




FreeMan
Members
-
Joined
-
Last visited
Everything posted by FreeMan
-
It's got NOTHING to do with what I thought it did... I had a totally unrelated docker going crazy with log files growing to > 7GB of space. That docker's been deprecated (any wonder why), so I shut it down and deleted it. I've just hit 100% utilization of my 30GB docker.img file, and I think I've nailed the major culprit down to the influxdb docker that was installed to host this dashboard. It's currently at 22.9GB of space. Is anyone else anywhere near this usage? Is there a way to trim the database so that it's not quite so big? I'm trying to decide whether I want to keep this (as cool as it was when it was first launched, it's wandered into a lot of Plex focus on later updates and, since I'm not a Plex user, they don't interest me, plus I've grown a touch bored with this much info overload), or if it's time to just scrap it. I totally appreciate the time and effort that went into building it and @falconexe's efforts and responsiveness in fixing errors and helping a myriad of users through the same teething pains. I'm just not sure it's for me anymore...
-
I think I found the problem. appdata\influxdb is 22.9GB. I believe the majority (if not all) of that is from "Ultimate UNRAID Dashboard" data. Short term, I think the best solution is to simply enlarge the .img file, while long term, I need to decide how much (if any) of that to actually keep. Still open to any other insights anyone may have.
-
My docker.img file is 30GB and is at 100% utilization as we speak. I know that the usual cause of this is poorly configured dockers that are writing things to the wrong path, however, this has been a long, slow fill, and I believe that I've simply filled space with logs or... something... over time as this hasn't been a sudden situation. I got the warning that I was at 91% about 2 weeks ago, but I've been away from the house and wasn't able to look into it, and it wasn't my #1 priority as soon as I returned home. I'm attaching diagnostics which will, I hope, point to what's filling the img file, in the hopes that someone can point me in the right direction of where to cull logs or whatever I need to do to recover some space. If it appears that I have, legitimately filled the img file, I'll recreate it and make it bigger. There are two potential culprits that I can think of: * I installed digiKam a couple of months ago. I had it load my library of > 250,000 images and I've begun cataloging and tagging them. I think that the database files that support this are on the appdata mount point and that they could be getting rather large. (Yes, I realize that I should probably migrate the DB to the mariaDB docker I've got, but that's still on my to do list, and even if I do, it will simply move the space utilized, possibly reducing it somewhat, but not eliminate it.) * I've been having issues with my binhex-delugevpn docker. It's been acting strangely and I noticed that when I restarted the container yesterday, it took about 15 minutes for it to actually properly start and get the GUI up and running. I had the log window open for a good portion of that time, and noted that it was writing quite a bit to that log. It's possible that it's filling and rotating logs and that these are using a fair bit of space. I'm looking into these two to see if they are causing issues, but I'd appreciate another set of eyes and any other tips/pointers on where I may be wasting/consuming unusual amounts of space, and recommended solutions. nas-diagnostics-20220701-1451.zip
-
This is a MINOR, LOW PRIORITY UI issue. I noticed that in 6.10.2, the [close all notifications] button doesn't actually close any of them, instead, it just rearranges them. The issue persists in 6.10.3. I had a bunch of disk usage notifications and took a screen shot (left), I then clicked the [close all notifications] and it rearranged them (middle), clicked it again and it rearranged them again (right). It also gives issues when attempting to close one at a time. From the last arrangement above, right, I clicked the "X" on the 6/18/22 12:05 notification (the bottom one). It briefly disappeared, then reappeared at the bottom of the list: They are now all gone. I believe (I had to leave between grabbing screen shots & making the report) that I had to close them from the top of the list down, and couldn't close from the bottom of the list. i.e., I had to close the 12:07, 12:28, 12:39 etc., instead of simply putting the mouse on the 12:05, closing, and waiting for the list to redraw then close 12:03, 12:01, etc and not have to move the mouse. The work around is a very minor inconvenience, but it's mildly annoying. nas-diagnostics-20220619-1249.zip
-
Not sure where you're wasting space... I've got 8TB data disks that have been filled to within 100MB of max capacity. Just remember, this isn't the OS for everyone.
