



.png.a98a80c78b81d2e8f977d9bb26103ff9.png)
DesertCookie
Members
-
Joined
-
Last visited
-
Can confirm that you need to add your chat id with echo "MyChatIDnumber" > /boot/config/plugins/dynamix/telegram/chatid. To get your own chat id, do the following (from here): Find UserInfoBot: Search for @userinfobot in Telegram. Start the Bot: Open the chat with @userinfobot and send the /start command. Retrieve Your CHAT_ID: The bot will respond with your chat ID, which is the unique identifier used by Telegram to direct messages to your chat.
-
Do you plan to somehow offer a way to find a buddy to back up with? Perhaps via a discussion thread on GitHub?
-
Ran for over a day without any issues. Now, that's half a month ago already, but I hope it's not gone bad since then. But I will retest it before and after I swap the mainboard.
-
I just started experiencing this with version 7, after having upgraded to it a few days ago after running the betas for a little while. The whole web UI went haywire too and be barely usable. It first started with the Apps page not loading, then the whole UI randomly reloading and returning to Main, where it would show all my drives popping out and back in over and over again. I think it started when I updated the Community Apps Application earlier today. There was a second update that seemed to fix it for a short while but then made it worse. A restart brought the system back to a usable state, showing three errors upon startup: ``` Jan 15 20:50:07 STower24 kernel: traps: mongod[24128] general protection fault ip:151b7d0c79a2 sp:7ffc5eab0230 error:0 in libc.so.6[151b7d0c7000+188000] Jan 15 20:50:09 STower24 kernel: traps: mongod[25705] general protection fault ip:1493b20eb9a2 sp:7fffe9d1d0f0 error:0 in libc.so.6[1493b20eb000+188000] Jan 15 20:50:12 STower24 kernel: traps: mongod[27290] general protection fault ip:1473acfef9a2 sp:7ffe7bbe1420 error:0 in libc.so.6[1473acfef000+188000] ``` Will soon swap the mainboard as that seems to possibly be wonky (threw some NIC errors that made me use a PCIe x1 NIC for now).
-
Thanks. It keeps happening with BTRFS. Already had changed my cache SSD to XFS a few months back due to other issues. Now I did the same for my Docker image. Has been more stable so far.
-
After a recent restart Docker won't start. I tried stopping the array, as well as restarting completely. I even attempted to manually restart my daemon which yielded this: root@STower24:~# /etc/rc.d/rc.docker stop rc.docker: Stopping containers... rc.docker: Stopping network... rc.docker: Stopping Docker daemon... rc.docker: Docker daemon... Already stopped. root@STower24:~# /etc/rc.d/rc.docker start rc.docker: Starting Docker daemon... rc.docker: Docker daemon... No image mounted at /var/lib/docker. rc.docker: Starting network... stower24-diagnostics-20241229-1752.zip
-
Had a lockup shortly after making this post. I've removed my parity disk since then and have had no issues for four days (let's see if that holds). For now, I'm keeping most frequently served data on the former parity HDD which I've added as a second cache pool and back that up using the Mover Tuning plugin, as well as Borgbackup for things such as Nextcloud.
-
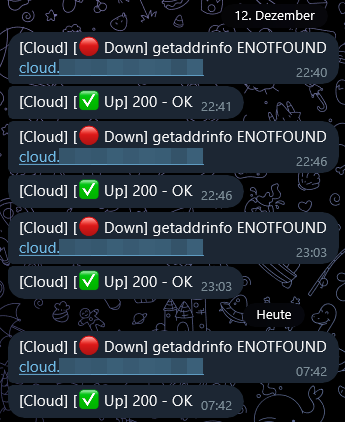
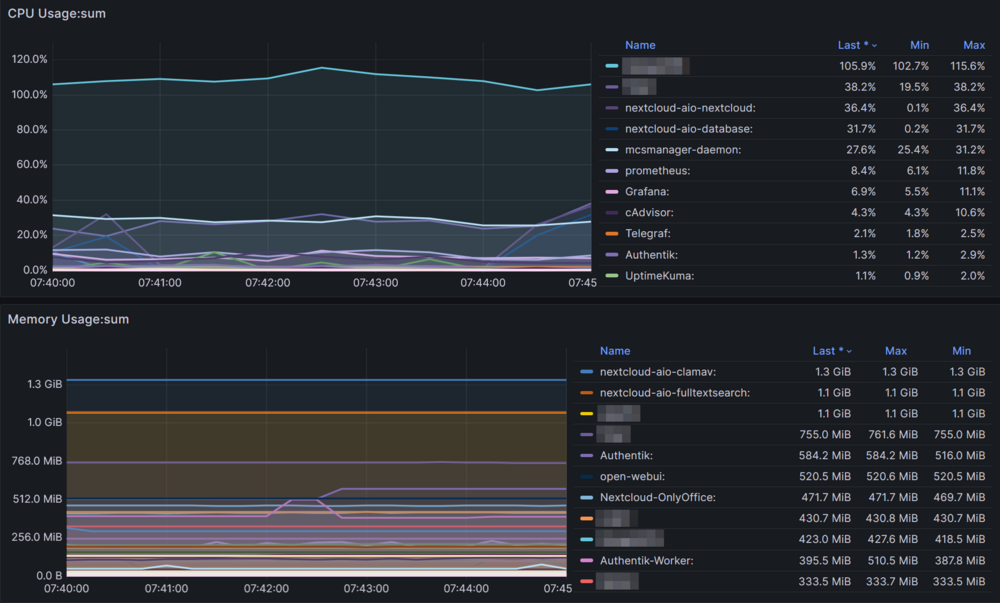
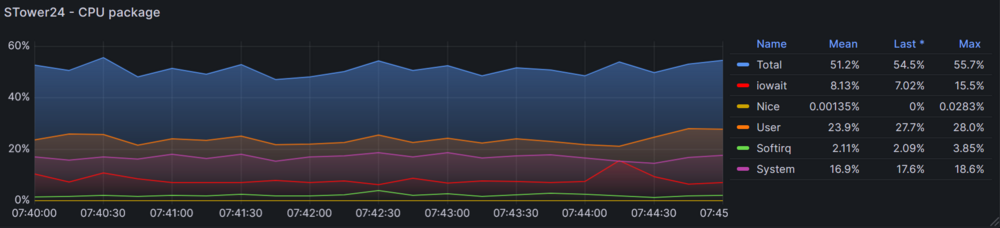
To give a little status update (I will investigate further and try to pinpoint the issue): My issue is not technically solved, but I've made some progress and have had no critical lockups for three days now. My stop-gap solution: Isolate two out of 12 threads. Also, I upgraded to v7.0.0-rc.1, but seeing as this has been an issue even in v6.x I don't see that as a major contributor to the improvements. This points at some Docker container using up too many resources or potentially causing I/O wait, which, depending on the severity, would lock up the system for minutes or hours before. Now, three days by no means indicate that I am in the clear, but it definitely is a milestone. Especially considering that my monitoring tools (Uptime Kuma) reported fewer lockups than before and all of them shorter than 60 seconds where before they would be 10-20 minutes long (or longer, but if by that point the server got locked up, monitoring would stop too which has not happened again so far). These are sub-60s timeouts on my Nextcloud server. These usually aren't noticeable, as they quickly resolve themselves without the user encountering a 504 error. Looking at the time around 7:42 today that had such a lockup, I am not able to see anything out of the ordinary in Grafana, hinting at Nextcloud being the issue; however, this wouldn't explain why other services sometimes are impacted too. I/O wait is not especially high. Overall, the highest I've seen is 24% over the past three days. Uptime Kuma, running on a secondary system now, reports numerous timeouts but ultimately only rare 60s-downtimes. Again, my main instance that only warns after downtimes of 300 seconds did not respond a single time the past days, where before it would regularly report timeouts across almost all of my services. --- A hardware issue definetely isn't out of the question. I'll leave the server running like this for a little longer to potentially find out whether it is some container or other service causing CPU usage or I/O wait. Next step would be swapping out the mainboard. After that, potentially the parity drive, as it has a read and write error rate in the millions. `sdc`, which previously threw a lot of UDMA CRC errors seems to have calmed down now with me having reseated all cables again. SMART tests pass. I'm monitoring it. In theory, it's the youngest drive in my server at 3 years power-on-time.


-
I added a TP-Link 2.5Gb NIC and reseated all SATA cables, yet continue to experience freezes. I did change some UEFI values that now allow the CPU to clock down to 800MHz on idle. stower24-diagnostics-20241206-2014.zip
-
Thanks. I don't have any PCIe cards connected. It must be the on-board 10 GbE NOC then. Darn; really didn't want to replace the mainboard. Is this a plausible cause for the server getting hung up occasionally, only responding very slowly? The ATA errors have been coming back every time I've changed ports or cables. I assume it's with the drive, but I can't replace it currently.
-
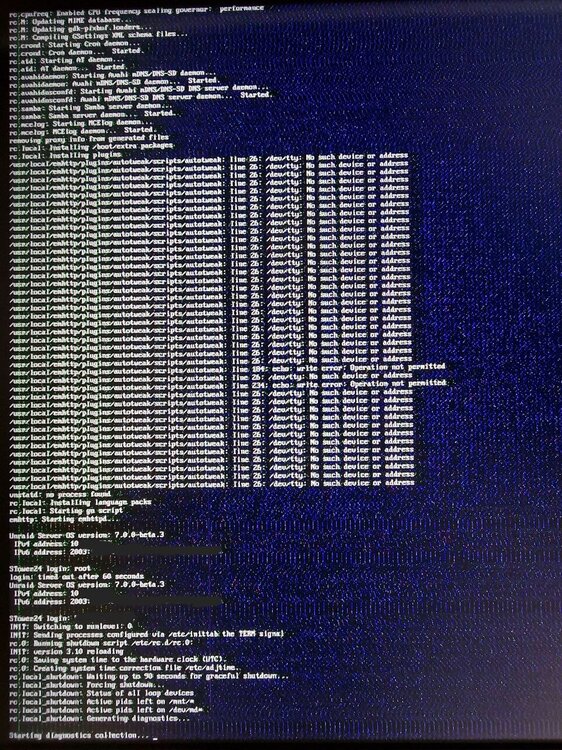
For a couple of months now, my unRAID server has been suffering from occasional lockups. Sometimes, the server would recover, most of the time not. Docker containers, even new SSH connections and the WebUI would not load most of the time. I recently managed to have an htop SSH connection running while it happened and the dashboard page open. The CPU seemed to be pinned at 100%. Culprits would change though. Even after having killed the processed pegged at 100+% in htop, the system would stay unresponsive. Any SAMBA connections made before the system locked up would still be usable, though, transferring at below 10 MB/s instead of the expected 2.5 Gb/s (to cache). I've been hard resetting the system. One time, however, I checked in via HDMI and saw the console was still up and blinking. While I couldn't log in, it would show that it was trying to shut down when I pressed the power button correctly. That one time I left it to shut down on its own. It was stuck on `Generating diagnostics` and then later on `Starting diagnostics collection...` for multiple hours until finally having turned off sometime in the night. Diagnostics and screenshot of that time are attached (the image errors on the screenshot are due to my monitor, not the server). Upgrading to v7 in mid-October seemed to solve the issue for a few weeks, but it came back soon thereafter. Rebuilding the thumb drive always seemed to buy me a week or two without issues, but considering I've changed USB ports and thumb drives multiple times now, buying brand new ones, it might be another issue still. I've tried removing unneeded devices, such as a GPU (GTX 1650) and an M.2 riser to see if those could be the culprit, but saw no change in behavior. The 11400 in this system is set in UEFI to not boost and to power saving to reduce energy consumption. Under normal operation I see around 30-50% utilization, only spiking when some Dockers transcode or run a game server. I don't experience IO-wait from my cache or array. stower24-diagnostics-20241117-1934.zip
-
Does `/usr/libexec/netdata/plugins.d/go.d.plugin` have anything to do with this plugin? I've encountered this application multiple times now using 100% of my CPU and completely locking up my system.
-
Well, one Docker container is not working properly. That alone could be an indication of a faulty thumb drive. For me, only the WordPress container and another container would have networking issues and only half the time. More than 20 other containers had no issues at all. Especially networking only requires one tiny thing to be wrong to break in unexpected ways. It literally takes ten minutes to reflash your thumb drive. Couldn't hurt to try. Again, make sure to copy your "config" dir and license file though.
-
I recently faced this issue on a frequent basis. It turned out to be a faulty thumb drive. Are you experiencing issues with other containers too? If so or if unsure, recreate your boot drive. Simply copying over the config folder will have your server start up as if nothing changed. If the issues vanished, you need to get a new thumb drive ASAP (if you haven't already).
-
Did both of these. Had enabled macvlan after some issues with Docker containers being unable to see each other; that seemed to fix it back then. tower-diagnostics-20240510-1851.zip
.thumb.png.cd783b56e03ecb7dd3cde237dc340538.png)





