Wimpie
Members
-
Joined
-
Last visited
Everything posted by Wimpie
-
Somehow the port mappings came back...

-
I had tonight a few backups working, didn't find any errors in the urbackup error log. So I think it is solved. Thanks Binhex!
-
We might have a winner... First I got: Then the website worked. This is the log: Created by... ___. .__ .__ \_ |__ |__| ____ | |__ ____ ___ ___ | __ \| |/ \| | \_/ __ \\ \/ / | \_\ \ | | \ Y \ ___/ > < |___ /__|___| /___| /\___ >__/\_ \ \/ \/ \/ \/ \/ https://hub.docker.com/u/binhex/ 2025-11-25 20:14:39.769416 [info] Host is running unRAID 2025-11-25 20:14:39.804091 [info] System information: Linux TV-Tower-2 6.1.118-Unraid #1 SMP PREEMPT_DYNAMIC Thu Nov 21 15:54:38 PST 2024 x86_64 GNU/Linux 2025-11-25 20:14:39.834078 [info] Image architecture: 'amd64' 2025-11-25 20:14:39.878105 [info] Application name: 'urbackup' 2025-11-25 20:14:39.907256 [info] Base image release tag: '2025112201' 2025-11-25 20:14:39.936647 [info] Application image release tag: '2.5.34-1-04' 2025-11-25 20:14:39.968364 [info] PUID defined as '99' 2025-11-25 20:14:39.999452 [info] Executing usermod for PUID '99'... 2025-11-25 20:14:40.086781 [info] usermod completed successfully 2025-11-25 20:14:40.120999 [info] PGID defined as '100' 2025-11-25 20:14:40.172512 [info] Executing groupmod for PGID '100'... 2025-11-25 20:14:40.288056 [info] groupmod completed successfully 2025-11-25 20:14:40.317654 [info] UMASK defined as '000' 2025-11-25 20:14:40.348670 [info] Permissions file '/config/perms.txt' exists, skipping setting ownership and permissions on '/config' and '/data' 2025-11-25 20:14:40.382920 [info] Deleting files in /tmp (non recursive)... [info] Creating soft link from /config/urbackup to /var/urbackup... 2025-11-25 20:14:43.634811 [info] Starting Supervisor... 2025-11-25 20:14:43,775 INFO Included extra file "/etc/supervisor/conf.d/urbackup.conf" during parsing 2025-11-25 20:14:43,775 INFO Set uid to user 0 succeeded 2025-11-25 20:14:43,779 INFO RPC interface 'supervisor' initialized 2025-11-25 20:14:43,780 INFO supervisord started with pid 7 2025-11-25 20:14:44,782 INFO spawned: 'urbackup' with pid 74 2025-11-25 20:14:44,783 INFO reaped unknown pid 8 (exit status 0) 2025-11-25 20:14:44,808 DEBG 'urbackup' stderr output: Raising maximum file descriptor to 65535 failed. This may cause problems with many clients. (errno=1) Raising nice-ceiling to 35 failed. (errno=1) 2025-11-25 20:14:45,809 INFO success: urbackup entered RUNNING state, process has stayed up for > than 1 seconds (startsecs) 2025-11-25 20:14:51,441 DEBG 'urbackup' stdout output: MOUNT TEST OK 2025-11-25 20:14:51,445 DEBG 'urbackup' stdout output: Testing for btrfs... 2025-11-25 20:14:51,450 DEBG 'urbackup' stderr output: ERROR: Could not create subvolume: Inappropriate ioctl for device 2025-11-25 20:14:51,451 DEBG 'urbackup' stdout output: TEST FAILED: Creating test btrfs subvolume failed 2025-11-25 20:14:51,451 DEBG 'urbackup' stdout output: Testing for zfs... TEST FAILED: Dataset is not set via /etc/urbackup/dataset I don't have a ZFS drive, and also no BTRFS drive that is backed up by urbackup (it's a XFS drive). Don't know what the "Could not create subvolume: Inappropriate ioctl for device" means (test for BTRFS drives ?). Don't know if these are important: Raising maximum file descriptor to 65535 failed. This may cause problems with many clients. (errno=1) Raising nice-ceiling to 35 failed. (errno=1) Haven't tried a restore or anything else, just a startup of the docker. One strange thing: I used to have 2 port mappings, they are gone. The website works though... Thanks for looking into this...

