



NIronwolf
Members
-
Joined
-
Last visited
Everything posted by NIronwolf
-
512GB for ram
-
I'm looking at getting it to auto start too. My guess in your case is that the go script runs before the pools are ready. I'm going to try putting the daemonize command in a User Script that I'll set to Array Start.
-
That's an honor. Thank you. I'm glad you found it useful!
-
Thanks. The change should be fine either way. If anyone runs across issues I haven't been able to test, I'm happy to update.
-
Yes. This line should have made $POOL_STATUS set to "DEGRADED" and it should run the different case section. POOL_STATE=$(echo "$JSON" | jq -r --arg POOL "$POOL" '.pools[$POOL].state // "UNKNOWN"') running "DEGRADED") SUBJECT="$POOL Degraded" DESCRIPTION="Pool <b>$POOL</b> is DEGRADED" if [[ $TOTAL_READ_ERRORS -gt 0 || $TOTAL_WRITE_ERRORS -gt 0 || $TOTAL_CHECKSUM_ERRORS -gt 0 ]]; then DESCRIPTION+=" with errors: READ=$TOTAL_READ_ERRORS, WRITE=$TOTAL_WRITE_ERRORS, CHECKSUM=$TOTAL_CHECKSUM_ERRORS" fi DESCRIPTION+=" - May be rebuilding or need attention" ICON="warning" ;; If you run something like POOL_STATE=$(zpool status -j | jq -r --arg POOL "$POOL" '.pools[$POOL].state // "UNKNOWN"') echo $POOL_STATE It should print DEGRADED And then I asked AI about it. The issue is that your JSON contains unescaped control characters (specifically newlines \n and tabs \t in the strings). It suggested processing the zpool command output. Can you verify by changing the line that stores the JSON? -- JSON=$(zpool status -j) ++ JSON=$(zpool status -j | sed 's/\\/\\\\/g')
-
Interesting. If you run it in debug mode or do a zpool status -j does the node for pools[tank].state show as "DEGRADED"? I haven't had a degraded pool yet so it's not a case I've been able to test.
-
I thought I'd share a script I setup to do daily monitoring of my ZFS pools. I run it with the User Scripts plug-in on a Daily schedule. The script will examine the output of zpool status and generate a message to send as a notification to the web GUI. All the configuration is in a block at the head of the script. #!/bin/bash # ==================== PARAMETERS ==================== # Set AUTO_DISCOVER to "true" to automatically find all pools, # or "false" to use the manual list below AUTO_DISCOVER="true" # Manual pool list (only used if AUTO_DISCOVER="false") # Use space-separated quoted strings like: ("hdd_main" "nvme_cache") POOLS=("hdd_main" "nvme_cache") # Notification settings NOTIFY_SUCCESS="true" # Set to "false" to only notify on errors/warnings ERROR_THRESHOLD=0 # Notify if READ/WRITE/CHECKSUM errors > this value SLOW_IO_THRESHOLD=10 # Notify if slow I/O count > this value (if supported) # Debug mode - set to "true" to see detailed parsing output DEBUG="false" # ==================================================== # Function to get all vdev error counts recursively get_vdev_errors() { local json="$1" local pool="$2" local vdev_path="$3" local read_errors=$(echo "$json" | jq -r "$vdev_path.read_errors // \"0\"") local write_errors=$(echo "$json" | jq -r "$vdev_path.write_errors // \"0\"") local checksum_errors=$(echo "$json" | jq -r "$vdev_path.checksum_errors // \"0\"") # Sum up errors from child vdevs if they exist local child_vdevs=$(echo "$json" | jq -r "$vdev_path.vdevs // empty | keys[]?" 