-
I used -f for a "fast" preclear, but I don't recall ever having used any other command line options, and I don't recall ever having had this issue in the past. As a matter of fact, I just precleared & installed a new drive a few weeks ago and didn't run into this issue. I know preclear isn't necessary anymore as the base OS will do it without having to take down the whole array for hours while it happens, I like having it as a handy disk check utility for new drives. I know there are various theories on this, it's my preference.
-
I just ran a preclear on a new drive (using binhex's preclear docker). After 40 hours it finished with no reported issues. I stopped my array, added the new drive, and started the array. Now it says that a clear is in progress. Why would it start clearing the drive again? Did the preclear somehow fail to properly write the correct signature to the disk? nas-diagnostics-20220406-1510.zip
-
When doing a manual add, I did specify HTTP, not HTTPS.
-
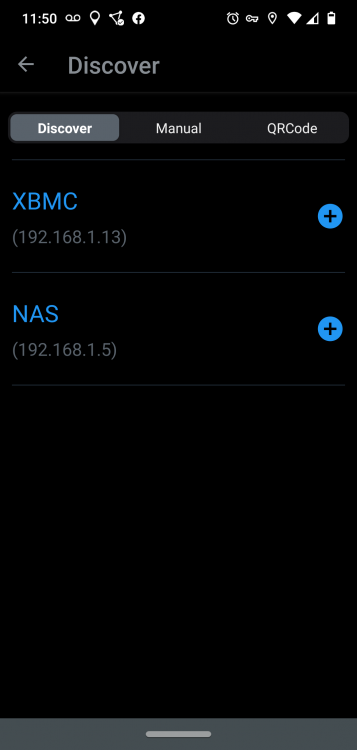
I can reach it via IP in a browser from my phone (though I get warnings about it being HTTP instead of HTTPS). If there are any rules blocking it in the phone, I'm certainly not aware of it, plus, the "Discover" method of adding it can find the server (by IP, I presume?). I honestly don't have a clue what might be blocking access to the server from the phone when the phone can clearly see that the server's there.
-
hmmm... bizarre. The address bar pic is from my desktop machine. My phone cannot resolve nas.local in a browser window, saying "site cannot be reached". When I try adding the server manually by IP address, I get: It's attempting to convert the IP to a host address, it seems, then is failing to resolve the host address back to an IP.
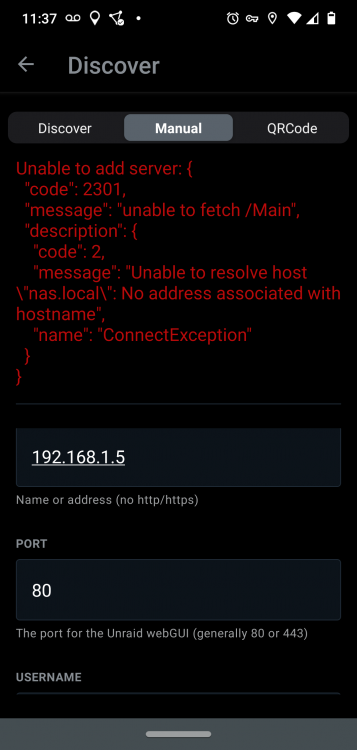
-
I deleted the server. Upon adding it back in (using auto) I got this message: However, nas.local resolves just fine in my browser: Gets me to the ControlR config page w/o issue
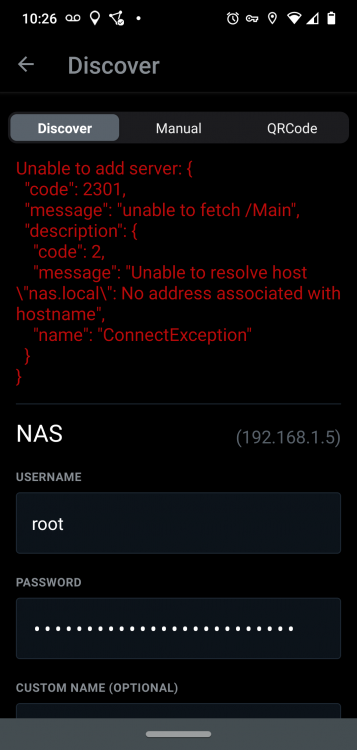

-
I presume deleting the server is by pressing the circled red x in the corner of the server list. There is no response to that.