-
Hoi @binhex, Saw your message just now. I tried the new image (latest and then update), but it doesn't work for me. Hope the log helps, if you need anything else, let me know... In the mean time, going back to binhex/arch-urbackup:2.5.33-2-01... Created by... ___. .__ .__ \_ |__ |__| ____ | |__ ____ ___ ___ | __ \| |/ \| | \_/ __ \\ \/ / | \_\ \ | | \ Y \ ___/ > < |___ /__|___| /___| /\___ >__/\_ \ \/ \/ \/ \/ \/ https://hub.docker.com/u/binhex/ 2025-11-25 13:05:37.885781 [info] Host is running unRAID 2025-11-25 13:05:37.916972 [info] System information: Linux TV-Tower-2 6.1.118-Unraid #1 SMP PREEMPT_DYNAMIC Thu Nov 21 15:54:38 PST 2024 x86_64 GNU/Linux 2025-11-25 13:05:37.955825 [info] Image architecture: 'amd64' 2025-11-25 13:05:38.002941 [info] Application name: 'urbackup' 2025-11-25 13:05:38.052286 [info] Base image release tag: '2025112201' 2025-11-25 13:05:38.088084 [info] Application image release tag: '2.5.34-1-02' 2025-11-25 13:05:38.125530 [info] PUID defined as '99' 2025-11-25 13:05:38.170413 [info] Executing usermod for PUID '99'... 2025-11-25 13:05:38.278140 [info] usermod completed successfully 2025-11-25 13:05:38.317381 [info] PGID defined as '100' 2025-11-25 13:05:38.350618 [info] Executing groupmod for PGID '100'... 2025-11-25 13:05:38.459368 [info] groupmod completed successfully 2025-11-25 13:05:38.489439 [info] UMASK defined as '000' 2025-11-25 13:05:38.520521 [info] Permissions file '/config/perms.txt' exists, skipping setting ownership and permissions on '/config' and '/data' 2025-11-25 13:05:38.553278 [info] Deleting files in /tmp (non recursive)... [info] Creating soft link from /config/urbackup to /var/urbackup... 2025-11-25 13:05:41.854716 [info] Starting Supervisor... 2025-11-25 13:05:41,997 INFO Included extra file "/etc/supervisor/conf.d/urbackup.conf" during parsing 2025-11-25 13:05:41,997 INFO Set uid to user 0 succeeded 2025-11-25 13:05:42,001 INFO RPC interface 'supervisor' initialized 2025-11-25 13:05:42,002 INFO supervisord started with pid 7 2025-11-25 13:05:43,004 INFO spawned: 'urbackup' with pid 74 2025-11-25 13:05:43,004 INFO reaped unknown pid 8 (exit status 0) 2025-11-25 13:05:43,040 DEBG 'urbackup' stderr output: /home/nobody/start.sh: line 20: 80 Illegal instruction /usr/bin/urbackupsrv run --config '/config/urbackup/config/urbackupsrv' --no-consoletime 2025-11-25 13:05:43,040 DEBG fd 9 closed, stopped monitoring <POutputDispatcher at 23114002800928 for <Subprocess at 23114002792864 with name urbackup in state STARTING> (stdout)> 2025-11-25 13:05:43,040 DEBG fd 11 closed, stopped monitoring <POutputDispatcher at 23114002441360 for <Subprocess at 23114002792864 with name urbackup in state STARTING> (stderr)> 2025-11-25 13:05:43,041 WARN exited: urbackup (exit status 132; not expected) 2025-11-25 13:05:43,041 DEBG received SIGCHLD