





untraceablez
Members
-
Joined
-
Last visited
Everything posted by untraceablez
-
Oh wow that was surprisingly well-hidden by color scheme on my end. That worked perfectly!
-
So I have 2 unRAID servers in my Connect account that are active, and I have an old one from way back that I'd like to remove, but because it's no longer online and it doesn't exist, I can't disconnect it from the unRAID side, which leaves this dead entry on my Connect page. Is there any way to disconnect it from the account side or am I just stuck looking at the dead entry? I only have 3 servers so it's not truly a big deal, but it does annoy me and I'd like to clear the bad entry out.
-
Support Thread for Agregarr: The Plex Collection Manager Application: Agregarr Docker Hub: https://hub.docker.com/r/agregarr/agregarr GitHub: https://www.github.com/untraceablez/unraid-apps/agregarr-unraid Docs: https://www.github.com/untraceablez/unraid-apps/agregarr-unraid/README.md Ported the new and growingly popular app, Agregarr as an unRAID template. If you appreciate the work, feel free to donate here.
-
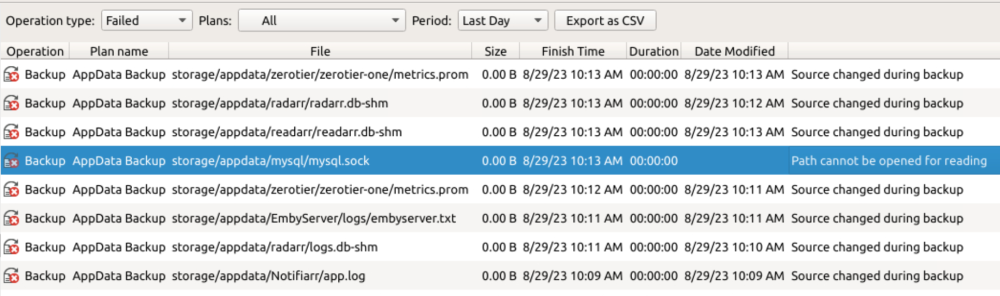
So I've been using CloudBerry backup for a while to backup the painfully digitized record collection I host on my NAS and other things. I have tried many times to backup my /mnt/user/appdata folder, but the backup always encounters errors due to log files, databases, and other types of files that update due to the running apps. These files are ones I would like backed up, especially in the case of a crash or hardware failure, so I don't want to blacklist the file extensions for them. Is there a way to get them to backup successfully and have CloudBerry not just throw a ton of errors at me in the error reporting? Screenshot attached shows the kind of files that typically result in errors for me.
-
Reserved for updates UPDATE #1 Accidentally messed up the template and it was populating with my personal info instead of the defaults, has been fixed and pushed.
-
Hey All! This is my first container template, so excited to finally give back to the unRAID community! This one's a template for UV Desk, a self-hosted helpdesk and knowledgebase software. You can learn more about the overall project at their site. This unRAID template is based off dietermartens/uvdesk. There is some initial setup that needs to be done before you install the container, please check the README for full details.
-
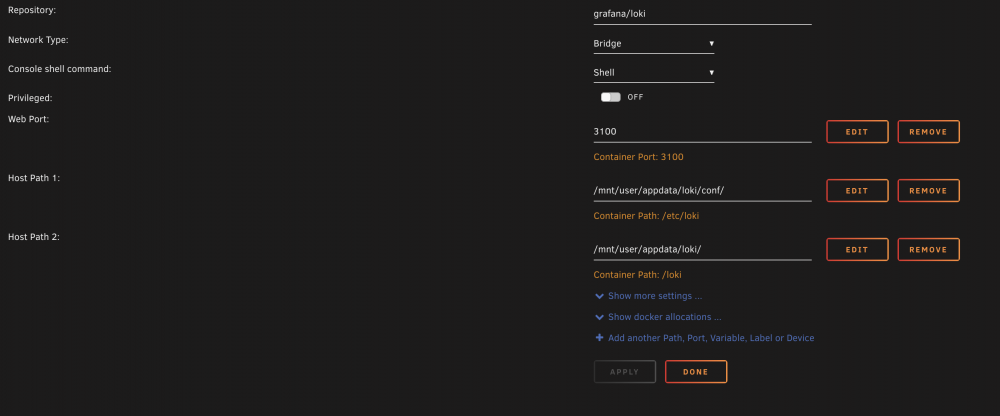
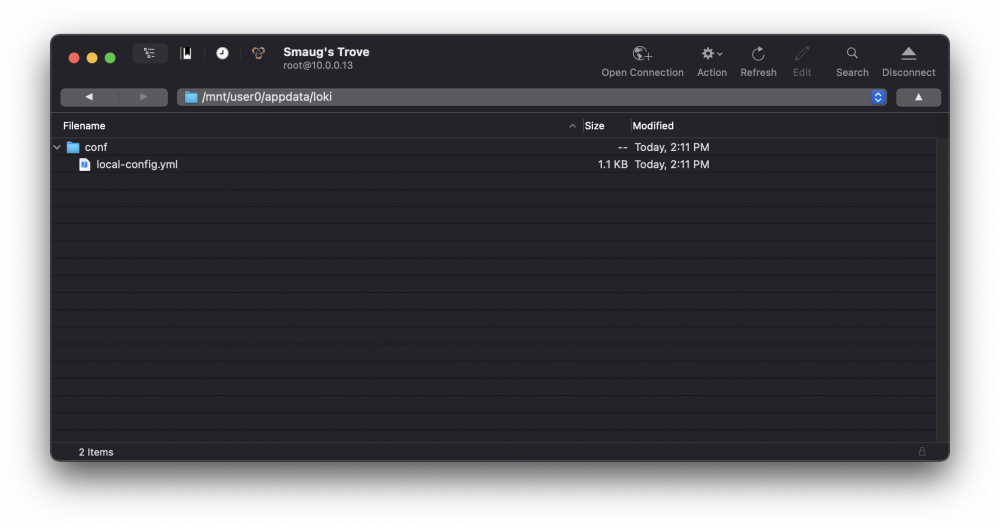
So trying to add Loki + Promtail into my existing setup, Promtail is fine, but Loki keeps insisting that my local-config.yaml isn't there? 2021-11-08 20:24:06.763073 I | proto: duplicate proto type registered: purgeplan.DeletePlan 2021-11-08 20:24:06.763141 I | proto: duplicate proto type registered: purgeplan.ChunksGroup 2021-11-08 20:24:06.763143 I | proto: duplicate proto type registered: purgeplan.ChunkDetails 2021-11-08 20:24:06.763145 I | proto: duplicate proto type registered: purgeplan.Interval 2021-11-08 20:24:06.817986 I | proto: duplicate proto type registered: grpc.PutChunksRequest 2021-11-08 20:24:06.817993 I | proto: duplicate proto type registered: grpc.GetChunksRequest 2021-11-08 20:24:06.817995 I | proto: duplicate proto type registered: grpc.GetChunksResponse 2021-11-08 20:24:06.817997 I | proto: duplicate proto type registered: grpc.Chunk 2021-11-08 20:24:06.817999 I | proto: duplicate proto type registered: grpc.ChunkID 2021-11-08 20:24:06.818001 I | proto: duplicate proto type registered: grpc.DeleteTableRequest 2021-11-08 20:24:06.818003 I | proto: duplicate proto type registered: grpc.DescribeTableRequest 2021-11-08 20:24:06.818005 I | proto: duplicate proto type registered: grpc.WriteBatch 2021-11-08 20:24:06.818007 I | proto: duplicate proto type registered: grpc.WriteIndexRequest 2021-11-08 20:24:06.818008 I | proto: duplicate proto type registered: grpc.DeleteIndexRequest 2021-11-08 20:24:06.818012 I | proto: duplicate proto type registered: grpc.QueryIndexResponse 2021-11-08 20:24:06.818014 I | proto: duplicate proto type registered: grpc.Row 2021-11-08 20:24:06.818016 I | proto: duplicate proto type registered: grpc.IndexEntry 2021-11-08 20:24:06.818018 I | proto: duplicate proto type registered: grpc.QueryIndexRequest 2021-11-08 20:24:06.818020 I | proto: duplicate proto type registered: grpc.UpdateTableRequest 2021-11-08 20:24:06.818022 I | proto: duplicate proto type registered: grpc.DescribeTableResponse 2021-11-08 20:24:06.818025 I | proto: duplicate proto type registered: grpc.CreateTableRequest 2021-11-08 20:24:06.818029 I | proto: duplicate proto type registered: grpc.TableDesc 2021-11-08 20:24:06.818036 I | proto: duplicate proto type registered: grpc.TableDesc.TagsEntry 2021-11-08 20:24:06.818039 I | proto: duplicate proto type registered: grpc.ListTablesResponse 2021-11-08 20:24:06.818042 I | proto: duplicate proto type registered: grpc.Labels 2021-11-08 20:24:06.818133 I | proto: duplicate proto type registered: storage.Entry 2021-11-08 20:24:06.818138 I | proto: duplicate proto type registered: storage.ReadBatch failed parsing config: open /etc/loki/local-config.yaml: no such file or directory I have a screenshot of the config in unRAID attached, at a loss as to why the file's not showing up. I also have a screenshot of the /appdata/loki folder attached as viewed from Cyberduck.
