



Ahmad
Members
-
Joined
-
Last visited
Everything posted by Ahmad
-
I have two nvidia gpus, and I don't want them to be associated with unraid GUI at all, I know vfio binding is useful for VMs, and it's not needed for docker (with the use of the nvidia plugin and --runtime flag on containers) is there any advantage/disadvantage to vfio binding the gpus when I only plan on using them with docker? and will doing so break the docker --runtime functionality?
-
sorry folks, my unraid server is out of commission this week (hoping it's not a bricked CPU / MB .... Threadripper Pro ... $$$) I'll be able to debug again next week if it all works out well. my setup is Unraid 7.0.0 with Nvidia 3090 (though those errors you're reporting are unlikely related to hardware) the Bolt project on GitHub does not release a tagged version (currently it's set to "latest") https://github.com/stackblitz-labs/bolt.diy/pkgs/container/bolt.diy/versions?filters[version_type]=tagged I might just make a docker automated build from the tagged versions and republish that way
-
I think something is off with USB for sure, keyboard works in BIOS & on the blue boot screen then stops after the selection is made. having cycled through all the USB ports / controllers .... I'm not sure what to try next.
-
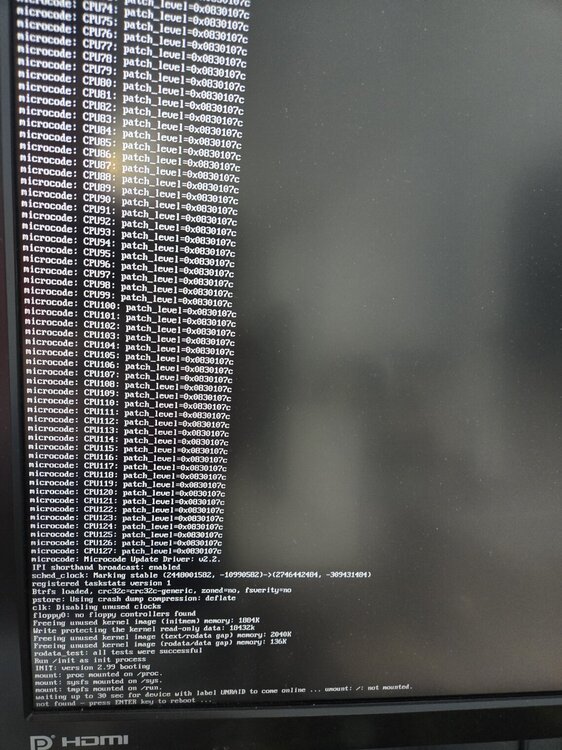
I've had my server with the same hardware working flawlesly for years, I recenly updated to 7.0 and it's been working great, through many reboots. I was in the middle of attempting to debug adding a second GPU, which unraid was not detecting for some reason ... where I am now completely stuck and cannot get unraid to boot at all. I get stuck at the "waiting up to 30 sec for device with label UNRAID to come online", I don't know how I got here, but I did reset the bios, update the bios, and juggle between UEFI and Legacy boot ... all to no avail. other things I tried from strands of mentions by others with similar problem: - unplugging everything, just keeping CPU, RAM, and unraid USB - using iGPU standalone - using iGPU while GPU is plugged in - using GPU while disabling iGPU (with physical switch) - xhci hand off disabled/enabled - fresh install of unraid on a fresh USB (both 7.0.0 and 6.12.15) - install unraid using the installer / manually - Legacy USB support enabled / disabled - changing the USB ports (3.0 & 2.0) - read every post on this forum and reddit related to this "waiting 30 sec" message IMPORTANT: one thing I noticed (which only started happening after many different messing with BIOS settings) is the keyboard gets DISABLED after the blue boot screen, and when I get to the "30 sec" message, where it prompts to hit Enter to reboot, the keyboard stopped working, where it WAS WORKING before at this step ... I think this is related to the issue of not detecting the device / mounting the partition... the whole thing doesn't make sense, things that were working, but now don't, even with a full reset of BIOS to default options, I can't even get back to a state where the keyboard was working! please help! Mother Board: Pro WS WRX80E-SAGE SE WIFI CPU: AMD Ryzen Threadripper PRO 3995WX USB: SanDisk 16GB Cruzer Fit
-
@nicksphone are you accessing the web interface through https:// URL? and are you using a local or remote (ollama) AI server (e.g. open router)m
-
the image has been fixed in v2.0.0 @fahmula FYI, you might want to review the new method of setting this up with the vscode cli (much lighter / simpler than apt-get install)
-
are you willing to release the source code? as it is right now the container runs a binary executable ... this is concerning for security / privacy, as well as you'd get more contributions if it's open source.