2>/dev/null) for child in $child_vdevs; do local child_path="$vdev_path.vdevs[\"$child\"]" local child_errors=$(get_vdev_errors "$json" "$pool" "$child_path") read_errors=$((read_errors + $(echo "$child_errors" | cut -d: -f1))) write_errors=$((write_errors + $(echo "$child_errors" | cut -d: -f2))) checksum_errors=$((checksum_errors + $(echo "$child_errors" | cut -d: -f3))) done echo "$read_errors:$write_errors:$checksum_errors" } # Build pool list if [[ "$AUTO_DISCOVER" == "true" ]]; then mapfile -t POOLS < <(zpool list -H -o name) echo "Auto-discovered pools: ${POOLS[*]}" else echo "Using manual pool list: ${POOLS[*]}" fi # Get JSON status for all pools # JSON=$(zpool status -j) # Worked fine on my PC... :D JSON=$(zpool status -j | sed 's/\\/\\\\/g') # Clean up control characters in zpool's erronous JSON output if [[ $DEBUG == "true" ]]; then echo "JSON Output:" echo "$JSON" | jq . fi # Check each pool for POOL in "${POOLS[@]}"; do echo "=========================================" echo "Checking pool: $POOL" # Parse JSON for pool information POOL_STATE=$(echo "$JSON" | jq -r --arg POOL "$POOL" '.pools[$POOL].state // "UNKNOWN"') if [[ "$POOL_STATE" == "null" || "$POOL_STATE" == "UNKNOWN" ]]; then echo "ERROR: Pool $POOL not found in status output" /usr/local/emhttp/webGui/scripts/notify -e "ZFS POOL STATUS" -s "Pool Not Found" -d "Pool $POOL not found - check pool name" -i alert continue fi # Get total error counts for the pool POOL_ERRORS=$(get_vdev_errors "$JSON" "$POOL" ".pools[\"$POOL\"].vdevs[\"$POOL\"]") TOTAL_READ_ERRORS=$(echo "$POOL_ERRORS" | cut -d: -f1) TOTAL_WRITE_ERRORS=$(echo "$POOL_ERRORS" | cut -d: -f2) TOTAL_CHECKSUM_ERRORS=$(echo "$POOL_ERRORS" | cut -d: -f3) # Check for scan information (scrub/resilver in progress) SCAN_STATE=$(echo "$JSON" | jq -r --arg POOL "$POOL" '.pools[$POOL].scan_stats.state // "none"') SCAN_FUNCTION=$(echo "$JSON" | jq -r --arg POOL "$POOL" '.pools[$POOL].scan_stats.function // "none"') # Determine notification level and message DESCRIPTION="" SUBJECT="" ICON="normal" if [[ $DEBUG == "true" ]]; then echo " State: $POOL_STATE" echo " Read Errors: $TOTAL_READ_ERRORS" echo " Write Errors: $TOTAL_WRITE_ERRORS" echo " Checksum Errors: $TOTAL_CHECKSUM_ERRORS" echo " Scan State: $SCAN_STATE" echo " Scan Function: $SCAN_FUNCTION" fi # Analyze pool health case "$POOL_STATE" in "ONLINE") if [[ $TOTAL_READ_ERRORS -gt $ERROR_THRESHOLD || $TOTAL_WRITE_ERRORS -gt $ERROR_THRESHOLD || $TOTAL_CHECKSUM_ERRORS -gt $ERROR_THRESHOLD ]]; then SUBJECT="$POOL Errors Detected" DESCRIPTION="Pool <b>$POOL</b> is ONLINE but has errors: READ=$TOTAL_READ_ERRORS, WRITE=$TOTAL_WRITE_ERRORS, CHECKSUM=$TOTAL_CHECKSUM_ERRORS" ICON="warning" else SUBJECT="$POOL Healthy" DESCRIPTION="Pool <b>$POOL</b> is ONLINE and healthy" ICON="normal" fi ;; "DEGRADED") SUBJECT="$POOL Degraded" DESCRIPTION="Pool <b>$POOL</b> is DEGRADED" if [[ $TOTAL_READ_ERRORS -gt 0 || $TOTAL_WRITE_ERRORS -gt 0 || $TOTAL_CHECKSUM_ERRORS -gt 0 ]]; then DESCRIPTION+=" with