




aim60
Members
-
Joined
-
Last visited
Everything posted by aim60
-
@strike, your missing the difference between what the script does, and what unraid does. The script forces a spin down, possibly on a timer delay. Unraid waits an amount of time after the last observed activity on the disk. What I'd like to implement is a spin down delay of Never during the day, and 15 minutes after the last observed disk activity at night.
-
Thanks. I was hoping for a much simpler solution, a way to change the value of Settings | Disk Settings | Default Spindown Delay
-
Does anyone know if it’s possible to change the Default Spin Down Delay from shell script. I would like to use User Scripts so I can have different values at night and during the day.
-
RE: MacOS Issue: Resolved. Thank You
-
MacOS issue. Running Unraid 6.12.8 with Enhanced macOS interoperability set to Yes. With the latest Recycle.Bin 2025.01.28, cannot copy & paste files to Unraid using Mac’s Finder app. After the paste, the file on the server shows as greyed out and cannot be read, but can be dragged to the trash can. Tested using Sequoia 15.3 and Big Sur 11.7. Reverting Recycle.Bin to 2024.11.17b resolves the problem. Verified this behavior on an Unraid 6.12.8 VM with no other plugins installed.
-
The check has been running for a while now, without errors. Thanks
-
Running 6.12.8 My array has 2 parity disks. I was in the process of rebuilding parity1 onto a larger disk. About half way through, I paused the rebuild to do some significant array access. Upon resuming the rebuild, the following showed in the syslog. Apr 8 22:04:41 Tower7 emhttpd: writing GPT on disk (sdj), with partition 1 byte offset 32KiB, erased: 0 Apr 8 22:04:41 Tower7 emhttpd: shcmd (161402): sgdisk -Z /dev/sdj Apr 8 22:04:42 Tower7 root: GPT data structures destroyed! You may now partition the disk using fdisk or Apr 8 22:04:42 Tower7 root: other utilities. Apr 8 22:04:42 Tower7 emhttpd: shcmd (161403): sgdisk -o -a 8 -n 1:32K:0 /dev/sdj Apr 8 22:04:42 Tower7 kernel: sdj: sdj1 Apr 8 22:04:43 Tower7 kernel: sdj: sdj1 Apr 8 22:04:43 Tower7 root: Creating new GPT entries in memory. Apr 8 22:04:43 Tower7 root: The operation has completed successfully. Apr 8 22:04:43 Tower7 emhttpd: re-reading (sdj) partition table Apr 8 22:04:43 Tower7 emhttpd: shcmd (161404): udevadm settle Apr 8 22:04:43 Tower7 kernel: sdj: sdj1 Apr 8 22:04:52 Tower7 kernel: mdcmd (38): check resume Apr 8 22:04:52 Tower7 kernel: md: recovery thread: recon P ... The rebuild completed successfully. I now need to determine if the contents of parity1 are valid. Since a non-correcting parity check would take almost a full day, I’m looking for an opinion as to the condition of parity1. If it is thought it is valid, I will do the non-correcting parity check. If not, I assume the way to proceed is to stop the array, wipe parity1 and redo the rebuild without pausing. tower7-diagnostics-20240409-1328.zip
-
Check out the USB Manager plugin. It allows you to pass individual usb devices/ports to a vm.
-
Once “Everything is a Pool”, the ability to start and stop pools individually.
-
A significant portion of the value of unraid comes from the awesome collection of plugins and dockers created by the community. In the long term, it will be almost impossible for those creators to support older versions of unraid. In fact CA itself will no longer support the very stable 6.11.5. So most people actively using unraid will be forced to keep upgrading.
