




BVD
Members
-
Joined
-
Last visited
Everything posted by BVD
-
@SimonF fantastic looking work! I'm watching the PR, looks like a super clean implementation 🙌 One thing to add that might be nice once the initial is merged would be to also show the %complete in the UI's tray at the bottom of the screen, similar to how parity checks are reported there. Doesn't need all the detailed info IMO, just that it's active when active and the percentage value, at least that's my thought anyway... Keep up the great work, and thanks!!
-
I'm assuming you tried all the other steps first, correct? Did the repair / occ steps above all come through clean? Manually editing the DB should be a last ditch effort, and youd likely want to walk through the totp plugin dev information to ensure that's handled properly- it's almost a certainty that theres fields in other tables which are reliant upon that one, and thatd be the easiest way to locate them with any certainty (imo anyway) unless others have documented the steps previously.
-
It's trying to execute a .txt file as a service? A reader no less? Seems weird. You open up the read readme to see what its saying/doing? Assuming you checked permissions already of course (and that the answer isn't just the readme contents), I'd hit up the github and look for other reports; this thread has mostly become a more generalized nextcloud applicarion support thread over the last year or two, while the repo is specific to the containers implementation of NC (and this is a container issue, based on the description at least).
-
You're going to want to step through nextcloud's documentation regarding database maintenance/repair - it's possible the version of the totp plugin youd previously used was older than the current one, or that theres another mismatch between versions of dependent applications (before the wipe vs current). In either case, the application isnt seeing what it expects from the DB. I'd first try the `maintenance:repair` command they've documented, along with verifying the indices are all there (should be an `add-missing` option documented in the same place). If that still fails, I'd check your logs to validate what version you previously had installed and then manually remove/clean up the current TOTP package, replacing it with that specific version from github. EDIT: Just thinking about this more, its relatively likely that the above will fail... in which case your only remaining options would be to A. Try disabling the totp provider from the cli, and if successful, then reinstall. If that gives you an error... B. Add missing primary keys (it's another db:add-missing blah blah type deal) C. Manually run the db migration to bring the DB schema up to date - think it's something like "migrations:migrate totp", something like that anyway - should be able to find it in nextclouds dev docs. D. Last, and certainly most drastic measure: Manually drop/delete all totp related tables from the DB, then reattempt install. Should go without saying, but make sure you've a solid backup first, and before attempting any of the above, enable maintenance mode.
-
Databases have specific schema requirements, often necessitating a dump/restore as part of their update process - I'd recommend researching your specific db container's update process in order to correct this after rolling back your DB container image to the expected/previous version and restoring a backup of your nextcloud+db instances. Additionally, you never want to restart a DB container without first stopping any container which relies upon it for it's metadata/storage. Doing so is similar to pulling the boot drive from an active Windows machine - it may be fine after, though depending on it's in-memory state at the time, it may become corrupted. Once you've restored your backups/container image(s), you can walk through the container update process for your DB.