errors: READ=$TOTAL_READ_ERRORS, WRITE=$TOTAL_WRITE_ERRORS, CHECKSUM=$TOTAL_CHECKSUM_ERRORS" fi DESCRIPTION+=" - May be rebuilding or need attention" ICON="warning" ;; "FAULTED"|"UNAVAIL") SUBJECT="$POOL CRITICAL" DESCRIPTION="Pool <b>$POOL</b> is $POOL_STATE - IMMEDIATE ATTENTION REQUIRED" if [[ $TOTAL_READ_ERRORS -gt 0 || $TOTAL_WRITE_ERRORS -gt 0 || $TOTAL_CHECKSUM_ERRORS -gt 0 ]]; then DESCRIPTION+=" Errors: READ=$TOTAL_READ_ERRORS, WRITE=$TOTAL_WRITE_ERRORS, CHECKSUM=$TOTAL_CHECKSUM_ERRORS" fi ICON="alert" ;; "OFFLINE") SUBJECT="$POOL Offline" DESCRIPTION="Pool <b>$POOL</b> is OFFLINE" ICON="warning" ;; *) SUBJECT="$POOL Unknown State" DESCRIPTION="Pool <b>$POOL</b> has unknown state: $POOL_STATE" ICON="warning" ;; esac # Add scan information if relevant if [[ "$SCAN_STATE" == "SCANNING" ]]; then DESCRIPTION+=" ($SCAN_FUNCTION in progress)" elif [[ "$SCAN_STATE" == "FINISHED" && "$SCAN_FUNCTION" == "SCRUB" ]]; then SCAN_ERRORS=$(echo "$JSON" | jq -r --arg POOL "$POOL" '.pools[$POOL].scan_stats.errors // "0"') if [[ "$SCAN_ERRORS" != "0" ]]; then DESCRIPTION+=" (Last scrub found $SCAN_ERRORS errors)" if [[ "$ICON" == "normal" ]]; then ICON="warning" fi fi fi # Send notification based on settings if [[ "$ICON" != "normal" || "$NOTIFY_SUCCESS" == "true" ]]; then /usr/local/emhttp/webGui/scripts/notify -e "ZFS POOL STATUS" -s "$SUBJECT" -d "$DESCRIPTION" -i "$ICON" fi echo "$DESCRIPTION" # Display detailed vdev states if there are issues if [[ "$ICON" != "normal" ]]; then echo "Detailed vdev information:" zpool status "$POOL" fi echo "" done echo "=========================================" echo "Pool monitoring complete."
-
Went to update to the new plugin. Somethings not pointing to the right place it seems. Getting a Network failure. I'd guess the .plg files are hosted the same place the list comes from, but that's probably not the case if it's not downloading. plugin: installing: unbalanced.plg Executing hook script: pre_plugin_checks plugin: downloading: unbalanced.plg ... plugin: unbalanced.plg download failure: Network failure Executing hook script: gui_search_post_hook.sh Executing hook script: post_plugin_checks
-
Rebuild and scrub completed. All looks good. Thanks again for your guidance JorgeB!
-
Oh, here's a diagnostic grabbed while it's starting all that work. If all goes normally I can say it's rebuilt in like 36 hours. Probably don't need to look at this diag unless something more goes haywire. Thank you for your assistance JorgeB! reality-diagnostics-20230111-1150.zip
-
Oh, and the 4 drives that are setup btrfs aren't connected that way. I'd guess any corruption there would have been from the system locking up and having to hard power it off. Ok, this time all the disks mounted normally and show they're xfs. (With the disk that dropped being rebuilt.) Running that scrub on my scratch cache drives now. I guess it just needed me to tattle on it to do what it normally does when I have to reset a drive.
-
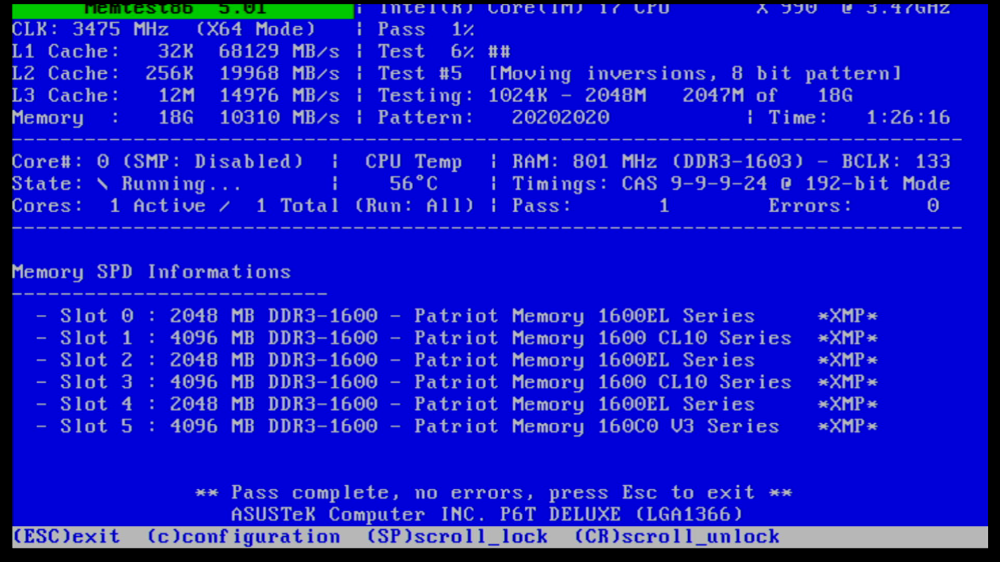
Memory checked fine (as I suspected it would). The errors are the flakey connection to my external drive enclosure over eSATA I believe.
