




BVD
Members
-
Joined
-
Last visited
Everything posted by BVD
-
This should be moved to the support section IMO - this sub-forum is for guides created to assist with different components of unraid.
-
@Partizanct That was actually intentional on my part 😅 This is primarily because there's precious few that applies to 'everything'. For instance, everyone says 'ashift=12' for the pool, right? But that means that our physical layer block size is set to 4K, and there's a huge amount of NAND out there that's 8k, even some that're 16k, leaving a lot to be desired. Or what about setting dnodesize to auto? This is great, but really. works best with xattr set to SA, and if you're not accessing the data primarily over NFS/iSCSI/SMB, you could actually lose (not much, likely, but some) performance. Heck, setting xattr to sa also means that pool's linux only now, losing the portability to BSD kernels (and others), as it's a Linux only thing. I'd hate to recommend something like that too broadly, then the user find out years later when they try to move the pool to some hot new BSD based system that's got all the new bells and whistles that they simply can't because some guy online said it was a good idea and they never looked any further into it right? Better that those values get researched, their implications understood, and folks choose what's best for them and their specific situation. Recommendations differ for HDD vs NAND as well. The other part of my reasoning also goes back to what I feel is required for someone to be successful with ZFS (will to learn, ability to research, and time to invest in both). For this one doc at least, the idea isn't to give someone an all inclusive summary of the best way to use ZFS on UnRAID overall, but to spark that something that gets them into the game if they read it and find themselves thinking 'this could've saved me hours last week on X, I wonder what else it can do...' I do give more explicit detail where possible though - for instance, postgres has it's fileset configuration laid out, with explanations of why. for each, same as I hope to continue to do with each other app as I find time to get them translated from my deployment notes to the docs github. I mentioned there's precious little I'd say applies globally, but that which does boils down to: atime = off compression = (at least something more than 'off' - again, whether to use lz4 or zstd still kinda depends, as if someone were using the old Westmere or Nehalem procs, lz4 is probably it for them) Everything else has sane defaults for most systems, with recommendations for specific deployments needs... I'm sorry in advance - I know this isn't super helpful in and of itself! I just hope my reasoning on why I did it this way makes some kind of sense at least!
-
This sounds like a DB or data consistency issue, especially given it happened after (I assume you had to do a hard reset) reboot. Have you tried restoring a backup and starting the container pointing to that backup (restoring both the DB and the nextcloud appdata being a requirement here as both are dependencies), and if so, does it fail at the same point? If it does, I'd start looking into methods to verify the integrity of your database, as well as the troubleshooting documentation from nextcloud re: their appdata dir and DB indices.
-
Have you checked permissions for the files it's specifying issues accessing? Confirmed that the container is running as that expected user account?
-
Pull up the container's console and check the available storage from the container's side - just 'df -h' will show you something like: Filesystem Size Used Avail Use% Mounted on overlay 80G 30G 51G 37% / tmpfs 64M 0 64M 0% /dev tmpfs 24G 0 24G 0% /sys/fs/cgroup shm 64M 0 64M 0% /dev/shm shfs 91T 61T 30T 68% /data If nothing there's showing near full, do the same from your unraid terminal. Depending on what's full, it may be as simple as a restart of the container, up to possibly remounting a tmpfs volume with a larger capacity specified - whatever the case, finding out what's full should give you the breadcrumb trail needed to research and correct it. If nothing is legitimately showing 'full', I'd increase the nextcloud logging level and reattempt. Edit - assuming you've verified you've got all your array disks set to available to the share mounted to the /data dir of course, though I'm sure you've covered that lol. Doesn't matter how much free space you have in the array if the nextcloud containers share isn't allowed to use em all hehehe
-
@Partizanct (and @Marshalleq if you're interested of course, more the merrier!) would you have time to give this a once over? Why would we want ZFS on UnRAID? What can we do with it? This is much less a 'technical thing can technically be done X way' doc than a 'here's why you might be interested in it, what problems it solves, and in what ways'. Given this, and that those types of reference material can often be interpreted numerous differing ways by different folks, I just want to make sure it's at least coherent, without going so deep into the weeds that someone newer to ZFS would just click elsewhere after seeing the encyclopedia britannica thrown at em as their 'introduction' lol. Open to any and all feedback here - again, this isn't supposed to get super technical, and has a unique goal of explaining why someone should care, as opposed to the rest of them which go over how to actually do the stuff once you've decided you * do * care enough to put forth the effort, so there's no such thing as 'bad' or 'useless' feedback for this type of thing imo. Anyway, thanks for your time!
-
114k tracks, you friggin MONSTER YOU!!! I'm super interested in taking a look at this, it sounds like an exciting challenge to me 🎉. Maybe start by getting some measurements to quantify the slowness, just something you can easily reproduce (like 'when I go to the activity page, it takes X seconds to load', stuff like that), then incrementally test a few things to see what we come out with. When you say super slow with operations... Are you using lidarr extended, referring to those scripts maybe, or do you mean the basic lidarr maintenance stuffs? With that many tracks, what's your sqlite DB size? ~2GB or so maybe? At that size.. Man, there's a bunch of additional stuff to think about - the WAL size, the compile time parameters for max pages before a checkpoint, hell, even the option to cache all instead of metadata only as an option of last resort lol. Few starting points: 1. You want to vacuum that sucker regularly, especially after mass media changes - I'd start with this, especially if you've never done it before. With the container stopped of course, but just cd to the dir then - "sqlite3 lidarr.db VACUUM;" 2. Definitely try the txg modification from the postgres side of things - as long as all your pools are redundant (z1/z2/z3/mirror) make the change, then start the container and evaluate. - "echo 1 /sys/module/zfs/parameters/zfs_txg_timeout" 3. In order to avoid NUMA issues, use lstopo, then pin the container to *just* one numa node worth of cores - at the very least, ensure only one CPU can operate the containers threads. Otherwise, you're certain to hit a significant IRQ penalty due to context switching... With the lidarr devs choosing to compile sqlite with the default variables (and hence, the db parameters set upon creation time are 'sqlite default'), we get hit multiple times by constraints that simply don't account for such massive DBs. For example, the default max number of pages prior to checkpointing the DB (a very 'expensive' operation) is 1000, and with a maximum page size limit of 64K, that means every 64MB worth encounters a checkpoint. Assuming you're at ~2TB, you've got a minimum of ~30 checkpoints if you were to 're-write' the database, which is bonkers. That's probably about as much as I'm comfortable recommending without actually looking at the thing - everything from modifying the zfs dataset to remove sa xattr and go back to posixacl (they do have the potential to incur a performance penalty, and arent necessary if you never access the data outside of the terminal shell of your unraid server - and I mean 'ever', so please, anyone else reading this after the fact, please leave xattr to sa unless you know you know better!) to throwing the database in a dedicated zvol, on down to crazy stuff like recompiling sqlite3 within the container image and rebuilding the database with new parameters to allow us to modify things like the sync behavior, that checkpoint option mentioned above, and a bunch of others, they're all on the table 😁 Anyway, just lemme know if you try any of the above what the outcomes are like, and/or if you'd eventually like to take me up on the second set of eyes; you can probably tell, but I'm eager to take a whack if you end up being game for it hehehe. _____ ioztat is basically 'iostat, but at the zfs fileset level' - super helpful when trying to track down latency issues especially. I briefly touch on it here _____ As for the variable page size - this is absolutely true. However, there are a lot of other factors at play here as well - for instance, as you rsync'd the data in bulk, that data wrote everything in 64K chunks because it had 'one big-ass file' (your lidarr.db file) to write at once, so it was able to fill those 64K blocks you set the lidarr fileset to use (also resulting in 'right after the copy, it was the most performant it'd ever be with these settings' by proxy). On top of that, the extended attributes of the file itself can be anything from 255 bytes up to 64KB in linux, so if we have xattr=sa, each file we've got extended attributes for has this linux metadata (which zfs thinks of as 'just data', and has it's own metadata for as it's contained within the file itself now), and *that* almost certainly won't be a full block... My one concern here with the rsync is if those pages don't line up block-wise with the records written. Correcting this is as easy as vacuuming the db though, so the above options will cover that 👍 Anyway, this topic could get super long. Suffice it to say 'what you've read is very much true, but is wicked easy to take out of context, and often is taken as such by otherwise trusted online sources' lol.
-
Keep in mind, while filesets can be renamed (and hence, their directory structure changed) on the fly, the existing data will still have been written in the prior fileset configuration. If you change things like recordsize, xattr, anything about the data itself, you'll need to copy the data off/back (or send to a new fileset with those parameters) in order to apply that configuration to the data (only applied at the time of write). ... I think I'm going to write a doc going over some more generalized zfs information at this point. I'd resisted the urge, as there are a couple detriments in my mind to doing so: 1. ZFS, while powerful, isn't for everyone - one has to have the desire/drive (and just as importantly, the TIME) to do some of their own background research and learning, or it's super easy for them to have a much worse experience with zfs than alternatives (or worse yet, cause themselves massive suffering by copy/pasting something they saw online ) 2. There's already so much out there on the basics, adding more stuff to the main page could mean that people just skip reading anything there altogether - if there's a short 'here's what you need to learn further', I feel like it's more likely to be read than if you add more than is absolutely necessary. Both of these things though I think aren't necessarily going to be a problem here - I was helping out another fellow forum member with some nextcloud issues where I'd asked if he'd be interested in proof-reading some of it for me once I got the time to write it, and he seemed amicable to the idea (we got his data back, AND his nextcloud instance running again - WOOOT!!). I just didn't know how useful it would be... But it sounds like there would be enough use to serve a purpose at least ❤️
-
Did you copy the data out and then back over after setting up the fileset? And what part of lidarr is slow - e.g. is it just general browsing, or looking at a specific set of pages? Could you share your zfs get output for lidarr, and maybe check the output of ioztat as well to see what it's IOPs usage is like? Finally, how many songs+artists are we talkin? I think you might be talking about the dnode size setting (re: variable records) - this is something I haven't covered in the guides/docs yet, but maybe I should... You may also be talking about how it treats multiple inodes from differing objects when writing a record though, not entirely sure. I could take a look with you at some point if you'd like (we can get a webex going or something after taking this to DMs) - I wonder if maybe you're hitting a frequency limitation (single threaded for sqlite, so boost speeds are important). You might also disable the zfs txg timeout value I'd noted in the postgres guide; it'll help with anything DB related, but should only be used if all zpools on your system are redundant (no stripe only pools). If this doesn't clear it up (it can be unset after the fact, it's a kernel level change), I'd want to start looking to see what our interrupt counts are like during slowness periods, arc hit rates, and so on. There's no reason a 1950x shouldn't be able to make lidarr with sqlite at least usable, even with ~40k songs (that's how many I've got currently at least, so it's the most I could comment on for now). Just lemme know - it sounds like audio's a pretty big deal for you, would be happy to poke at it a bit with you if you like, maybe get a better experience out of it for you.
-
I actually do that in the guides, setting up the recordsize and explaining why it's set to what it is - equally. important for the sqlite applications (like the 'arrs), where we set the page size to the max (64k), and configure the fileset to match. Only way to make sonarr history viewing any kind of performant with 10's of thousands of shows 👍
-
I tried to allude to this in the guides themselves by first noting the fileset specifications recommended for that given application, but I guess it may not've been clear - I use a specific fileset for each application. Not only is this the only way to actually tune zfs for each individual application (as you're applying filesystem level features specific to those applications), but it's also the only way to fully take advantage of the snapshot and backup features in a meaningful way - this way, you can apply specific snapshot requirements to your dbs that you don't necessarily need for your more static applications. As a for-example, I've attached my zfs list output; filesets natively inherit the settings of their parents, so if you've a bunch of apps which have similar requirements, you don't have to keep manually setting them each time. My 'static-conf' filesets, which are almost never changed, the 'vms' fileset, which has all img files, etc, then just customize the few small changes needed for the others (...speaking of which... reminds me I need to move postgres over to wd/dock/dep - where all my databases [dependencies] are lol):
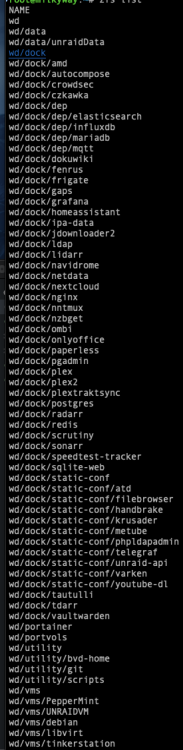
-
If you apply the sqlite tuning, I'd argue that postgres isnt really required. Even with all the media I've stored, everything loads in less than a second after applying the tuning, along with the benefit of having all the containers data in a single location. To me, the added complexity isnt worth the negligible benefit (Not to mention the additional request load on PG that could be used for other more intensive applications such as nextcloud).
-
Did you both go through the guide to optimize sqlite? None of the 'Arrs actually need postgres IMO, excepting possibly lidarr.
-
I use postgres as the application database for everything that both supports (and actually needs) a full fledged DB actually. What do you mean?
-
Happy to help! I've been at a cabin with limited connectivity the last 3 days or so, but am returning to civilization tomorrow and have a couple more days worth of updates planned, so hopefully there'll be a bit more somewhere within the updates thatll help with some other parts of whatever you're workin on as well 👍
-
Your PHP tuning needs to be 'compatible' (for lack of a better term) with your database tuning - if, for instance, you allow 200 php processes, but only allow 100 DB connections in your DB config, nextcloud will complain. In addition, one tuning variable within postgres.conf can impact another - the paragraph directly following the postgresql.conf sample variables has a brief explanation, where you have a total number of worker processes, maint processes, and allocations of memory each, which should be less than or equal to your shared buffers. You'll want to check out the postgres config reference linked in the guide for full explanations of each of the options and their impacts. The database tuning information is in the respective DB's page, linked from the main page above - the postgres one is more complete at this point, as it's what I've primarily used for anything that needs a database for many years, while my MariaDB/MySQL experience is strictly relegated to working on other's environments (so I don't have everything already written up for it to just copy from my deployment notes).
-
This is the reason I use the pre/post scripts capability of sanoid and stick with zfs snapshots. Qemu has the ability to quiesce the VM which you do in the prescript section, snapshot occurs, then post-script to resume normal operations. Edit: Just to be clear, I do something similar to this to ensure my snapshot's consistency. It *is* still only crash consistent, which is the reason all my "complex" applications (databases etc) run in docker containers - I then have the granularity to individualize the pre/post scripts to the specific applications needs for application consistent backups via snapshot.
-
<RESERVED>
-
Cross-posting here, as I finally made some progress on documenting some ZFS on UnRAID performance related stuff I'm using my vacation week to work on some of this as a passion project - hope it's found to be helpful by some, and just note, it'll continue to grow/evolve as time allows 👍
-
I posted what I hope to be a single place to reference for performance related tuning/information over in the guides/general section which had a couple pieces I thought were applicable, so I figured I'd cross post the relevant bits here - it goes into a great deal of the performance tuning one might wish to undertake with LSIO's Nextcloud+Postgres+Nginx containers, and I'm posting here in hopes that it can help some folks and reaches the right audience: Postgres - My recommendation for nextcloud's backing database - guide to keeping your applications performance snappy using PG to back systems with millions of files, 10's or even hundreds of applications, and how to monitor and tune for your specific HW with your unique combination of applications Nextcloud - Using nextcloud, onlyoffice, elasticsearch, redis, postgres, nginx, some custom cron tasks, and customization of the linuxserver container (...and zfs) to get highly performant app responsiveness even while using apps like facial recognition, full text search, and online office file editing (among many others). I've collaborated some with the Ibracorp folks on their work towards an eventual nextcloud guide to help with some performance stuff, along with my notes as something of a 'first draft' for their written version, so hopefully there'll be something of a video version of this eventually for those who prefer that. Haven't finished documenting the whole of the facial recog part, nor elasticsearch. Just for some context: I've migrated my entire family off of google drive using nextcloud, including my dad's contracting business and my wife's small wfh custom clothing shop, have about 1.1m files across 11 users (all of which are doing automatic phone photo and contacts backups) and 16 linked devices between phones and computers, and 17 calendars - the time for initial login page is less than a second, and scrolling through even the photos in gallery mode is almost instantaneous. Super impressed with the Nextcloud dev's work!!!
-
Hello All! As I'd alluded to in my earlier SR-IOV guide, I've been (...slowly...) working on turning my server config/deployment notes into something that'd at least have the opportunity to be more useful to others as they're using UnRAID. To get to the point as quickly as possible: The UnRAID Performance Compendium I'm posting this in the General section as it's all eventually going to run the gambit, from stuff that's 'generically UnRAID', to container/DB performance tuning, VMs, and so on. It's all written from the perspective of *my* servers though, so it's tinged with ZFS throughout - what this means in practice is that, while not all of the information/recommendations provided will apply to each person's systems, at least some part of them should be useful to most, if not all (all is the goal!). I've been using ZFS almost since it's arrival on the open source scene, starting back with the release of OpenSolaris back in late 2008, and using it as my filesystem of choice wherever possible ever since. I've been slowly documenting my setup as time's gone on, and as I was already doing so for myself, I thought it might be helpful to build it out a bit further in a form that could be referenced by others (if they so choose). I derive great satisfaction from doing things like this, relishing the times when work's given me projects where I get to create and then present technical content to technical folks... But with the lockdown, I haven't gotten out much, and work's been so busy with other things, I haven't much been able to scratch that itch. However, I'm on vacation this week, and finally have a few of them polished up to the point that I feel like they can be useful! Currently guides included are (always changing, updated 08.03.22): The Intro Why would we want ZFS on UnRAID? What can we do with it? - A primer on what our use-case is for adding ZFS to UnRAID, what problems it helps solve, and why we should care. More of an opinion piece, but with some backing data enough that I feel comfortable and confident in the stance taken here. Also details some use cases for ZFS's feature sets (automating backups and DR, simplifying the process of testing upgrades of complex multi-application containers prior to implementing them into production, things like that). Application Deployment and Tuning: Ombi - Why you don't need to migrate to MariaDB/MySQL to be performant even with a massive collection / user count, and how to do so Sonarr/Radarr/Lidarr - This is kind of a 'less done' version of the Ombi guide currently (as it's just SQLite as well), but with some work (in progress / not done) towards getting around a few of the limitations put in place by the application's hard-coded values Nextcloud - Using nextcloud, onlyoffice, elasticsearch, redis, postgres, nginx, some custom cron tasks, and customization of the linuxserver container (...and zfs) to get highly performant app responsiveness even while using apps like facial recognition, full text search, and online office file editing. Haven't finished documenting the whole of the facial recog part, nor elasticsearch. Postgres - Keeping your applications performance snappy using PG to back systems with millions of files, 10's or even hundreds of applications, and how to monitor and tune for your specific HW with your unique combination of applications MariaDB - (in progress) - I don't use Maria/MySQL much personally, but I've had to work with it a bunch for work and it's pretty common in homelabbing with how long of a history it has and the dev's desire to make supporting users using the DB easier (you can get yourself in a whole lot more trouble a whole lot quicker by mucking around without proper research in PG than My/Maria imo). Personally though? Postgres all the way. Far more configurable, and more performant with appropriate resources/tuning. General UnRAID/Linux/ZFS related: SR-IOV on UnRAID - The first guide I created specifically for UnRAID, posted directly to the forum as opposed to in github. Users have noted going from 10's of MB/s up to 700MB/s when moving from default VM virtual NIC's over to SR-IOV NICs (see the thread for details Compiled general list of helpful commands - This one isn't ZFS specific, and I'm trying to add things from my bash profile aliases and the like over time as I use them. This one will be constantly evolving, and includes things like "How many inotify watchers are in use... And what the hell is using so many?", restarting a service within an LSIO container, bulk downloading from archive.org, and commands that'll allow you to do unraid UI-only actions from the CLI (e.g. stop/start the array, others). Common issues/questions/general information related to ZFS on UnRAID - As I see (or answer) the same issues fairly regularly in the zfs plugin thread, it seemed to make sense to start up a reference for these so it could just be linked to instead of re-typing each time lol. Also includes information on customization of the UnRAID shell and installing tools that aren't contained in the Dev/Nerdpacks so you can run them as though they're natively included in the core OS. Hosting the Docker Image on ZFS - squeezing the most performance out of your efforts to migrate off of the xfs/btrfs cachepool - if you're already going through the process of doing so, might as well make sure it's as highly performant as your storage will allow You can see my (incomplete / more to be added) backlog of things to document as well on the primary page in case you're interested. I plan to post the relevant pieces where they make sense as well (e.g. the Nextcloud one to the lsio nextcloud support thread, cross-post this link to the zfs plugin page... probably not much else at this point, but just so it reaches the right audience at least). Why Github for the guides instead of just posting them here to their respective locations? I'd already been working on documenting my homelab config information (for rebuilding in the event of a disaster) using Obsidian, so everything's already in markdown... I'd asked a few times about getting markdown support for the forums so I could just dump them here, but I think it must be too much of a pain to implement, so github seemed the best combination of minimizing amount of time re-editing pre-existing stuff I'd written, readability, and access. Hope this is useful to you fine folks! HISTORY: - 08.04.2022 - Added Common Issues/general info, and hosting docker.img on ZFS doc links - 08.06.2022 - Added MariaDB container doc as a work-in-progress page prior to completion due to individual request - 08.07.2022 - Linked original SR-IOV guide, as this is closely tied to network performance - 08.21.2022 - Added the 'primer' doc, Why ZFS on UnRAID and some example use-cases
-
@stuoningur Finally had some time to sit down and type - As I was doing some quick napkin math though thinking about your situation today, some points on the test setup/config: 4 disk raidz1, so 3 'disks worth of IOPs' rough rule of thumb is 100 IOPs per HDD in a raidz config (varies a lot more than that of course the default block size of 128k means 'each IOP is 128k' 128KB * 3 disks * 100 IOPs, equals ~38MB your test was for 256k block size, halving the IO - which results in our ~20MB/s Outside of the above: Confirm your zpool has ashift set to 12 zfs dataset. Nearly all newer non-enterprise drives (ironwolf being the SMB/NAS market instead) are 4k sectors (w/ 512b emulation). Huge potential overhead depending on the implementation, and really no downsides to this, so it's win/win. Lots of good background information on this out there for further reading if interested Check your zfs dataset's configuration to ensure it's a one-to-one match for what you're comparing against - Wendell did his tests without case sensitivity, no compression, etc Validate your disk health via SMART, ensuring no UDMA/CRC/reallocated sectors/etc are being encountered (which could easily contribute to hugely reduced performance Ensure the system is completely idle otherwise at the time of the test And finally, validate your hardware against the comparison point - Wendell's system had a 32GB l2arc, so the point about ensuring the file tested is bigger than the l2arc miiiiiiight've been one of those 'do as I say, not as I forgot to do' kind of things (he's a wicked busy dude, small misses happen to us all! However I don't think that's the case here, as ~45-60MB/s per drive for a 4 disk z1 is actually pretty average / not exactly unheard of performance levels) Assuming the config 100% matches (or at least 'within reason'), the rest is unfortunately just going to be going through those steps mentioned earlier, ruling out one by one until the culprit's determined.
-
Likely a permissions issue with the location - should have "drwxr-xr-x" perms for the nextcloud appdata dir, and if running as PUID/PGID 99/100, then ownership of that directory should be "nobody:users". If that's not the case, I'd correct the permissions and re-attempt, ensuring as little customization as possible (e.g. use the built in database to trial it, and if this works correctly, then the issue is likely related to whichever DB/web proxy container you're running).
-
@SliMat I'm mobile right now so cant 100% validate the specific log locations, but you should hopefully be able to find them pretty easy with a bit of googling for it. From the container side of things, I know nextcloud has a support diagnostic bundle that it can collect as well... but if I recall correctly, I think it included significantly more sensitive info than I'd feel comfortable asking you to post up here (not like "oh you're hacked now!1!!1!!" sensitive, but more local connectivity details, user account addresses, things like that). We could always move to DMs or something in that case? Up to you. As an alternative (or maybe in parallel with, up to you!), I could probably swing some time today to do a remote session together and I can help you poke at it a bit. I'm normally so starved for time that I couldnt afford to read an email notification (lol), but I'm on vacation this week and times a luxury I can finally afford (for a bit anyway hehehe). If you're willing to put in the work necessary to learn + self-teach/research + possibly a little additional coaching, I'd be happy to invest some time in helping you do so. (I should be back to the house around 1400-1500CT just for awareness in the event you wanted to take me up on a second set of eyes on it)
-
Before anything further, I'd want to check a couple of the files (rename to proper extension and open in whatever application uses that ext). Are the files indeed safe and accessible? Whatever it takes, make another copy of the data once that's confirmed - whether it's a usb thumb drive, heck even an old blank dvd if it comes to it.... just something *OFF* the array in case its eventually found to be the cause. Once you have a safe, secondary, non-array dependent (an unassigned drive would technically be alright, as long as it's not something related to memory/segfaults), then we should start looking at the /var/log messages for the host, spot check a couple file's ACLs to make sure they've not gotten bent out of shape, and compare the host logs with nextcloud and (whatever you're using for RDBMS - maria/mysql/postgres).