-
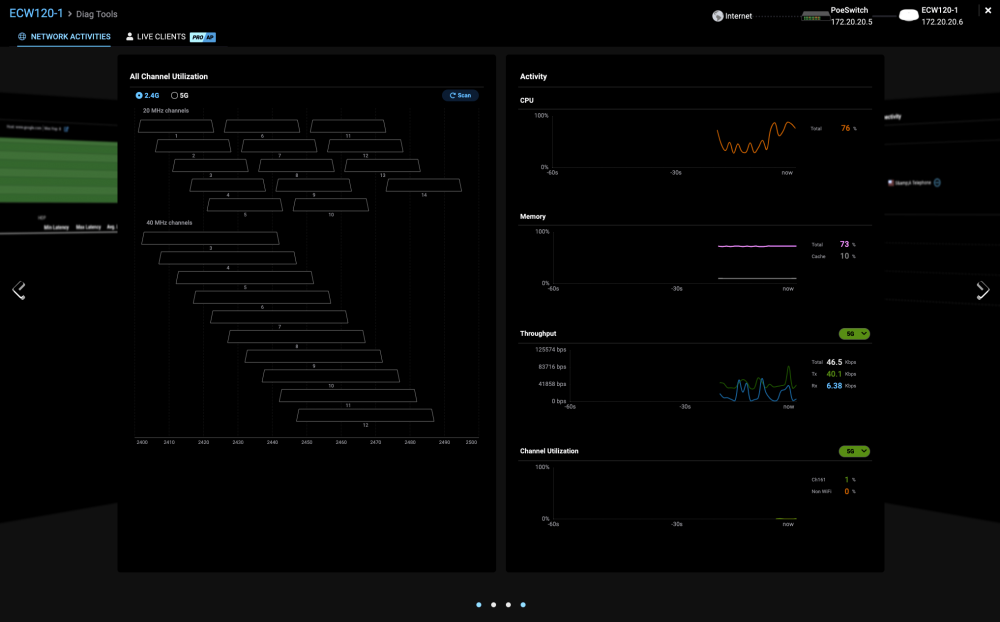
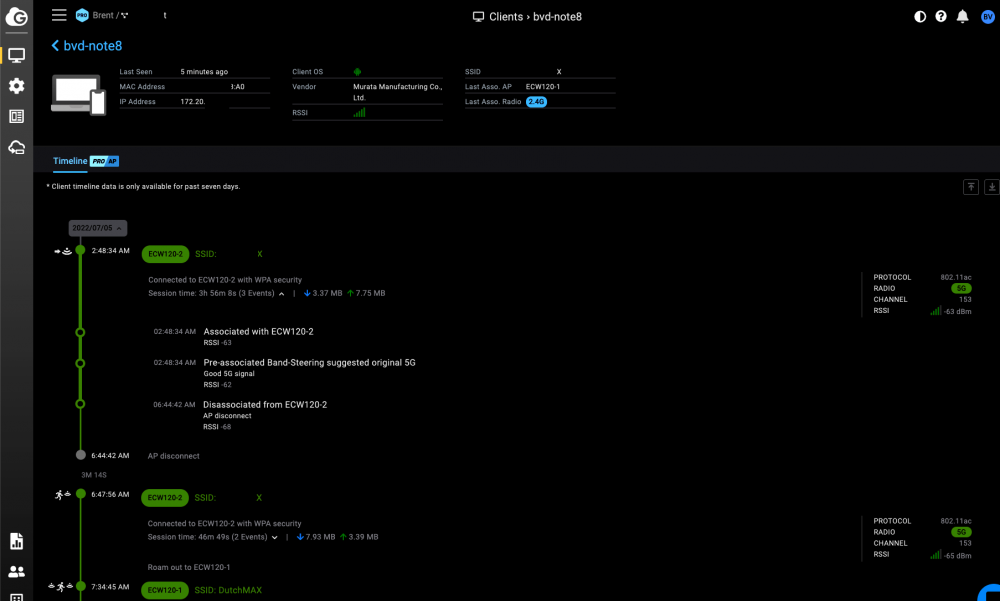
Glad you found it helpful! The Intel AIC is a P3520 - very oooooold... But especially good at 4K reads. I've stopped using it as my write cache, instead opting to use it for the docker volume and for some work backup appliance's boot drives that just consume massive amounts of space - basically just things that need the best random 4K read performance possible, but that I don't care about losing. I picked it up for something like $150 I want to say close to 3 years ago now, and it ended up not being a large enough cache, so I watched ebay till a good enough deal came along that I couldn't pass it up; 4TB micron 5100 pros for all of 250 bucks! They had no history associated with them, and this was at the height of chia, so it was a little bit of a gamble, at least I thought so. But when the package arrived and I connected up... 8 power on hours. Total. EIGHT! On 12v power it maxes out at 3.5w, typically more like 1.5-ish (while still busy saturating the SATA read bandwidth). I couldn't believe it. Almost still can't lol. As for the network, that's the dashboard for Engenius's cloud-enabled products. I'd been using their stuff professionally in one way or another for years and have had nothing but good things to say about them, but when it came time to build a new home network, I thought to jump on the unifi bandwagon - everyone always seems to have the best things to say about their network gear, and while I wasn't a fan of the fairly limited interface, their pricing couldn't be beat. I had my reservations about their cloud account requirements and all, but went against my better judgement and placed an order on 01.21.21. Two days later, they issued a software updated that removed multi-site support; that was enough to convince me to cancel my order. They later said it was a 'bug' - with their history, I can't really believe that... Fortunately the hardware was still in transit, and all that was needed was to notify UPS of the intercept/redirect and all was well. Anyway, enough of all that negativity (ugh, sorry!), on to Engenius! Between my place and the parents/in-laws, I've got 5 of their switches 2 x ECS1112FP (8x1GbE PoE+, 2x1Gb, 2xSFP) 1 x ECS1552 (48x1GbE, 4xSFP+) 1 x ECS2512 (8x2.5GbE, 4xSFP+) 1 x 5512FP (8x10GbE, 4xSFP+) Along with 11 of their AP's now: 4 x ECW120 - (wifi 5) - Two at my in-laws, two at my parents 3 x ECW160 - (wifi 5) - These are outdoor APs, 1 at in-laws, 2 at parents - both live out in the country, and dad likes to have spotify playing in his workshop while mom wanted cameras to monitor the barn (security stuff) 2 x ECW220S - (wifi 6) - Engenius had a buy-one-get-one promo late last year that my distributor hooked me up with, or I'd have gotten the (much cheaper) non 