




Autchirion
Members
-
Joined
-
Last visited
Everything posted by Autchirion
-
So, please let us know the new name of Pinocchio (credit to @NLS) or what you decided... Because this night I a warning in Fix Common Problems: The plugin folder.view.plg is not known to Community Applications and is possibly incompatible with your server
-
Sorry, wasn't a great explaining job, so now enjoy my equally great painting skills! Current solution is: sum of all read speeds (including parity) = array read speeds (and vise versa for write) in the picture: sum(red)=blue What I want: sum off all read speeds (not including parity) = array read speed (and vise versa for write) in the picture: sum(green)=blue since I see that people might be interested in the current solution as well I'd suggest a switch for the two different solutions. Background: If I transfer data, I know the sum of all the data transfers running and with the sum of write speed I can estimate how long it's going to take. With the current solution I'd have to divide it by half (not a hard task, I agree, but I'm still a moron enough to forget it every time I do a write to multiple drives). Absolutely a very minor thing to do, but it would be a qol improvement for me.

-
This would enable a better estimation of data transfers. I’m right now transfering data to multiple disks and reading from some others. So the data written to the parity drive is for me no information, since this doesn’t really transfer data.
-
I'm running a fresh install of the container, but after start I get: => Searching for scripts (*.sh) to run, located in the folder: /docker-entrypoint-hooks.d/before-starting and it will just stop there, I checked, there are no scripts in this folder. I added one (just an echo command) it's getting called. So I assume it's something happening after this. I quite don't understand what's going on. When pulling the container I'm getting: IMAGE ID [a480a496ba95]: Already exists. So I'm not sure if this might be the culprit, but I don't think so, it's quite common, that an image already exists... fyi, I had major issues with my server, but it should be back to normal and all other containers are working fine. I just checked, this happens for every nextcloud I'm pulling, so even nextcloud-ffmpeg is showing the same behavior.
-
I assumed so, so I tried to regenerate them, following this guide: https://unix.stackexchange.com/questions/741404/overwritten-luks-with-a-partition-table/741850#741850 however, when I run stdbuf -oL strings -n 64 -t d /dev/nvme0n1 | grep '"keyslots":' I get two headers, but I also got two keys, so right now I just tried to go with the two lines where he only gets one. So right now I'm trying to find the correct header and get some input from someone who can help me with luks headers (especially if there are two 🙂 )
-
hey guys, I just had a short failure of power and after rebooting unraid didn't add the drives back to my cache (eventhough they were still visible in unmounted devices). So added them back, unfortunately in (most likely) the wrong order. So after that, I shut down the server and exchanged the disk.cfg and super.dat on the usb stick with an backup I had from this night using my windows PC, booted it up, but it's still not working. I'm getting "unmountable: unsupported or no file system". The FS is zfs (encrypted). Any suggestions on how to tackle this further? The Cache drives are mirrored, so I'm also wondering how I can mount at least one of them manually to not loose any data (nightly backup was done, but there are some changes). [UPDATE1] running cryptsetup luksOpen /dev/nvme0n1 my_encrypted_volumecryptsetup luksOpen /dev/sdd my_encrypted_volume returns: Device /dev/nvme0n1 is not a valid LUKS device. cryptsetup --debug luksDump /dev/nvme0n1 outputs: # cryptsetup 2.6.1 processing "cryptsetup --debug luksDump /dev/nvme1n1" # Verifying parameters for command luksDump. # Running command luksDump. # Installing SIGINT/SIGTERM handler. # Unblocking interruption on signal. # Allocating context for crypt device /dev/nvme1n1. # Trying to open and read device /dev/nvme1n1 with direct-io. # Initialising device-mapper backend library. # Trying to load any crypt type from device /dev/nvme1n1. # Crypto backend (OpenSSL 1.1.1v 1 Aug 2023) initialized in cryptsetup library version 2.6.1. # Detected kernel Linux 6.1.106-Unraid x86_64. # Loading LUKS2 header (repair disabled). # Acquiring read lock for device /dev/nvme1n1. # Opening lock resource file /run/cryptsetup/L_259:0 # Verifying lock handle for /dev/nvme1n1. # Device /dev/nvme1n1 READ lock taken. # Trying to read primary LUKS2 header at offset 0x0. # Opening locked device /dev/nvme1n1 # Verifying locked device handle (bdev) # Trying to read secondary