-
Just an FYI Getting a lot of these in the syslog Jan 30 12:36:21 Tower7 Parity Check Tuning: ERROR: marker file found for both automatic and manual check P Q I had an unclean shutdown. The array is set to not auto-start. After power cycling the server, I unchecked the box to correct parity, before starting the array. A correcting parity check started anyway. Unraid 6.11.5, Parity Check Tuning 2023.12.08 tower7-diagnostics-20240130-1358.zip
-
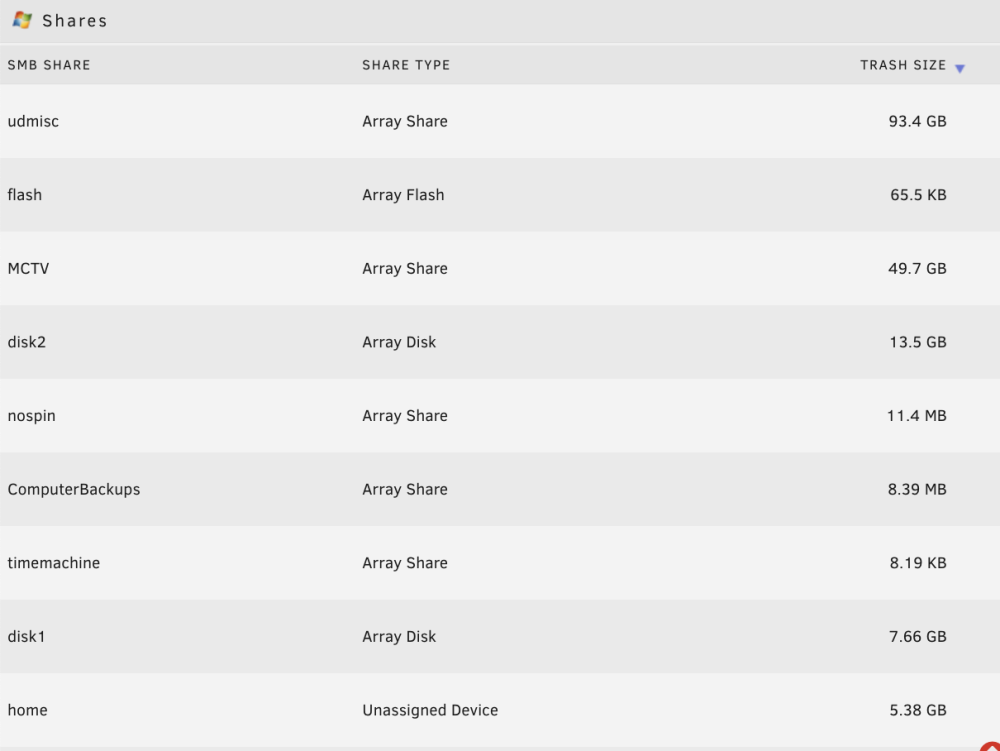
Minor cosmetic issue. If you go to the Recycle Bin settings page and sort the shares by Trash Size, the list is sorted by the number of (GB, MB), ignoring the fact that GBs are larger than MBs.
-
Try these switches to the ls command ls -lsh total 151M 65M -rwxrwxrwx 1 nobody users 20G Dec 30 15:02 vdisk1.img* 86M -rwxrwxrwx 1 nobody users 10G Dec 30 15:02 vdisk2.img* The size on the left is the allocated space.
-
Thanks for the insight. I did some additional testing. Client access to a UD share on exFat over smb is flakey if "Enhanced macOS interoperability" is enabled. I have not observed this problem with any other partition type, including FAT32, which also doesn't support extended attributes. Manually editing the share's samba config, removing streams_xattr, and restarting samba seems to resolve the issue.
-
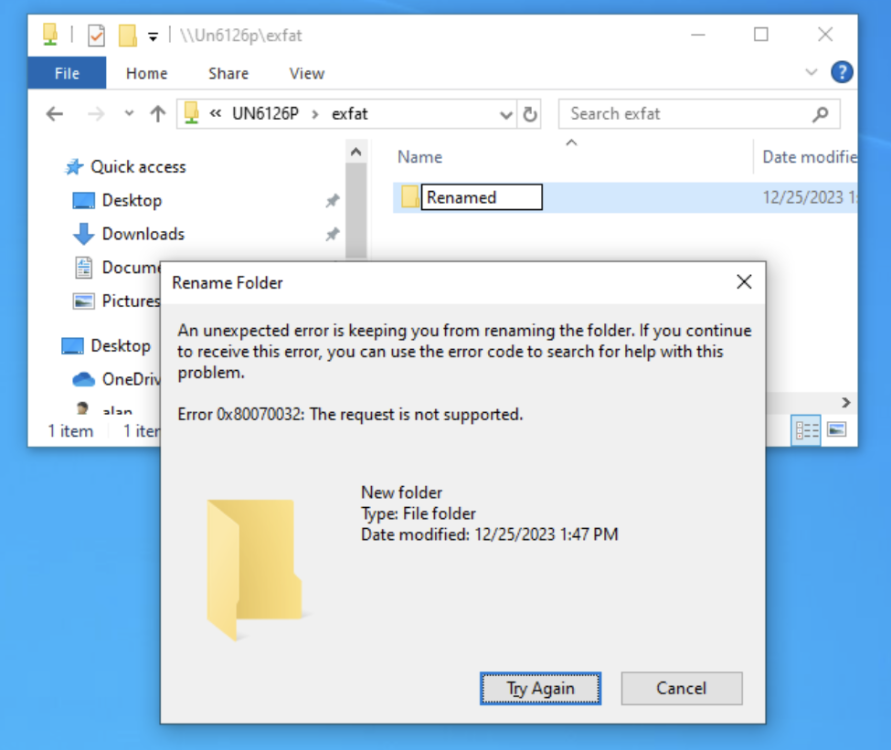
I am having trouble renaming folders on exFat formatted UD mounted disks. This is an example from Windows 10, although MacOS and Ubuntu are having issues as well. I believe this is a recent problem, since I am often using exFat disks in UD since they are OS agnostic. Unraid 6.11.5 or 6.12.6 UD 2023.12.15 UD Plus 2023.11.30 The share is public. un6126p-diagnostics-20231225-1627.zip
-
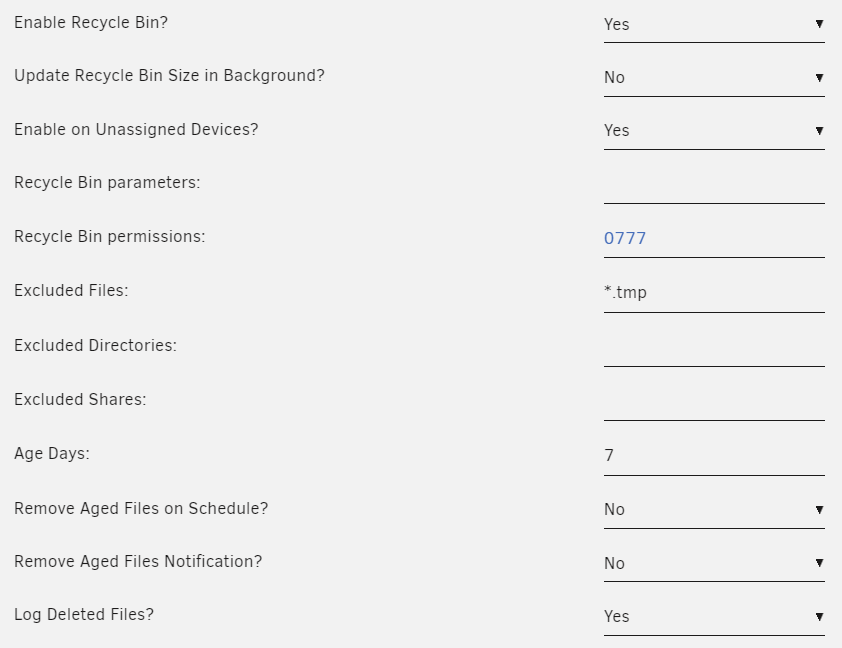
I’m running 6.11.5, and after updating the plugin to 2023.02.20, I’m still having instances of folders in the recycle bin with their files missing. However, my usage is probably uncommon. My apps are configured to use user shares, but interactively, I use disk shares. During testing, deletes were done from a Windows client. In all test cases, I am deleting: \\Servername\DiskOrPoolName\UserShare\FolderWithFile If the user share resides on an array disk (they are all Use cache pool=no), the folder and file show up in the disk’s .Recyele.Bin folder as expected. If the user share resides on the cache pool (they are all Use cache pool=only), the folder appears in the pool’s .Recycle.Bin without the file. The strange thing is, during testing I created a new user share in the cache pool, and it is working as expected. None of my other pools had previously defined user shares, and newly defined shares work ok. tower7-diagnostics-20230403-1145.zip
-
Sorry, was on the wrong docker hub tag page
-
@binhex, FYI Trying to explicitly specify Repository binhex/arch-qbittorrentvpn:1.31.1.6733-1-01 fails with Unable to find image 'binhex/arch-qbittorrentvpn:1.31.1.6733-1-01' locally docker: Error response from daemon: manifest for binhex/arch-qbittorrentvpn:1.31.1.6733-1-01 not found: manifest unknown: manifest unknown. Building with :latest works fine, which assume pulls the same version.
-
Works now. Thanks
-
plugin: downloading: https://raw.githubusercontent.com/itimpi/ parity.check.tuning/master/archives/parity.check.tuning-2023.02.10.txz ... failed (Invalid URL / Server error response)
-
I wouldn't expect NerdTools to include every package that the community wants to run. What is the effect of using NerdTools for some packages and manually adding others to /boot/extra?
-
Even after upgrading to 2022.10.25a and rebooting, smbd_audit messages are appearing in the syslog. Running Unraid 6.9.2. tower7-diagnostics-20221026-1214-B.zip
-
Can we assume that all of the packages that were in Nerdpack will be migrated to Nerdtools?
-
I've experimented with echo '1' > /sys/block/sdX/device/delete and it gave me a warm and fuzzy before powering off a device. But sometimes I wanted to remount the device without unplugging it first. However, it had disappeared completely. Even doing an UD Refresh Disks wouldn't bring it back. Research lead me to echo 1 > /sys/class/scsi_device/<scsi bus>/device/rescan which was successful. But there was no way to tell which bus the disk was on unless you noted it before the device delete. If you implement the above, please include a way to bring back the disk.
-
Same issue as