-
Great container, the interface is very nice, got my Wasabi account linked flawlessly. That being said, encountering a couple issues: 1.) Has anyone tried backing up all system files from / excluding some shares in /mnt and /storage? All the errors I'm getting are permission denied errors, even though the container is assigned /storage as / and it's running at a privileged level. I suppose this isn't necessary and I could get away with just backing up /flash 2.) I can't expand the /mnt folder to selectively backup my /appdata folder. The whole container hangs. I assume this is due to the downloads and media library folders there. Is there anyway to manually specify the path and not have to use the GUI there, or am I just screwed trying to backup anything under /mnt?
-
Given others already explained UPSs & UNRAID pretty well, I'll just chime in with the UPS I use personally, I caught mine at a Office Depot that was going out of business, so it was below MSRP, but even at MSRP it's still a great balance of capacity/bulkiness: APC BN1350M2 1350VA UPS w/ USB Charging I also keep my router/modem plugged into the UPS to ensure I have WiFi for a bit in the event of a power outage.
-
Hello, First off, love your containers, about 1/3rd of my containers are running from your images! To get to the point though, I'm currently trying to accomplish 2 tasks for my mineos-node instance. 1) Being able to run multiple servers (distinguished by port number) 2) Using the swag container to proxy the webui AND the servers to subdomains for friends/family to access. Do you have any info on getting this accomplished? Most of what I found were forum posts over on the main mineos forums, and the results were rather inconclusive. I have almost every container of yours running behind a proxy for remote management, if it's possible to use other container .confs as template of sorts. And of course, given the time of year, Happy Holidays and Happy New (Finally) Year!
-
Funny enough NZBPlanet has since resolved itself for me, and for NZBGeek I eventually got it working by adding my username/password as a backup method if API calls failed. For NZBPlanet I'd just suggest removing it, updating the container, and re-adding it.
-
I use the LetsEncrypt docker, making just the changes you stated for that container worked for me! Thanks for the explainer, very helpful!
-
A re-install could work if you make sure to wipe out the binhex-radarr folder in appdata. That should force it to rebuild its database on re-install. I would make sure to note down any specific settings/customizations you have so you've got a reference to set everything back up after re-install.
-
Nope unfortunately, still stuck at 500KB which is really inconvenient, having to resize every image in PS.