-
just published a new version 1.4.0 that supports TZ env, also upgrade to ubuntu:23.04 cheers.
-
have you tried the TZ environment variable? it might need adding the tzdata package to the image to work, I haven't tried it. give it a try and open a pull request if it works?
-
indeed I have (and used it for a bit), though that one is NOT the official VS-Code and hence it doesn't have the full extensions functionality as you indicated, hence why I made this one. I don't plan on adding functionality beyond what the official image provides, so things like password protection can be achieved with a reverse proxy like Authelia and SWAG: https://www.linuxserver.io/blog/2020-08-26-setting-up-authelia
-
The passkey is used in the `gnome-keyring-daemon` to remember your vscode login credentials for the settings sync feature between container runs. see code here: https://github.com/ahmadnassri/docker-vscode-server/blob/889626ddb47c0c9f23cb30b6cf4f94cd555568c2/src/start-vscode#L9 see info on settings sync here: https://code.visualstudio.com/docs/editor/settings-sync
-
are you referring to vscode? you should be able to login with your Github / Microsoft accounts.
-
is there a way to make the address fixed for the br0 network? I keep getting a bunch of random mac addresses in my Unifi UDMP and I'd rather label them accurately.
-
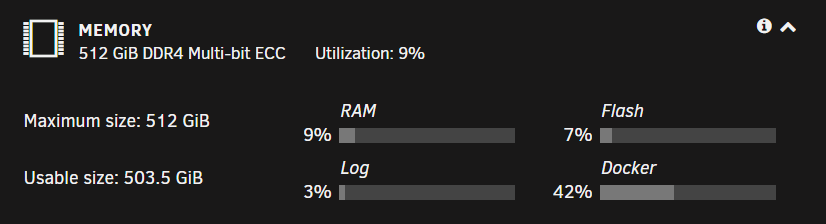
I keep running into this issue as well every few weeks ... despite having 512 GB in RAM and adjusting the "vm.dirty_background_ratio" & "vm.dirty_ratio" to 1 & 2 respectively ... to answer the question commonly asked by @Squid in this thread ... yes I do have a browser window always open on my server (windows + chrome), and I am running 6.10.3 (so the auto reload thing doesn't seem to be helping) every time this happens, I look the next morning, and things are operating normally ... it's just the Fix Common Problems notification that keeps coming up. (I also can't acknowledge or ignore this error, it keeps coming up) when running: $ grep -ir memory /var/log/syslog results are: Sep 23 21:33:46 Unraid kernel: out_of_memory+0x3e3/0x416 Sep 23 21:33:46 Unraid kernel: mem_cgroup_out_of_memory+0x7e/0xb3 Sep 23 21:33:46 Unraid kernel: memory: usage 1048576kB, limit 1048576kB, failcnt 6490 Sep 23 21:33:46 Unraid kernel: memory+swap: usage 1048576kB, limit 2097152kB, failcnt 0 Sep 23 21:33:46 Unraid kernel: Memory cgroup stats for /docker/62109599b64d728923799a0ea81ff1ac204891d801cbc73c81ec51d17f62072d: Sep 23 21:33:46 Unraid kernel: Tasks state (memory values in pages): Sep 23 21:33:46 Unraid kernel: Memory cgroup out of memory: Killed process 84342 (node) total-vm:856328kB, anon-rss:39280kB, file-rss:38888kB, shmem-rss:0kB, UID:0 pgtables:1544kB oom_score_adj:0 Sep 23 23:33:52 Unraid kernel: out_of_memory+0x3e3/0x416 Sep 23 23:33:52 Unraid kernel: mem_cgroup_out_of_memory+0x7e/0xb3 Sep 23 23:33:52 Unraid kernel: memory: usage 1048576kB, limit 1048576kB, failcnt 50011 Sep 23 23:33:52 Unraid kernel: memory+swap: usage 1048576kB, limit 2097152kB, failcnt 0 Sep 23 23:33:52 Unraid kernel: Memory cgroup stats for /docker/62109599b64d728923799a0ea81ff1ac204891d801cbc73c81ec51d17f62072d: Sep 23 23:33:52 Unraid kernel: Tasks state (memory values in pages): Sep 23 23:33:52 Unraid kernel: Memory cgroup out of memory: Killed process 86340 (node) total-vm:854380kB, anon-rss:37628kB, file-rss:38736kB, shmem-rss:0kB, UID:0 pgtables:1528kB oom_score_adj:0 Sep 23 23:33:57 Unraid kernel: out_of_memory+0x3e3/0x416 Sep 23 23:33:57 Unraid kernel: mem_cgroup_out_of_memory+0x7e/0xb3 Sep 23 23:33:57 Unraid kernel: memory: usage 1048576kB, limit 1048576kB, failcnt 62273 Sep 23 23:33:57 Unraid kernel: memory+swap: usage 1048576kB, limit 2097152kB, failcnt 0 Sep 23 23:33:57 Unraid kernel: Memory cgroup stats for /docker/62109599b64d728923799a0ea81ff1ac204891d801cbc73c81ec51d17f62072d: Sep 23 23:33:57 Unraid kernel: Tasks state (memory values in pages): Sep 23 23:33:57 Unraid kernel: Memory cgroup out of memory: Killed process 69574 (node) total-vm:856328kB, anon-rss:47884kB, file-rss:37908kB, shmem-rss:0kB, UID:0 pgtables:1544kB oom_score_adj:0 Sep 23 23:33:57 Unraid kernel: out_of_memory+0x3e3/0x416 Sep 23 23:33:57 Unraid kernel: mem_cgroup_out_of_memory+0x7e/0xb3 Sep 23 23:33:57 Unraid kernel: memory: usage 1048576kB, limit 1048576kB, failcnt 76377 Sep 23 23:33:57 Unraid kernel: memory+swap: usage 1048576kB, limit 2097152kB, failcnt 0 Sep 23 23:33:57 Unraid kernel: Memory cgroup stats for /docker/62109599b64d728923799a0ea81ff1ac204891d801cbc73c81ec51d17f62072d: Sep 23 23:33:57 Unraid kernel: Tasks state (memory values in pages): Sep 23 23:33:57 Unraid kernel: Memory cgroup out of memory: Killed process 84328 (nginx) total-vm:123248kB, anon-rss:23508kB, file-rss:7620kB, shmem-rss:540kB, UID:0 pgtables:128kB oom_score_adj:0 Sep 23 23:33:57 Unraid kernel: out_of_memory+0x3e3/0x416 Sep 23 23:33:57 Unraid kernel: mem_cgroup_out_of_memory+0x7e/0xb3 Sep 23 23:33:57 Unraid kernel: memory: usage 1048576kB, limit 1048576kB, failcnt 79372 Sep 23 23:33:57 Unraid kernel: memory+swap: usage 1048576kB, limit 2097152kB, failcnt 0 Sep 23 23:33:57 Unraid kernel: Memory cgroup stats for /docker/62109599b64d728923799a0ea81ff1ac204891d801cbc73c81ec51d17f62072d: Sep 23 23:33:57 Unraid kernel: Tasks state (memory values in pages): Sep 23 23:33:57 Unraid kernel: Memory cgroup out of memory: Killed process 3671 (nginx) total-vm:123248kB, anon-rss:23528kB, file-rss:5612kB, shmem-rss:104kB, UID:0 pgtables:112kB oom_score_adj:0 Sep 23 23:33:57 Unraid kernel: out_of_memory+0x3e3/0x416 Sep 23 23:33:57 Unraid kernel: mem_cgroup_out_of_memory+0x7e/0xb3 Sep 23 23:33:57 Unraid kernel: memory: usage 1048576kB, limit 1048576kB, failcnt 90718 Sep 23 23:33:57 Unraid kernel: memory+swap: usage 1048576kB, limit 2097152kB, failcnt 0 Sep 23 23:33:57 Unraid kernel: Memory cgroup stats for /docker/62109599b64d728923799a0ea81ff1ac204891d801cbc73c81ec51d17f62072d: Sep 23 23:33:57 Unraid kernel: Tasks state (memory values in pages): Sep 23 23:33:57 Unraid kernel: Memory cgroup out of memory: Killed process 84786 (nginx) total-vm:123120kB, anon-rss:23336kB, file-rss:5632kB, shmem-rss:100kB, UID:0 pgtables:116kB oom_score_adj:0 Sep 23 23:33:57 Unraid kernel: out_of_memory+0x3e3/0x416 Sep 23 23:33:57 Unraid kernel: mem_cgroup_out_of_memory+0x7e/0xb3 Sep 23 23:33:57 Unraid kernel: memory: usage 1048576kB, limit 1048576kB, failcnt 92210 Sep 23 23:33:57 Unraid kernel: memory+swap: usage 1046712kB, limit 2097152kB, failcnt 0 Sep 23 23:33:57 Unraid kernel: Memory cgroup stats for /docker/62109599b64d728923799a0ea81ff1ac204891d801cbc73c81ec51d17f62072d: Sep 23 23:33:57 Unraid kernel: Tasks state (memory values in pages): Sep 23 23:33:57 Unraid kernel: Memory cgroup out of memory: Killed process 69405 (nginx) total-vm:121712kB, anon-rss:22100kB, file-rss:5376kB, shmem-rss:0kB, UID:0 pgtables:112kB oom_score_adj:0 Sep 25 00:30:35 Unraid root: Fix Common Problems: Error: Out Of Memory errors detected on your server unraid-diagnostics-20220925-1130.zip

-
Microsoft crew just tagged the issue preventing "remote" mode being usable as a backlog candidate, they are looking for at least 10 votes to move it to the backlog: https://github.com/microsoft/vscode-remote-release/issues/7018#issuecomment-1211196838
-
"local": runs completely independently, locally on your unraid "remote": allows the container to act as a remote target for vscode.dev, however, this is behind a beta invite for now, and as per previous post, is not functional due to an issue with vscode-server itself, and awaiting Microsoft to address my ticket. for now stick to "local" until I announce it fully functional.
-
oops, apologies for this, corrected the issue in the template: https://github.com/ahmadnassri/unraid-templates/commit/78c883529bb063681ca527e6792f9307c54c8d37 the next refresh of CA Community Applications will surface this fix, in the meantime: as @resuarezsaid, adding a variable named VSCODR_SERVER_MODE with value set to "local" will allow it to run properly. note: this is in prep to allow the container to run as a remote target for vscode.dev (vs. local), however this is currently nonfunctional due to an issue: https://github.com/microsoft/vscode-remote-release/issues/7018
-
I'm creating and maintaining a bunch of templates mainly around web development tools. Verdaccio: A lightweight Node.js private proxy registry https://verdaccio.org/ Visual Studio Code Server: Run full VS Code on your own hardware! https://code.visualstudio.com/docs/remote/vscode-server UniFi API Browser: pull raw, JSON formatted data from the API running on your UniFi Controller. https://github.com/Art-of-WiFi/UniFi-API-browser GitHub Templates Repository: https://github.com/ahmadnassri/unraid-templates/
-
more specifically it looks like the issue is from this line in /etc/rc.d/rc.nginx: IP4=$(grep 'IPADDR:0' /var/local/emhttp/network.ini | cut -d'"' -f2) it returns the two IP addresses... could be solved with: IP4=$(grep -m 1 'IPADDR:0' /var/local/emhttp/network.ini | cut -d'"' -f2)
-
I have run into an issue where the nginx configuration is malformed ... maybe due to having dual IPs? from /etc/nginx/conf.d/servers.conf: # # Redirect http requests to https # ex: http://tower.local -> https://hash.unraid.net # server { listen 80 default_server; listen [::]:80 default_server; return 302 https://10-0-1-100 10-0-1-101.[ID].myunraid.net$request_uri; } ... # # Port settings for https using CA-signed cert # ex: https://lan-ip.hash.myunraid.net # ex: https://wan-ip.hash.myunraid.net # ex: https://hash.unraid.net # ex: https://www.hash.unraid.net # server { listen 443 ssl http2; listen [::]:443 ssl http2; server_name 10-0-1-100 10-0-1-101.[ID].myunraid.net [external-IP].[ID].myunraid.net; # Ok to use concatenated pem files; nginx will do the right thing. ssl_certificate /boot/config/ssl/certs/certificate_bundle.pem; ssl_certificate_key /boot/config/ssl/certs/certificate_bundle.pem; ssl_trusted_certificate /boot/config/ssl/certs/certificate_bundle.pem; # # Enable OCSP stapling # ssl_stapling on; ssl_stapling_verify on; # location ~ /wsproxy/443/ { return 403; } include /etc/nginx/conf.d/locations.conf; } note how there are line breaks on the server name and the return directives ... my server has two NICs with IPs: 10.0.1.100 and 10.0.1.101 (10Gbe & 1Gbe) it seems this is tripping up the generated nginx configuration ... editing the nginx file manually doesnt' seem to work, as when I try to start nginx after, it overwrites it.
-
thx @limawaken the only docker containers currently running are AdGuard and Home Assistant... I could look closer at those, but I doubt they are the cause... where do I look in the diagnostic report? I'm trying search for "memory" but the only relevant result I could find is the avahi one I posted about ...
-
I have noticed this block in the diagnostic data, which lines up with problems I've had with "avahi-daemon" ... some days I find a CPU core stuck at 100% and it's avahi-daemon stuck, so I have to manually kill it in the console ... Mar 16 16:23:35 NAS kernel: avahi-daemon invoked oom-killer: gfp_mask=0x1100dca(GFP_HIGHUSER_MOVABLE|__GFP_ZERO), order=0, oom_score_adj=0 Mar 16 16:23:35 NAS kernel: CPU: 115 PID: 7255 Comm: avahi-daemon Not tainted 5.14.15-Unraid #1 Mar 16 16:23:35 NAS kernel: Hardware name: Default string Default string/Default string, BIOS WRX80SU8-F3 12/12/2012 Mar 16 16:23:35 NAS kernel: Call Trace: Mar 16 16:23:35 NAS kernel: dump_stack_lvl+0x46/0x5a Mar 16 16:23:35 NAS kernel: dump_header+0x4a/0x1f3 Mar 16 16:23:35 NAS kernel: oom_kill_process+0x80/0xfb Mar 16 16:23:35 NAS kernel: out_of_memory+0x3e3/0x416 Mar 16 16:23:35 NAS kernel: __alloc_pages_slowpath.constprop.0+0x6f5/0x86f Mar 16 16:23:35 NAS kernel: __alloc_pages+0x10b/0x1ac Mar 16 16:23:35 NAS kernel: alloc_pages_vma+0x120/0x13c Mar 16 16:23:35 NAS kernel: __handle_mm_fault+0x7c9/0xc73 Mar 16 16:23:35 NAS kernel: ? __default_send_IPI_dest_field+0x21/0x49 Mar 16 16:23:35 NAS kernel: handle_mm_fault+0x11c/0x1e2 Mar 16 16:23:35 NAS kernel: do_user_addr_fault+0x342/0x50b Mar 16 16:23:35 NAS kernel: exc_page_fault+0xe2/0x101 Mar 16 16:23:35 NAS kernel: ? asm_exc_page_fault+0x8/0x30 Mar 16 16:23:35 NAS kernel: asm_exc_page_fault+0x1e/0x30 Mar 16 16:23:35 NAS kernel: RIP: 0033:0x154d2fc7196c Mar 16 16:23:35 NAS kernel: Code: 35 59 41 00 00 48 8d 3d 65 41 00 00 e8 fd d8 ff ff 66 66 2e 0f 1f 84 00 00 00 00 00 66 90 41 56 41 55 41 54 55 53 48 83 ec 70 <48> 89 7c 24 08 48 89 14 24 64 48 8b 0c 25 28 00 00 00 48 89 4c 24
-
I've been running my server on 6.10.0-rc2 for months now and everything is working just fine ... except for this OOM error that is persisting even after reboot, I only see it in Fix Common Problems plugin, and no where else ... I have 512 GB memory here, and I have not fully deployed VMs/Containers yet that would use anywhere near that much memory, so I'm confused to where this error is from ... attached is the diagnostic. nas-diagnostics-20220316-1949.zip
-
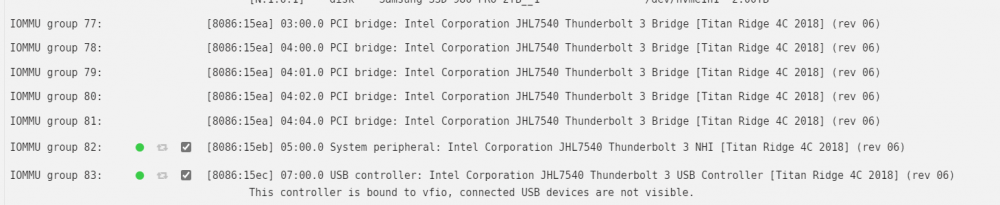
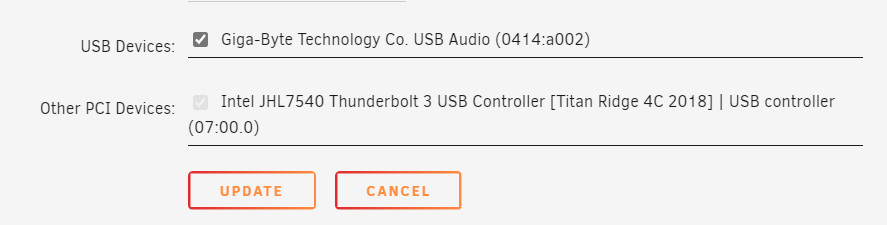
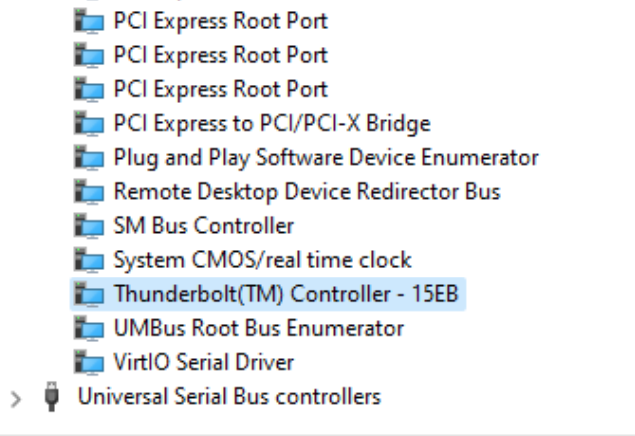
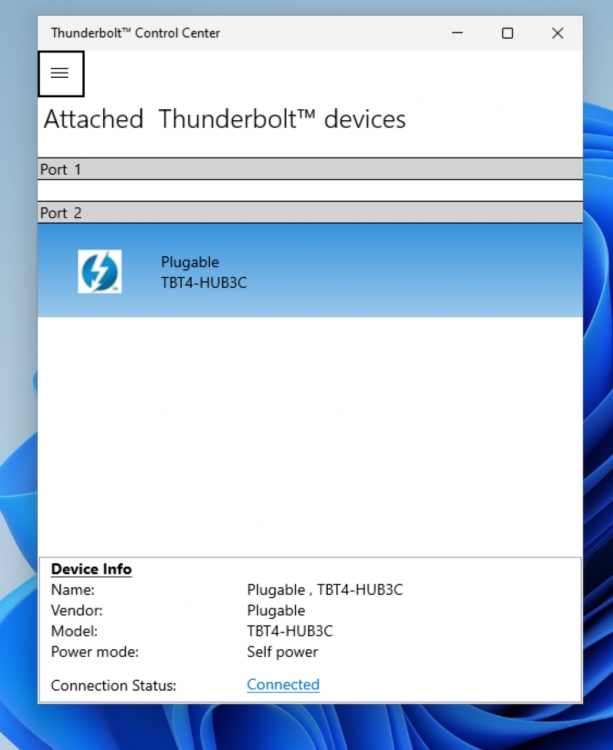
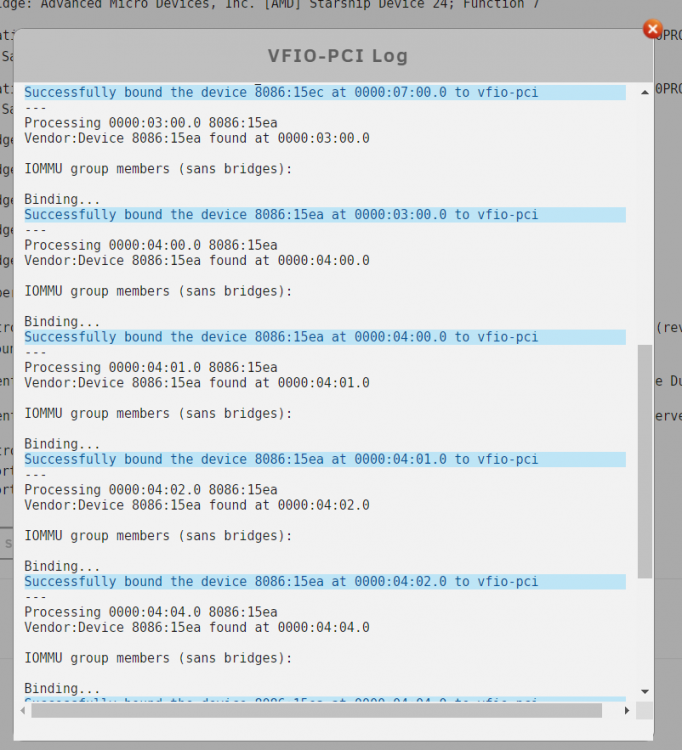
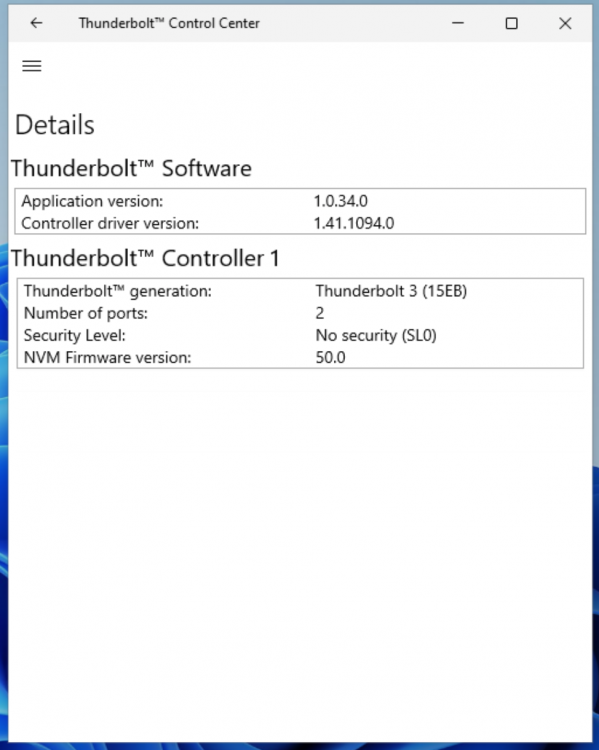
Device information: MB: GIGABYTE WRX80-SU8 CPU: AMD Ryzen Threadripper PRO 3995WX IOMMU: Enabled TB3 Card: GC-TITAN RIDGE (rev. 2.0) PCIe ACS override: Both I'm running a Windows 11 VM through Unraid Version: 6.10.0-rc2 (I had no success with stable version at all) after much trial and error, I managed to get the IOMMU groups for the Titan Ridge card to the following state: this was still not enough to to add the card to the Windows VM as only one of the two PCI devices was showing up: so I manually added the 05:00.0 NHI device through XML: <hostdev mode='subsystem' type='pci' managed='yes'> <source> <address domain='0x0000' bus='0x05' slot='0x00' function='0x0'/> </source> </hostdev> this allowed the device to properly show up and get discovered by Windows: and the Thunderbolt Software was automatically installed. I plugged in a Thunderbolt Hub into it and was successfully detected: Here's the issue: when I plug USB-C drives into the hub (or directly into the TB3 Card) it does not get detected by windows. even after a whole restart of the entire Host server (in case it was a hot plug issue) more importantly, I cannot get the DisplayPort Signal to work over Thunderbolt. tl;dr: Thunderbolt 3 AIC Passthrough successful, but nothing is detected. More Notes: What are the other PCI devices showing up that are associated with the Titan Ridge card? (named: "0X:0X.0 PCI bridge: Intel Corporation JHL7540 Thunderbolt 3 Bridge [Titan Ridge 4C 2018] (rev 06)") do those need to be passed through as well? how do I do that? I tried to add them to the XML with the same method, but the VM wont load with an error: Execution error internal error: Non-endpoint PCI devices cannot be assigned to guests I'm not an expert at the XML syntax, maybe it needs to be different? Why are those devices not addressable in the PICE Devices and IOMMU Groups UI? I tried to override that with manually setting the vfio-pci.cfg values to: BIND=0000:c1:00.0|10de:1b82 0000:c1:00.1|10de:10f0 0000:05:00.0|8086:15eb 0000:07:00.0|8086:15ec 0000:03:00.0|8086:15ea 0000:04:00.0|8086:15ea 0000:04:01.0|8086:15ea 0000:04:02.0|8086:15ea 0000:04:04.0|8086:15ea I can see Unraid trying to bind them during boot in the vfio-pci log, but seems unsuccessful at doing so: How can I pass the ENTIRE PCIe card / lane to the VM so that I don't have to individually pass those devices? Thanks for the help!
-
I had to look up the difference between qcow2 and RAW ... thanks for the suggestion. I might give that a try with a fresh Windows VM setup, but, based on my Ubuntu VM, which uses a RAW disk type, and works fine with the agent installed and running, I don't think this is the answer, besides, reading about qcow2 seems to indicate performance hit vs. RAW