LUKS2 header at offset 0x4000. # Reusing open ro fd on device /dev/nvme1n1 # Trying to read secondary LUKS2 header at offset 0x8000. # Reusing open ro fd on device /dev/nvme1n1 # Trying to read secondary LUKS2 header at offset 0x10000. # Reusing open ro fd on device /dev/nvme1n1 # Trying to read secondary LUKS2 header at offset 0x20000. # Reusing open ro fd on device /dev/nvme1n1 # Trying to read secondary LUKS2 header at offset 0x40000. # Reusing open ro fd on device /dev/nvme1n1 # Trying to read secondary LUKS2 header at offset 0x80000. # Reusing open ro fd on device /dev/nvme1n1 # Trying to read secondary LUKS2 header at offset 0x100000. # Reusing open ro fd on device /dev/nvme1n1 # Trying to read secondary LUKS2 header at offset 0x200000. # Reusing open ro fd on device /dev/nvme1n1 # Trying to read secondary LUKS2 header at offset 0x400000. # Reusing open ro fd on device /dev/nvme1n1 # LUKS2 header read failed (-22). # Device /dev/nvme1n1 READ lock released. Device /dev/nvme1n1 is not a valid LUKS device. # Releasing crypt device /dev/nvme1n1 context. # Releasing device-mapper backend. # Closing read only fd for /dev/nvme1n1. Command failed with code -1 (wrong or missing parameters). cryptsetup repair /dev/nvme1n1 outputs: WARNING! ======== Really try to repair LUKS device header? Are you sure? (Type 'yes' in capital letters): YES Device /dev/nvme1n1 is not a valid LUKS device. So it seems like the the luks header has been damaged, so I'm looking for a way to repair it. Thank you in advance Autchi
-
I just ran some more tests, and it seems not to be fritzbox related. So here is what I did: create VPN tunnel between a server on the internet and unraid ping6 my unraid server -> responding ping6 my docker container -> not responding create VPN tunnel between a server on the internet and fritzbox ping 6 my unraid server -> responding ping6 my docker container ->responding 3. and 6. indicate, that there is an issue communicating from the host to the container via macvlan. This does not not prove that it isn't the fritzbox, but it reduces the probability. So, I think there is an issue communicating from the host to the container via IPv6.
-
Ok, great, I was so happy to get a fritzbox because they seemed more customizable compared to the vodafone station. Let's assume it's an issue with the FritzBox, Do you know by any chance, if I add my own DHCP Server would this override the IPv6 shit they are doing? I mean, basically I could forward the prefix to my other router which than handles all the DHCP (v6) related topics. Anyways, I attached the diagnostics. mano-server-diagnostics-20240917-1406.zip
-
Hey Guys, I'm at a loss here, I've got multiple docker containers running on my unraid server which are having their own ipv4 + ipv6 address (using macvlan). I can access them from all my services from the network but I can not even ping them from my unraid server itself on their IPv6. I've got another server running ubuntu which has the same issue. @MAM59 posted "...the Fritzbox handles V6 very poorly and utterly wrong. It will be hard to impossible to train it it use a "good" address, switching the dockers to static wont help you because your prefix is dynamic... BAD LUCK!!!" here I'm also using a FritzBox, so I'm wondering if this is related to this or if this is just a misconfiguration on my side. Have a great day Autchi
-
Hey Guys, I got a good deal on a NVIDIA K80 and would like to utilize it for different docker containers (instead of my GTX 1070). Is there a guide somewhere how to do this with unraid? I saw some for other operating systems, but it seems like the K80 is unliked in unraid. 🙂 Right now, even NVIDIA SMI doesn't recognize the card or outputs something, so I'm assuming there is something wrong with the driver, since it was working on my windows machine with GPU-Z. Thank you in advance Autchi
-
actually, this might even destroy it! This does reset the user:group to nobody:nobody and read write to 777. If I do that to my data nextcloud won't start!
-
Hey Guys, I've got a share /mnt/user/nextclouddata where I store all my data for nextcloud. This is not in appdata since I want appdata to be exclusively on the cache to speed it up without the the /mnt/user overhead. Nextcloud requires the data folder to be owned by 33:33 with the rights 770. However, every now and then (not sure when) it's being reset to 777 and nobody:users. Is there any way to prevent this? Every time this happens my nextcloud is giving me a warning that this happened and just stops working. Thank you in advance, Autchi
-
acupsd.org seems not to exist any more (but rather is being forwarded to sourceforge). The link in the ups settings which leads to http://apcupsd.org/manual/manual.html doesn't work any more.
