header while reading response header from upstream, client: 10.0.11.23, server: localhost, request: "GET /php/getplugins.php HTTP/1.1", upstream: "fastcgi://127.0.0.1:7777", host: "10.0.11.205:9080", referrer: "http://10.0.11.205:9080/" **** EDIT **** I played around a bit and removed everything from the catalog /binhex-rtorrentvpn/rutorrent/share/users/admin/settings/tasks/ under APPDATA It was filled with directories with names such as 15885367825eaf25ce088530.58325658 that looks like temporary directories for tasks with e.g. the created .torrent files, result files etc. After removing it all the web interface worked again.