-
I don't know how to make a backup of the LUKS headers. (I recognize the word though and that worries me greatly.) The btrfs is only for one of the cache pools. I use ext4 on all the array drives (encrypted).
-
First, I realize I have a flakey port replicator or something. It can sometimes drop a drive. I had a drive drop from the array. I took a diagnostic and then rebooted. Then took a second diagnostic. I toggled the drive to empty then back to the original drive. I've done this in the past and it just rebuilt and everything was fine. However, today ALL the disks say "Unmountable: Volume not encrypted". I'm worried it already killed everything as it auto started the rebuild, but I hit stop right away. No it's trying to Stop the array but not finishing. It's reporting the drive activity is 0, but the status at the bottoms says "Array Stopping • Retry unmounting disk share(s).." Have I just corrupted everything? reality-diagnostics-20230111-0735.zip reality-diagnostics-20230111-0841.zip
-
I held off a bit on updating in hopes that it would go more smoothly, but unfortunately that hasn't happened. After rebooting I could no longer access the WebGUI. At first I reconnected a monitor and saw that it wasn't even finishing booting. From where it stuck in the log it seemed that the disklocation plugin wasn't finishing. I was able to access through SSH and I moved the disklocation.plg and directory out of the the boot folders. Now the system will complete and get to the login prompt but the WebGUI is still not running. I attempted to run the diagnostics command but it doesn't complete either. I'm not sure what all it gathers up and I'm happy to manually pull more files. To get started I have the syslog. How can I either revert or manually retry the upgrade? Thank you for your help! syslog
-
I'm not positive at this point. It may have been marked disabled when started in maintenance. I've been having issues with my external port replicating enclosures so I may just be headed for a big crash. I'm finding some bulky files with recognizable names. I'm hoping that I can find a decent backup of my appdata stuff, but I usually take that on the 1st of the month so... yeah. And ofc it's on the array instead of a separate system so worried about the reliability of that.
-
I'm hoping someone has any sliver of decent news about my situation. I had a drive halt and it stopped the array. When I rebooted it came up as a bad file system so I stopped it and restarted in maintenance mode so that I could run the xfs_repair check from it's settings page. The repair finished and I was then able to get the array to start up again. I set about seeing what had happened on the drive and now I'm faced with 10s of thousands of numbered files in my 'lost+found' directory. There are a few directories, but a huge amount of this drive was various appdata subdirectories and that means I have no idea where these files belong even when I have a directory listing of filenames. I guess I'm just looking for confirmation that I'm completely hosed. Thanks.
-
Thank you! It's only in lost+found, but there's quite a bit there.
-
Ran with "-nv" It's not saying exactly what to try next aside from removing "n" so it can better do the repair (and actually perform the repair). Do you see any reason to run anything other than "-v"? Phase 1 - find and verify superblock... - block cache size set to 845784 entries Phase 2 - using internal log - zero log... zero_log: head block 194072 tail block 194068 ALERT: The filesystem has valuable metadata changes in a log which is being ignored because the -n option was used. Expect spurious inconsistencies which may be resolved by first mounting the filesystem to replay the log. - scan filesystem freespace and inode maps... - found root inode chunk Phase 3 - for each AG... - scan (but don't clear) agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 Metadata corruption detected at 0x436cd3, xfs_inode block 0x80/0x4000 bad CRC for inode 128 bad next_unlinked 0x7ef00fbf on inode 128 bad (negative) size -8990289313340167769 on inode 128 bad CRC for inode 131 bad next_unlinked 0x94474835 on inode 131 Bad flags2 set in inode 131 inode 131 is marked bigtime but file system does not support large timestamps would zero timestamps. bad CRC for inode 132 bad next_unlinked 0x9d2ffbdc on inode 132 Bad flags2 set in inode 132 inode 132 is marked bigtime but file system does not support large timestamps would zero timestamps. bad CRC for inode 133 bad next_unlinked 0x40cbedb0 on inode 133 inode