-
As soon as I change the CPU pinning for at least one container and hit "apply" it will only show "Please wait..." with a spinning wheel in the UI which will never end. I tried it with Containers on and containers off and I checked the log for error messages while doing so. No error message commes up, it just seems like it's doing nothing.
-
Hey Guys, I'm getting an error "chmod(): Operation not permitted at /var/www/html/lib/private/Log/File.php#86" in my log lately. There are two issues I'm observing: Attachements to E-Mails aren't being uploaded (sometimes) when the container gets an update, I have to edit the template and click save, so that it completely reruns all commands. Any Ideas what's going on? Extra Parameters: --user 99:100 --sysctl net.ipv4.ip_unprivileged_port_start=0 Post Arguments: && docker exec -u 0 nextcloud_prod /bin/sh -c 'echo "umask 000" >> /etc/apache2/envvars' && docker exec -u 0 nextcloud_prod /bin/bash -c "apt update && apt install -y libmagickcore-6.q16-6-extra ffmpeg imagemagick ghostscript" && docker network connect redis nextcloud_prod && docker network connect mariadb nextcloud_prod
-
you just edit the template and add these two as environment variables, be aware to edit the values in <> to your needs. Also, the phone app does not support oauth, so your uses still need a password if they want to use the app. SOCIAL_PROVIDERS: allauth.socialaccount.providers.openid_connect SOCIALACCOUNT_PROVIDERS: { "openid_connect": { "SERVERS": [ { "id": "authentik", "name": "Authentik", "server_url": "https://<auth.domain.tld>/application/o/<appname>/.well-known/openid-configuration", "token_auth_method": "client_secret_basic", "APP": { "client_id": "<your client id>", "secret": "<your secret>" } } ] } }
-
I just updated to the version 11.3.2 which was released 7h ago, since then mariadb is broken. I had to roll back to a backup from tonight and go back to version mariadb:11.2.3. Anyone else facing this issue? I wasn't able to connect any more, every time phpmyadmin/own scripts/nextcloud tried to connect it would resolve in an errormessage posted in the log.
-
I'm starting to get rid of login screens and using authentik to authenticate at basically every service I'm hosting myself. Add support for any other authentication method in order to be able to use authentik or other identity providers to log into Unraid. Examples: *arrs are using basic auth jellyseer supports LDAP nextcloud supports oauth2 so basically everything on my network supports this by now so the only service I have to login at the moment is unraid. With the future of passkeys and other authentication Unraid should support more possibilities to log in. Of course HTTP Basic Auth might be the best option, since it allows users to still use the login screen and this is way less effort than implementing oauth2 into the root user.
-
Not really, I deleted my docker.img and recreated it. While doing this I changed all CPU assignments, so right now I don’t need to fix it any more.
-
It is made to handle bursts, but sometimes these bursts are to big in size to be handled by the cache. I was hoping to find a solution without throwing money (aka bigger cache, not reusing my first SSD) at it.
-
Yeah, my Problem is, cache is only 120GB, if I set it to e.g. move only at 80% I'd need to run it every 3.4 Minutes (assuming 1Gbit/s upload rate which is my home network speed) to make sure it never fills up.
-
yes, I expected this, damn it. 🙂
-
Somehow it seems to me, that moving when the cache is full isn't working. I've got a share with the "Move All from Cache-Yes shares when disk is above a certain percentage" yes. Two caches (Naming Cache and Datacache), where for this share the Datacache (~120GB) is used I'm downloading ~100 files with ~2GB each, files are beeing pre generated (~1KB) and then after this filled with data. -> Mover isn't being activated when Datacache is 80% full. I'm not sure if I set up something wrong or if this usecase isn't covered by mover tuning. [EDIT] since it sounded similar, cache.cfg and datacache.cfg exist, I'm not sure if it is case sensitive, because the filename is lowercase, but the first letter of the Cache Name in the UI is uppercase. Mover Tuning - Share settings: Mover Tuning Settings:
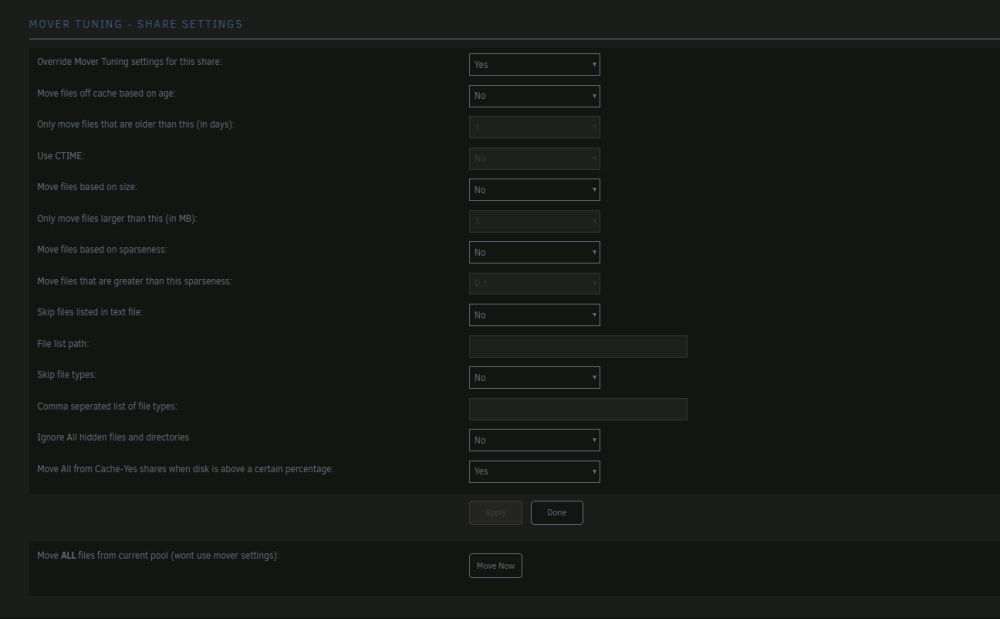
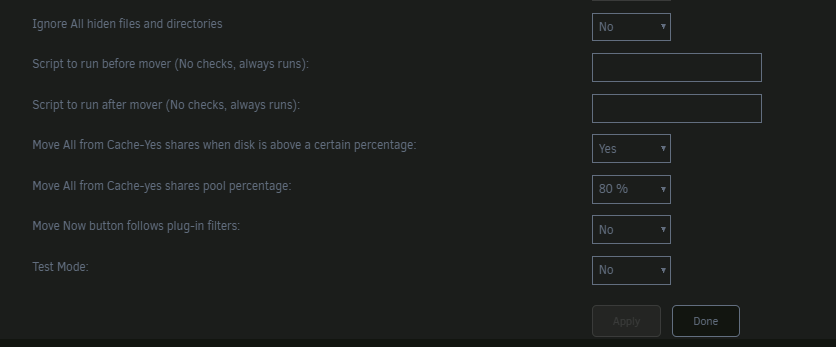
-
Thank you for your reply! Sorry, native languate isn't english, so sometimes I still think I made something clear, but obivously didn't. You are right, this happens if the users start the transfer at the same time. Of course this won't work and I should have thought of this, my bad. I will need to increas the Min Free Space zu users * max filesize obviously to cover this usecase as well. Is there any way to invoke the mover when the min free space is hit? This way I could move all the finished files while the new files are written, so I don't have to increase the min free space to a massive size. I checked mover tuning, but I didn't see an option for this. [edit] learned that move tuning allowed exactly what I want, start moving (per share setting) as soon the drive is about to be full.
-
Hey Guys, I'm running a nextcloud server where I sometimes get the issue that the cache is running full. This occurs, whenever we are uploading Video Files into one folder. Each file is smaller than the cache, but together they are way bigger and the upload happens before the mover is scheduled. So I expected as soon the Minimum free Space gets hit, the next file will automatically be written to the array. However, this does not happen, at least not if everything is in one folder or e.g. multiple folders are bigger than the cache together (so each user would upload his files into his own folder, but they start uploading before the cache is "full") . This is causing me quite a headdache, and I'm not sure what to do. So, can't I tell unraid to just move the files to the array from now on, even if it would mean to split up the folders over cache and array? In generall, this is possible, if the mover took place, the folder is on the array and now we are adding some more files to this folder. Alternatively, can't we invoke the mover for this specific cache as soon as free space < min free space? Are there any other options to prevent file loss for huge writes to my cache? I mean, the files individually are relatively small, we are recording using 4k video max, so it's not like that one file can exceed the 120GB of cache drive I'm using. Thank you in advance, Autchi