-
For the last couple of months, The controlR app on my phone (Android) has shown me my server, but I can't tap on the server to get any additional info about it, and it shows a red x in a circle next to it. I've not done any trouble shooting on this in particular, but the server's IP address hasn't changed in ages. The plug in is still running on the server. I have CA auto-update running, so the plug in should be the latest available (v2021.11.25), and I presume that my app is the latest (5.1.1), as I've got autoupdate enabled on the phone too. I just tried clicking on the "Spin Up" option on the Servers list. It popped up a little box with a spinner for a while, but nothing happened on the server itself. Any recommendations on what to check?
-
I may have done that. However, leaving a file on cache instead of on a diskx seems odd. This does seem to be a reasonable explanation, I suppose, though. I've learned to do a copy/delete instead of move when I'm manually working with files in Krusader. I tend to avoid using Windoze for file management (somewhat) because it's a lot slower. I think I avoid most of those other situations, but certainly couldn't guarantee it. I guess that's why I'm finding this a bit perplexing. I'll just do a manual clean up (I've got several other files in this situation, too, I think). Thanks for the insight.
-
Nope, not a clue. That's why I asked. If I have a DVD rip of a movie, then get a Blu-Ray rip by the same name, the mover won't overwrite the older file with the newer one?
-
Looking at my TV share info, I see this: Looking at it from a terminal session, I see: root@NAS:/mnt/cache/TV/Frankie Drake Mysteries/Season 04# ls -la total 4 drwxrwxrwx 1 nobody users 20 Mar 2 2021 ./ drwxrwxrwx 1 nobody users 18 Jan 26 19:26 ../ -rw-rw-rw- 1 nobody users 331 Jan 27 2021 season.nfo root@NAS:/mnt/cache/TV/Frankie Drake Mysteries/Season 04# ls -la /mnt/disk5/TV/Frankie\ Drake\ Mysteries/Season\ 04/ total 4 drwxrwxrwx 2 nobody users 32 Jan 22 19:04 ./ drwxrwxrwx 3 nobody users 124 Jan 26 19:31 ../ -rw-rw-rw- 1 nobody users 331 Jan 27 07:16 season.nfo How is it that the second listing (on /mnt/disk5) didn't/doesn't get overwritten by the file residing on the cache drive when the mover runs? Disk5 is a reasonably full 8TB drive, but it's still got almost 700GB of free space - more than plenty to store a 331 byte file, and even then, it shouldn't matter, because the file in Cache should simply overwrite the file on the array. I can, and probably will, simply delete the file from the cache dir, but why does it seem that the mover isn't doing its job here?

-
It's been 7 years, is this still in your server? If so, how have temps been? How has it held up to drive changes? Would you buy it again? (Do they still make it?)
-
I just picked up an IcyDock Fat Cage and installed it in my Zalman MS800 case. Slid right in with no problems (I long ago bent down the drive mount tabs to fit my old 5x3 cages in). I was able to use one of the case's quick locks to hold the dock in place instead of using the provided screws. This is a big full-size tower case with 10 5.25" bays front accessible, so there's plenty of room for the dock. It even allowed me to gain access to an additional 15-pin power connector and run it to the very top bay to plug in the last SSD that I'd installed but hadn't yet been able to power up. (Lack of 4-pin Molex connectors to adapt to 15-pin SATA, and hadn't yet purchased a 15-pin extender.) I had a heck of a time getting the one SATA cable plugged in that goes on the MoBo side of the case, so when I have to remove the dock, I'll leave that plugged into the doc, and pull it from the MoBo, instead. I say "when" I have to remove the dock because I've just ordered a Noctua NF-B9 fan because now I'm sitting next to a vacuum cleaner. The stock fan in this is loudI! Also, I may have to return the whole thing since one of the drive trays was bent. The bottom of the tray curved into the drive. I had to flex the tray a bit to get the screw holes to line up with the drive, and it was still difficult to get the tray to slide into the dock. Because of this, the server wouldn't recognize the drive, no matter which slot in the dock it was plugged into. I put the drive into another tray and the server was most happy. I've contacted the seller to see if I can get a swap on just the tray or if I'm going to have to send the whole thing back. I haven't done a parity check yet, but in normal use (less than 24 hours since install), drive temps for the 3 drives that are in the dock are on par with the other drives, so I'm going to guess that they'll stay that way. I've got loads of little bits of packing foam, so I may try cutting some filler blocks to put into the unused trays to see if that helps improve air flow.
-
I've got two cache pools: Name: Apps Consists of a single SSD Name: Cache Consists of a pool of 3 SSD The astute among you will see the issue here. I've already set my Apps pool cache setting to "Yes" (from "Prefer") so I can migrate data onto the array. (Involves stopping all dockers & the docker service. VM service isn't running.) Once I've got the data off the Apps and Cache pool, what's the best way to swap the names so I can have all my dockers live on the actual pool for some drive failure resistance? I'm thinking: Rename "Apps" to "temp" Rename "Cache" to "Apps" Rename "temp" to "Cache" Set Apps cache setting back to Prefer Run mover Restart docker service & dockers. Does this make sense? Is there an easier way? Have I missed something?
-
OK. I'll wait patiently. I'm pretty sure it was more than "seconds" more like "at least a minute". I know I'm an impatient fella, but it really was slower than "seconds". As a matter of fact, I'd waited a bit, then I typed up this question and it still hadn't shown up. Could just be that my machine isn't the fastest thing out there. I'll be sure to be patient in the future. Thanks as always!
-
Forest, meet trees. Sheesh. I did actually look at that, but it just didn't register. `If set to 'Yes' then if the device configuration is correct upon server start-up, the array will be automatically Started and shares exported.` I am set to "Yes". However, since the config wasn't correct, it didn't auto start. ------------------------------- OK, that small drama is resolved. However, I'm still curious what caused the server to recognize that the drive was there. Was it: 1) Passage of time? i.e. the server polls every couple of minutes looking for a drive to "magically" appear (expecting that there's a hot-swap cage and it might.) 2) I looked at the right setting somewhere that caused it to rescan drives and notice that the disk was now there? If it's the first, I now know to be patient and wait. If it's the second, I'd like to know what I looked at so I can trigger it intentionally the next time.
-
I'm going to guess that no, I do not. However, I don't recall where that setting is and a quick browse hasn't turned it up, so I can't confirm
-
huh... After poking through a variety of settings, the Main screen is now showing the drive is there. I would like to know if I did something (I looked at settings but didn't change anything) or if it's just a matter of time before it'll notice that the drive is now available.
-
When the server booted, the array didn't start and it shows: So, if you would, please have a chat with my server and let it know what it's supposed to be doing. TBH, that does make sense that it should have started the array with a missing disk. However, it didn't and here we are... As it turns out, the caddy I put that particular disk in was slightly bent fresh out of the box. Again - an issue to take up with the vendor. Is there a way to now get unraid to recognize that I've plugged the disk back in other than rebooting the server?
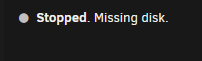
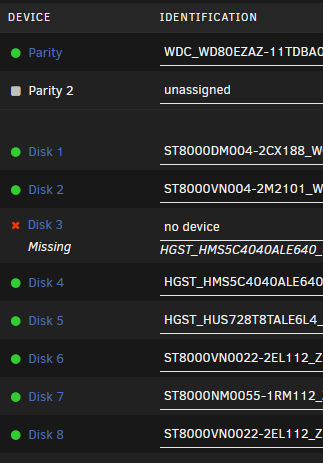
-
Sorry, I wasn't clear enough: The array never started because one drive was unrecognized on boot. I moved that drive to a different slot in the cage and it powered up. Is there a way, short of a reboot, of getting UNRAID to notice that the disk is now there?







