




Snowman
Members
-
Joined
-
Last visited
Everything posted by Snowman
-
I'm trying to add the perplexity node but getting an error when I enter my api and save it, see error below. I think it has to do with n8n setup in unraid but unsure what I need to fix it? Has anybody else tried this? Error: Couldn’t connect with these settings Bad request - please check your parameters
-
I'm getting this when trying to update the plugin: plugin: run failed: '/bin/bash' returned 1. Not sure why as all other updates have worked before.
-
I had power outage and Unraid is ok but had to re-install all dockers from app store for some reason as docker page was blank. When I reinstalled Nextcloudaio docker is acting like new install. Trying to do restore from a borg backup but apparently I don't have encryption password as I thought it was the AIO password etc. What is my path to recover this or install new and keep files etc?
-
I came back from vacation with this error on multiple containers when trying to update them. I suspect appdata backup ran etc and something went wrong but now it wants me to rename containers to fix or something like there is 2 of the container. Fix common problems suggest docker.img is full or corrupt, check and it's not full so maybe corrupted, hoping not. I already restarted Unraid and restarted docker a few times in a attempt to fix it. I can't delete a container either as it gives execution error. Attached logs. snowtower-diagnostics-20231003-1012.zip
-
I had luckybackup working but then switched to 10GB card in backup server but same IP address as before and it won't work. It times out on backup server when trying to copy rsa.pub key over, logs below. Tying to delete things and redo but nothing has worked so far. Any help would be appreciated? Oct 23 17:31:51 Tower sshd[27983]: Connection from 192.168.0.15 port 59962 on 192.168.0.190 port 22 rdomain "" Oct 23 17:33:51 Tower sshd[27983]: fatal: Timeout before authentication for 192.168.0.15 port 59962
-
Ever since I updated to 24.0.6 from 24.0.5.1 I'm getting errors below in my logs and the dahsboard online is messed up. I assume it's have to do with the CSS errors but not sure how to fix it. It's like something got corrupted or something in the update. Any ideas or route to fix this? Error cssresourceloader Could not find resource css/css-variables.css to load 2022-10-13T17:56:22-0600 Warning core Failed to compile and/or save /config/www/nextcloud/core/css/css-variables.scss 2022-10-13T17:56:22-0600 Error scss_cacher SCSSCacher::cache unable to cache: css-variables.scss 2022-10-13T17:56:22-0600 Error PHP Error: file_put_contents(/data/appdata_ocbxpymb2asp/css/core/82bd-0564-css-variables.css): failed to open stream: Permission denied at /config/www/nextcloud/lib/private/Files/Storage/Local.php#296 2022-10-13T17:56:22-0600

-
I updated to 24.0.6 and the dashboard is all messed up which I assume is related to the errors in my logs here. Not sure how to fix it..?

-
I have same error on my 6.11.0 servers as well with Theme Engine. Server works fine but not sure how to fix it.
-
Is there any fix for this besides the manual fix in advance settings mentioned here, like is this a bug or what? My dockers on other VLAN worked before with no issue until today...
-
I used webUI. They ran and worked where they could but Disk 3 never found a block or secondary block.
-
Wish it was so but my rebuild were not clean and had lost and found items. 1 Disk won't emulate or mount so have to backup in separate computer and try to put info back after format. Been a long road trying to recovery data correctly. My cache drives/pools are the same mess and some info is not recognizable when copied over and try to open. This was a major blow up despite UPS etc. Not sure if it was me, power spike, trying to add new drive which was not working, or other that corrupted things but main not a fun one. Hard to pinpoint what happened. For sure I'll take screen shot configs for reference. I had no problems up to this point with my card.
-
Will I be able to pull data off the pooled cache disk with UFS explorer?
-
FYI-I had just powered down to pull a cache drive but powered back up to get diags. snowtower-diagnostics-20220907-1041.zip
-
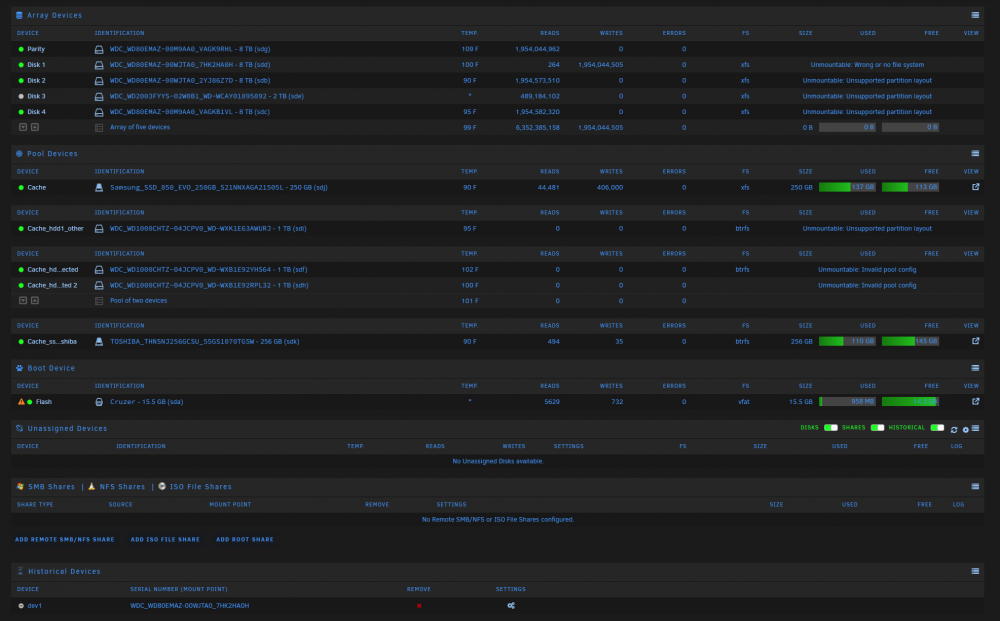
I have a couple of cache drives, 1 is a single cache drive that is "unmountable: unspported partition layout" from my crash the other is a pool of 2 drives that says: unmountable: Invalid pool config. Can I recover the pool somehow with the 2 drives or not sure why I got this error on the 2 drive pool? The single drive I will likely pull and back up for UFS Explorer but thinking the 2 drive pool might be something related to this post but not sure: Other update-I have backed up Disk 3 and will format and move data back using UFS Explorer

-
Emulated disk for disk 3 doesn't mount or show anything...still shows unmountable: wrong or no file system....
-
Can I replace disk 3 with new disk and rebuild or will i lose data that way? Already rebuilt other disks in array.
-
My disk 3 XFS repair goes no where, stuck on "attempting to find secondary superblock.... unable to verify superblock continuing" forever. This is in -n mode. I'll let it run longer but don't think it will fing secondary block. What do I do from here if it doesn't get past Phase 1?
-
Ok I will give it a go. On Disk 2 rebuild now. Have feeling this is going to be lots in lost in found like disk 1, the whole disk contents is in lost and found on Disk 1. Hard to put it back in place where the placeholder folder or anything are not there anymore. As far as HBA, hard to connect lots of drives without HBA but have seen Adaptec cards might be the culprit. On my pool disks do I do the same repair and rebuild process as they are in same status?
-
So I run the -L and then had to run just normal xfs repair. It appears it put everything in lost and found. Do I have to move it back or how does that work? Do I have to rebuild each disk by removing from array and then add again to start rebuild and then xfs repair or can I just do repair of what is correct steps?
-
So from this I assume I should put -L in? Phase 1 - find and verify superblock... bad primary superblock - bad magic number !!! attempting to find secondary superblock... ....................................................................................................found candidate secondary superblock... verified secondary superblock... writing modified primary superblock - reporting progress in intervals of 15 minutes Phase 2 - using internal log - zero log... Log inconsistent (didn't find previous header) failed to find log head zero_log: cannot find log head/tail (xlog_find_tail=5) ERROR: The log head and/or tail cannot be discovered. Attempt to mount the filesystem to replay the log or use the -L option to destroy the log and attempt a repair.
-
Check filesystem results: xfs_repair status: Phase 1 - find and verify superblock... bad primary superblock - bad magic number !!! attempting to find secondary superblock... ..................................................................................................................................................................................................................................................................................................................................................................found candidate secondary superblock... verified secondary superblock... would write modified primary superblock Primary superblock would have been modified. Cannot proceed further in no_modify mode. Exiting now.
-
Ok disk 1 rebuilt but still shows "Unmountable: Wrong or no file system" and others still show "Unmountable: Unsupported partition layout". How do I fix this or what are steps? It wants me to format drives that are not mountable which I won't do. snowtower-diagnostics-20220830-0948.zip
-
This was prior to starting Disk 1 rebuild. snowtower-diagnostics-20220829-1529.zip
-
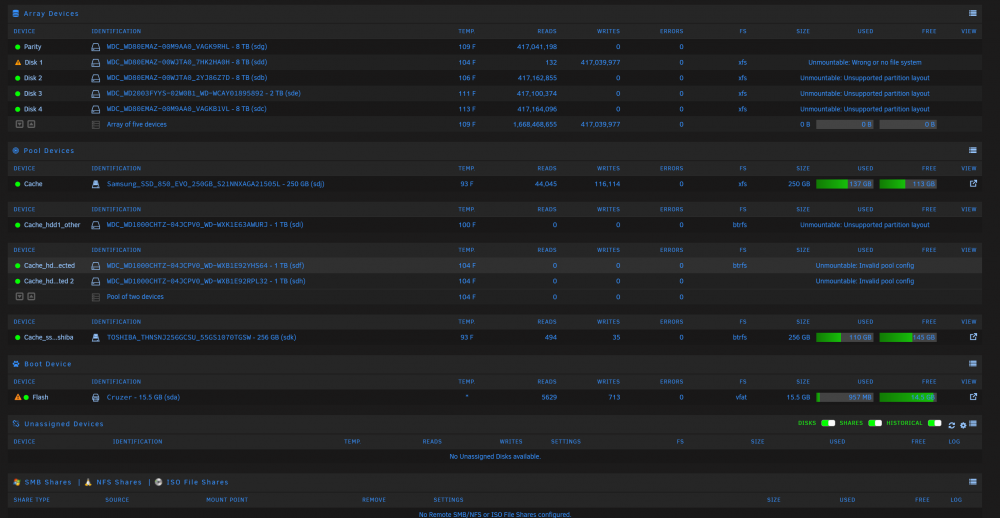
Now in rebuild of 1st drive it shows Unmountable: Wrong or no file system for Disk 1. Will the disk be ok after rebuild?
-
6.10.3 Unraid version. I was attempting to add another 8TB sas drive to this card in unraid. Was having issues viewing drive so I did some moved cable hooked only to this drive to 1 of the1 free ports on the card for this drive and looked at settings for card from super micro bios where I could see card. I don't recall changing it out of HBA mode but might of. Anyway I now have all the drives saying Unmountable: Unsupported partition layout but parity is valid and fine. I'm trying this post solution right now to take 1 drive out and then back in and rebuild. It is rebuilding disk 1 now. Not sure if this is the right thing to do or if other direction I should go?