indicating a child quit 2025-11-25 13:05:44,043 INFO spawned: 'urbackup' with pid 81 2025-11-25 13:05:44,058 DEBG 'urbackup' stderr output: /home/nobody/start.sh: line 20: 87 Illegal instruction /usr/bin/urbackupsrv run --config '/config/urbackup/config/urbackupsrv' --no-consoletime 2025-11-25 13:05:44,058 DEBG fd 9 closed, stopped monitoring <POutputDispatcher at 23114002441360 for <Subprocess at 23114002792864 with name urbackup in state STARTING> (stdout)> 2025-11-25 13:05:44,059 DEBG fd 11 closed, stopped monitoring <POutputDispatcher at 23114002296480 for <Subprocess at 23114002792864 with name urbackup in state STARTING> (stderr)> 2025-11-25 13:05:44,059 WARN exited: urbackup (exit status 132; not expected) 2025-11-25 13:05:44,059 DEBG received SIGCHLD indicating a child quit 2025-11-25 13:05:46,062 INFO spawned: 'urbackup' with pid 88 2025-11-25 13:05:46,079 DEBG 'urbackup' stderr output: /home/nobody/start.sh: line 20: 94 Illegal instruction /usr/bin/urbackupsrv run --config '/config/urbackup/config/urbackupsrv' --no-consoletime 2025-11-25 13:05:46,080 DEBG fd 9 closed, stopped monitoring <POutputDispatcher at 23114002296480 for <Subprocess at 23114002792864 with name urbackup in state STARTING> (stdout)> 2025-11-25 13:05:46,080 DEBG fd 11 closed, stopped monitoring <POutputDispatcher at 23114002717232 for <Subprocess at 23114002792864 with name urbackup in state STARTING> (stderr)> 2025-11-25 13:05:46,080 WARN exited: urbackup (exit status 132; not expected) 2025-11-25 13:05:46,080 DEBG received SIGCHLD indicating a child quit 2025-11-25 13:05:49,084 INFO spawned: 'urbackup' with pid 95 2025-11-25 13:05:49,098 DEBG 'urbackup' stderr output: /home/nobody/start.sh: line 20: 101 Illegal instruction /usr/bin/urbackupsrv run --config '/config/urbackup/config/urbackupsrv' --no-consoletime 2025-11-25 13:05:49,099 DEBG fd 9 closed, stopped monitoring <POutputDispatcher at 23114002923872 for <Subprocess at 23114002792864 with name urbackup in state STARTING> (stdout)> 2025-11-25 13:05:49,099 DEBG fd 11 closed, stopped monitoring <POutputDispatcher at 23114002926320 for <Subprocess at 23114002792864 with name urbackup in state STARTING> (stderr)> 2025-11-25 13:05:49,099 WARN exited: urbackup (exit status 132; not expected) 2025-11-25 13:05:49,099 DEBG received SIGCHLD indicating a child quit 2025-11-25 13:05:50,100 INFO gave up: urbackup entered FATAL state, too many start retries too quickly
-
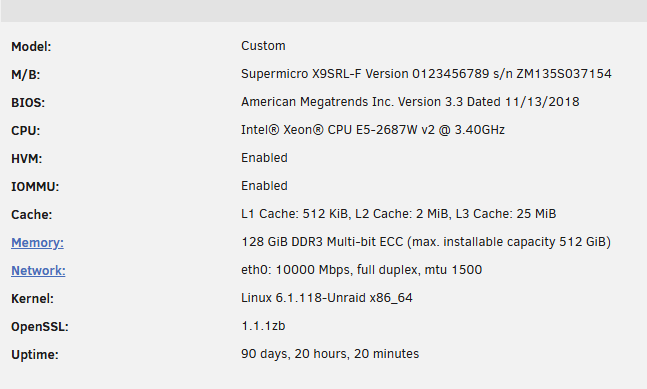
Like I said, it doesn't work for me. This is the server hardware. I'm still running unRAID v6.12.14 PS: I also pulled 2.5.33-2-01, this version works for me.
-
Sadly, me too... Container "runs", but in the log you see that it had too many retry's ("gave up: urbackup entered FATAL state, too many start retries too quickly"), website is also not working.
-
Just an idea, haven't tried it: https://docs.paperless-ngx.com/advanced_usage/#consume-hooks Custom Container Initialization The Docker image includes the ability to run custom user scripts during startup. This could be utilized for installing additional tools or Python packages, for example. Scripts are expected to be shell scripts. To utilize this, mount a folder containing your scripts to the custom initialization directory, /custom-cont-init.d and place scripts you wish to run inside. For security, the folder must be owned by root and should have permissions of a=rx. Additionally, scripts must only be writable by root. Your scripts will be run directly before the webserver completes startup. Scripts will be run by the root user. If you would like to switch users, the utility gosu is available and preferred over sudo. This is an advanced functionality with which you could break functionality or lose data. If you experience issues, please disable any custom scripts and try again before reporting an issue. For example, using Docker Compose: services: # ... webserver: # ... volumes: - /path/to/my/scripts:/custom-cont-init.d:ro Could you not use this to install wget? Again, haven't tried it...
-
Please read the manual, it's all there. Eg: Paths and folders PAPERLESS_CONSUMPTION_DIR=<path> This where your documents should go to be consumed. Make sure that it exists and that the user running the paperless service can read/write its contents before you start Paperless. Don't change this when using docker, as it only changes the path within the container. Change the local consumption directory in the docker-compose.yml file instead. Defaults to "../consume/", relative to the "src" directory. PAPERLESS_DATA_DIR=<path> This is where paperless stores all its data (search index, SQLite database, classification model, etc). Defaults to "../data/", relative to the "src" directory. PAPERLESS_TRASH_DIR=<path> Instead of removing deleted documents, they are moved to this directory. This must be writeable by the user running paperless. When running inside docker, ensure that this path is within a permanent volume (such as "../media/trash") so it won't get lost on upgrades. Note that the directory must exist prior to using this setting. Defaults to empty (i.e. really delete documents). PAPERLESS_MEDIA_ROOT=<path> This is where your documents and thumbnails are stored. You can set this and PAPERLESS_DATA_DIR to the same folder to have paperless store all its data within the same volume. Defaults to "../media/", relative to the "src" directory. PAPERLESS_STATICDIR=<path> Override the default STATIC_ROOT here. This is where all static files created using "collectstatic" manager command are stored. Unless you're doing something fancy, there is no need to override this. If this is changed, you may need to run collectstatic again. Defaults to "../static/", relative to the "src" directory. PAPERLESS_LOGGING_DIR=<path> This is where paperless will store log files. Defaults to PAPERLESS_DATA_DIR/log/. PAPERLESS_NLTK_DIR=<path> This is where paperless will search for the data required for NLTK processing, if you are using it. If you are using the Docker image, this should not be changed, as the data is included in the image already. Previously, the location defaulted to PAPERLESS_DATA_DIR/nltk. Unless you are using this in a bare metal install or other setup, this folder is no longer needed and can be removed manually. Defaults to /usr/share/nltk_data
-
Docker containers don't always expose the config file. From the manual: "If you run paperless on docker, paperless.conf is not used. Rather, configure paperless by copying necessary options to docker-compose.env". Unraid uses a slightly modified docker system. The docker-compose.env file is not adjustable by a user. This means that in unraid you configure the application through variables... https://docs.paperless-ngx.com/configuration/ An example:
-
Did you read the manual? https://docs.paperless-ngx.com/ Is this the first container (docker) you install? look at:
-
Thanks for the template. It installed ok on my server (got it's own IP). Now looking to configure it.
