




BVD
Members
-
Joined
-
Last visited
Everything posted by BVD
-
In the sane vein, I'd like to see the 'unbalance' feature brought in to core unraid - the ability to choose at will where you'd like a given share's files relocated to. As my storage needs have grown more and more complex, I find myself having to jump through some pretty significant hoops to get data moved around as I'd prefer it.
-
They review them fairly regularly, though I suspect they may not respond until they've something of a concrete answer. The way I handle consistency on the array is mult-pronged - Short SMART tests are ran every other day, long tests bi-weekly Running a container called Scrutiny which provides a dashboard for disk health Array parity checks monthly Notifications sent to my phone should there be an error here The Integrity plugin to validate the data on disk matches whats expected It calculates the hash of each file and stores them, then on later runs of the has calculation, generates a notification if the hashes no longer match for whatever reason My expectation is that, if you'd ran a parity check (either manually, or via schedule, you'd have been notified then of the issue. I agree that this is less than ideal in that you'd have the added delay of (however long it is still your next parity check), but at the very least, there is *some* form of check there... I do wish a lot of this was part of the base OS, some kind of sane defaults, then let us change what we want. The fact that there's actually no default schedule for running SMART tests against drives (nor any method to schedule them in the UI actually) is something of a black eye here. I guess I never really thought about it too much, I just kind of 'set everything up', but looking back on it now at least... A lot of this really should be part of the base functionality for *any* NAS OS imo.
-
I'm betting they mean 'without stopping the array' - I agree that it's something that's sorely missing, and the primary reason I no longer use unraid for anything where uptime is paramount, but with how the parity writes are designed to be handled, pretty sure it'd need a complete rewrite to support this unfortunately 😞
-
Might get a better response from the Hardware subforum - this one's for completed builds, so I'm guessing most of those who might have input simply wouldn't see this here 👍
-
@neuernick @andyb216 @tchmnkyz please feel free to upvote the feature request here - it'll get more visibility there 👍
-
That's also expected - watching the filesystem isn't free, for sure! Pretty rare it'd take 1KB/watcher though.
-
Pretty normal. Anything you have that 'watches a directory for changes' will add to this list - Plex, Tdarr, Sonarr, NZBGet/SabNZB, Radarr, etc. In the end, it's just a number, albeit one that's useful for keeping the number of disk spinups down.
-
@Ford Prefect Not a replacement really, but I use netdata for this - having it graphed over time is significantly more useful than raw stats IMO. I don't keep it running indefinitely as it's honestly a bit of a pig when it comes to resources for a monitoring application, but it collects stats by default every 5 seconds, amounts to a one-click deployment, and allows me to quickly visualize the impact of changes I've made. Then once I'm done tuning, shut it down and go back to relying on grafana+influx+telegraf for longer term stats. You can configure it to keep data for as long or as little as you'd like - personally, I'd keep it as a tuning tool as opposed to a longer term record of activity though. Small subset of the data it shows below, as I've been playing with some tuning for SMB today:
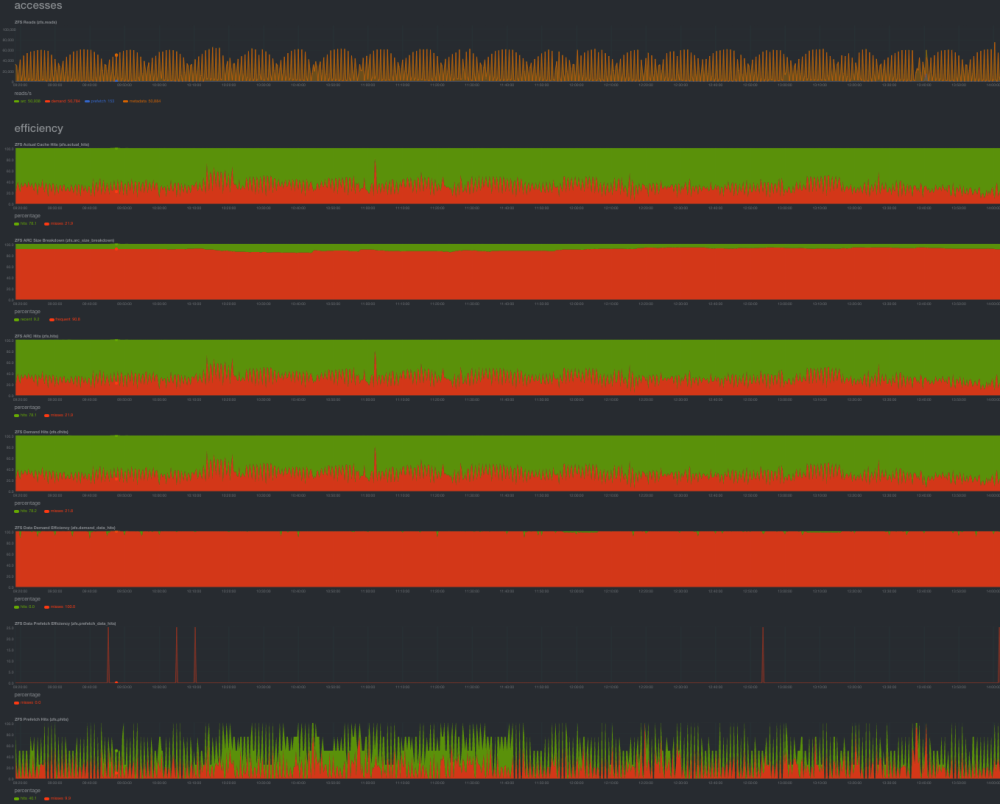
-
@SimonF been a while since I logged in, gotta update my notification settings! @mocakong this is exactly the kind of thing device pass-through and SR-IOV are designed for, but neither of your devices support SR-IOV - this limits you to either working with VLANs (passing through one of the two NICs, setting a native VLAN for the WAN connection, then tagged VLANs for everything else in the LAN to communicate with router OS), or buying another NIC. You can find suitable NICs quite cheaply these days, and SR-IOV means you don't have to dedicate two ports fully to the VM; you can find some steps on this here.
-
Pretty sure its @ich777tthat maintains the build automation for it, unless I misread at some point?
-
Ever since the nerd/dev packs went the way of the dodo I've just set up mirrors for all the tools I've ended up using and compiled my own, so while I'm not really certain anymore where the slackware stuff is, you can just build from source instead: https://git.kernel.dk/cgit/fio/ If you want to avoid mucking around with the hypervisor, you can always use a container of course. I pushed up a little container to github that I've used in the past in such situations in case it's helpful - just clone the repo + build, then run the command noted: https://github.com/teambvd/docker-alpine_fio Just be sure you've cd'd into the mountpoint path for your SMB share prior to running to ensure the test is valid 👍
-
Not OP, but my use-case for seemingly 'crazy' amounts of NAND is CockroachDB - I used it to basically create a blobstore (sort of a distributed filesystem across multiple servers) so the services could survive a complete server failure/crash. As you can imagine, such a thing is highly latency sensitive, NAND (but most especially optane) is perfect for this stuff.
-
@levelel I don't have an iGPU to test, and am unsure whether sysfs supports active repartitioning of these devices. For an iGPU, I really don't see the use case for it either, so it simply may not exist, not sure. They're not scale-type devices, and I somewhat doubt that development effort was expended creating options for things such as variable partitioning and the like. Should just be a 'set it and forget it' configuration, and since there (likely) isn't much of a business case behind regular reconfiguration, I'd just stick with the PCI device tree method. Understanding nobody likes to reboot if they don't have to of course, in this case, you just do it once on initial system setup, and never have to think about it again.
-
@ensnare before diving too deeply into the configuration, my recommendation (as @JorgeB alluded to above) would be narrow down the source a bit (confirming this pool was originally created on scale (not core) as well would be useful). Can you go over what testing you've done so far to better pinpoint this? In general, assuming you've done nothing yet, a good start would be: Do you experience the same throughput with a generic IO stream? I'd use an extended FIO run with fully randomized IO bypassing the L2arc to start (don't expect it's storage related, but doesn't take much time, and rules out a ton of other junk), then hit it with bi-directional iperf as well, and finally nfs. Assuming you see 900+ MB/s for each of the above, THEN you can start focusing on SMB. You've a ton of additional config's added for samba, so I'd first try commenting all those out and simply copying a file over, then see what (if anything) changes to get a better idea on what direction to take this. Is *all* SMB traffic equally impacted, regardless of which host/application is attempting to write? Are read requests similarly impacted? Really the biggest thing here is to do some troubleshooting to narrow the focus of your analysis/investigation. If you could share what you've already done on that front, it'll probably help us give you a better idea of where to go next.
-
Well, if you wanna double down on it, you could just integrate this: https://github.com/mikesart/inotify-info Builds perfectly on unraid inside of 5 seconds lol Thanks so much for the work you continue to put into these quality-of-life-like additions - it's hugely appreciated, and truly fills out the ecosystem ❤️
-
I've found myself repeatedly sending folks the command below to run on their servers while trying to help them track down things like random disk spinup, and wondered if we might add the it to the help section for the "Max Watches fs.inotify.max_user_watches" section? It's a simple one liner that gives the total current watchers in use: find /proc/*/fd -lname anon_inode:inotify | cut -d/ -f3 | awk '{s+=$1} END {print s}' I suppose it could instead have something within the plugin that just runs the above and displays it as 'currently used watchers' or something as well, but that'd take a bit more doing, so I figured I'd go for the low hanging fruit here 😅 Or if you've got a better way to get to the info (or perhaps a more reliably accurate one - the number changing constantly can make it hard for folks to nail down as new pids spawn/die), I'm all for it of course! Just figured an easy way for folks to check this being on hand in the tool would be cool. Thanks for all your work to better the UI experience @dlandon!!
-
It's all networking at that point - Firstly, only virtual functions should be used (mapped) if using SR-IOV - ensure that each machine needing to communicate on the network has both a VF attached, and a valid network address assigned to them. Confirm they're able to communicate by checking your router's IP assignments for the associated MAC addresses. Make sure the hostnames, MAC's, and IP's you see from the router line up with what is shown on the clients themselves as well. It's likely your router has a DHCP lease for the MAC that's not yet expired attaching that MAC to the previous device, and if that's the case, simply expire the lease. You can always manually assign static IP's on the router/DNS side to ensure you don't have to worry about this in the future should you need to do so.
-
What's your upload bandwidth like, and what's your system/container load look like when you're doing this scrolling? You're either dealing with limited upload, or more likely, resource starvation of the nextcloud container as it's trying to generate the previews on the fly. If you've sufficient bandwidth, then I'd look at running preview pre-generation and ensure the previews are all stored on SSD. If still encountering issues after that, I'd first verify that all available cpu cores are pinned to the container other than threads 0 and 1, as well as increase the shm size to whatever you can afford to allocate to it.
-
NH3 is just the "app store" of NC 25, which is currently in RC and not quite ready for broad scale deployment. You'll have it as soon as you upgrade. If you're in a rush, switch to the beta branch - dont trust your data to it though, back up and test recovering from that backup prior to upgrading.
-
It's really not a bad case, and Silverstone is just about the only non-server chassis option out there these days if you want true externally accessible hot-swap built in. Kinda crazy, used to be dang near every vendor had at least SOMETHING in that vein. Most of the issues can be fixed for almost $0 - some scissors, a little packing tape, and some plastic to build the ducting, and the built in fans can even do alright. Now if you've got a high TDP CPU and are running multiple pcie cards though, you're going to want some higher end fans regardless. The problem I had with it is the replacement parts - my systems are on 24x7, and there are folks depending on their remaining operational that entire time. The backplane looked pretty cheap (caps literally wiggling at the slightest touch), and the drive trays tend to deform pretty easy, so I'd tried to buy spares... only to find they wouldnt consider it unless I'd had a failed one to show them. Given the uptime needs, I just went all supermicro for the builds following. The chassis is still living a good life, over at a friends house in GA as of last month acting as his main server, and an off-site backup for me. I still recommend the chassis even, especially for the more typical use-cases of forum members here. It just wasnt fit for my purpose/needs.
-
That just doesnt make sense to me 😳 - I spent some time the weekend before last trying to recreate the issue (so I could un-screw it I mean), and it all "just worked"... then last weekend I'd tried messing with various combinations of other apps being installed to see if there was maybe a tie-in index messing with us (like oauth2 of ldap), but again, no dice, everything kept doing exactly what I expected 🤬 ... in any case, I'm glad you got it sorted! Just sorry I wasnt able to help more lol
-
One other thing immediately comes to mind - you're mounting you're zpool directly in /mnt, right? If not, do that and re-test - putting zfs inside the virtual directory unraid uses to merge the disparate filesystems of multiple disks introduces a massive number of unaccounted for variables, and even unraid itself doesnt directly mount physical filesystems directly on top of virtual ones.
-
Just letting you know, I've not forgotten about this, hoping to make it back tonight and look further following 👍
-
Restore backup, then update via CLI would be your best bet - save you from hitting timeouts incurred by the UI updater 👍
-
8@elco1965agree - traveling currently, I'll take a deeper look once freed up