-
So as of recent Lidarr has begun crashing, requiring a restart of the container to get things going again only for it to crash a few hours later. I have the log dump here for the last crash, it seems to be a memory error, didn't know if this is a container level issue or if this is a main branch lidarr issue. 2020-09-23 15:30:17,155 DEBG 'lidarr' stdout output: * Assertion at lock-free-alloc.c:145, condition `sb_header' not met, function:alloc_sb, Failed to allocate memory for the lock free allocator ================================================================= Native Crash Reporting ================================================================= Got a SIGABRT while executing native code. This usually indicates a fatal error in the mono runtime or one of the native libraries used by your application. ================================================================= 2020-09-23 15:30:17,156 DEBG 'lidarr' stdout output: ================================================================= Basic Fault Adddress Reporting ================================================================= Memory around native instruction pointer (0x14c697d9f82f):0x14c697d9f81f d2 4c 89 ce bf 02 00 00 00 b8 0e 00 00 00 0f 05 .L.............. 0x14c697d9f82f 48 8b 8c 24 08 01 00 00 64 48 33 0c 25 28 00 00 H..$....dH3.%(.. 0x14c697d9f83f 00 44 89 c0 75 19 48 81 c4 10 01 00 00 5b c3 66 .D..u.H......[.f 0x14c697d9f84f 90 48 8b 15 e9 75 18 00 f7 d8 64 89 02 eb ba 67 .H...u....d....g 2020-09-23 15:30:17,156 DEBG 'lidarr' stderr output: /proc/self/maps: 400ca000-4066a000 rwxp 00000000 00:00 0 40ec2000-40ed2000 rwxp 00000000 00:00 0 14c3bdaa9000-14c3bee00000 r--s 00000000 00:29 36611 /var/tmp/etilqs_ea5b35344a134efd (deleted) 14c3bee00000-14c3bef00000 rw-p 00000000 00:00 0 14c3bf100000-14c3bf200000 rw-p 00000000 00:00 0 14c3bf300000-14c3bf400000 rw-p 00000000 00:00 0 14c3bf500000-14c3bf600000 rw-p 00000000 00:00 0 14c3bf700000-14c3bf800000 rw-p 00000000 00:00 0 14c3bf900000-14c3bfa00000 rw-p 00000000 00:00 0 14c3bfb00000-14c3bfc00000 rw-p 00000000 00:00 0 14c3c0900000-14c3c0a00000 rw-p 00000000 00:00 0 14c3c0b00000-14c3c0c00000 rw-p 00000000 00:00 0 14c3c0d00000-14c3c0e00000 rw-p 00000000 00:00 0 14c3c0f00000-14c3c1000000 rw-p 00000000 00:00 0 14c3c1100000-14c3c1200000 rw-p 00000000 00:00 0 14c3c1300000-14c3c1400000 rw-p 00000000 00:00 0 14c3c1500000-14c3c1600000 rw-p 00000000 00:00 0 14c3c1700000-14c3c1800000 rw-p 00000000 00:00 0 14c3c1900000-14c3c1a00000 rw-p 00000000 00:00 0 14c3c1b00000-14c3c1c00000 rw-p 00000000 00:00 0 14c3c1d00000-14c3c1e00000 rw-p 00000000 00:00 0 14c3c1f00000-14c3c2000000 rw-p 00000000 00:00 0 14c3c2100000-14c3c2200000 rw-p 00000000 00:00 0 14c3c2300000-14c3c2400000 rw-p 00000000 00:00 0 14c3c2500000-14c3c2600000 rw-p 00000000 00:00 0 2020-09-23 15:30:41,773 DEBG 'lidarr' stdout output: ================================================================= Native stacktrace: ================================================================= 0x55fda9163dea - /usr/bin/mono : (null) 0x55fda90fa32e - /usr/bin/mono : (null) 2020-09-23 15:30:41,773 