-
Ran the repair under 6.9.2 and it solved the problem. Thanks
-
Real life is very busy, but found now some time... Running the filesystem check on disk 1 in unRAID v6.9.2 resulted in this: Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... - scan filesystem freespace and inode maps... Metadata CRC error detected at 0x47542a, xfs_sb block 0x0/0x200 superblock has bad CRC for ag 0 would zero unused portion of primary superblock (AG #0) - found root inode chunk Phase 3 - for each AG... - scan (but don't clear) agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 1 - agno = 0 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 No modify flag set, skipping phase 5 Phase 6 - check inode connectivity... - traversing filesystem ... - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify link counts... No modify flag set, skipping filesystem flush and exiting. So should I run the repair now without the -n flag (let it correct the error)? No problem running this under 6.9.2, or should I do it under 6.11.0? Thanks
-
It seems I misnamed the diagnostics, 6.9.2 is 6.11.0 and reversed. Anyway, I get this from 6.11.0: Oct 1 17:52:18 TV-Tower emhttpd: Mounting disks... Oct 1 17:52:20 TV-Tower emhttpd: shcmd (102): mkdir -p /mnt/disk1 Oct 1 17:52:20 TV-Tower emhttpd: shcmd (103): mount -t xfs -o noatime,nouuid /dev/md1 /mnt/disk1 Oct 1 17:52:21 TV-Tower kernel: SGI XFS with ACLs, security attributes, no debug enabled Oct 1 17:52:21 TV-Tower kernel: XFS (md1): Metadata CRC error detected at xfs_sb_read_verify+0x11e/0x1aa [xfs], xfs_sb block 0x0 Oct 1 17:52:21 TV-Tower kernel: XFS (md1): Unmount and run xfs_repair Oct 1 17:52:21 TV-Tower kernel: XFS (md1): First 128 bytes of corrupted metadata buffer: Oct 1 17:52:21 TV-Tower kernel: 00000000: 58 46 53 42 00 00 10 00 00 00 00 00 74 70 25 49 XFSB........tp%I Oct 1 17:52:21 TV-Tower kernel: 00000010: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ Oct 1 17:52:21 TV-Tower kernel: 00000020: 24 04 07 d5 8a d8 4e 24 b9 9b ad 55 55 e3 a8 49 $.....N$...UU..I Oct 1 17:52:21 TV-Tower kernel: 00000030: 00 00 00 00 20 00 00 04 00 00 00 00 00 00 00 80 .... ........... Oct 1 17:52:21 TV-Tower kernel: 00000040: 00 00 00 00 00 00 00 81 00 00 00 00 00 00 00 82 ................ Oct 1 17:52:21 TV-Tower kernel: 00000050: 00 00 00 01 0a ea 85 1b 00 00 00 0b 00 00 00 00 ................ Oct 1 17:52:21 TV-Tower kernel: 00000060: 00 05 75 42 b4 b4 02 00 01 00 00 10 00 00 00 00 ..uB............ Oct 1 17:52:21 TV-Tower kernel: 00000070: 00 00 00 00 00 00 00 00 0c 09 08 04 1c 00 00 05 ................ Oct 1 17:52:21 TV-Tower kernel: XFS (md1): SB validate failed with error -74. Oct 1 17:52:21 TV-Tower root: mount: /mnt/disk1: mount(2) system call failed: Structure needs cleaning. Oct 1 17:52:21 TV-Tower root: dmesg(1) may have more information after failed mount system call. Oct 1 17:52:21 TV-Tower emhttpd: shcmd (103): exit status: 32 Oct 1 17:52:21 TV-Tower emhttpd: /mnt/disk1 mount error: Wrong or no file system Oct 1 17:52:21 TV-Tower emhttpd: shcmd (104): umount /mnt/disk1 Oct 1 17:52:21 TV-Tower root: umount: /mnt/disk1: not mounted. Oct 1 17:52:21 TV-Tower emhttpd: shcmd (104): exit status: 32 Oct 1 17:52:21 TV-Tower emhttpd: shcmd (105): rmdir /mnt/disk1 Oct 1 17:52:21 TV-Tower emhttpd: shcmd (106): mkdir -p /mnt/disk2 While under 6.9.2 I get: Oct 1 17:41:07 TV-Tower emhttpd: Mounting disks... Oct 1 17:41:07 TV-Tower emhttpd: shcmd (166): /sbin/btrfs device scan Oct 1 17:41:09 TV-Tower root: Scanning for Btrfs filesystems Oct 1 17:41:09 TV-Tower emhttpd: shcmd (167): mkdir -p /mnt/disk1 Oct 1 17:41:09 TV-Tower emhttpd: shcmd (168): mount -t xfs -o noatime /dev/md1 /mnt/disk1 Oct 1 17:41:09 TV-Tower kernel: SGI XFS with ACLs, security attributes, no debug enabled Oct 1 17:41:09 TV-Tower kernel: XFS (md1): Deprecated V4 format (crc=0) will not be supported after September 2030. Oct 1 17:41:09 TV-Tower kernel: XFS (md1): Mounting V4 Filesystem Oct 1 17:41:09 TV-Tower kernel: XFS (md1): Ending clean mount Oct 1 17:41:09 TV-Tower kernel: xfs filesystem being mounted at /mnt/disk1 supports timestamps until 2038 (0x7fffffff) Oct 1 17:41:09 TV-Tower emhttpd: shcmd (169): xfs_growfs /mnt/disk1 Oct 1 17:41:09 TV-Tower root: meta-data=/dev/md1 isize=256 agcount=11, agsize=183141659 blks Oct 1 17:41:09 TV-Tower root: = sectsz=512 attr=2, projid32bit=0 Oct 1 17:41:09 TV-Tower root: = crc=0 finobt=0, sparse=0, rmapbt=0 Oct 1 17:41:09 TV-Tower root: = reflink=0 Oct 1 17:41:09 TV-Tower root: data = bsize=4096 blocks=1953506633, imaxpct=5 Oct 1 17:41:09 TV-Tower root: = sunit=0 swidth=0 blks Oct 1 17:41:09 TV-Tower root: naming =version 2 bsize=4096 ascii-ci=0, ftype=0 Oct 1 17:41:09 TV-Tower root: log =internal log bsize=4096 blocks=357698, version=2 Oct 1 17:41:09 TV-Tower root: = sectsz=512 sunit=0 blks, lazy-count=1 Oct 1 17:41:09 TV-Tower root: realtime =none extsz=4096 blocks=0, rtextents=0 Oct 1 17:41:09 TV-Tower emhttpd: shcmd (170): mkdir -p /mnt/disk2 Nothing is changed, except the upgrade. Why do I get this with 6.11.0? Oct 1 17:52:21 TV-Tower kernel: XFS (md1): Metadata CRC error detected at xfs_sb_read_verify+0x11e/0x1aa [xfs], xfs_sb block 0x0
-
Did you unselect the drive, and then select it again in the same slot (when the array is stopped)? Hope you understand what I mean, if it is disk 3, put the disk 3 slot in "no" drive, and then select the drive again in the disk 3 slot.
-
I'm not an expert, but before all trying that, why not just reboot the server. You won't do something that can't be undone, and I have a guess it will solve the problem. "new config" is irreverseble, so don't do it without some advice from an expert here. Don't know about the rebuild, but also propably better wait for advice before you do that.
-
Hi, Decided to upgrade a 6.9.2 server to 6.11.0. Ran "Update Assistant" before and removed Nerdpack. "Update Assistant" said 'good to go'. After the update (running 6.11.0) disk 1 was disabled (Unmountable: Wrong or no file system). This seemed to be the only problem (did not search further). I downgraded to 6.9.2, and disk 1 worked again (disk was mounted). Took a diagnostics. Upgraded to 6.11.0 again, and disk 1 was again disabled. Took again a diagnostics. How do I best solve this? Is there a XFS filesystem error that 6.9.2 can handle and 6.11.0 not. Would a rebuild get rid of that XFS filesystem error (or whatever the problem is)? I don't have a spare drive, could buy one, but prefer not to if not needed. PS: Posted this also in the "General Support" forum, including the 2 diagnostic files. I post here just to let others know if they have a similar problem.
-
Hi, Decided to upgrade a 6.9.2 server to 6.11.0. Ran "Update Assistant" before and removed Nerdpack. "Update Assistant" said 'good to go'. After the update (running 6.11.0) disk 1 was disabled (Unmountable: Wrong or no file system). This seemed to be the only problem (did not search further). No files were accessable on disk 1, they are not simulated. I downgraded to 6.9.2, and disk 1 worked again (disk was mounted). Took a diagnostics. I can access files on disk 1, at least no problems with 1 at random chosen file. Upgraded to 6.11.0 again, and disk 1 was again disabled. Took again a diagnostics. I am now back on 6.9.2. How do I best solve this? Is there a XFS filesystem error that 6.9.2 can handle and 6.11.0 not? Would a rebuild get rid of that XFS filesystem error (or whatever the problem is)? I don't have a spare drive, could buy one, but prefer not to if not needed. tv-tower-diagnostics-6.9.2.zip tv-tower-diagnostics-6.11.0.zip
-
JorgeB, Thanks. That did it. Didn't know it was so simple...
