




WalkerJ
Members
-
Joined
-
Last visited
Everything posted by WalkerJ
-
I am having this same, or very similar, issue on v2024.12.23a when trying to use Gather. When it happens the UI is completely crashed and I have to stop/restart the plugin before I can interact with it again.
-
The 1.6 version has a couple of issues. Missing closing quotation marks on lines 95 an 101 prevent it from running, and "preogram_dir" is misspelled on line 49 which makes that check fail silently. The version number returned from -V was incorrect, also. Here's an updated file with those issues fixed. unRAIDFindDuplicates v1.7.zip
-
I just tried installing it for the first time and am getting the same error. I tried several different UI options with the same result. Edit... the Fooocus UI works, but some of the others do not.
-
Fix Common Problems is saying "Realtek R8125 NIC found" and suggesting that I install this plugin. When I check Tools->System Devices, my built-in NIC reports as "Realtek Semiconductor Co., Ltd. Killer E3000 2.5GbE Controller (rev 06)". System drivers says that I have "r8169 - RealTek RTL-8169 Gigabit Ethernet driver" in use, but no mention of 8125. Is this a false positive with Fix Common Problems? I have some flaky issues with browsing shares occasionally, long delays to load the folders and files, but I'm not sure it's related to the network card. The server has an i7-13700k with 64GB RAM, so CPU/RAM should not be an issue.
-
I had a Zerotier container running. I disabled both it and the built-in Wireguard VPN and the container still fails to start with the same error: "possible DNS issues, exiting..." There must be something different about how the Deluge container starts the VPN vs how the QBT one does because the QBT one works fine, but the VPN setup in init.sh is identical for both. I am not enough of a Docker expert to investigate much further myself.
-
This container stopped working for me after upgrading to 6.12, also, and I was already bridge networking. The symptom is the VPN can't connect because of "possible DNS issues". That could be because it just can't connect to anything due to a networking issue. I had been running 6.12 RC5 for a while, and I don't think I had any issues then. It only broke after upgrading to 6.12 final. I tried two different VPN providers with the same result. The binhex-qbittorrentvpn container works fine, though.
-
My VM's have been randomly crashing. I've done dozens of tests for two weeks and there is no evidence of hardware being to blame. Is there something in libvirt.img that could cause something like this? Should I rebuild my Unraid USB? Here are some details: After lots of troubleshooting I've found that Prime95 will crash any of the VM's instantly when running the small or smallest FFT torture test. It crashes the second I click the start button and the temp never goes above 45 C. It only crashes the VM and doesn't affect Unraid. Booting the server with Windows instead of Unraid and running the same tests directly on the server rather than from a VM doesn't cause a crash, and in fact it spikes the temp to 100 C (which is the default thermal throttle temp for a 13700k, and Intel says is an OK temp for that CPU) and continues to run completely stable in spite of the temp. (The VM's were crashing randomly before. I started testing with Prime95 because it can cause them to crash on demand.) I've tried everything else possible with the hardware, BIOS settings, and Unraid and VM settings. I've set the Tjmax in BIOS to 65C to prevent the CPU from going higher than that, and set max power draw to 235w, and it still crashes. There's no correlation between the temp/power and crashing. The problem is also 100% not RAM related. I've tried different RAM, one stick or two, and lowering the RAM speed to half of stock. The VM's still crash in all scenarios. I replaced the power supply with a brand new Seasonic 850w, which is more than double what the system really needs. If the problem were the CPU or motherboard (or any of the hardware) it would crash running the torture tests locally rather than through a VM because it's using more cores than I had allocated to the VM, and the temp goes much higher. There's nothing helpful in any of the logs. Here's my original post...
-
That was the issue. I used their config builder to create a new config file and it worked with the latest image. I left in the line "comp-lzo adaptive" and it seems to work, in spite of an earlier post saying that the comp-lzo line had to be removed.
-
Removing the "compress" line causes errors and the VPN never connects. I rolled back to 4.4.5-1-01 for now until this gets sorted out.
-
It's crashing with both Windows and Linux guests (Ubuntu & Clear Linux). Some are old, others I just created from scratch. I don't think it's the guest, but I'm not sure where to go next. I tried undervolting the CPU and setting a CPU power limit, but it didn't change anything. I also ran Memtest and there were no errors. I also tried limiting a VM to only 2 cores, and enabled hugepages. Update... I tried restoring a libvirt backup and moving the VM IMG to a different disk (from cache to array) - same result. I also tried running Prime95 instead of the app I usually use in these VM's. It crashed just the same with Prime95, so it's not something specifically to the apps I'm using in the VM. Update 2.... I updated Unraid to 6.12.0-rc2 and get the same result.
