




MiniKahn
Members
-
Joined
-
Last visited
Everything posted by MiniKahn
-
I have the exact same problem @Ahmad Thank you for your solution. Unraid 6.10 RC4
-
Ich schließe mich der Suche an. Und pushe damit den Thread 😃
-
Hallo nochmal, danke für euren Input. ich habe den Aspekt mit der Tiefe beachtet. jetzt steht hier ein 15HE Serverschrank, 60cm breit und 80cm tief. Vordere und Hintere Schiene und abnehmbarer Rückseite. Für einen - wie ich finde - soliden Preis. Konnte ihn persönlich im Lager abholen da ich zufälligerweise nicht weit entfernt wohne (ca. 1h). https://www.it-budget.de/19-Serverschrank-SJB-15-HE-BxT-600x800-mm-Glastuer-Rueckwand-schwarz Dazu bisher zwei ausziehbare Böden mit 55cm Fläche. Verarbeitung ist super. Platz ist ebenfalls. Bisher liegt der Unraid Server unten drin. Und sehe keinen Anlass das umzubauen. Sollte ich? Also Luftzirkulation ist gewährleistet… passt. Klar komme ich nicht schnell an die Festplatten ran. Aber dazu ziehe ich ihn einmal raus und nehme den Deckel ab. Das geht ja auch schnell…? gibts noch irgendwelche Tipps die ich beachten sollte? Liebe Grüße und danke nochmal! PS: Bild kommt ggf. Ach Fertigstellung.
-
Guten Morgen, vielen Dank! würde für meine Zwecke sorgend langen? Digitus Network Cabinet Wall Housing, 19 Inch Unique https://www.amazon.de/dp/B07FK64MMW/ref=cm_sw_r_cp_api_glt_i_7KTDDG6ZXCB5XM4FRDNA Vielleicht jetzt nicht genau der, aber so in die Richtung? 80-100cm hoch, 60 breit und 60 tief? Nur damit ich mal eine Richtung habe. 😃
-
Sorry für die dumme Frage. Stell ich dann den Tower-Pc da einfach rein? dachte es gibt vielleicht etwas, wo ich dann Mainboard usw. Draufschraube oder so. +24 Port Switch und Router. hab da wirklich keine Ahnung… sorry 😫 Platz spielt erstmal keine Rolle. Eher die Höhe. Da hab ich circa 100cm…
-
Hallo zusammen, gibt es eine Möglichkeit die verbaute Hardware in einen Serverschrank umzuziehende, in welchem gleichzeitig ein Switch und mein Router (ohne wifi) packen kann. ich ziehe demnächst um, und hab dannetwas mehr Platz. Hier würde ich dann gerne alle Komponenten in einem Gehäuse unterbringen wollen. Gibt es sowas? Bin auf diesem Gebiet absoluter Anfängern. Die verbaute Hardware ist hier im Thread aufgeführt. Nichts besonderes / massangefertigtes.
-
Du hast das doch bereits gepostet. da siehst du die einzelnen Ordner und Dateien die geschrieben werden..
-
Nun, das macht schon viel Sinn.... Ansonsten würde jeder healthcheck eines jeden Containers alle 5 oder 30 oder was weiß ich wie viele Sekunden auf deine SSD schreiben. So ist die Abnutzung schon Signifikant geringer. Möchtest du es noch weiter perfektionieren, musst du natürlich jeden Container nochmal anpassen und beispielsweise /var/log oder /log oder wie auch immer in /tmp mounten. Bei dir wurden innerhalb 4 Minuten nur 5 Dateien geschrieben. Das macht einen großen unterschied zu davor. 2021-09-09 12:50:01.754990137 +0200 /mnt/cache_raid/appdata/mariadb/databases/ib_logfile0 2021-09-09 12:50:01.605989534 +0200 /mnt/cache_raid/appdata/mariadb/log/mysql/mariadb-bin.000122 2021-09-09 12:48:55.007720243 +0200 /mnt/cache_raid/appdata/NginxProxyManager/log/proxy_host-1.log 2021-09-09 12:47:04.408275228 +0200 /mnt/cache_raid/appdata/bitwarden/db.sqlite3-shm 2021-09-09 12:46:33.447151153 +0200 /mnt/cache_raid/appdata/bitwarden/db.sqlite3-wal Ansonsten hat mir @mgutt sehr geholfen. Wir konnten ein Problem mit einem Plugin identifizieren. Er ist dran und wird sich mit dem Entwickler in Verbindung setzen. Nun läuft alles wie gewollt! Vielen vielen herzlichen Dank! Liebe Grüße
-
Hast du den Server auch neu gestartet? Bei mir wird folgendes Angezeigt: (letzter Eintrag ist der Relevante) Filesystem Size Used Avail Use% Mounted on rootfs 16G 1.3G 15G 9% / devtmpfs 16G 0 16G 0% /dev tmpfs 16G 8.0K 16G 1% /dev/shm cgroup_root 8.0M 0 8.0M 0% /sys/fs/cgroup tmpfs 128M 16M 113M 13% /var/log /dev/sda1 29G 1016M 28G 4% /boot overlay 16G 1.3G 15G 9% /lib/modules overlay 16G 1.3G 15G 9% /lib/firmware tmpfs 1.0M 0 1.0M 0% /mnt/disks tmpfs 1.0M 0 1.0M 0% /mnt/remotes /dev/md1 9.1T 4.6T 4.6T 51% /mnt/disk1 /dev/md2 9.1T 537G 8.6T 6% /mnt/disk2 /dev/nvme0n1p1 932G 68G 863G 8% /mnt/cache shfs 19T 5.1T 14T 28% /mnt/user0 shfs 19T 5.1T 14T 28% /mnt/user tmpfs 16G 12M 16G 1% /var/lib/docker/containers Kannst ja berichten, wie es dann bei dir aussieht, ob du noch Writes hast, nachdem du den Eintrag siehst. Ich weiß auch nicht was bei mir da los ist... Vielleicht wissen mgutt und ich später oder irgendwann mehr
-
Den Standard AppData Pfad habe ich ebenfalls angepasst. Mein vorgehen mag ungewöhnlich sein, ist sicher nicht aktuellster Stand der Dinge.. aber ich hab mir wirklich was dabei gedacht 😂 (Unraid sicherlich auch bei ihren Einstellungen :D) stand jetzt ist alles auf einem Share, alles zusammen, auch Appdata. Ich hoffe das passt einfach für die Zukunft! Aber herzlichen Dank für den Hinweis. Bin gespannt ob ich heute mit mgutt auf eine Lösung meines Write Problems komme, und vor allem ob es ein Fehler von mir ist …
-
Guten Morgen, ich habe mir einen extra Share angelegt, unabhängig von system und appdata, welche alle Docker Dateien gebündelt auf einem Fleck sortiert. Ich verstehe den Punkt, das wohl von Seiten unraid system für docker, und appdata für docker- appfiles gedacht ist, finde es aber angenehmer das in einem komplett eigenen Share zu haben. Dadurch ist, wie gesagt, nicht alles auf verschiedene Shares verteilt. Meine Container usw. richte ich alle händisch auf die entsprechenden Pfade ein. Finde ich so angenehmer und sehe keinen Nachteil. Sollte es einen Nachteil geben, gerne immer her damit. Kann es ja jederzeit anpassen. Die Dinge sind ja schnell passend verschoben. Liebe Grüße
-
@mgutt gerne morgen jederzeit. Hab Urlaub Am besten per PM, dass der Thread frei bleibt. Das Ergebnis kann ich / können wir ja dann hier posten. @Anym001 dadurch ist einfach die Aufteilung eleganter. Da ich kein docker Image nutze, sonder die Ordnerstruktur, habe ich alle Docker Sachen im Docker Ordner. Und diese dort nochmal sortiert nach appdata/ docker-Instanz usw.
-
Am Rande: Ist /var/lib/docker/containers intern / symlink der selbe Pfad wie /mnt/cache/docker/docker ?? bei find /var/lib/docker und /mnt/cache/docker werden mir nämlich die selben Dateien zur selben Zeit angezeigt. Nur eine Frage Sorry wenn es irgendwo offensichtlich steht 😅 Für /var/lib/docker wird das ja in /tmp geschrieben. Aber für /mnt/cache/docker ja nicht? Keine Ahnung, sorry...

-
Hatte es oben gerade Editiert. root@Tower:~# find /mnt/cache/ -type f -not -path "*/diff*" -print0 | xargs -0 stat --format '%Y:%.19y %n' | sort -nr | cut -d: -f2- 2> /dev/null | head -n30 | sed -e 's|/merged|/...|; s|^[0-9-]* ||' 12:39:08 /mnt/cache/docker/docker/containers/dffe492d2e5893875caa5164af76d6a33c7b67a6982b3f4b8e1defeda7d3415f/hostconfig.json 12:39:08 /mnt/cache/docker/docker/containers/dffe492d2e5893875caa5164af76d6a33c7b67a6982b3f4b8e1defeda7d3415f/dffe492d2e5893875caa5164af76d6a33c7b67a6982b3f4b8e1defeda7d3415f-json.log 12:39:08 /mnt/cache/docker/docker/containers/dffe492d2e5893875caa5164af76d6a33c7b67a6982b3f4b8e1defeda7d3415f/config.v2.json Ich schaue im GUI wenn ein WRITE zu sehen ist, dann den Befehl... Und das kommt dabei raus. In der Docker Ansicht ist auch "Einfache Ansicht" gewählt. Falls das noch ein Grund sein könnte. Keine Ahnung...
-
Servus, diesen hier: https://hub.docker.com/r/flowgunso/seafile-client/ Healthcheck Datei aus dem Container: Hilft das etwas? Ansonsten stell ich gern alles zur Verfügung, inklusive xml und einer seafile-test-repo LG /edit 08.09.2021 12:15 Ich habe nun einen eigenen Docker Cointainer erstellt auf Basis des oben genannten Images. Diesen habe ich so modifiziert, dass es mir möglich war, .ccnet/logs in UNRAIDs /tmp zu mounten. (So kann ich die Logs als Write absolut ausschließen) (Dies war ohne Modifikation nicht möglich, da durch mounten von .ccnet/logs seafile-cli dachte, dass schon Configs bestehen - und startete deshalb nicht. Dennoch habe ich nach wie vor periodisch alle 30 Sekunden einen Write auf meinem Cache. Output in UNRAID: find /var/lib/docker -type f -not -path "*/diff*" -print0 | xargs -0 stat --format '%Y:%.19y %n' | sort -nr | cut -d: -f2- 2> /dev/null | head -n30 | sed -e 's|/merged|/...|; s|^[0-9-]* ||' 12:15:33 /var/lib/docker/containers/dffe492d2e5893875caa5164af76d6a33c7b67a6982b3f4b8e1defeda7d3415f/hostconfig.json 12:15:33 /var/lib/docker/containers/dffe492d2e5893875caa5164af76d6a33c7b67a6982b3f4b8e1defeda7d3415f/dffe492d2e5893875caa5164af76d6a33c7b67a6982b3f4b8e1defeda7d3415f-json.log 12:15:33 /var/lib/docker/containers/dffe492d2e5893875caa5164af76d6a33c7b67a6982b3f4b8e1defeda7d3415f/config.v2.json csv="CONTAINER;PATHS\n"; for f in /var/lib/docker/image/*/layerdb/mounts/*/mount-id; do subid=$(cat $f); idlong=$(dirname $f | xargs basename); id="$(echo $idlong | cut -c 1-12)"; name=$(docker ps --format "{{.Names}}" -f "id=$id"); [[ -z $name ]] && continue; csv+="\n"$(printf '=%.0s' {1..20})";"$(printf '=%.0s' {1..100})"\n"; [[ -n $name ]] && csv+="$name;" csv+="/var/lib/docker/(btrfs|overlay2).../$subid\n"; csv+="$id;"; csv+="/var/lib/docker/containers/$idlong\n"; for vol in $(docker inspect -f '{{ range .Mounts }}{{ if eq .Type "volume" }}{{ .Destination }}{{ printf ";" }}{{ .Source }}{{ end }}{{ end }}' $id); do csv+="$vol\n"; done; done; echo ""; echo -e $csv | column -t -s';'; echo ""; ==================== ==================================================================================================== Z_Seafile_Desktop /var/lib/docker/(btrfs|overlay2).../b7798914f61c28221cdf268a18b447cb48b6dfbd416bbb2680603a9cc5fb9999 dffe492d2e58 /var/lib/docker/containers/dffe492d2e5893875caa5164af76d6a33c7b67a6982b3f4b8e1defeda7d3415f Und innerhalb des Cointainers: find / -type f -print0 | xargs -0 stat --format '%Y :%y %n' | sort -nr | cut -d: -f2- | head -100 ganz viel von: /proc/.... 2021-09-08 12:15:36.339192185 +0200 /proc/1203/cgroup 2021-09-08 12:15:36.339192185 +0200 /proc/1203/auxv 2021-09-08 12:15:36.339192185 +0200 /proc/1203/arch_status 2021-09-08 12:15:33.186228187 +0200 /home/seafuser/.ccnet/logs/seafile.log 2021-09-08 12:06:49.456146159 +0200 /proc/21/task/26/fdinfo/25 2021-09-08 12:06:49.456146159 +0200 /proc/21/fdinfo/25 2021-09-08 12:06:49.455146170 +0200 /proc/21/task/25/fdinfo/25 2021-09-08 12:06:49.455146170 +0200 /proc/21/task/24/fdinfo/25 und irgendwann dazwischen dann Die Uhrzeiten stimmen auf die Sekunde überein. In diesem Moment wird der Healthcheck ausgeführt, da dieser in den Log schreibt. In dem Moment geht auch der Write des Cache an. Da der Log auf /tmp gemountet ist, wird es nicht der .log sein, welcher hier geschrieben ist. Es müssen andere Dateien (die drei die eben oben angezeigt werden) sein. Ich habe aber alles so angepasst wie im Eingangs-Post beschrieben. Auch die RAM-Disk wird so angelegt wie hier angezeigt: (siehe Anhang) .... ach und reboot wurde durchgeführt... In find /mnt/cache/ wird ebenfalls keine andere Datei angezeigt die beschrieben wird. Ausschließlich hostconfig.json und die zwei -json.log von oben... Was kann ich noch tun? @mgutt Teamviewer und co gerne.




-
Herzlichen Dank @mgutt für die geniale Anpassung! Eine Verständnisfrage: Ich habe alles so gemacht wie beschrieben. Die Logfiles vom Container Seafile habe ich auf /tmp/seafile/log gemountet. Hab dahingehend auch keine Schreibzugriffe mehr. Darüber hinaus sehe ich nach reboot in rc.docker usw. die eingefügten Zeilen und dass ein tmpfs auf /var/lib/docker/containers liegt. Passt also alles. Nun zeigt mir der Befehl folgendes: (Ist soweit ja auch alles korrekt, du hast ja geschrieben, dass wir die ignorieren können, da wir das weggemountet haben. find /var/lib/docker -type f -not -path "*/diff*" -print0 | xargs -0 stat --format '%Y:%.19y %n' | sort -nr | cut -d: -f2- 2> /dev/null | head -n30 | sed -e 's|/merged|/...|; s|^[0-9-]* ||' 12:07:22 /var/lib/docker/containers/feef8c6c57761a42b20ce7b85bee71cd8a7134e7054a63c319eda02f09e1d419/hostconfig.json 12:07:22 /var/lib/docker/containers/feef8c6c57761a42b20ce7b85bee71cd8a7134e7054a63c319eda02f09e1d419/feef8c6c57761a42b20ce7b85bee71cd8a7134e7054a63c319eda02f09e1d419-json.log 12:07:22 /var/lib/docker/containers/feef8c6c57761a42b20ce7b85bee71cd8a7134e7054a63c319eda02f09e1d419/config.v2.json Allerdings sehe ich auch immer dann wenn das im Log auftritt, dass ich ein WRITE auf meinem Cache habe. Sodass ich nun nicht weiß, ob das passt, oder ob da wirklich 0kb stehen sollte.. Ich habe nur einen Container laufen. Nur diese Ausgabe und sonst wird nichts anderes geschrieben. Zumindest laut den Logs. /edit: mit --no-healthcheck wird hingegen tatsächlich absolut nichts geschrieben. LG und herzlichen Dank
-
Andere Frage ohne alles im Forum darüber durchgelesen zu haben: den Namen Root lässt sich nicht ändern? Also einen SuperUser / Admin einrichten mit anderen Namen, und den Root deaktivieren funktioniert nicht, oder? Liebe Grüße
-
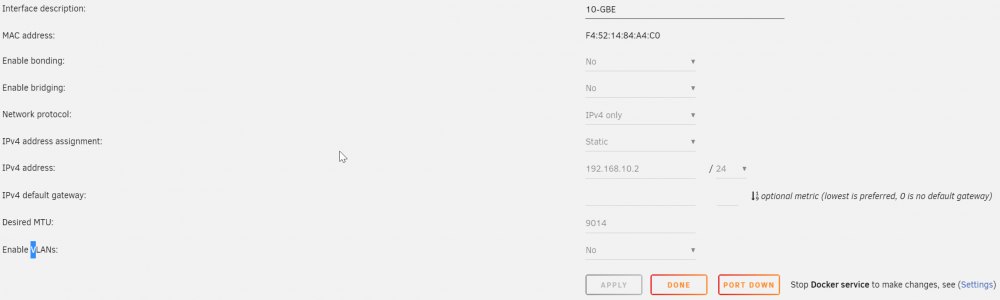
Hallo Zusammen. freut mich, dass hier wieder Wind reingekommen ist 😃 Ich persönlich habe das Skript leider nicht getestet, da das vorherige ohne Probleme funktioniert und ich nicht nochmal ein Fass aufmachen wollte. Ansonsten kannst du wie @mgutt sagt ein Skript einfach in Userskripts erstellen, welches du dann beim Start ausführst. Dabei ist es aber egal ob du es in das "Feld hineinskriptest" oder in eine extra Datei. Meins sieht nun so aus: Sleep-Skript: (weiß gar nicht ob das nötig ist / irgendetwas am Stromverbrauch bewirkt) /sbin/ifconfig eth2 down Wakeup-Skript: Da die Festplatten sowieso Anlaufen, nur irgendwie der Status nicht adäquat aktualisiert wird, führe ich erst ein Spinup aus. Ändert nichts an den Platten, nur am Status, sodass ich dann kurz darauf ein Spindown ausführen kann (ohne Spinup würde das nicht gehen...) um Strom zu sparen. Durch Zuweisung der Adresse zu eth2 passt alles. /usr/local/sbin/emcmd cmdSpinupAll=apply sleep 2 /usr/local/sbin/emcmd cmdSpindownAll=apply ip -4 addr add 192.168.10.2/255.255.255.0 dev eth2 ip link set mtu 9014 dev eth2 Per Userskripts und dem Cronjob prüfe ich alle 2 Minuten, ob mein PC mit verbautem 10GBE online ist. Wenn ja, dann: /sbin/ifconfig $eth_device up Ansonsten Spare ich damit ca. 0.5-1 Watt. Zusätzlich lasse ich Unraid nur herunterfahren wenn bestimmte PCs für mindestens 15 Minuten offline sind. Wenn Unraid heruntergefahren ist, prüft ein Bash-Skript auf dem RaspberryPi jede Minuten ob die bestimmten PCs online sind. Sind sie es für mindestens 3 Minuten, dann fährt Unraid wieder hoch. Nützlich dann, wenn ich Abends via Plex etwas schauen will. Schalte ich meinen TV an (und der bleibt es auch), dann startet Unraid und damit auch die Docker Container. Die 3 Minuten habe ich extra gewählt, da Nachts gelegentlich der TV anpingbar ist. Dies hat den Hintergrund, dass TVs gerne Nachts Updates der Sendeliste usw. machen und somit kurzzeitig "an" sind. Falls Interesse besteht, poste ich natürlich gerne das Skript. So ist der Server wirklich nur dann Online, wenn er es muss. Kritik an der Vorgehensweise? Habe ich was nicht beachtet? Nachteile? Liebe Grüße
-
Nein. Tatsächlich nicht. Also im Unraid-Terminal ist 100% packet loss netstat -rnp zeigt: Kernel IP routing table Destination Gateway Genmask Flags MSS Window irtt Iface 0.0.0.0 192.168.178.1 0.0.0.0 UG 0 0 0 br0 172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0 192.168.178.0 0.0.0.0 255.255.255.0 U 0 0 0 br0 also nichts von der 192.168.10.X ein "/sbin/ifconfig eth2 down" wird vor dem Sleep bereits ausgeführt. Aber auch ohne diesen Befehl vor dem Sleep funktioniert es leider nicht. Ich such mal einen Befehl, welcher die Internet-Settings einmal neu läd. /edit: Ein "ip -4 addr add 192.168.10.2/255.255.255.0 dev eth2" lässt mich wieder richtig zugreifen. Hoffe damit nicht irgendwas zu zerstören. Deshalb schaue ich eher nach einem internet Reload
-
Anderes Problem, welches bislang verdeckt geblieben ist... Unraid-Server ist aus --> Wird gebootet. 10GBE Karte / Port ist Up und erreichbar an meinem Netzwerk. Ping wird ausgeführt für 192.168.10.2 mit 32 Bytes Daten: Antwort von 192.168.10.2: Bytes=32 Zeit<1ms TTL=64 Antwort von 192.168.10.2: Bytes=32 Zeit<1ms TTL=64 Antwort von 192.168.10.2: Bytes=32 Zeit<1ms TTL=64 Antwort von 192.168.10.2: Bytes=32 Zeit<1ms TTL=64 Ping-Statistik für 192.168.10.2: Pakete: Gesendet = 4, Empfangen = 4, Verloren = 0 (0% Verlust), ---> Unraid server geht in den Ruhezustand mit dem Sleep-Plugin. ---> Nach einem WoL Signal, startet der Server... ---> Durch "/sbin/ifconfig eth2 up" oder alternativ "ip link set dev eth2 up" wird die Karte in Unraid als "Aktiv" angezeigt. Dennoch kann die Verdingung nicht richtig aufgebaut werden. Ping wird ausgeführt für 192.168.10.2 mit 32 Bytes Daten: Antwort von 192.168.10.3: Zielhost nicht erreichbar. Zeitüberschreitung der Anforderung. Zeitüberschreitung der Anforderung. Zeitüberschreitung der Anforderung. kennt jemand das Problem bereits? /edit: bei /usr/sbin/smartctl -n standby -A /dev/sdb usw. bekomme ich Device is in STANDBY mode. Angezeigt mehr nicht. @mgutt
-
Wobei ja gesagt wurde, dass der Befehl aus dem anderen Thread: sdspin <device> up ja nur die Disk startet. Also nichts am GUI Updatet.Hingegen dieser Befehl den wir verwenden: "/usr/local/sbin/emcmd cmdSpinupAll=apply" ja schon. Nur beim starten aus dem Ruhezustand..... Da ist das GUI nicht aktualisiert. Erst dieser Befehl aktualisiert das GUI. Sau doof. Alternativ wäre ein sdspin <device> down um den tatsächlichen Disk-Status an das WebGUI anzupassen. Entweder ... oder ... | Wie man es macht ... ist egal @mgutt zu den SMART Log Auszügen... Das erscheint nicht nur so mal eben im Log, sondern weckt meine HDDs tatsächlich auf. SpinUp. Verhindert dadurch den Sleep und verbraucht wieder mehr Strom... Ich weiß aber nicht was UnRAID damit will...
-
Also ich kann das wie gesagt nur bestätigen. Ein weiteres Verhalten welches ich gerne verifizieren würde: Über das Sleep-Plugin wird der Unraid-Server in den Ruhezustand versetzt. Via Wake-on-Lan wird dieser dann geweckt. Soweit so gut. Nun beobachte ich folgendes Verhalten: Die HDDS starten. Das wäre passend zum Logfile, Geräusch das auftritt und den Stromverbrauch. Apr 8 09:10:21 Tower kernel: sd 2:0:0:0: [sdc] Starting disk Apr 8 09:10:21 Tower kernel: sd 3:0:0:0: [sdd] Starting disk Apr 8 09:10:21 Tower kernel: sd 1:0:0:0: [sdb] Starting disk PASST. ABER: Die HDDs bleiben laut Webinterface auf "grau". Auch ein klick auf "Spindown" im Webinterface oder "/usr/local/sbin/emcmd cmdSpindownAll=apply" führt nicht zum Erfolg. Erst nachdem ich mit SpinUP oder "/usr/local/sbin/emcmd cmdSpinupAll=apply" die Platten "aktiviere" (obwohl sie eigentlich schon laufen - man hört dann auch kein "Anlaufgeräusch" - es ändert sich einfach gar nichts, da die Platten, wie eben erwähnt, bereits laufen), gelingt ein manueller Spindown. Deshalb sieht derzeit mein Sleep-StartSkript so aus: /usr/local/sbin/emcmd cmdSpinupAll=apply sleep 2 /usr/local/sbin/emcmd cmdSpindownAll=apply Aber... klüger wäre es, den SpinUp (von Unraid oder von Seiten des Servers /BIOS) gar nicht erst starten zu lassen, falls nicht nötig. Ungeachtet dessen: Was mich weiterhin richtig abnervt ist, dass auch wenn das Array an ist, immer und immer wieder diese doofen Smart-Werte ausgelesen werden wollen. Das geht die ganze Zeit so... Apr 8 09:15:06 Tower emhttpd: read SMART /dev/sdc Apr 8 09:15:22 Tower emhttpd: read SMART /dev/sdb Apr 8 09:17:28 Tower emhttpd: spinning down /dev/sdb Apr 8 09:17:28 Tower emhttpd: spinning down /dev/sdc Apr 8 09:17:36 Tower emhttpd: read SMART /dev/sdc Apr 8 09:17:45 Tower emhttpd: read SMART /dev/sdb Apr 8 09:19:38 Tower emhttpd: spinning down /dev/sdb Apr 8 09:19:38 Tower emhttpd: spinning down /dev/sdc Apr 8 09:20:05 Tower emhttpd: Spinning up all drives... Apr 8 09:20:05 Tower emhttpd: spinning up /dev/sdd Apr 8 09:20:05 Tower emhttpd: spinning up /dev/sdb Apr 8 09:20:05 Tower emhttpd: spinning up /dev/sdc Apr 8 09:20:18 Tower emhttpd: read SMART /dev/sdd Apr 8 09:20:18 Tower emhttpd: read SMART /dev/sdb Apr 8 09:20:18 Tower emhttpd: read SMART /dev/sdc Apr 8 09:20:18 Tower emhttpd: read SMART /dev/nvme1n1 Apr 8 09:20:18 Tower emhttpd: read SMART /dev/nvme0n1 Apr 8 09:20:18 Tower emhttpd: read SMART /dev/sda Apr 8 09:20:20 Tower emhttpd: spinning down /dev/sdd Apr 8 09:20:20 Tower emhttpd: spinning down /dev/sdb Apr 8 09:20:20 Tower emhttpd: spinning down /dev/sdc
-
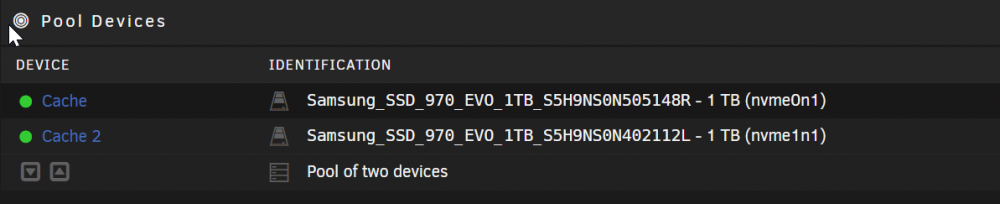
Also unter /mnt/cache wird die cache angezeigt. Die einzelnen Platten heißen Cache und Cache 2 Aber egal ob ich Cache groß oder klein schreibe. Es passiert leider nichts. Oder finde ich den richtigen Namen woanders? Seriennummern sind registriert, damit sollte nix passieren. /edit: Guten Morgen, auch ein /usr/local/sbin/emcmd cmdSpindown=nvme0n1 usw. bringt keinen Erfolg. Auch Über diese beiden Pfeile (unter Cache 2), welche für SpinDown Cache da sein sollen, passiert ausser ein kurz drehender Kreis bei den Statuslampen nichts. Danach bleiben die Punkte grün.
-
Das war auch zwischenzeitlich so. Mit dem Tipp "/sbin/ifconfig eth2 up" habe ich die Mellanox Karte wieder aktiviert bekommen und ist somit wieder bereit. Die GPU Funktioniert seit dem neuen Sleep Plugin ebenfalls wieder. Das war auch kein Vorwurf oder so. Nicht falsch verstehen! Bin sehr dankbar für jede Hilfe! Ansonsten ändert zumindest im laufenden Betrieb ein "modprobe mlx4_en oder mlx4_core" nichts an Stromverbrauch. Weder beim löschen noch beim entfernen. Also bei mir hat es auch mit Copy & Paste direkt funktioniert. Die Platten gehen in den Spindown. Die Cache SSDs allerdings nicht. Mir fällt allerdings auf, dass wenn ich das Array stoppe und den Spindown Befehl ausführe, spätestens nach einer Minute die Platten wieder anlaufen. Ist das ein normales Verhalten? Allerdings nur wenn das Array gestoppt ist. Ein Spindown über das WebGUI bei gestartetem Array, führt nicht zu diesem Verhalten. Apr 7 19:36:57 Tower flash_backup: adding task: php /usr/local/emhttp/plugins/dynamix.unraid.net/include/UpdateFlashBackup.php update Apr 7 19:37:01 Tower emhttpd: read SMART /dev/sdc Apr 7 19:37:16 Tower emhttpd: read SMART /dev/sdb Apr 7 19:37:25 Tower emhttpd: read SMART /dev/sdd Apr 7 19:38:12 Tower emhttpd: spinning down /dev/sdd Apr 7 19:38:12 Tower emhttpd: spinning down /dev/sdb Apr 7 19:38:12 Tower emhttpd: spinning down /dev/sdc Apr 7 19:39:01 Tower emhttpd: read SMART /dev/sdc Apr 7 19:39:16 Tower emhttpd: read SMART /dev/sdb Apr 7 19:39:26 Tower emhttpd: read SMART /dev/sdd Apr 7 19:40:58 Tower flash_backup: adding task: php /usr/local/emhttp/plugins/dynamix.unraid.net/include/UpdateFlashBackup.php update Apr 7 19:41:14 Tower emhttpd: spinning down /dev/sdd Apr 7 19:41:14 Tower emhttpd: spinning down /dev/sdb Apr 7 19:41:14 Tower emhttpd: spinning down /dev/sdc Apr 7 19:42:01 Tower emhttpd: read SMART /dev/sdc Apr 7 19:42:15 Tower emhttpd: read SMART /dev/sdb Apr 7 19:42:25 Tower emhttpd: read SMART /dev/sdd Apr 7 19:42:58 Tower flash_backup: adding task: php /usr/local/emhttp/plugins/dynamix.unraid.net/include/UpdateFlashBackup.php update Apr 7 19:44:39 Tower emhttpd: spinning down /dev/sdd Apr 7 19:44:39 Tower emhttpd: spinning down /dev/sdb Apr 7 19:44:39 Tower emhttpd: spinning down /dev/sdc Apr 7 19:45:01 Tower emhttpd: read SMART /dev/sdc Apr 7 19:45:16 Tower emhttpd: read SMART /dev/sdb Apr 7 19:45:27 Tower emhttpd: spinning down /dev/sdd Ansonsten habe ich das Script mal angepasst an meine IP usw. Und führe es alle 2 Minuten aus. Bin gespannt und gebe später bescheid. /Edit: Das Script funktioniert, nachdem ich in "ip link show $eth_device | grep down;" das DOWN; bzw. das UP groß geschrieben habe. Es scheint Case-Sensitiv zu sein.
-
Das teste ich! Danke! Daraus entnehme ich aber, dass es keine Möglichkeit der kompletten Abschaltung gibt. Das war echt ein produktiver Tag heute! Ich werde mich erkenntlich zeigen soweit es geht