identifier 5872355820447164167 mismatch on inode 133 bad CRC for inode 156 bad next_unlinked 0x97860f4f on inode 156 inode identifier 16625386536039003860 mismatch on inode 156 bad CRC for inode 128, would rewrite bad next_unlinked 0x7ef00fbf on inode 128, would reset next_unlinked bad (negative) size -8990289313340167769 on inode 128 would clear root inode 128 bad CRC for inode 131, would rewrite bad next_unlinked 0x94474835 on inode 131, would reset next_unlinked Bad flags2 set in inode 131 inode 131 is marked bigtime but file system does not support large timestamps would zero timestamps. would fix bad flags2. Bad CoW extent size 0 on inode 131, would reset to zero directory inode 131 has bad size 6155860142751504924 would have cleared inode 131 bad CRC for inode 132, would rewrite bad next_unlinked 0x9d2ffbdc on inode 132, would reset next_unlinked Bad flags2 set in inode 132 inode 132 is marked bigtime but file system does not support large timestamps would zero timestamps. would fix bad flags2. Bad CoW extent size 0 on inode 132, would reset to zero directory inode 132 has bad size 6351474981558740519 would have cleared inode 132 bad CRC for inode 133, would rewrite bad next_unlinked 0x40cbedb0 on inode 133, would reset next_unlinked inode identifier 5872355820447164167 mismatch on inode 133 would have cleared inode 133 bad CRC for inode 156, would rewrite bad next_unlinked 0x97860f4f on inode 156, would reset next_unlinked inode identifier 16625386536039003860 mismatch on inode 156 would have cleared inode 156 - agno = 1 - agno = 2 - agno = 3 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... root inode would be lost - check for inodes claiming duplicate blocks... - agno = 0 - agno = 1 bad CRC for inode 128, - agno = 3 - agno = 2 would rewrite bad next_unlinked 0x7ef00fbf on inode 128, would reset next_unlinked bad (negative) size -8990289313340167769 on inode 128 would clear root inode 128 bad CRC for inode 131, would rewrite bad next_unlinked 0x94474835 on inode 131, would reset next_unlinked Bad flags2 set in inode 131 inode 131 is marked bigtime but file system does not support large timestamps would zero timestamps. would fix bad flags2. Would clear next_unlinked in inode 131 Bad CoW extent size 0 on inode 131, would reset to zero directory inode 131 has bad size 6155860142751504924 would have cleared inode 131 bad CRC for inode 132, would rewrite bad next_unlinked 0x9d2ffbdc on inode 132, would reset next_unlinked Bad flags2 set in inode 132 inode 132 is marked bigtime but file system does not support large timestamps would zero timestamps. would fix bad flags2. Would clear next_unlinked in inode 132 Bad CoW extent size 0 on inode 132, would reset to zero directory inode 132 has bad size 6351474981558740519 would have cleared inode 132 bad CRC for inode 133, would rewrite bad next_unlinked 0x40cbedb0 on inode 133, would reset next_unlinked inode identifier 5872355820447164167 mismatch on inode 133 would have cleared inode 133 entry ".." at block 0 offset 80 in directory inode 149 references free inode 131 entry "Rescued.by.Ruby.2022.1080p.NF.WEB-DL.DDP5.1.Atmos.x264-Telly.mkv" in shortform directory 151 references free inode 156 would have junked entry "Rescued.by.Ruby.2022.1080p.NF.WEB-DL.DDP5.1.Atmos.x264-Telly.mkv" in directory inode 151 bad CRC for inode 156, would rewrite bad next_unlinked 0x97860f4f on inode 156, would reset next_unlinked inode identifier 16625386536039003860 mismatch on inode 156 would have cleared inode 156 entry ".." at block 0 offset 80 in directory inode 3263691136 references free inode 131 entry "NCIS" at block 0 offset 96 in directory inode 3263691136 references free inode 133 would clear inode number in entry at offset 96... No modify flag set, skipping phase 5 Phase 6 - check inode connectivity... would reinitialize root directory - traversing filesystem ... - agno = 0 Metadata corruption detected at 0x436cd3, xfs_inode block 0x80/0x4000 entry ".." in directory inode 149 points to free inode 131, would junk entry bad hash table for directory inode 149 (no data entry): would rebuild would rebuild directory inode 149 entry "Rescued.by.Ruby.2022.1080p.NF.WEB-DL.DDP5.1.Atmos.x264-Telly.mkv" in shortform directory inode 151 points to free inode 156 would junk entry - agno = 1 - agno = 2 - agno = 3 entry ".." in directory inode 3263691136 points to free inode 131, would junk entry entry "NCIS" in directory inode 3263691136 points to free inode 133, would junk entry bad hash table for directory inode 3263691136 (no data