




BVD
Members
-
Joined
-
Last visited
Everything posted by BVD
-
@steini84 or @ich777 would it be possible to include ioztat with the plugin, or do you feel it's better served to something like NerdPack? I've been using it since it's inception, super helpful for quickly tracking down problem-child filesets: https://github.com/jimsalterjrs/ioztat It does require python, but that's the only thing outside of the base OS that's required for us (though I don't know if that requirement precluded it from inclusion, hence the NerdPack comment...) Something else I've been symlinking for a while now is the bash-completion.d file from mainline zfs - it's 'mostly' functional in openzfs, though I've not spent a lot of time poking around at it. https://github.com/openzfs/zfs/tree/master/contrib/bash_completion.d
-
@BoKKeR Best bet would be to use pip instead - both python and pip are included in dev tools, and it looks like it's one of the supported ways to install tldr
-
There should be some additional lines above that that'll tell you what exactly is going on - believe it means you're trying to use a container which doesn't support one of the streams used in the source media, while having 'force compliance' set to false. Set it to true, and it'll just drop whatever can't be translated to the chosen container (happens most often with mp4 [which is like the 'universally supports damned near everything' container] -> mkv/etc [which has more restrictions] if I'm remembering correctly)
-
Having the container means you don't have to care about anything other than having a browser to access. I don't mind paying for good software. I do mind paying a monthly subscription just so I can access the same content on all my devices.
-
I've mine mapped to the Notes folder from my nextcloud location - you'll have to set up nextcloud to scan for file changes on occasion for this to work properly, but once done, it works out pretty well.
-
We must be on the same wavelength - I literally just started building my own container for this one, after discovering obsidian a couple weeks ago thanks to Wendell over at Level1Techs... Only to find it in CA this morning! Great work, and thanks!
-
@SpencerJ just wanted to check in with you as I've been eagerly awaiting the next episode, but it's been quite a while now since the last one, and the one prior was a little later than the previous cadence.... Has the uncast been retired, or perhaps on hiatus for now? Hope it's still going, and looking forward to to the next episode if so!
-
@ich777 I actually went a similar route tbh - I'd had everything running in one box, and every time I had to take it down for whatever reason (adding a SAS card for the disk shelf, pulling one of the GPUs for another project, etc) it was something of a planning ordeal. These days I have two unraid boxes (the primary, then my older setup acting as something of a backup vault / tinkering playground) as well as one proxmox host. * CARP ensure's routing's always available through the pfsense VMs (one on unraid, one on proxmox) * zfs snapshots ensure that the proxmox host's datasets are never more than 10 minutes out of date (just for those "tier 1" [home edition, lol] services) * if the proxmox host detects any of those services are down for whatever reason, it starts up it's own copies of them locally. Kinda stole the idea from one of @SpaceInvaderOne's old pfsense videos and adapted it. There's some additional logic there to ensure that it only self initiates starting its own services if it's not already started them due to my shutting down the array on purpose, but that's the gist. I just think given how rare it is for folks to be running multiple NAS/servers at home (home NAS users are already niche, but then those running multiple are a niche within a niche), I see a lot of value in the idea of allowing VM's to run with the array down. Maybe once multiple arrays become a thing, it'll make more sense for Limetech to implement some logic like 'this VM doesn't rely on data in array X, so it remains running'. We'll see!
-
Guessing it's the way libvirt's utilized based on the review I'd initially done when trying to sort this out myself - it's definitely no easy task, but I'd certainly appreciate the effort!!
-
Any chance you've a static IP set for the container? There's a macvlan issue with some systems which causes in random crashes with that setup (I'd had one within 12 hours, then next didn't happen for 27 days), fixed in 6.10 by switching to IP VLAN.
-
With rumors regarding zen 3 TR Pro seemingly evaporating overnight (nothing new since December), I've been getting antsy. Sincerely hoping that all the March 2022 release date rumors leading up to the drought turn out to be true... Because in preparation for it's release, I've been deploying more and more of the workloads I'd had planned for the server, and now I've stacked enough on that the 16c 3955wx has been redlining somewhat regularly the last few weeks. Images of a super buff 4'5" body builder trying to backpack a volkswagen have come to mind. Given this, I've spun down had to disable Tdarr's CPU transcodes and just stick with GPU accelerated only. It's helped quite a bit, saving some headroom for those occasional spikes. Some current results on that front: Almost ready to add the last Plex library and queue it up. I figure the 1650S has pretty much paid for itself twice over at this point (at least at the price I'd paid for it back when anyway) - 16TB drives @ ~$320/per, with the 1650S costing me ~$170, I'm honestly pretty stoked! The first 'new' addition since moving to the new hardware was Paperless-ng - I had no idea how much it'd change our life to be honest. We went from having 2 banker boxes full of everything from tax paperwork, to paid bills, work reviews, etc, to about 3 inches of papers left. No more having to go into the boxes each and every time we have a bill come in the mail, no more time wasted trying to find 'that one bill that we know we paid but the stupid bank/lender/government/whatever say they never received payment for... Just plop it on the scanners feed tray, hit a button, and done. It's been a hell of a process to get here, about 5 months in the making as we're using this ancient HP business scanner and I'm too cheap to replace it - it's wicked slow at a decent quality setting, maybe a page every couple minutes... but we're in no hurry, the quality is perfect for Paperless's OCR (converting the scanned image to searchable text), it's able to scan directly to SMB, and it's got a 35 page feed tray. I just put another stack on a couple times a day and leave it at that. Paperless automatically tags them based on content, and we've not had to dig out a single page since setting it up. Next, I opened up the media request website to my sister, now that my parents have gotten the whole 'we can just submit it here and we don't have to change DVD's anymore!? *CLICK CLICK CLICK CLICK CLICK CLICK* " thing out of their system; that might've been a bit of a mistake: Nearly everything in TV_SaturdayMorning is hers, and she literally sat down for a full hour adding each and every one her series... I wasn't expecting that kind of growth lol. That 'last library' to add? ...That's it. There's more, but I think I gotta hit the sack - hoping to get more time to catch this thing up to date in the coming weeks! Brief preview of what I've still got to detail out: Another host - two hypervisors, routing, and a little room to spare Network refresh - IoT takes a bite out of wifi And a couple other odds and ends - several containers, storage crunch woes (thanks sis...), and repurposing the older xeon gold 6139 based system.
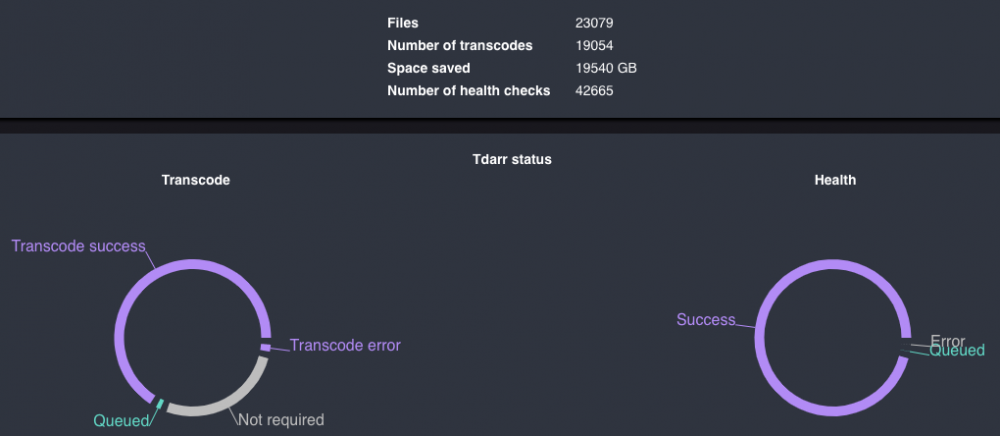


-
Reaffirming the home assistant note - I'd not really thought of it a great deal until recently, as we just finished purchasing and moving into our new home about 4 months ago, and have finally gotten it to the stage where we're ready to implement some of our plans for the place (connected garage door, motion detection and temp control, soil monitoring for the garden, etc)... Say you suffer a double failure - you want to minimize IO during the rebuild to mitigate (as much as one can) the potential for a third failure during reconstruction, so you start the array in maintenance mode. With 16TB drives becoming more commonplace, 20TB drives now available, and 24TB+ drives on the horizon, rebuild times are only going to get longer and longer. If we average 150MB/s across the entirety of reconstruction (whichever then is wildly optimistic), you're looking at ~1.5-2 days downtime. Not a huge deal for a media server. But for critical needs (like heating and cooling, home security, many others), thatd feel like a lifetime.
-
The kernel driver isnt ready for 12th gen at least as far as gpu partitioning is concerned. Haven't tried it with bleeding edge kernels yet or anything, but at least as of 5.13, the latest "clean/stable" iGPU supported is 10th gen.
-
I'm kind of hoping that the work they're doing towards moving the UI to a Vue event-driven system makes the whole mobile app idea moot by allowing them to easily code a mobile view/version and baking it in. The effort these mobile app devs have put in is admirable and definitely appreciated, but I think it's not super sustainable with how much and often needs within them evolve over time these days
-
+1 for this Mostly I'd just like to be able to move cards between columns... The three column layout is great, but super lop-sided on both my servers; column 1 ends up 2-3x longer than column 2, with column 3 only being slightly better (just under half as long). If I could move the cards from one column to the next, even if I had to go in and edit a config file somewhere that says 'this should be rendered in grid X-Y', I'd be totally fine with that!
-
You're both speaking my language lol - as soon as I think "this should last me a year or so, at least", it's like a 60 day countdown begins to fill it up 😅
-
Can't restate this enough - it's not a replacement for backup, but damn it's helpful in avoiding downtime in the event you do suffer a failure. My main array setup is something like this: * 10 drives, up to 16TB in size, containing all my data with 2 set up for parity * Vast majority of this is media content, which I don't back up separately, but this also includes about 8TB of what I consider 'valuable data' (nextcloud user files for 11 users, DB files built up over the years, appdata-like information, and 'hoarded' data I've collected going back to 1997) * That 8TB worth of files is contained within 4 specific shares, all of which backup via borg to a secondary system * That second system sends nightly diff's to my parents house (about 2 hours away) over my dog-slow 30Mbps upload, which is regularly verified. I've only had to restore one of those off site backups one time in the years I've had it running, and it was only about 1.5TB at the time, but man am I ever glad I had it available; wedding photos, birthdays, all kinds of memories would've been lost otherwise (flood took out everything locally). The beauty for me with Unraid is how power efficiently I can do all this. I've got file hashing so I can help to detect silent errors, drives are only spun up when content is actually accessed, and overall power utilization savings is substantial. If I'm writing data, it's usually only to one disk, which means I'm spinning 3... If reading, it's just the one disk being read, quite nice vs the alternative of spinning up all 10. I did the math in a post some time back if anyone has the energy and cares to look for it - can't beat the value add here when it comes to power savings!
-
Maybe we're talking past each other- I guess I'll try ti explain once more- It's not that setting up two radarr instances isnt something that can be done, it's that its additional unnecessary complexity, as well as wastes space with duplicate files- and for someone that doesnt want to waste space, I'm surprised that's the route you went tbh... As for downloading vs rebuilding, two key differences: 1. You dont have to worry about re-locating what was lost, then hoping it's still available, or worse, reripping it. 2. Far more importantly, you continue to maintain access to all your content without the need to wait to re-accumulate it This all is a bit of a moot point though imo for most - if all you ever store is plex data, why even use unraid? Far more likely, theres personal content there as well. If you're ok with losing that along with you media, I suppose that's up to the individual, but I'm not. And for the immediately expected response of "yeah, but you should back that up" - I back up everything. That doesnt mean I ever want to lose access to any of it and have to restore from backup. Hope for the best, plan for the worst. Until weve the ability to create multiple arrays, actual unraid arrays, I dont see why anyone would argue *against* using additional parity when available, unless they've just never encountered drive failure before; it's a poor recommendation. Drive failures happen, and if you've not encountered them yet, you will. May not be tomorrow, maybe not even next year or 3 years from now. But itll happen. If you feel parity isnt a worthwhile investment, you either dont value your data, or dont value your time *AND* trust your backups, both to a degree that is unrealistic for what I feel are the majority of users.
-
I'll second that! I recently hit 60TB used, after my parents got through adding their stuff to my server so they could access it remotely - that was a friggin wakeup call lol, "your 70% utilized array as of last week is 95% full as of today". Ugh. Tdarr to the rescue! Transcoding just offers the flexibility without the management hassle, and gives me better overall resource utilization as the GPU is used amongst by numerous other resources anyway - nextcloud for facial recognition of photo backups, image detection in the NVR, video acceleration for a webtops container I've been playing with, plex, and now a tdarr node. Might as well get the most out of it!
-
If you don't mind the noise (they're not *that* noisy tbh), you can save significant funds by going with the exos drives as opposed to the ironwolfs - for about the same price as a 12TB Ironwolf Pro, you can get a 16TB Exos. Same 5 years worth of warranty, still runs cool (mine never hit above 34C, even under parity check), just without the 'recovery' warranty. That's the route I went anyway, and couldn't be happier! I've been trying to find a 3060 for 7 months now so my wife could game with me, both of us running off the Unraid server, but without much luck - The EVGA version was set to be 329 originally, now up to something like ~400 bucks new, and even at that price (which seems absurd for an 'entry' level gaming card lol), they're basically unobtainium it seems like. I'm sure you can find either a good use for yours, or a willing buyer without much trouble! At these nutty market rates, hell, you could probably buy a couple 16TB exos with the funds or something lol
-
There are counters to each of these: Why not have everything in 1080p? A. I like having 4k available for in home consumption Why not have duplicate copies of everything then? Or even just dupes of your 4ks at least A. Because its annoying to manage, and adds additional steps and/or complexity even with the highest levels of automation possible. Why parity for plex media? A. Because many of us have limited monthly bandwidth allocations, and waiting 40 months to download 40TB+ (or paying extra for "unlimited"), re-ripping everything or restoring from a backup takes too dang long, and is best avoided where possible. Even losing one 12TB drive worth of data (as you so aptly mentioned) means 12 months rations. If you're ok waiting that long, or else ok being gouged by your ISP instead, that's more than I would be at least. Why transcode at all? A. It's the best way to have to most flexibility in how media can be consumed remotely. Especially important for those on a cable connection, where you might have gigabit downloads, but are limited to something comparitively stupid like 25mbps upload. Idk, these questions dont really seem very thoroughly considered or thought out imo, but my apologies if I've somehow misunderstood them in some way
-
Are you still dealing with this by chance? Just looking through the log, the main errors I see seem to have to do with resizable BAR; if you could point out timing for when this was encountered (e.g. last issue noted at 1500 eastern, or at least as close as you can recall) that'd help. This seems to be where the issue first starts (from your docker logs): time="2021-10-12T13:25:36.576501793+08:00" level=error msg="873581800cf8e11d577fd6b1fd5934a3fe3665162523052dc21cd102d476fd07 cleanup: failed to delete container from containerd: no such container" Which is followed by this from syslog: Oct 12 13:25:36 Magnus kernel: resource sanity check: requesting [mem 0x000c0000-0x000fffff], which spans more than PCI Bus 0000:00 [mem 0x000c0000-0x000dffff window] Oct 12 13:25:36 Magnus kernel: caller _nv000723rm+0x1ad/0x200 [nvidia] mapping multiple BARs Oct 12 13:25:37 Magnus kernel: resource sanity check: requesting [mem 0x000c0000-0x000fffff], which spans more than PCI Bus 0000:00 [mem 0x000c0000-0x000dffff window] Oct 12 13:25:37 Magnus kernel: caller _nv000723rm+0x1ad/0x200 [nvidia] mapping multiple BARs This all happens right after a login, so it seems like maybe some user-action initiated all this? Not sure... Oct 12 13:25:07 Magnus webGUI: Successful login user root from 10.253.0.2
-
It's still a WIP - you can follow the dev work on it here: https://github.com/DualCoder/vgpu_unlock/issues/8 I wouldn't expect anything in the short term tbh - this entire GPU generation has been such a friggin heartache for so many folks, I wouldn't expect anything until either the next gen, or if we're lucky, the super refresh. I concur with @Michael_P above - since you're running Intel, that iGPU is about all anyone could ask for when it comes to plex transcoding. IMO at least, this is one of the few clear places that Intel is easily the best choice - any intel system since coffee lake and newer is about as good as it gets as far as bang-for-buck when it comes to a plex server. AMD just doesn't have a viable alternative (that may be mostly on plex though as they've not updated the transcode engine to support APU's nearly as well from AMD), and the efficiency levels you'll get with the iGPU simply can't be beaten. Use the iGPU for media server/NVR/whatever needs, pass through your 3060 to your gaming VM, and enjoy the best of both worlds.
-
I asked about buying replacement trays and a spare midplane, but they wouldnt even consider anything until I showed them failed hw, so I just stopped buying from em - if I've gotta wait till somethings dead to even order a replacement (let alone however long itd take to ship), that's just not viable for me. Imo the design itself isnt conducive to dual sided air intake imo, not without some dremel work anyway.
-
There are folks who use unraid for massive archival tasks where tape isnt really an option, such as the web archive, where multiple arrays would be of significant benefit. I dont think it's a big percentage of users or anything, but they're power users for sure, and often have 100+ drives, some running one unraid instance as the main hypervisor, then running nested unraid vm instances to allow for multiple arrays beneath. Definitely not a common scenario... but one way we could see a benefit is by being able to split our usage across multiple arrays, we'd strongly reduce the possibility of a full failure during reconstruction - I dont relish the idea of having more than, say, 12 drives or so in any type of double RAID array (regardless of zfs, unraid, lvm/MD, etc). Still, idk how many actually run that many drives these days, I might be completely off base 🤔