'S' variants 1 x ECW336 - (wifi 6E) - Again a promo deal where you could buy up to two for half off each... I'm wishing I bought two now lol. My only regret thus far has been related to purchase timing - they released the damned 2528FP only about a month after I picked up the 2512, or I'd have gone with that lol. You can see the switch lineup's datasheet here. Some notes / further details on this: All of their gear can be locally managed if you prefer, which is a huge plus for me personally, as it means they'll remain usable no matter what as long as the hardware is still healthy (and longevity isn't a concern of mine with their hw just based on my history with them). For the switches, they're rock solid, online upgrades (PoE remains active), stellar remote troubleshooting tools built in, and 0 issues in ~18 months. They really come into their own though when you pair them with their APs (not sure I'd still have sprung for them with the cost if I'd no need for access points)... Their best feature imo is their roaming implementation - cisco/meraki, ruckus, unifi, netgear, aruba cambium, I've never had better AP-to-AP handoff, and only one matched them (again, just my experience). Roaming between 3 units while on VOIP/webex/zoom is completely seamless, no drops or hitches in video/audio, nothing to indicate you've reassociated with a new AP. I expected this though, as even their prior (non cloud-managed) hardware was similarly capable. Simply supporting 802.11r is one thing, but their implementation does the best job I've ever seen of making it seamless/perfect. Second best is the troubleshooting tools, and that was a new one to me (as it's only available on their newer gear). It's built for people who manage hundreds/thousands of endpoints, so they've got a number of super handy tools built in that allow you to initiate things like channel scans, PCAPs, check latency values to (whatever you want), has a client history so you can see what happened with a given device (e.g. device X associated with AP1 @ 1710GMT, Band Steering suggested move to 5Ghz do to RSSi value of ### @ 1713GMT, etc). Here's one of the troubleshooting/diag pages, for example, showing the channel scanner and resource tools at my parents place; you can have it automatically scan channels to look for the 'least utilized' and automatically switch to that channel with the 'S' models, or do so manually with the rest: Troubleshooting clients is also much easier as you can see the client history, when the AP nudged the device to a different frequency (or if the device just had a mind of it's own and did it itself - apple devices... ugh.), and the same for roaming: Honestly it's saved me more in time and gas not having to hop in the car and drive out any time either parents or in-laws call that I feel they're well worth it.
-
@Stubbs glad to hear it! To me, if you're using anything more than SQlite (and in some cases even if you are), the GUI's not really suitable, but happy you've got it sorted out 👍
-
With anything more than a tiny number of files, the GUI updater typically eventually will timeout due to hitting php's active worker time limit - use the CLI instead, and you'll likely have a much better experience 👍
-
I'd guess hes talking about the warranty check - nothing to do with the drive manufacturer, everything to do with the seller though, so not really relevant to the discussion imo 🤷♂️
-
All good, my friend! Ive often said that pure command line zfs isnt for everyone, and it's not even about "skill" or "ability"; for anyone new to it, its primarily about the time investment required. I've been working on some guides that I hope will make some parts of it make some sense to folks (primarily geared towards performance tuning, but with other stuff occasionally thrown in) - I've added iSCS, NFS, and SMB sharing on zfs to the list if stuff to document, though I've already got a hell of a backlog of stuff to get through so it might be a bit... I primarily use iSCSI and NFS on ZFS, but I've got my wifes mac and my work laptops time machine going there, so it should just be a matter of copying out the config parameters, then expanding in what the options are (and what they mean). I wouldnt give up completely on unraid though if you've got a large media collection, at least if you're down to virtualize unraid - run it in a vm on truenas, pass through a controller, and save all that sweet sweet money by keeping inactive disks from sucking down unnecessary power 😁The settings noted are for the zfs datasets you wish to share out, so you'll configure them with 'zfs set'Something else to note - since you're on linux AND sharing out over SMB, you'll want to ensure you've aclmode set to passthrough, aclinherit to passthrough-x, and likely want to set xattr to 'sa' if not already done (make sure it's at least not set to 'off').As far as I'm aware, unraid is still using modified versions of the md and associated r5/r6 libraries/drivers (while still called raid5/raid6, we call the patched r5/r6 files instead of the originals). My request here is that we instead create a 'new' function/driver (same functionality as now, but called separately from raid 5/6 source), so we can use the standard md commands to create md RAID storage (allowing for us to use standard LVM as well, which is the real benefit here). My own personal reason for this - I need to create numerous backup appliance VMs for work in order to go through a bunch of testing whose workload is such that XFS is the best option for me, but currently I can only use a single drive for this (unless I got really hacky and did it on top of ZFS... but that's just a crazy amount of hardware and complexity to throw this). As they're backup appliances, their minimum (supported at least) storage capacity and IO needs are such that a single disk won't suffice. Other more broadly appealing reasons to do this: It'd enable solving numerous other feature requests (such as vfs shadow copies and the like) Higher performance pool available without the inherent resource overhead of zfs, or the latency hit of btrfs Lays the groundwork to support other kernel storage tools via plugins (e.g. anything that requires LVM that someone wants can be easily created/used)@limetech quick question on this, if you don't mind - is this implementation of LVM (using a triple mirror) a one-off, or does it mean that we're also getting the standard MD RAID functions underdeath (RAID 5 / RAID 6 along with the rest)? Looking at the code, it seems like most of what'd be necessary to do this is a refactor to the parity/dual parity of the unraid array to be called <something else> so that the standard (unmodified) libs can be called when trying to create a new pool using `md`, so I wondered... I'm sincerely hoping so!! It's the last big hurdle I've yet to solve with my unraid servers actually lol - everything else is... well, fan-friggin-tastic at this point 😁@ljm42Sorry to bug ya with a seemingly unnecessary follow up, but wanted to ask - do you know, or happen to recall, how this was initially sorted out? Debug's annoying, and pktt felt like crazy overkill, but I honestly couldnt think of any other way around it, and am wondering if theres some other simpler method that would've pointed to the answer (initially I mean, prior to it being added to tips and tweaks). Thanks for your time!Since it's all bash, I'd increase syslog's logging level to debug and re-test, then evaluate based on what you see there. If you haven't attempted rebooting the host yet, that's worth a shot prior to investing the effort into debug - there are times where something in memory isnt updated to reflect config changes, which a reboot would then fix. Not common, but worth a shot. If both of those come up empty (e.g. you find its something network related), you're next bet is unfortunately likely a packet trace (ugh). It's only been about 24 hours, and we're mostly volunteer here - we do what we can, but sometimes it takes us a bit. Little patience goes a long way ❤️@sonofdbn glad you got it sorted, and happy to have been able to help! 🎉Can you expand on what you mean (what the "this" part is)? How the plugin works, or snapshots? Or maybe the filesystem itself and how snapshots work within that filesystem? Not sure. If you're unfamiliar specifically with advanced filesystems, or just havent worked with them previously, the first post in the zfs plugin support page has some handy reference links towards the bottom that should help as a primer.Did you ever track this down to determine the cause? I don't have any systems which exhibit this behavior, but I'd be curious to dive into it if you haven't already and are interested... Fuse is a HUGE pain in the nuts to troubleshoot from a performance perspective, but maybe if we could at least track it down to a specific set of variables from the HW/Network side where this ends up being seen (e.g. typically occurs on systems with low max freq., has turbo boost disabled or unavailable, and is dual CPU, just for instance) and maybe even what fuse is doing during that time that's taking so long (enable debug tracing, check out what the fuse, kernel, and filesystem API's are doing, which calls those APIs are making and which are taking the longest, perhaps get a flame graph to make visualizing that part a bit easier). I'd guess the reason behind a simple `mv filename /location` being slower than copying over smb has to do with the fuse interrupt queue getting thrashed - with mv being a single-threaded-with-no-optimizations type of tool whose thread is on the same server doing the fuse ops, you're almost certainly going to have more interrupts than with SMB given it's massive history of perf optimizations and the fact that those optimizations were designed against our use case (network file transfers). I could see how with * either * a limited number of cores (causing high IRQ from the kernel side), or lower frequency (fuse's interrupt queue getting stacked up waiting for cpu to finish it's actions with the filesystem/etc), SMB could be more performant. ... Im rambling. It's late. Anyway, hoping to hear your thoughts!Why'd you use sudo? All that should be required is just the command 'updater.phar' - to rule out permissions issues having been introduced, I'd restore the app and DB from backup and re-run normally, just in case. If you're looking for further help, you'll want to increase the logging level of nextcloud from the cli, restart the container, then post up what you're seeing.This sounds like a space issue - you're at something like 0.4% free space, and even if that equates to multiple GB of space, you have to take into account the fact that the filesystem has journaling/maintenance to address that uses your free space to do so. Any filesystem (and each disk contains a single unique filesystem - unraid just presents the array as a single namespace for it) starts acting more and more wonky the closer you get to capacity; even for write-once-read-many things like you'd typically put on the unraid array, 3% is the bare minimum I'd want free (5% is better). Add more capacity, and I'm near certain your issue will go away.The power consumption one is something I thought was already there, but when I went to look for it, didn't see it immediately off-hand. The second is the more interesting one to me honestly - I see a TON of people talking about idle power consumption, and I'm just wondering how much time people actually have these servers idle. For myself, I went back 96 hours, and there's only 2 hours in there that I'd call 'idle'. There's almost always at least one plex transcode going, tdarr will often see new media and get cracking away on converting it, Nextcloud is now up to 7 users and there usually someone working on a document or sharing files, checking their email, or syncing something with their PCs/phones, just tons of stuff. I'm just wondering whether 'idle power consumption' is a thing folks actually see (and how much) - even if my system utilization is above 'typical', it makes me wonder if instead we shouldn't be thinking about the system's efficiency (instructions per clock and the like) vs 'mine idles at 30w' ... For the record, if I saw 30w on mine, it'd mean something's broken/misreporting 😅+1 for this; one of several things (some of which are admittedly self-inflicted lol) keeping me from heading to 6.10. My eth0 is a shared IPMI/host onboard, and I don't use it for anything other than IPMI as it's 1Gb and vlan'd off at the switch level anyway, instead accessing everything over eth1's 10Gb interface.I'd like it better if they sorta threw them and the docker logs in with the syslog (separate files of course) so you could just have them *all* sent to the configured syslog server.