-
I tried this and it got rid of the split log messages in the log, but the VM's still crashed.
-
All of my VM's just started crashing today. AFAIK nothing has changed with the VM or Unraid. The rest of Unraid and multiple Docker containers are unaffected. I tried a VM I haven't started for months (so it's on a much older version of Windows 10) and it crashed the same way. One of them is using a RAW image, the other Qcow2. Hardware is i7 13700k with 64GB RAM. I have tried searching the forums and Google, and rebooted the Unraid server. I tried updating VirtIO drivers, expanding the Vdisk to make sure it's not out of space, and disabled Windows Defender. I also changed which CPU's were assigned so that only the P-cores were assigned to the VM, but it didn't make a difference. It seems to be OK as long as I just boot it and leave it idle. As soon as I run something that uses the CPU, it crashes. In particular I am running an old Java 8 based application that I use for my business. I doubt the particular app or Java is the root cause because this app is ancient and hasn't changed since 2017. I've been running this app on VM's on Unraid for years and it has run flawlessly until today, and on this server for about 6 months. I just created a new VM from scratch using a freshly downloaded Windows 10 ISO. I didn't install any Windows updates and only install the aforementioned Java app. It crashed the same way as soon as I tried to run the Java program. I'm not trying to pass through GPU or sound. All of my VM's are vanilla Windows 10 installs. The last thing in the VM log when it crashed is the following, then a register dump. I don't think the spice-server bug is the issue because I've seen it on VM's that didn't crash. Syslog, VM log, and VM XML are attached. I tried running the same Java app on a Linux VM and it froze but didn't crash to the point of doing a register dump. I could still connect with VNC, but everything was frozen and there was no CPU usage according to Unraid. char device redirected to /dev/pts/1 (label charserial0) qxl_send_events: spice-server bug: guest stopped, ignoring error: kvm run failed Invalid argument voyager-syslog-20230407-2319.zip UnraidVMlog.txt UnraidVM.xml
-
There are no lines with 'comp-lzo' in the config file. There is a line that says 'compress'. Is that related?
-
I am getting this error also, and the container can't connect to the VPN/internet.
-
I've been having to restart the API every couple of days to resolve this. Restarting it fixes the issue immediately but it eventually returns. It started for me the same day OP posted this thread. I'm on 6.11.5.
-
Supervisord.log is filled with just this, repeating about 100 times per second. I rolled back to the previous version of the image and it ran with no errors. 2023-02-13 08:16:50,648 DEBG 'start-script' stdout output: Options error: Unrecognized option or missing or extra parameter(s) in /config/openvpn/TorGuard.ovpn:34: ncp-disable (2.6.0) Use --help for more information. 2023-02-13 08:16:50,649 DEBG 'start-script' stdout output: [info] Starting OpenVPN (non daemonised)... 2023-02-13 08:16:50,651 DEBG 'start-script' stdout output: Options error: Unrecognized option or missing or extra parameter(s) in /config/openvpn/TorGuard.ovpn:34: ncp-disable (2.6.0) Use --help for more information. 2023-02-13 08:16:50,651 DEBG 'start-script' stdout output: [info] Starting OpenVPN (non daemonised)...
-
I'm seeing the same issue with the same symptoms and log errors.
-
I just ran into an issue with the share watch feature not working in the ChangeDetection.io Docker. I contacted the developer and this is what he said. Does this mean that something with the Unraid version of the container needs to be changed or fixed? https://github.com/dgtlmoon/changedetection.io/discussions/1364#discussioncomment-4815864
-
The checkboxes were the problem with email. I was so curious what is actually happening that I downloaded the source. The documentation says that if you check "Profile is scheduled", it will "send an email when the profile is run from within a cronjob". This is only true, however, if "--no-questions" is passed as an argument to the command. That argument gets added to the command line if you check "Console mode" when saving the schedule. I just tested this and it does work and makes the checkboxes on the email screen behave more like you would expect. I don't understand why this email setting and console mode are linked, or if they even should be. If --no-questions is not specified, I think the status of the "Error" checkbox gets ignored because there's an "or" comparison between the two checkbox states. I suspect that is a bug. It doesn't look intentional the way the code is written - at least I wouldn't have written it that way. Restarting the container does let the GUI see the logs files. I think that it only reads the settings and checks the log folder when the GUI starts up, which is why you have to restart the container. AFAIK there's no reason it couldn't read the log folder when you click "Manage Backup", it just doesn't.
-
@ich777 - I spoke too soon. The email part does work when I click the test button, but not when a job actually runs. I don't think the issue is email related, though. When I go to Tasks->Manage Backup->View Log I get "Could not open the logfile!! No such file or directory". However, if I log into the Docker console and run "ls -l luckybackup/.luckyBackup/logs", the logs are there and the jobs ran successfully. Is it possible that the GUI and whatever triggers the email is looking for a different path than what is scheduled via cron? I installed the container with all of the defaults and running jobs interactively or scheduled works fine.
-
Thank you for posting this tip on adding the username and password to the arguments. I can confirm that it works and can send email through a Gmail account using App Passwords as of 3-21-2022. Here's an explanation of Gmail App Passwords for anyone that isn't familiar: https://support.google.com/accounts/answer/185833
-
I haven't used a root share before. This seems like an improvement vs how it sounds like it was done before. But why does the plugin create a /mnt/rootshare folder even when the rootshare feature isn't being used?
-
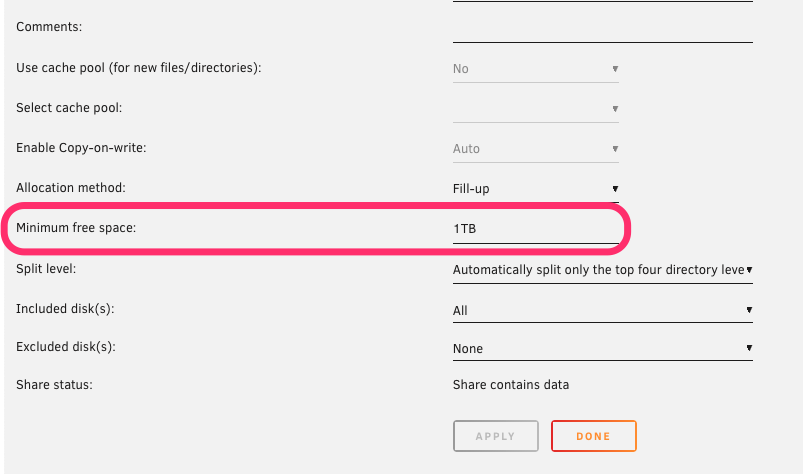
I didn't think I had any 4th level folders that would conflict with a 1TB free space setting, but maybe I do. I figured there had to be precedence rules but didn't know what they are. Are there other undocumented precedence rules? This precedence behavior is not mentioned in the docs nor in-line help under split level or minimum free space. After seeing your reply I found the comment below that I completely agree with. This behavior is counterintuitive and undesirable in most circumstances. There should at least be a setting to choose which takes precedence.
-
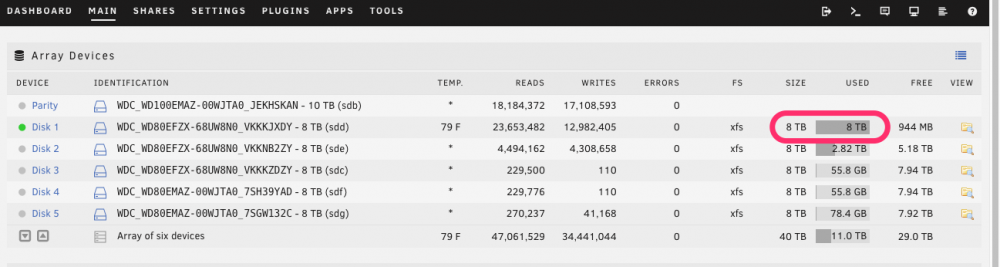
I just build a new Unraid server to act as a backup from my original. I created one share to receive the backups from the LuckyBackup docker running on the main server. I mounted the share via NFS through unassigned devices. I started the backup last night and opened the dashboard today to find a screen full of disk full warnings. The minimum free space on this share is set to 1TB but it wrote the drive to within 1GB of being full, even though there is almost 30 TB of free space on other drives (3 of them are empty). There is no cache pool on this server. All of the data on drive 2 was moved there manually. I'm not sure the share has written any data to drive 2 from the NFS connection. Is Unraid supposed to respect the minimum free space setting over NFS? What else could be happening?
-
If you're talking about the category save paths, it looks like that has been fixed. The release notes contains this update, and I just updated to the 4.4.1 version of this container and it's fixed for me. WEBUI: WebAPI: fix wrong key used for categories (Chocobo1) This isn't the first time this bug has happened, and each time it was just a display issue. The paths were still saved and used, but when you went back into the edit dialog it was blank.