-
Hi, I have a X9SRL-F MB, which has 2 1Gb sockets. I added a dual 10Gb NIC and want to use this as my only network connection, ie put a network cable in one of the 2 10Gb sockets. The 1Gb sockets get no cable. Things I already did: - VM's: virbr0 stopped working, but br2 seems to work. I can acces my VM fine, and it has internet connectivity. - Docker: I managed to get it on br2: " IPv4 custom network on interface br2: Subnet: 192.168.157.0/24 Gateway: 192.168.157.1 DHCP pool: not set". The dockers seems to work (updates not). - Also some fiddling to get my router assign the fixed IP for the server (MAC for 10 Gb is of course different from the MAC address of the 1Gb socket) What does not work: I can't seem to give eth2 a DNS server, this appears to be only possible to eth0 How do I do this? Maybe another solution would be to rename the interfaces. See this I checked and the file "70-persistent-net.rules" also exists on unraid, it contains: # PCI device 0x8086:0x10d3 (e1000e) SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="00:25:90:d0:f4:6e", ATTR{dev_id}=="0x0", ATTR{type}=="1", KE RNEL=="eth*", NAME="eth0" # PCI device 0x8086:0x10d3 (e1000e) SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="00:25:90:d0:f4:6f", ATTR{dev_id}=="0x0", ATTR{type}=="1", KE RNEL=="eth*", NAME="eth1" # PCI device 0x8086:0x151c (ixgbe) SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="00:1b:21:ac:11:b0", ATTR{dev_id}=="0x0", ATTR{type}=="1", KE RNEL=="eth*", NAME="eth2" # PCI device 0x8086:0x151c (ixgbe) SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="00:1b:21:ac:11:b1", ATTR{dev_id}=="0x0", ATTR{type}=="1", KE RNEL=="eth*", NAME="eth3" By changing this file to : # PCI device 0x8086:0x10d3 (e1000e) SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="00:25:90:d0:f4:6e", ATTR{dev_id}=="0x0", ATTR{type}=="1", KE RNEL=="eth*", NAME="eth2" # PCI device 0x8086:0x10d3 (e1000e) SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="00:25:90:d0:f4:6f", ATTR{dev_id}=="0x0", ATTR{type}=="1", KE RNEL=="eth*", NAME="eth1" # PCI device 0x8086:0x151c (ixgbe) SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="00:1b:21:ac:11:b0", ATTR{dev_id}=="0x0", ATTR{type}=="1", KE RNEL=="eth*", NAME="eth0" # PCI device 0x8086:0x151c (ixgbe) SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="00:1b:21:ac:11:b1", ATTR{dev_id}=="0x0", ATTR{type}=="1", KE RNEL=="eth*", NAME="eth3" I think this would also solve my problem. However, how do I change this "70-persistent-net.rules" file so that these changes are preserved across reboots and upgrades (just copy new file over old file would suffice, but how/when in the booting process do I do that)? Can anyone please help so I can update my plugins an dockers again. Another way to fix this is also good for me. Thanks Wim tv-tower-2-diagnostics-20220607-1718.zip
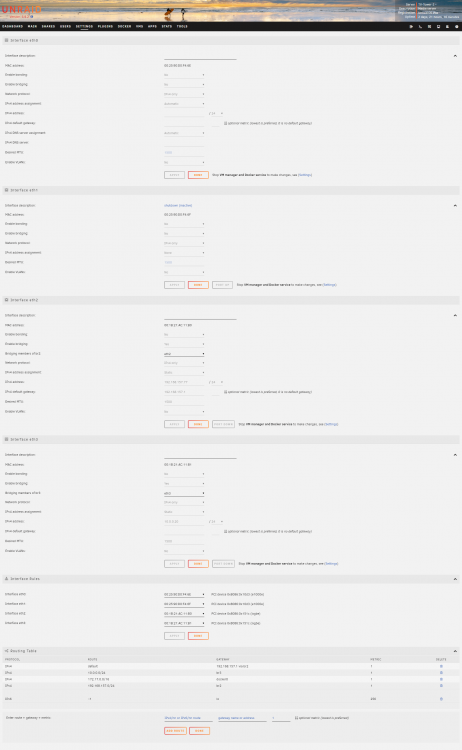
-
Had the same problem, solved it by uninstalling strace from nerdpack and then getting an older package from: https://slackware.pkgs.org/14.2/slackware-x86_64/strace-4.11-x86_64-1.txz.html Copy it somewhere on your server, get a shell and use : upgradepkg --install-new strace-4.11-x86_64-1.txz Worked for me...
-
Binhex, thanks to update the docker! I appreciate all the effort you put in this!
-
A new version is available, see https://www.urbackup.org/server_changelog.html (we are now on 2.4.13, 2.4.15 is available). "Fix corruption on transfer resume with full sparse file transfer" looks like something you want fixed... Can the docker please be upgraded? Thanks!
-
I am having trouble accessing files in the appdata UrBackUp directory (eg saving an edited urbackupsrv config file). I noticed that the root dir has other file rights than my other dockers. Is this a bug or a feature?
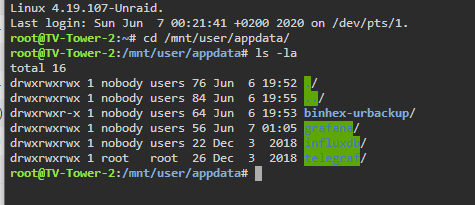
-
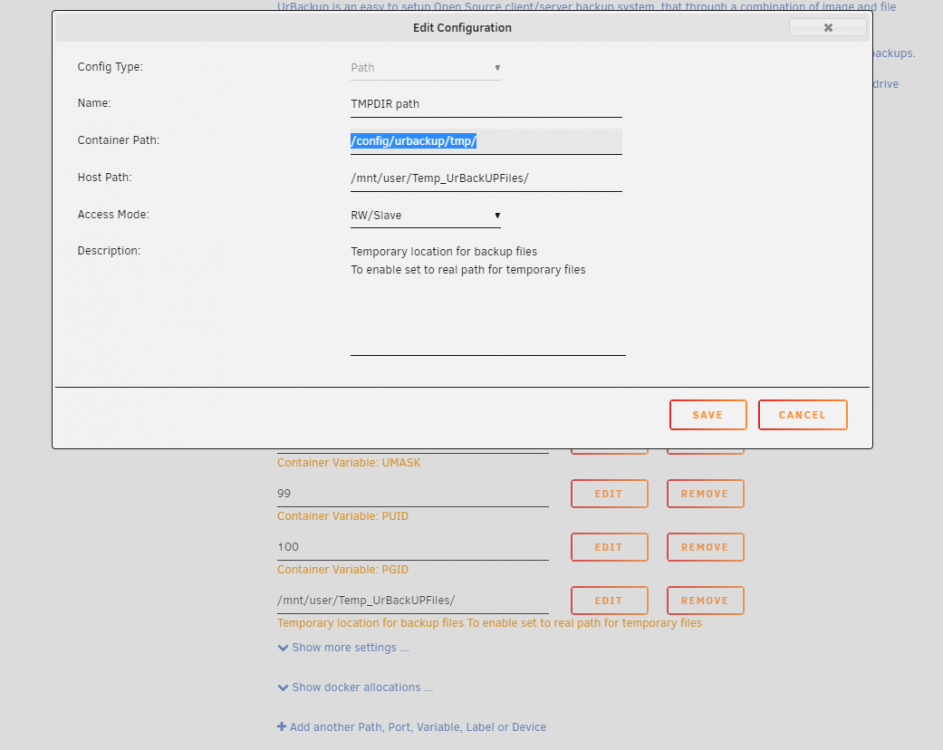
Great docker, thank you! I wanted to enable the temporary file buffers (section 8.5.1 in the manual, this can speedup the backup when you have a slow array), but when I did, all the temp data was (temporarily) saved in the appdata dir. This meant that if CA Backup started to do a backup while UrBackUp was working, that it also saved all those temp files. I tried to set a TMPDIR variable with docker, but that didn't work. It appeared that the TMPDIR var was set in the UrBackUp config file to "/config/urbackup/tmp/", and that the config file overrides the variable. In the end I solved this by just redirecting the docker path to a external (to the docker) directory. The "/mnt/user/Temp_UrBackUPFiles/" dir is on the cache drive with a "prefer" cache setting.