




TexasUnraid
Members
-
Joined
-
Last visited
Everything posted by TexasUnraid
-
Yeah, once synced it doesn't take much to stay synced. Indeed, I will be taking a backup on a regular basis from now on as well. Been sitting at 48TB for awhile but looks like I am going to have to pull my 12TB drive for proper service soon so will drop me down to 36TB. Just can't justify putting nice drives into chia at this point.
-
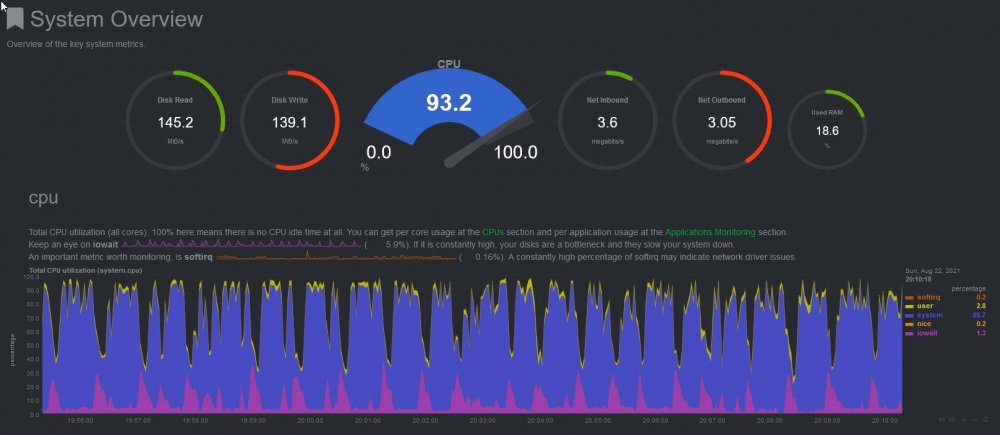
Here is what half the blockchains just trying to sync up the wallets and remaining blocks from that site you linked looks like on a 20C/40T server, it is getting HAMMERED. Pulling 500w from the wall lol. It would be working even harder but it is IO limited since the VM is running on some 10k drives.
-
Dang, that site saved me a TON of time. I was in the process of spinning up a VM to download all these and it was not going to be quick lol.
-
wow, that does help indeed! Good find!
-
Well, this sucks. The boot SSD for my farming machine just died. On the plus side I think that it might of been failing for awhile and causing my crashes. Now I get the fun of re-downloading all those blockchains. That will take weeks lol. Wish there was a way to download a monthly updated blockchain directly or something to at least get a head start. Thinking about spinning up a VM on my server to help with the load.
-
So had a BTRFS corruption error on a drive and decided to run a scrub of all my drives to check them out but noticed something odd. The total scrub speed for the system seems to be bottlenecked to around ~800mb/s? AKA, if I start 4x drives scrubbing I get 200mb/s per drive but if I start a 5th drive they all drop to ~160mb/s for the same total system read speed. If I do a parity check on the other hand I can get the full speed of all drives and over 2GB/s easily. The system is a 2x 10c/20t 2680v2 and CPU usage is only around ~30%. I would think adding more scrub jobs would be more threads and thus easily spread over the 40 threads I have. The SAS card can sustain far more then 800mb/s as shown by the parity check. I can't figure out where the bottleneck could be, anyone have any ideas?
-
True, more habit I guess of not wanting to have to fix something but as long as it has the files in a backup, the age should not matter.
-
very interesting idea, I guess it still counts on unraid not changing the docker file too much but interesting for sure. I will have to think about if I want to implement it. Leaning towards yes. Personally I would just setup a script to sync the ramdisk hourly. I do that with my ramdisk now and still get 1/8th the writes I used to get. Could even sync it to the array as well I suppose if you have a drive you don't spin down.
-
1: I did a du of the folder that is being converted to a ramdrive and even with my 70 dockers I only had 60mb in it. Figure it would grow some as the logs grew but still I don't see it growing more then ~256mb even with all my dockers unless there is a misbehaving docker with far too many log writes or VERY long uptimes. Edit: come to think of it, the docker log rotation setting should limit the max size it could grow to. 2: This folder seems to only hold log files, so docker should not care if a write was missed as long as the folders exist (it might even re-create them if they are missing, not sure). During testing I deleted a few of the log files and don't remember there being any issues, it simply started a new one. That said an hourly rsync to the backup folder would not be a horrible idea, it could be a adjustable setting in the docker settings as well if this was combined into the official docker. This basically cut my writes in half. Worst possible case, the docker can simply be re-installed / updated and it would correct any issues.
-
A very involved fix but should work. Although think I will stick with the setup I have now. Once I start making permanent changes that will not flow through updates is where I tend to draw the line unless there are no other options. Still very good to have a complete option to deal with the writes, I will keep it in mind if I have to keep dealing with it. Seems like something that could be added into unraid in general considering the write it saves and how easy it would be to implement.
-
Sad, it is a good idea and would solve a lot of issues. Good enough that it should be done in the official unraid docker mount command IMHO. It would not be hard at all to sort it out and the timing of the syncs could be adjusted in the docker settings menu easily.
-
Yeah, I had this issue when dealing with the inotifywait command. Have you tried working directly in the /var/lib/docker? This is how I got the inotifywait to work and better yet it worked fine with both folder and image docker setups.
-
First part Interesting idea, I had not even considered that. I like it and think I will switch my setup over to that, it is just a few extra commands to add to my existing sync script. I will add this to the OP as well. I said at the start of the section that all commands need to be entered into the extra parameters, maybe that was not enough? Another interesting idea but also not sure of the ramifications.
-
Well, after spending the last week chasing issues I am starting over and starting the blockchinas one by one to see what is causing the crashes. I know it can run stable without crashing as I have randomly had it happen but could not find the common denominator that is causing the crashes.
-
Ah, ok, now I see how those button options work. I could not figure out where it added the buttons. Very handy indeed. Particularly the command option. Yes, the Container/VM preview and I think there was 1 or 2 more that didn't have the description option. Took some experimentation to figure out what they did exactly.
-
Been messing around getting this setup with my ~70 dockers today. I am curious, what do the Add button and divider options do? I have tried adding them but can't see any difference? It looks like you could add a button that runs a command in the docker, this would be really handy for a few dockers that I have to tweak some manual stuff when they are updated. Some of the options are missing descriptions, would be cool to add in some descriptions to explain what they do. I had to toggle some of them on and off a few times to figure out what they did. Otherwise VERY nice work. I have been having to scroll through all 70 dockers for months and it gets old lol.
-
Ah I see. Yeah either adding another page or a section below those with icons that can be uploaded to the USB would be fantastic. Call me old school but I like to have everything possible local. Plus it is just simpler and quicker. If you wanted to add the ability to browse local icons to individual dockers as well that would be cool. I tend to do a lot of custom containers and it is annoying to do the icons right now.
-
If you click the icon on the left of that box it pulls up a menu that seems to be an icon selection box with a pick and cancel button. Seems to be a menu to select from locally stored icons (which makes total sense). What is that menu for if it is not for picking icons?
-
I love this plugin! Been needing this for a long time! Ok, I must be missing something obvious. How do I upload the icons to the sever so that the "pick" button will work? I want to upload them all so I don't have to copy/paste URL's everytime.
-
I redid a lot of my drive setup and think I figured out what is causing some of them to crash. I am also mining on an old Vega 56 on this system and somehow it seems to cause the Chia blockchains to crash. No idea how or why. I was updating the blockchains and they all kept running for a full day without an issue but as soon as I started the GPU mining they started to crash within hours. Leaves me in a pickle. I don't think that chia is worth the ~250w it takes to mine it alone so not sure if I should just disable chia mining, only mine the blockchains that don't crash or split it up into 2 separate machines.
-
Ah, I forgot to update that go command when I changed the file format. Thanks for pointing that out. Yes, everything except /boot and /mnt is stored in memory with unraid IIRC.
-
Odd, when you compressed the keyfile it should have made it a key.7z file automatically. Are you sure you compressed it with 7z in a prior step? The keyfile is not on the USB, it is stored in ram. It is lost if the system is powered down or rebooted already. You could create a script in user scripts that will delete the files on array start pretty easily though if it bothers you.
-
If you want it to auto start, then yes you would want to enable that. I tend to leave it disabled most of the time and this just keeps me from having to enter the password manually. I only enable it if there is a chance it will need to be restarted when I am not around.
-
Correct
-
Ok, updated the OP.