DEBG 'lidarr' stdout output: 0x14c697f594d0 - /usr/lib/libpthread.so.0 : (null) 0x14c697d9f82f - /usr/lib/libc.so.6 : gsignal 0x14c697d8a672 - /usr/lib/libc.so.6 : abort 0x55fda9069a58 - /usr/bin/mono : (null) 0x55fda934c456 - /usr/bin/mono : (null) 0x55fda936640c - /usr/bin/mono : (null) 0x55fda93669cd - /usr/bin/mono : monoeg_assertion_message 0x55fda935843b - /usr/bin/mono : mono_lock_free_alloc 0x55fda931ba23 - /usr/bin/mono : (null) 0x55fda931a4ff - /usr/bin/mono : (null) 0x55fda931a57f - /usr/bin/mono : (null) 0x55fda9312b91 - /usr/bin/mono : (null) 0x55fda934375d - /usr/bin/mono : (null) 0x55fda9312349 - /usr/bin/mono : (null) 0x55fda93142d9 - /usr/bin/mono : (null) 0x55fda93148e0 - /usr/bin/mono : (null) 0x55fda9318ffe - /usr/bin/mono : (null) 0x55fda9319187 - /usr/bin/mono : (null) 0x55fda931c03f - /usr/bin/mono : (null) 0x55fda9308809 - /usr/bin/mono : (null) 0x55fda92e8f4c - /usr/bin/mono : (null) 0x55fda926ab1b - /usr/bin/mono : (null) 0x55fda9280356 - /usr/bin/mono : (null) 0x400ce84d - Unknown ================================================================= Telemetry Dumper: ================================================================= Pkilling 0x14c68f729700 from 0x14c67e59a700 Pkilling 0x14c63e0bd700 from 0x14c67e59a700 Pkilling 0x14c68f92a700 from 0x14c67e59a700 Pkilling 0x14c67d866700 from 0x14c67e59a700 Pkilling 0x14c63e2be700 from 0x14c67e59a700 Pkilling 0x14c5bfe72700 from 0x14c67e59a700 Pkilling 0x14c67e198700 from 0x14c67e59a700 Pkilling 0x14c67e399700 from 0x14c67e59a700 Pkilling 0x14c695379700 from 0x14c67e59a700 Pkilling 0x14c67ea9b700 from 0x14c67e59a700 Pkilling 0x14c63d8b9700 from 0x14c67e59a700 Pkilling 0x14c63daba700 from 0x14c67e59a700 Pkilling 0x14c697d63780 from 0x14c67e59a700 Pkilling 0x14c67c53a700 from 0x14c67e59a700 Pkilling 0x14c67d2fe700 from 0x14c67e59a700 Pkilling 0x14c63dcbb700 from 0x14c67e59a700 Pkilling 0x14c68f528700 from 0x14c67e59a700 Pkilling 0x14c63debc700 from 0x14c67e59a700 * Assertion: should not be reached at mini-posix.c:249 * Assertion: should not be reached at mini-posix.c:249 * Assertion: should not be reached at mini-posix.c:249 2020-09-23 15:30:41,797 DEBG fd 8 closed, stopped monitoring <POutputDispatcher at 23379921680984 for <Subprocess at 23379921595640 with name lidarr in state RUNNING> (stdout)> 2020-09-23 15:30:41,797 DEBG fd 10 closed, stopped monitoring <POutputDispatcher at 23379921595696 for <Subprocess at 23379921595640 with name lidarr in state RUNNING> (stderr)> 2020-09-23 15:30:41,798 INFO exited: lidarr (exit status 0; expected) 2020-09-23 15:30:41,798 DEBG received SIGCHLD indicating a child quit
-
I left the project in the dustbin for a bit and picked it up today, and just went through the install fully again, and everything's working like a charm this time, don't know what went screwy the first time still but hey, it's working now! The interface on this is slick and I quite enjoy it, I only have one question, how does one adjust the image size limit for recipe pictures? 500kb is rather small and I'd like to just it to 10Mb, I like hi-res photos.
-
So I've got my server up and operating, but I can't seem to create an account via the Ferdi Windows client, upon clicking the 'create account' button it just spins a little bit and then does nothing. Trying to access the account dashboard via the webui fails, citing no account existing. I also get a failure with trying to import Franz credentials. With that I just get a blank page that has "Could not log into Franz with your supplied credentials. Please check and try again" and I've verified the Franz credentials work. Also not getting any log output from the Docker tab in UNRAID, at an absolute loss as to what's going on with it.
-
So I've been having issues with torrents entirely stalling out in Deluge, and I finally went digging in the logs to find this initial issue: 2020-09-06 14:00:49,695 DEBG 'watchdog-script' stdout output: [warn] Incoming port site 'https://portchecker.co/' failed to web scrape, marking as failed So I went and added the other PIA servers that support port-forwarding and reloaded the container. The attached log file is the result, and the WebUI won't even load at this point. I'm a bit stumped as to what a fix for it would be. delugevpn_log_9_6_2020.txt
-
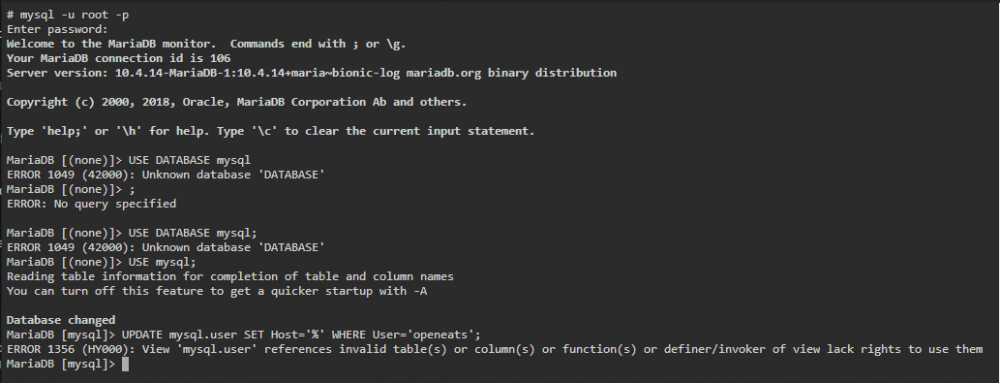
Same result with that command, verbatim. What's the correct syntax on the command? I'm also able to log in via Adminer if it's possible to flush the privileges from there.
-
Seems like I'm looking at an invalid table given there's no way I don't have the perms as root. Do I need to take the nuclear option and clear mariadb & openeats? I have no other data other than a dead authelia database that isn't being used.
-
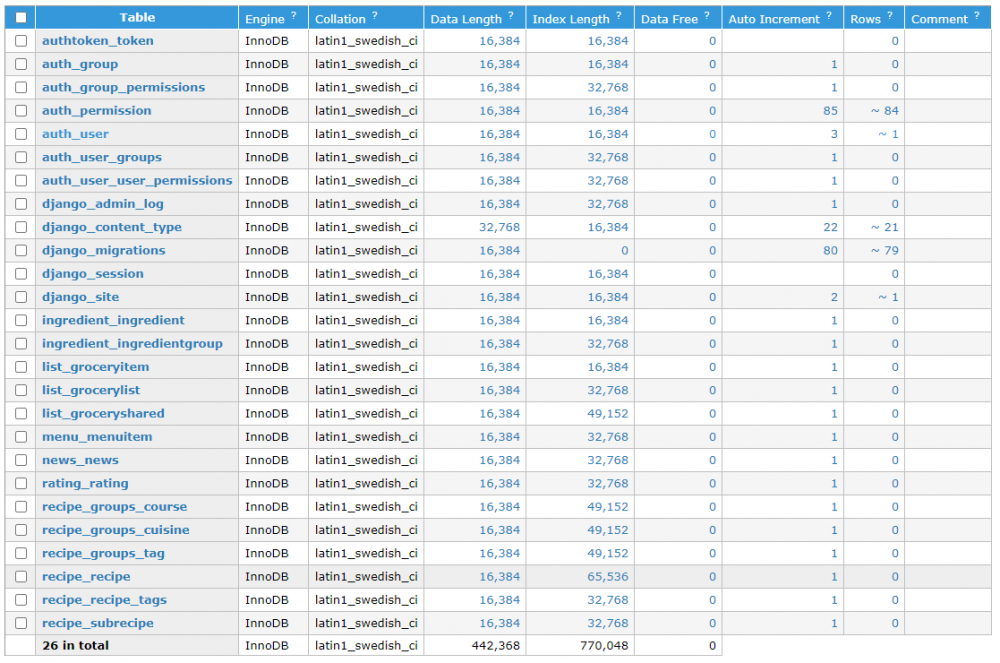
Mine is [email protected], which table do I edit that in, auth-user or a different group? I see the attached table after I log into Adminer.
-
Apologies for resurrecting a comment, but I'm having identical issues to this, would you be able to explain the changes you made to the host connections in the DB? I'm not a huge MySQL guy and am currently accessing the db via Adminer.
-
Looks perfect in my setup, thanks for the great work!

-
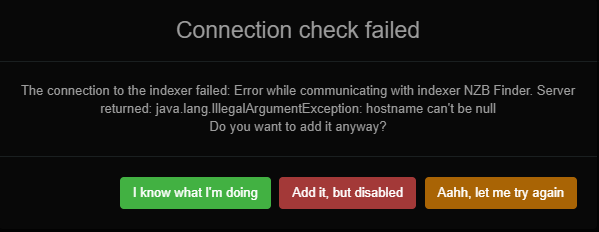
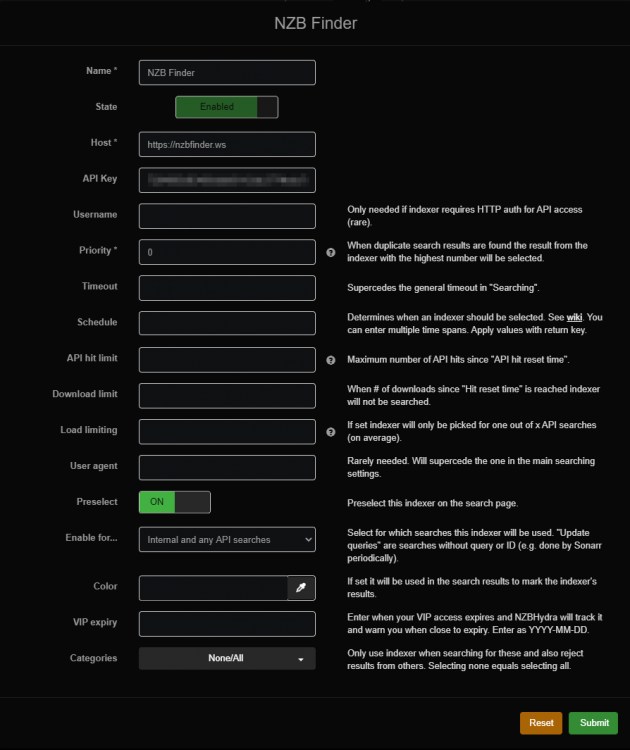
Hey there, I'm unable to add any NZB indexers into NZBHydra, even though all of my torznabs are working fine and imported from Jackett perfectly. This is the error I'm getting. I've tried with the 2 NZBIndexers I use, NZBPlanet and NZB Finder, but neither one seems to be working. The config panel on both is pretty much identical, just their respective API URLs and Keys, everything else is left blank: Any ideas what could be causing this error? Happy to upload logs if that helps.
-
So I run my server in a Cooler Master HAF XB EVO and it'd be great to get one of these custom icons for it. Spectacular work on the ones you've made already, you've got some great design chops! Front view of it:











