HALPtech
Members
-
Joined
Everything posted by HALPtech
-
For anyone who stumbles upon this topic - changing the ethernet cable (assuming it was faulty) and disabling network bonding (I only have one interface) seems to have done the trick. I'll update if I notice it happening again.
-
I've been experiencing some issues with my Unraid rig losing its network connection every so often. It happens briefly, and when it does, I usually can't connect to the web interface and any streaming freezes until it comes back up. Note: I've noticed this only happens when an application on it is being actively used. It doesn't happen overnight when everything is quiet. Here are the relevant logs (with diagnostics attached) - I'm not sure what promiscuous mode is, but I can see that something is happening to my network device (eth0) during these times: Jul 22 08:00:29 unraid kernel: device eth0 left promiscuous mode Jul 22 08:00:29 unraid kernel: bond0: now running without any active interface! Jul 22 08:00:29 unraid kernel: br0: port 1(bond0) entered disabled state Jul 22 08:00:32 unraid ntpd[1770]: Deleting interface #228 br0, 192.168.121.12#123, interface stats: received=9, sent=9, dropped=0, active_time=56 secs Jul 22 08:00:32 unraid ntpd[1770]: 216.239.35.0 local addr 192.168.121.12 -> <null> Jul 22 08:00:32 unraid ntpd[1770]: 216.239.35.4 local addr 192.168.121.12 -> <null> Jul 22 08:00:32 unraid ntpd[1770]: 216.239.35.8 local addr 192.168.121.12 -> <null> Jul 22 08:00:32 unraid ntpd[1770]: 216.239.35.12 local addr 192.168.121.12 -> <null> Jul 22 08:00:44 unraid kernel: r8169 0000:04:00.0 eth0: Link is Up - 100Mbps/Full - flow control rx/tx Jul 22 08:00:44 unraid kernel: bond0: (slave eth0): link status definitely up, 100 Mbps full duplex Jul 22 08:00:44 unraid kernel: bond0: (slave eth0): making interface the new active one Jul 22 08:00:44 unraid kernel: device eth0 entered promiscuous mode Jul 22 08:00:44 unraid kernel: bond0: active interface up! Jul 22 08:00:44 unraid kernel: br0: port 1(bond0) entered blocking state Jul 22 08:00:44 unraid kernel: br0: port 1(bond0) entered forwarding state Jul 22 08:00:46 unraid ntpd[1770]: Listen normally on 229 br0 192.168.121.12:123 Jul 22 08:00:46 unraid ntpd[1770]: new interface(s) found: waking up resolver Jul 22 08:07:04 unraid emhttpd: read SMART /dev/sdf Jul 22 08:07:14 unraid emhttpd: read SMART /dev/sdd Jul 22 08:07:14 unraid emhttpd: read SMART /dev/sdc Jul 22 08:13:22 unraid kernel: r8169 0000:04:00.0 eth0: Link is Down Jul 22 08:13:22 unraid kernel: bond0: (slave eth0): link status definitely down, disabling slave Jul 22 08:13:22 unraid kernel: device eth0 left promiscuous mode Jul 22 08:13:22 unraid kernel: bond0: now running without any active interface! Jul 22 08:13:22 unraid kernel: br0: port 1(bond0) entered disabled state Jul 22 08:13:25 unraid ntpd[1770]: Deleting interface #229 br0, 192.168.121.12#123, interface stats: received=28, sent=28, dropped=0, active_time=759 secs Jul 22 08:13:25 unraid ntpd[1770]: 216.239.35.0 local addr 192.168.121.12 -> <null> Jul 22 08:13:25 unraid ntpd[1770]: 216.239.35.4 local addr 192.168.121.12 -> <null> Jul 22 08:13:25 unraid ntpd[1770]: 216.239.35.8 local addr 192.168.121.12 -> <null> Jul 22 08:13:25 unraid ntpd[1770]: 216.239.35.12 local addr 192.168.121.12 -> <null> Jul 22 08:13:36 unraid kernel: r8169 0000:04:00.0 eth0: Link is Up - 100Mbps/Full - flow control rx/tx Jul 22 08:13:37 unraid kernel: bond0: (slave eth0): link status definitely up, 100 Mbps full duplex Jul 22 08:13:37 unraid kernel: bond0: (slave eth0): making interface the new active one Jul 22 08:13:37 unraid kernel: device eth0 entered promiscuous mode Jul 22 08:13:37 unraid kernel: bond0: active interface up! Jul 22 08:13:37 unraid kernel: br0: port 1(bond0) entered blocking state Jul 22 08:13:37 unraid kernel: br0: port 1(bond0) entered forwarding state Jul 22 08:13:38 unraid ntpd[1770]: Listen normally on 230 br0 192.168.121.12:123 Jul 22 08:13:38 unraid ntpd[1770]: new interface(s) found: waking up resolver unraid-diagnostics-20210722-0818.zip
-
Looks like I'm having the exact same issue with Radarr that some other folks were having, but I don't see a resolution for it in this thread. I have reverse proxies set up for Sonarr and Radarr in NGINX Proxy Manager almost identically (both with a scheme of 'http'), with the only difference between their port. Both work great. I began following this guide (which is fantastic, by the way - thank you) to set up Authelia and was successfully able to route Sonarr through Authelia on the first try. However, when I perform the exact same steps with Radarr and Portainer (add the rules to the Authelia conf file, add Protected Endpoint conf block in the advanced tab for each proxy host in NPM), Authelia redirects the subdomain to http://radarr.subdomain.com instead of https://radarr.subdomain.com and throws an error. (I can access it just fine if I manually add an 's' to 'http' myself.) Note that I've used the exact same Protected Endpoint conf as Sonarr, replacing only the container name for Radarr/Portainer. I have no idea why Sonarr is the only one being automatically redirect to https right off the bat. Edit: It looks like this is an NPM issue - I was able to resolve it using the recommended fix per this support thread. Essentially, replace this line in OP's original config: auth_request_set $target_url $scheme://$http_host$request_uri; with this: auth_request_set $target_url https://$http_host$request_uri;
-
Any idea how stable the latest version is?
-
How can I update to the latest stable version of PMS 1.20 using this container? I don't want to be on the beta release because I don't want to test new features or bugs, but I'd like access to the new Plex Movie agent and installing this container from community apps only pulls down v1.19.
-
I'm currently using the binhex-Plex Docker container instead of this one (I do have the lifetime Plex Pass) and am interested in the new Plex movie scanner introduced in v1.20. The regular binhex-Plex container is still on 1.19 so I'm contemplating upgrading to binhex-plexpass so I can take advantage of the new scanner. Is this version actually prone to experiencing bugs and issues that might pop up, given it's on the faster release track? And would I be able to maintain all of my settings if I backed up the Plex Media Server folder from the regular version and restored it after installing the PlexPass container?
-
I have two identical directories in Unraid (one to store movie info - NFO files, posters, etc., and one to store actual movies). I'm trying to find a script that will automate copying all the metadata files in the first directory into the directory with the actual media on a daily basis. When I try to run this: #!/bin/bash bash cp -R mnt/user/metadates/movies/. mnt/user/movies/ I get this error: /bin/cp: /bin/cp: cannot execute binary file Does anyone have any thoughts on how I can accomplish this with User Scripts?
-
I'm having the same issue. I just rebooted and despite seeing my folders in the terminal, can't view them anywhere else (SMB, Krusader, etc.). This is frustrating.
-
Hey, sorry I'm seeing this so late - were you able to resolve this?
-
Hi. I'm having trouble getting rclone to actually mount using spaceinvaderone's guide. When I view my Dropbox mount from the terminal in rclone (reclone lsd Dropbox:) I can see all of the folders in the root of my Dropbox. However, when I try to mount it using the following script, nothing appears in the /mnt/disks/Dropbox folder: mkdir -p /mnt/disks/Dropbox rclone mount --max-read-ahead 1024k --allow-other Dropbox: /mnt/disks/Dropbox & Why can the terminal see my Dropbox folders and files but not Krusader when I run the mount script?
-
Does this support generating SSH keys? I don't see the typical "Auth" options under "SSH" in the PuTTY settings.
-
That worked. Do you know why I can't use the code command? I'm new to this and a friend who was helping me out also referenced the code command, so now I'm curious what it is and why I don't have it.
-
It isn't recognizing 'code' as a valid command in the terminal. I'm wondering if something isn't installed that should be.
-
Adding a path to another Unraid share allows me to access that share via the terminal from within the container, but I'd like to be able to see it when I try to open a file (along with the workspace folder, etc.). Is this possible?
-
I've added a new path via the template for the container but still don't see the option to select a file within it when opening a new file/folder from within the editor. Any thoughts?
-
I'm currently configuring the Python3 version of this - is it always going to take ~10 minutes to boot once I restart the container?
-
What's the best way to map other shares within my Unraid configuration to this container so I can view/edit files saved in those shares?
-
That did it. Thanks so much for your help, and thanks for all the work you do on your containers - I use them whenever possible and they're all great!
-
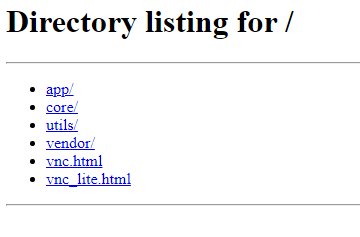
I have Krusader up and running on my Unraid server and have successfully added a password to access it. I'd now like to set up a reverse proxy so I can access it outside of my network. I've added it as a proxy host in Nginx Proxy Manager via the usual process, but when accessing the URL through it's subdomain, it's taking me to the page below. Is there any special configuration needed to access it via NPM?