entry): would rebuild would rebuild directory inode 3263691136 - traversal finished ... - moving disconnected inodes to lost+found ... disconnected dir inode 149, would move to lost+found disconnected dir inode 170, would move to lost+found disconnected dir inode 174, would move to lost+found disconnected dir inode 1263113345, would move to lost+found disconnected dir inode 1263113396, would move to lost+found disconnected dir inode 3249673023, would move to lost+found disconnected dir inode 3263691136, would move to lost+found Phase 7 - verify link counts... would have reset inode 3263691136 nlinks from 86 to 85 No modify flag set, skipping filesystem flush and exiting. XFS_REPAIR Summary Mon Aug 8 10:44:45 2022 Phase Start End Duration Phase 1: 08/08 10:44:44 08/08 10:44:44 Phase 2: 08/08 10:44:44 08/08 10:44:45 1 second Phase 3: 08/08 10:44:45 08/08 10:44:45 Phase 4: 08/08 10:44:45 08/08 10:44:45 Phase 5: Skipped Phase 6: 08/08 10:44:45 08/08 10:44:45 Phase 7: 08/08 10:44:45 08/08 10:44:45 Total run time: 1 second
-
I've got a disk I had trouble with dropping from the array and now when I start the array it reports "Unmountable: Wrong or no file system" on the Main page. I'm pretty sure the data is lost on this one but I thought I'd send in a diagnostic anyhow. reality-diagnostics-20220808-0954.zip
-
Seems to have been something w/ Unassigned Devices. I just removed all 5 entries and recreated them. It's attaching fine now.
-
After a reboot today I suddenly can't connect to my remote SMB shares from two other devices on my network. These had been working for about a year just fine. I have 4 iSCSI targets being serverd from a Drobo 800i through a RaspberryPi4 (RASPBERRYPI). It's basically translating the iSCSI to SMB. Previously the iSCSI was direct linked to my former Windows "server" prior to upgrading to unRAID. There is also an old Buffalo TeraStation (CORE) that I grab one SMB share from. (Yes I know it v1 and it may concern me enough to retire it at some point but I'm ok with it for now.) This is a typical new error block: May 7 01:09:04 REALITY unassigned.devices: Mounting Remote Share '//RASPBERRYPI/drobo'... May 7 01:09:04 REALITY unassigned.devices: Mount SMB share '//RASPBERRYPI/drobo' using SMB default protocol. May 7 01:09:04 REALITY unassigned.devices: Mount SMB command: /sbin/mount -t 'cifs' -o rw,noserverino,nounix,iocharset=utf8,file_mode=0777,dir_mode=0777,uid=99,gid=100,credentials='/tmp/unassigned.devices/credentials_drobo' '//RASPBERRYPI/drobo' '/mnt/remotes/RASPBERRYPI_drobo' May 7 01:09:04 REALITY kernel: CIFS: Attempting to mount //RASPBERRYPI/drobo May 7 01:09:04 REALITY kernel: CIFS: Status code returned 0xc000006d STATUS_LOGON_FAILURE May 7 01:09:04 REALITY kernel: CIFS: VFS: \\RASPBERRYPI Send error in SessSetup = -13 May 7 01:09:04 REALITY kernel: CIFS: VFS: cifs_mount failed w/return code = -13 I haven't setup any new users or security requirements. I'm leaning toward it being on the unRAID side because it's affecting both remote devices, but I'm kind of at a loss. Searching for generic help on the error didn't really reveal any good answers beside "turn it off and on again". Anyone have any other thoughts? I don't even see any place to add credentials. reality-diagnostics-20220507-0109.zip
-
@Mihai, @Zidichy I'm using the v5 template and it all looks like it's running and I can enter data and even connect with the Windows app. However, I cannot upload anywhere. Not in the invoice or expense documents bins, nor any of the import buttons. I don't know what voodoo isn't working. I get no errors or logging of any kind while trying to click the buttons. Not even in the Chrome console. Feeling more and more defeated by this app. Any thoughts on what it might be?
-
I was able to "pull" all the info using the info found on this post. https://stackoverflow.com/questions/32758793/how-to-show-the-run-command-of-a-docker-container I did have a backup but it's a bit stale. Can you point me to the directory where these are stored so I can selectively try to pull it out? And yes I was in the Add Template section because I was looking to try my hand at making a v5 for Invoice Ninja as the one in CA is only the legacy v4. Thought I'd pop up the current one to see how they look before just bumbling through it. AKA New-ish to docker and never tried making up my own template. Oops.
-
Um, do these get backed up anywhere? I, uh, may have hit x on one thinking I was clearing the page instead of DELETEING the template. It had some passwords in it. :facepalm:

