



Craig Dennis
Members
-
Joined
-
Last visited
Everything posted by Craig Dennis
-
After removing two sticks of RAM I was still experiencing crashes. I replaced with the other two sticks and have been up for 24 hours. Memtest reported no errors. I also thought Netdata docker was causing issues due some errors in the log Sep 22 21:22:32 Sakaar kernel: netdata[23864]: segfault at 30 ip 0000149933ef42c0 sp 000014992f5af500 error 4 in ld-musl-x86_64.so.1[149933eb1000+4c000] likely on CPU 9 (core 1, socket 0) Sep 22 21:22:32 Sakaar kernel: Code: 29 45 31 c0 31 c9 31 d2 4c 89 e6 bf 0f 00 00 00 31 c0 e8 d1 80 fc ff 89 c3 85 c0 0f 84 83 00 00 00 e8 7a 4c fc ff 8b 18 eb 7a <8b> 4d 30 48 8d 5c 24 0e be 22 00 00 00 31 c0 48 8d 15 aa db 03 00 Re-enabled with the second sticks of RAM and no issues.
-
This is all too familiar. 1st pass memtest with no issues. I'll remove 2 RAM sticks. Thanks for the help (again).
-
I ran that a few weeks ago. I'll run it again. Could this also indicate CPU hardware fault?
-
How did you identify the faulty disk? Mine are all showing as good.
-
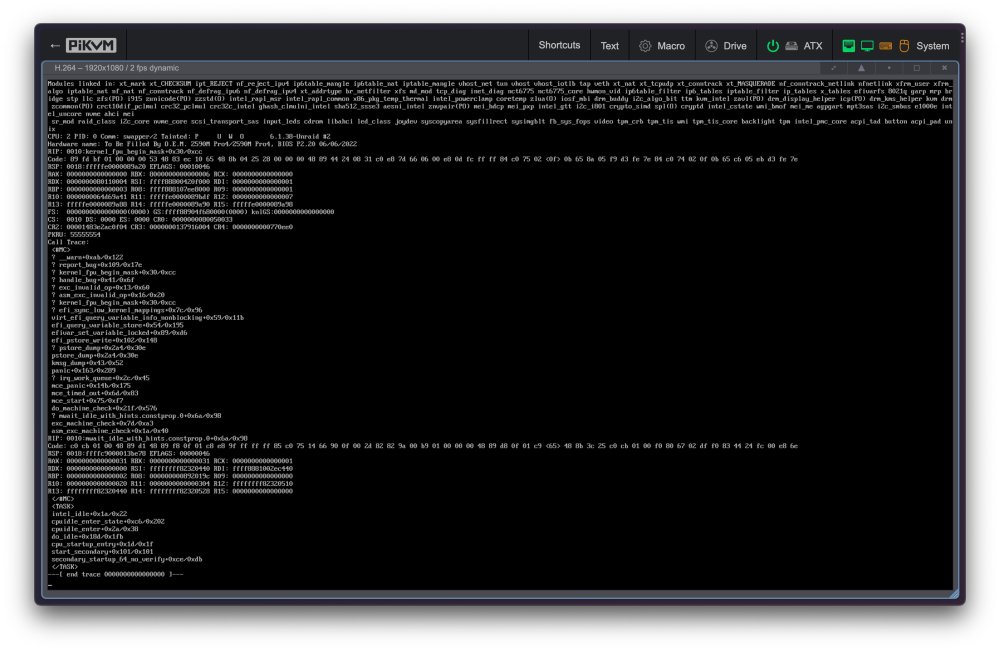
I am having issues after my server has been running for 30 mins to an hour. The UI crashes completely and I get output to the screen showing `tainted` and other worrying things. I have been having issues with overheating so I'm wondering if I have damaged the CPU somehow. Services still appear to be running (e.g. I can still access Plex) but not the Unraid web UI. Can someone help me decipher the errors please? Attached are the diagnostics. Below is also the output from the syslog mirrored to the flash drive (full log from today attached as well). Sep 22 10:24:16 Sakaar kernel: BUG: kernel NULL pointer dereference, address: 0000000000000000 Sep 22 10:24:16 Sakaar kernel: #PF: supervisor read access in kernel mode Sep 22 10:24:16 Sakaar kernel: #PF: error_code(0x0000) - not-present page Sep 22 10:24:16 Sakaar kernel: PGD 0 P4D 0 Sep 22 10:24:16 Sakaar kernel: Oops: 0000 [#1] PREEMPT SMP NOPTI Sep 22 10:24:16 Sakaar kernel: CPU: 5 PID: 23791 Comm: python3 Tainted: P U O 6.1.49-Unraid #1 Sep 22 10:24:16 Sakaar kernel: Hardware name: To Be Filled By O.E.M. Z590M Pro4/Z590M Pro4, BIOS P2.20 06/06/2022 Sep 22 10:24:16 Sakaar kernel: RIP: 0010:get_mmap_base+0xe/0x47 Sep 22 10:24:16 Sakaar kernel: Code: ff ff 48 8d 73 38 49 89 e8 4c 89 e1 48 8d 7b 30 5b 48 89 c2 5d 41 5c e9 5e fe ff ff 0f 1f 44 00 00 65 48 8b 14 25 c0 cb 01 00 <f6> 42 10 02 48 8b 82 f8 03 00 00 75 0d 85 ff 74 1f 48 8b 40 28 c3 Sep 22 10:24:16 Sakaar kernel: RSP: 0018:ffffc9002c64bd60 EFLAGS: 00010246 Sep 22 10:24:16 Sakaar kernel: RAX: 0000000000000000 RBX: 0000000000009000 RCX: 0000000000000000 Sep 22 10:24:16 Sakaar kernel: RDX: 0000000000000000 RSI: 0000000000000000 RDI: 0000000000000000 Sep 22 10:24:16 Sakaar kernel: RBP: 0000000000000000 R08: 0000000000000022 R09: 0000000000000000 Sep 22 10:24:16 Sakaar kernel: R10: 0000000000000003 R11: 0000000000000000 R12: 0000000000000022 Sep 22 10:24:16 Sakaar kernel: R13: 0000000000000000 R14: ffff8883fad30cc0 R15: 0000000000000000 Sep 22 10:24:16 Sakaar kernel: FS: 00001523c6161b48(0000) GS:ffff88904f740000(0000) knlGS:0000000000000000 Sep 22 10:24:16 Sakaar kernel: CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 Sep 22 10:24:16 Sakaar kernel: CR2: 0000000000000000 CR3: 000000065009a005 CR4: 0000000000770ee0 Sep 22 10:24:16 Sakaar kernel: PKRU: 55555554 Sep 22 10:24:16 Sakaar kernel: Call Trace: Sep 22 10:24:16 Sakaar kernel: <TASK> Sep 22 10:24:16 Sakaar kernel: ? __die_body+0x1a/0x5c Sep 22 10:24:16 Sakaar kernel: ? page_fault_oops+0x329/0x376 Sep 22 10:24:16 Sakaar kernel: ? do_user_addr_fault+0x12e/0x48d Sep 22 10:24:16 Sakaar kernel: ? exc_page_fault+0xfb/0x11d Sep 22 10:24:16 Sakaar kernel: ? asm_exc_page_fault+0x22/0x30 Sep 22 10:24:16 Sakaar kernel: ? get_mmap_base+0xe/0x47 Sep 22 10:24:16 Sakaar kernel: arch_get_unmapped_area_topdown+0xdd/0x1b2 Sep 22 10:24:16 Sakaar kernel: ? preempt_latency_start+0x1e/0x46 Sep 22 10:24:16 Sakaar kernel: get_unmapped_area+0xc4/0x14f Sep 22 10:24:16 Sakaar kernel: do_mmap+0x110/0x428 Sep 22 10:24:16 Sakaar kernel: vm_mmap_pgoff+0xbb/0x112 Sep 22 10:24:16 Sakaar kernel: ksys_mmap_pgoff+0x138/0x166 Sep 22 10:24:16 Sakaar kernel: do_syscall_64+0x68/0x81 Sep 22 10:24:16 Sakaar kernel: entry_SYSCALL_64_after_hwframe+0x64/0xce Sep 22 10:24:16 Sakaar kernel: RIP: 0033:0x1523c61001c2 Sep 22 10:24:16 Sakaar kernel: Code: f6 c1 10 74 0f 4c 89 4c 24 08 e8 d5 fc 01 00 4c 8b 4c 24 08 48 63 d5 4c 63 d3 4d 63 c6 b8 09 00 00 00 4c 89 e7 4c 89 ee 0f 05 <48> 89 c7 48 83 f8 ff 75 20 4d 85 e4 75 1b 83 e3 30 48 c7 c0 f4 ff Sep 22 10:24:16 Sakaar kernel: RSP: 002b:00007ffedcd4b860 EFLAGS: 00000246 ORIG_RAX: 0000000000000009 Sep 22 10:24:16 Sakaar kernel: RAX: ffffffffffffffda RBX: 0000000000000022 RCX: 00001523c61001c2 Sep 22 10:24:16 Sakaar kernel: RDX: 0000000000000003 RSI: 0000000000009000 RDI: 0000000000000000 Sep 22 10:24:16 Sakaar kernel: RBP: 0000000000000003 R08: ffffffffffffffff R09: 0000000000000000 Sep 22 10:24:16 Sakaar kernel: R10: 0000000000000022 R11: 0000000000000246 R12: 0000000000000000 Sep 22 10:24:16 Sakaar kernel: R13: 0000000000009000 R14: 00000000ffffffff R15: 00001523c615fb00 Sep 22 10:24:16 Sakaar kernel: </TASK> Sep 22 10:24:16 Sakaar kernel: Modules linked in: wireguard curve25519_x86_64 libcurve25519_generic libchacha20poly1305 chacha_x86_64 poly1305_x86_64 ip6_udp_tunnel udp_tunnel libchacha xt_CHECKSUM ipt_REJECT nf_reject_ipv4 ip6table_mangle ip6table_nat iptable_mangle vhost_net tun vhost vhost_iotlb tap ipvlan veth xt_nat xt_tcpudp xt_conntrack xt_MASQUERADE nf_conntrack_netlink nfnetlink xfrm_user iptable_nat nf_nat nf_conntrack nf_defrag_ipv6 nf_defrag_ipv4 xt_addrtype br_netfilter xfs md_mod tcp_diag inet_diag nct6775 nct6775_core hwmon_vid ip6table_filter ip6_tables iptable_filter ip_tables x_tables efivarfs af_packet bridge 8021q garp mrp stp llc ixgbe xfrm_algo mdio e1000e zfs(PO) i915 zunicode(PO) intel_rapl_msr intel_rapl_common x86_pkg_temp_thermal zzstd(O) intel_powerclamp coretemp kvm_intel zlua(O) zavl(PO) kvm icp(PO) iosf_mbi drm_buddy i2c_algo_bit ttm drm_display_helper drm_kms_helper mei_pxp mei_hdcp crct10dif_pclmul crc32_pclmul crc32c_intel zcommon(PO) drm ghash_clmulni_intel sha512_ssse3 Sep 22 10:24:16 Sakaar kernel: aesni_intel znvpair(PO) mei_me intel_gtt crypto_simd spl(O) cryptd wmi_bmof intel_cstate mpt3sas agpgart intel_uncore i2c_i801 nvme i2c_smbus raid_class sr_mod i2c_core mei ahci nvme_core scsi_transport_sas cdrom input_leds joydev led_class libahci syscopyarea sysfillrect sysimgblt fb_sys_fops video tpm_crb tpm_tis tpm_tis_core wmi tpm backlight intel_pmc_core acpi_tad acpi_pad button unix [last unloaded: xfrm_algo] Sep 22 10:24:16 Sakaar kernel: CR2: 0000000000000000 Sep 22 10:24:16 Sakaar kernel: ---[ end trace 0000000000000000 ]--- Sep 22 10:24:16 Sakaar kernel: RIP: 0010:get_mmap_base+0xe/0x47 Sep 22 10:24:16 Sakaar kernel: Code: ff ff 48 8d 73 38 49 89 e8 4c 89 e1 48 8d 7b 30 5b 48 89 c2 5d 41 5c e9 5e fe ff ff 0f 1f 44 00 00 65 48 8b 14 25 c0 cb 01 00 <f6> 42 10 02 48 8b 82 f8 03 00 00 75 0d 85 ff 74 1f 48 8b 40 28 c3 Sep 22 10:24:16 Sakaar kernel: RSP: 0018:ffffc9002c64bd60 EFLAGS: 00010246 Sep 22 10:24:16 Sakaar kernel: RAX: 0000000000000000 RBX: 0000000000009000 RCX: 0000000000000000 Sep 22 10:24:16 Sakaar kernel: RDX: 0000000000000000 RSI: 0000000000000000 RDI: 0000000000000000 Sep 22 10:24:16 Sakaar kernel: RBP: 0000000000000000 R08: 0000000000000022 R09: 0000000000000000 Sep 22 10:24:16 Sakaar kernel: R10: 0000000000000003 R11: 0000000000000000 R12: 0000000000000022 Sep 22 10:24:16 Sakaar kernel: R13: 0000000000000000 R14: ffff8883fad30cc0 R15: 0000000000000000 Sep 22 10:24:16 Sakaar kernel: FS: 00001523c6161b48(0000) GS:ffff88904f740000(0000) knlGS:0000000000000000 Sep 22 10:24:16 Sakaar kernel: CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 Sep 22 10:24:16 Sakaar kernel: CR2: 0000000000000000 CR3: 000000065009a005 CR4: 0000000000770ee0 Sep 22 10:24:16 Sakaar kernel: PKRU: 55555554 Sep 22 10:24:16 Sakaar kernel: note: python3[23791] exited with irqs disabled sakaar-diagnostics-20230922-1257.zip syslog
-
Mine was related to overheating. Mover caused NVMe and HDDs to run hot and overheat the CPU causing a shutdown. Bios meant it would start up again. Solved for me. I used NetData to track all temps; some were _much_ higher than Unraid Temp addon was reporting.
-
My issue has been resolved but what an issue. I had one bad RAM module as well as intermittent overheating. No wonder it was so difficult to isolate.
-
It looks like I had one bad RAM stick that has subsequently failed. Possibly due to overheating.
-
I have commented on other posts because my server seems to crash when Plex or Jellyfin are scanning files or running scheduled maintenance. It also seems to crash while trying to install Windows on a VM. There was nothing in the logs which points to a hardware issue but I've swapped almost everything out. I recently reduced my RAM speed to 2666 based on a suggestions from another post and now it's crashing more frequently. I managed to capture the screen as the server crashed just now and caught the following error. WARNING: CPU: 9 PID: 0 at arch/x86/kernel/fpu/core.c:424 kernel_fpu_begin_mask+0x30/0xcc And then the server crashed again while trying to download the syslog. I'm currently trying to diagnose the issue but can't find results here or on the wider internet regarding the message. Has the RAM speed change made things worse? Or merely exposed the RAM as the potential hardware issue? I ran memtest a few days ago and all was clear. Has anyone encountered this before? sakaar-diagnostics-20230811-2237.zip
-
I just installed Jellyfin and went through the setup process and the initial scanning killed the server. Again nothing in the logs. This suggests the issue _is_ at least partly a hardware issue. All I have left are the CPU and motherboard but both work fine unless intensely scanning files. I have tried: - New power supply - New cables - Memtest (clear) - Safe mode (with and without starting the array) - Multiple different Plex docker images - None of the HDD or NVMe are reporting errors I have a new motherboard and the CPU appears to work fine (hw transcoding fine). Could this be a HDD issue? I can run for days with no crash until I start the Plex docker. Then scheduled maintenance kills the server. Complete panic and reboot but nothing in the logs. Aug 10 15:18:08 Sakaar kernel: eth0: renamed from veth8e9cec0 Aug 10 15:18:08 Sakaar kernel: IPv6: ADDRCONF(NETDEV_CHANGE): veth2823d2e: link becomes ready [ crash occurerd at approx 15:58] Aug 10 15:59:33 Sakaar kernel: microcode: microcode updated early to revision 0x56, date = 2022-08-02 Aug 10 15:59:33 Sakaar kernel: Linux version 6.1.38-Unraid (root@Develop-612) (gcc (GCC) 12.2.0, GNU ld version 2.40-slack151) #2 SMP PREEMPT_DYNAMIC Mon Jul 10 09:50:25 PDT 2023 Attached is my syslog (mirrored to the Flash drive) and diagnostics in case someone can see something I can't. EDIT: Jellyfin shows some failures in the logs prior to the crash but there are a few of the same type and I'm not sure that it could cause a crash. MediaBrowser.Common.FfmpegException: ffmpeg image extraction failed for file:"/media/tv/Taskmaster/Season 12/Taskmaster (2015) - S12E01 - An Imbalance in the Poppability [WEBDL-1080p][AAC 2.0][x264]-NTb.mkv" at MediaBrowser.MediaEncoding.Encoder.MediaEncoder.ExtractImageInternal(String inputPath, String container, MediaStream videoStream, Nullable`1 imageStreamIndex, Nullable`1 threedFormat, Nullable`1 offset, Boolean useIFrame, Nullable`1 targetFormat, CancellationToken cancellationToken) at MediaBrowser.MediaEncoding.Encoder.MediaEncoder.ExtractImage(String inputFile, String container, MediaStream videoStream, Nullable`1 imageStreamIndex, MediaSourceInfo mediaSource, Boolean isAudio, Nullable`1 threedFormat, Nullable`1 offset, Nullable`1 targetFormat, CancellationToken cancellationToken) at Emby.Server.Implementations.MediaEncoder.EncodingManager.RefreshChapterImages(Video video, IDirectoryService directoryService, IReadOnlyList`1 chapters, Boolean extractImages, Boolean saveChapters, CancellationToken cancellationToken) sakaar-diagnostics-20230810-1602.zip syslog (15)
-
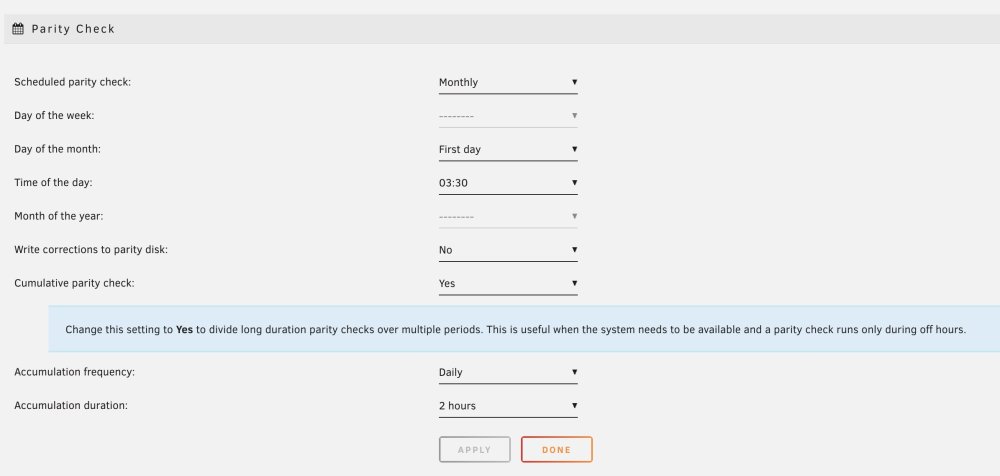
Good to know. I'm also on 6.12.2 so may not be the same issue. I have noticed a new parity check accumulation feature (I don't know when this was added) which may have been conflicting with the Parity Check Tuning plugin. I only recently enabled Mover logging so we'll see. I've manually initiated Mover now and have also changed the scheduled time to see if the crashes also change. It could also be hardware. With nothing in logs it's difficult to tell. Constant hard reboots since 6.12 i915 issues could have damaged something.
-
My server has been crashing consistently in the middle of the night (full reboot) and Mover is the only thing scheduled to run at that time. The last few log entries are related to Mover and Parity Check Tuning. I have removed that plugin and will see if the crashes persist. No errors in syslog. Also ordered a new PSU to eliminate that. I don't really want to run Memtest but I guess I'll have to if none of these work.
-
Unraid is now crashing every night at around 3am (corresponding to the scheduled maintenance window - periodic scanning disabled). I'm going to change that and see if the reboots change as well. Currently running: Unraid 6.12.2 Plex 4.108.0 I have ordered a new power supply to rule that out.
-
Ok it seems like every time the server transcodes something it crashes. After several hours of stability I tried to watch something on my phone, opened Plex Dash app and it was a spinning wheel. Then I got a notification saying the server was offline (from Home Assistant). I wonder if this is a CPU issue or a RAM issue triggered by Plex transcoding. It does transcode, and shows hw in the details. This time it stayed off instead of rebooting. I’m not sure why it was crashing every hour before and disabling/enabling the scanner fixed that. More testing needed.
-
No crash yet after 3 hours (over 2 since enabling hourly scan) so maybe not Plex library scan. I’ll enable a new Docker every couple of hours to see if it happens again.
-
Unraid 6.12.1 Plex 4.1.08 (official) My server was rebooting every hour (or there about) and it used to be every day (for the last week) and I realised I’d changed the library scan interval in Plex. I ran unraid in safe mode and turned off Docker etc. no reboots. Enabled Docker and Plex - reboots every hour. Turned off scheduled library scan and uptime was 8 hours plus (overnight) so I’m concluding that’s the culprit. I’ve just re-enabled library scan for hourly so we’ll see if it crashes in an hour. I have a ping sensor on home assistant so I can clearly see when it went down and came back. Any ideas what would cause this behaviour? Next step is a fresh Plex install in a new container.
-
Are you concluding from this crash that the issue is with either the Docker service itself or a container you're running? Would disabling 'auto start' for all containers and rebooting determine if it's a container or the service itself (if it stays up for 4+ hours)? I'm by no means an expert but am experiencing similar issues with 6.12.
-
I recently had to switch back to an old motherboard and everything seemed to go fine with the transplant. Fired up unraid and everything worked. For about 20 mins. Then it became unresponsive. Power buttons are unresponsive but the computer is still on and fans still spinning. This happens repeatedly. I've swapped out the USB drive, booted into safe mode (no plugins). The only thing I can think is that it's a CPU issue. I can see this in the diagnostics. WARNING: CPU: 6 PID: 8994 at drivers/gpu/drm/i915/display/intel_display_power_well.c:271 hsw_wait_for_power_well_enable+0xc9/0xd8 ASrock H510M (mITX) Intel 11700K Potentially related: Diagnostics attached. sakaar-diagnostics-20230601-2112.zip
-
The VM locked up again with all pinned cores at 100% but the host system did not sleep. It happened within a couple of hours. Again, nothing I can see in the VM logs: 2023-05-10 14:26:43.174+0000: Starting external device: TPM Emulator /usr/bin/swtpm socket --ctrl 'type=unixio,path=/run/libvirt/qemu/swtpm/1-Windows 11-swtpm.sock,mode=0600' --tpmstate dir=/var/lib/libvirt/swtpm/eb86ceb7-fe1e-143b-e4e7-3d54d80ac0a2/tpm2,mode=0600 --log 'file=/var/log/swtpm/libvirt/qemu/Windows 11-swtpm.log' --terminate --tpm2 2023-05-10 14:26:43.182+0000: Starting external device: virtiofsd /usr/libexec/virtiofsd --fd=35 -o source=/mnt/user/craigmdennis,cache=always,sandbox=chroot,xattr 2023-05-10 14:26:43.208+0000: starting up libvirt version: 8.7.0, qemu version: 7.1.0, kernel: 6.1.27-Unraid, hostname: Sakaar LC_ALL=C \ PATH=/bin:/sbin:/usr/bin:/usr/sbin \ HOME='/var/lib/libvirt/qemu/domain-1-Windows 11' \ XDG_DATA_HOME='/var/lib/libvirt/qemu/domain-1-Windows 11/.local/share' \ XDG_CACHE_HOME='/var/lib/libvirt/qemu/domain-1-Windows 11/.cache' \ XDG_CONFIG_HOME='/var/lib/libvirt/qemu/domain-1-Windows 11/.config' \ /usr/local/sbin/qemu \ -name 'guest=Windows 11,debug-threads=on' \ -S \ -object '{"qom-type":"secret","id":"masterKey0","format":"raw","file":"/var/lib/libvirt/qemu/domain-1-Windows 11/master-key.aes"}' \ -blockdev '{"driver":"file","filename":"/usr/share/qemu/ovmf-x64/OVMF_CODE-pure-efi-tpm.fd","node-name":"libvirt-pflash0-storage","auto-read-only":true,"discard":"unmap"}' \ -blockdev '{"node-name":"libvirt-pflash0-format","read-only":true,"driver":"raw","file":"libvirt-pflash0-storage"}' \ -blockdev '{"driver":"file","filename":"/etc/libvirt/qemu/nvram/eb86ceb7-fe1e-143b-e4e7-3d54d80ac0a2_VARS-pure-efi-tpm.fd","node-name":"libvirt-pflash1-storage","auto-read-only":true,"discard":"unmap"}' \ -blockdev '{"node-name":"libvirt-pflash1-format","read-only":false,"driver":"raw","file":"libvirt-pflash1-storage"}' \ -machine pc-i440fx-7.1,usb=off,dump-guest-core=off,mem-merge=off,memory-backend=pc.ram,pflash0=libvirt-pflash0-format,pflash1=libvirt-pflash1-format \ -accel kvm \ -cpu host,migratable=on,hv-time=on,hv-relaxed=on,hv-vapic=on,hv-spinlocks=0x1fff,hv-vendor-id=none,host-cache-info=on,l3-cache=off \ -m 16384 \ -object '{"qom-type":"memory-backend-memfd","id":"pc.ram","share":true,"x-use-canonical-path-for-ramblock-id":false,"size":17179869184}' \ -overcommit mem-lock=off \ -smp 12,sockets=1,dies=1,cores=6,threads=2 \ -uuid eb86ceb7-fe1e-143b-e4e7-3d54d80ac0a2 \ -display none \ -no-user-config \ -nodefaults \ -chardev socket,id=charmonitor,fd=34,server=on,wait=off \ -mon chardev=charmonitor,id=monitor,mode=control \ -rtc base=localtime \ -no-hpet \ -no-shutdown \ -boot strict=on \ -device '{"driver":"ich9-usb-ehci1","id":"usb","bus":"pci.0","addr":"0x7.0x7"}' \ -device '{"driver":"ich9-usb-uhci1","masterbus":"usb.0","firstport":0,"bus":"pci.0","multifunction":true,"addr":"0x7"}' \ -device '{"driver":"ich9-usb-uhci2","masterbus":"usb.0","firstport":2,"bus":"pci.0","addr":"0x7.0x1"}' \ -device '{"driver":"ich9-usb-uhci3","masterbus":"usb.0","firstport":4,"bus":"pci.0","addr":"0x7.0x2"}' \ -device '{"driver":"virtio-serial-pci","id":"virtio-serial0","bus":"pci.0","addr":"0x4"}' \ -blockdev '{"driver":"file","filename":"/mnt/user/domains/Windows 11 - Gaming/vdisk1.img","node-name":"libvirt-4-storage","cache":{"direct":false,"no-flush":false},"auto-read-only":true,"discard":"unmap"}' \ -blockdev '{"node-name":"libvirt-4-format","read-only":false,"cache":{"direct":false,"no-flush":false},"driver":"raw","file":"libvirt-4-storage"}' \ -device '{"driver":"virtio-blk-pci","bus":"pci.0","addr":"0x5","drive":"libvirt-4-format","id":"virtio-disk2","bootindex":1,"write-cache":"on","serial":"vdisk1"}' \ -blockdev '{"driver":"host_device","filename":"/dev/disk/by-id/ata-CT2000BX500SSD1_2250E69357F9","node-name":"libvirt-3-storage","cache":{"direct":false,"no-flush":false},"auto-read-only":true,"discard":"unmap"}' \ -blockdev '{"node-name":"libvirt-3-format","read-only":false,"cache":{"direct":false,"no-flush":false},"driver":"raw","file":"libvirt-3-storage"}' \ -device '{"driver":"virtio-blk-pci","bus":"pci.0","addr":"0x6","drive":"libvirt-3-format","id":"virtio-disk3","write-cache":"on","serial":"vdisk2"}' \ -blockdev '{"driver":"file","filename":"/mnt/user/isos/Win11_EnglishInternational_x64v1.iso","node-name":"libvirt-2-storage","auto-read-only":true,"discard":"unmap"}' \ -blockdev '{"node-name":"libvirt-2-format","read-only":true,"driver":"raw","file":"libvirt-2-storage"}' \ -device '{"driver":"ide-cd","bus":"ide.0","unit":0,"drive":"libvirt-2-format","id":"ide0-0-0","bootindex":2}' \ -blockdev '{"driver":"file","filename":"/mnt/user/isos/virtio-win-0.1.229-1.iso","node-name":"libvirt-1-storage","auto-read-only":true,"discard":"unmap"}' \ -blockdev '{"node-name":"libvirt-1-format","read-only":true,"driver":"raw","file":"libvirt-1-storage"}' \ -device '{"driver":"ide-cd","bus":"ide.0","unit":1,"drive":"libvirt-1-format","id":"ide0-0-1"}' \ -chardev 'socket,id=chr-vu-fs0,path=/var/lib/libvirt/qemu/domain-1-Windows 11/fs0-fs.sock' \ -device '{"driver":"vhost-user-fs-pci","id":"fs0","chardev":"chr-vu-fs0","queue-size":1024,"tag":"craigmdennis","bus":"pci.0","addr":"0x2"}' \ -netdev tap,fd=35,id=hostnet0 \ -device '{"driver":"virtio-net","netdev":"hostnet0","id":"net0","mac":"52:54:00:39:84:e6","bus":"pci.0","addr":"0x3"}' \ -chardev pty,id=charserial0 \ -device '{"driver":"isa-serial","chardev":"charserial0","id":"serial0","index":0}' \ -chardev socket,id=charchannel0,fd=33,server=on,wait=off \ -device '{"driver":"virtserialport","bus":"virtio-serial0.0","nr":1,"chardev":"charchannel0","id":"channel0","name":"org.qemu.guest_agent.0"}' \ -chardev 'socket,id=chrtpm,path=/run/libvirt/qemu/swtpm/1-Windows 11-swtpm.sock' \ -tpmdev emulator,id=tpm-tpm0,chardev=chrtpm \ -device '{"driver":"tpm-tis","tpmdev":"tpm-tpm0","id":"tpm0"}' \ -device '{"driver":"usb-tablet","id":"input0","bus":"usb.0","port":"1"}' \ -audiodev '{"id":"audio1","driver":"none"}' \ -device '{"driver":"vfio-pci","host":"0000:01:00.0","id":"hostdev0","bus":"pci.0","addr":"0x8"}' \ -device '{"driver":"vfio-pci","host":"0000:01:00.1","id":"hostdev1","bus":"pci.0","addr":"0x9"}' \ -sandbox on,obsolete=deny,elevateprivileges=deny,spawn=deny,resourcecontrol=deny \ -msg timestamp=on char device redirected to /dev/pts/0 (label charserial0)
-
When I look at the libvert logs it shows this message about 50 times: 8355: error : virNetSocketReadWire:1791 : End of file while reading data: Input/output error I can't see anything in the VM logs but I'll wait until the system has performed the usual sleep/wake to look again. text error warn system array login 2023-05-08 06:46:46.850+0000: Starting external device: TPM Emulator /usr/bin/swtpm socket --ctrl 'type=unixio,path=/run/libvirt/qemu/swtpm/1-Windows 11-swtpm.sock,mode=0600' --tpmstate dir=/var/lib/libvirt/swtpm/eb86ceb7-fe1e-143b-e4e7-3d54d80ac0a2/tpm2,mode=0600 --log 'file=/var/log/swtpm/libvirt/qemu/Windows 11-swtpm.log' --terminate --tpm2 2023-05-08 06:46:46.855+0000: Starting external device: virtiofsd /usr/libexec/virtiofsd --fd=35 -o source=/mnt/user/craigmdennis,cache=always,sandbox=chroot,xattr 2023-05-08 06:46:46.875+0000: starting up libvirt version: 8.7.0, qemu version: 7.1.0, kernel: 6.1.27-Unraid, hostname: Sakaar LC_ALL=C \ PATH=/bin:/sbin:/usr/bin:/usr/sbin \ HOME='/var/lib/libvirt/qemu/domain-1-Windows 11' \ XDG_DATA_HOME='/var/lib/libvirt/qemu/domain-1-Windows 11/.local/share' \ XDG_CACHE_HOME='/var/lib/libvirt/qemu/domain-1-Windows 11/.cache' \ XDG_CONFIG_HOME='/var/lib/libvirt/qemu/domain-1-Windows 11/.config' \ /usr/local/sbin/qemu \ -name 'guest=Windows 11,debug-threads=on' \ -S \ -object '{"qom-type":"secret","id":"masterKey0","format":"raw","file":"/var/lib/libvirt/qemu/domain-1-Windows 11/master-key.aes"}' \ -blockdev '{"driver":"file","filename":"/usr/share/qemu/ovmf-x64/OVMF_CODE-pure-efi-tpm.fd","node-name":"libvirt-pflash0-storage","auto-read-only":true,"discard":"unmap"}' \ -blockdev '{"node-name":"libvirt-pflash0-format","read-only":true,"driver":"raw","file":"libvirt-pflash0-storage"}' \ -blockdev '{"driver":"file","filename":"/etc/libvirt/qemu/nvram/eb86ceb7-fe1e-143b-e4e7-3d54d80ac0a2_VARS-pure-efi-tpm.fd","node-name":"libvirt-pflash1-storage","auto-read-only":true,"discard":"unmap"}' \ -blockdev '{"node-name":"libvirt-pflash1-format","read-only":false,"driver":"raw","file":"libvirt-pflash1-storage"}' \ -machine pc-i440fx-7.1,usb=off,dump-guest-core=off,mem-merge=off,memory-backend=pc.ram,pflash0=libvirt-pflash0-format,pflash1=libvirt-pflash1-format \ -accel kvm \ -cpu host,migratable=on,hv-time=on,hv-relaxed=on,hv-vapic=on,hv-spinlocks=0x1fff,hv-vendor-id=none,host-cache-info=on,l3-cache=off \ -m 16384 \ -object '{"qom-type":"memory-backend-memfd","id":"pc.ram","share":true,"x-use-canonical-path-for-ramblock-id":false,"size":17179869184}' \ -overcommit mem-lock=off \ -smp 12,sockets=1,dies=1,cores=6,threads=2 \ -uuid eb86ceb7-fe1e-143b-e4e7-3d54d80ac0a2 \ -display none \ -no-user-config \ -nodefaults \ -chardev socket,id=charmonitor,fd=34,server=on,wait=off \ -mon chardev=charmonitor,id=monitor,mode=control \ -rtc base=localtime \ -no-hpet \ -no-shutdown \ -boot strict=on \ -device '{"driver":"ich9-usb-ehci1","id":"usb","bus":"pci.0","addr":"0x7.0x7"}' \ -device '{"driver":"ich9-usb-uhci1","masterbus":"usb.0","firstport":0,"bus":"pci.0","multifunction":true,"addr":"0x7"}' \ -device '{"driver":"ich9-usb-uhci2","masterbus":"usb.0","firstport":2,"bus":"pci.0","addr":"0x7.0x1"}' \ -device '{"driver":"ich9-usb-uhci3","masterbus":"usb.0","firstport":4,"bus":"pci.0","addr":"0x7.0x2"}' \ -device '{"driver":"virtio-serial-pci","id":"virtio-serial0","bus":"pci.0","addr":"0x4"}' \ -blockdev '{"driver":"file","filename":"/mnt/user/domains/Windows 11 - Gaming/vdisk1.img","node-name":"libvirt-4-storage","cache":{"direct":false,"no-flush":false},"auto-read-only":true,"discard":"unmap"}' \ -blockdev '{"node-name":"libvirt-4-format","read-only":false,"cache":{"direct":false,"no-flush":false},"driver":"raw","file":"libvirt-4-storage"}' \ -device '{"driver":"virtio-blk-pci","bus":"pci.0","addr":"0x5","drive":"libvirt-4-format","id":"virtio-disk2","bootindex":1,"write-cache":"on","serial":"vdisk1"}' \ -blockdev '{"driver":"host_device","filename":"/dev/disk/by-id/ata-Samsung_SSD_840_Series_S14CNEBD106747W","node-name":"libvirt-3-storage","cache":{"direct":false,"no-flush":false},"auto-read-only":true,"discard":"unmap"}' \ -blockdev '{"node-name":"libvirt-3-format","read-only":false,"cache":{"direct":false,"no-flush":false},"driver":"raw","file":"libvirt-3-storage"}' \ -device '{"driver":"virtio-blk-pci","bus":"pci.0","addr":"0x6","drive":"libvirt-3-format","id":"virtio-disk3","write-cache":"on","serial":"vdisk2"}' \ -blockdev '{"driver":"file","filename":"/mnt/user/isos/Win11_EnglishInternational_x64v1.iso","node-name":"libvirt-2-storage","auto-read-only":true,"discard":"unmap"}' \ -blockdev '{"node-name":"libvirt-2-format","read-only":true,"driver":"raw","file":"libvirt-2-storage"}' \ -device '{"driver":"ide-cd","bus":"ide.0","unit":0,"drive":"libvirt-2-format","id":"ide0-0-0","bootindex":2}' \ -blockdev '{"driver":"file","filename":"/mnt/user/isos/virtio-win-0.1.229-1.iso","node-name":"libvirt-1-storage","auto-read-only":true,"discard":"unmap"}' \ -blockdev '{"node-name":"libvirt-1-format","read-only":true,"driver":"raw","file":"libvirt-1-storage"}' \ -device '{"driver":"ide-cd","bus":"ide.0","unit":1,"drive":"libvirt-1-format","id":"ide0-0-1"}' \ -chardev 'socket,id=chr-vu-fs0,path=/var/lib/libvirt/qemu/domain-1-Windows 11/fs0-fs.sock' \ -device '{"driver":"vhost-user-fs-pci","id":"fs0","chardev":"chr-vu-fs0","queue-size":1024,"tag":"craigmdennis","bus":"pci.0","addr":"0x2"}' \ -netdev tap,fd=35,id=hostnet0 \ -device '{"driver":"virtio-net","netdev":"hostnet0","id":"net0","mac":"52:54:00:39:84:e6","bus":"pci.0","addr":"0x3"}' \ -chardev pty,id=charserial0 \ -device '{"driver":"isa-serial","chardev":"charserial0","id":"serial0","index":0}' \ -chardev socket,id=charchannel0,fd=33,server=on,wait=off \ -device '{"driver":"virtserialport","bus":"virtio-serial0.0","nr":1,"chardev":"charchannel0","id":"channel0","name":"org.qemu.guest_agent.0"}' \ -chardev 'socket,id=chrtpm,path=/run/libvirt/qemu/swtpm/1-Windows 11-swtpm.sock' \ -tpmdev emulator,id=tpm-tpm0,chardev=chrtpm \ -device '{"driver":"tpm-tis","tpmdev":"tpm-tpm0","id":"tpm0"}' \ -device '{"driver":"usb-tablet","id":"input0","bus":"usb.0","port":"1"}' \ -audiodev '{"id":"audio1","driver":"none"}' \ -device '{"driver":"vfio-pci","host":"0000:01:00.0","id":"hostdev0","bus":"pci.0","addr":"0x8"}' \ -device '{"driver":"vfio-pci","host":"0000:01:00.1","id":"hostdev1","bus":"pci.0","addr":"0x9"}' \ -sandbox on,obsolete=deny,elevateprivileges=deny,spawn=deny,resourcecontrol=deny \ -msg timestamp=on char device redirected to /dev/pts/0 (label charserial0)
-
I have this MB. Haven't tested the 2.5GbE speeds yet but one issue I have is that I can't get any fan speeds in the System Temp settings.
-
I set my unraid server to sleep every night because I want to save power/money. When the server wakes, there are no issues with docker containers but the Windows 11 VM (I only have one) is inaccessible (by Microsoft Remote Desktop or VNC) and has some (sometimes all) pinned cores set to 100%. I have to force stop and restart the VM every time (restarting does nothing). I have all power saving features disabled in the Windows VM so it won't sleep on its own/turn off the display etc. Can someone point me in the right direction for resolving this? Thanks! --- VM Configuration I have a 11700K and a GTX 1650 passed through. <?xml version='1.0' encoding='UTF-8'?> <domain type='kvm' id='2'> <name>Windows 11</name> <uuid>eb86ceb7-fe1e-143b-e4e7-3d54d80ac0a2</uuid> <metadata> <vmtemplate xmlns="unraid" name="Windows 11" icon="windows11.png" os="windowstpm"/> </metadata> <memory unit='KiB'>8388608</memory> <currentMemory unit='KiB'>8388608</currentMemory> <memoryBacking> <nosharepages/> <source type='memfd'/> <access mode='shared'/> </memoryBacking> <vcpu placement='static'>8</vcpu> <cputune> <vcpupin vcpu='0' cpuset='4'/> <vcpupin vcpu='1' cpuset='12'/> <vcpupin vcpu='2' cpuset='5'/> <vcpupin vcpu='3' cpuset='13'/> <vcpupin vcpu='4' cpuset='6'/> <vcpupin vcpu='5' cpuset='14'/> <vcpupin vcpu='6' cpuset='7'/> <vcpupin vcpu='7' cpuset='15'/> </cputune> <resource> <partition>/machine</partition> </resource> <os> <type arch='x86_64' machine='pc-i440fx-7.1'>hvm</type> <loader readonly='yes' type='pflash'>/usr/share/qemu/ovmf-x64/OVMF_CODE-pure-efi-tpm.fd</loader> <nvram>/etc/libvirt/qemu/nvram/eb86ceb7-fe1e-143b-e4e7-3d54d80ac0a2_VARS-pure-efi-tpm.fd</nvram> </os> <features> <acpi/> <apic/> <hyperv mode='custom'> <relaxed state='on'/> <vapic state='on'/> <spinlocks state='on' retries='8191'/> <vendor_id state='on' value='none'/> </hyperv> </features> <cpu mode='host-passthrough' check='none' migratable='on'> <topology sockets='1' dies='1' cores='4' threads='2'/> <cache mode='passthrough'/> </cpu> <clock offset='localtime'> <timer name='hypervclock' present='yes'/> <timer name='hpet' present='no'/> </clock> <on_poweroff>destroy</on_poweroff> <on_reboot>restart</on_reboot> <on_crash>restart</on_crash> <devices> <emulator>/usr/local/sbin/qemu</emulator> <disk type='file' device='disk'> <driver name='qemu' type='raw' cache='writeback'/> <source file='/mnt/user/domains/Windows 11 - Gaming/vdisk1.img' index='4'/> <backingStore/> <target dev='hdc' bus='virtio'/> <serial>vdisk1</serial> <boot order='1'/> <alias name='virtio-disk2'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x05' function='0x0'/> </disk> <disk type='block' device='disk'> <driver name='qemu' type='raw' cache='writeback'/> <source dev='/dev/disk/by-id/ata-Samsung_SSD_840_Series_S14CNEBD106747W' index='3'/> <backingStore/> <target dev='hdd' bus='virtio'/> <serial>vdisk2</serial> <alias name='virtio-disk3'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x06' function='0x0'/> </disk> <disk type='file' device='cdrom'> <driver name='qemu' type='raw'/> <source file='/mnt/user/isos/Win11_EnglishInternational_x64v1.iso' index='2'/> <backingStore/> <target dev='hda' bus='ide'/> <readonly/> <boot order='2'/> <alias name='ide0-0-0'/> <address type='drive' controller='0' bus='0' target='0' unit='0'/> </disk> <disk type='file' device='cdrom'> <driver name='qemu' type='raw'/> <source file='/mnt/user/isos/virtio-win-0.1.229-1.iso' index='1'/> <backingStore/> <target dev='hdb' bus='ide'/> <readonly/> <alias name='ide0-0-1'/> <address type='drive' controller='0' bus='0' target='0' unit='1'/> </disk> <controller type='pci' index='0' model='pci-root'> <alias name='pci.0'/> </controller> <controller type='ide' index='0'> <alias name='ide'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x1'/> </controller> <controller type='virtio-serial' index='0'> <alias name='virtio-serial0'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x04' function='0x0'/> </controller> <controller type='usb' index='0' model='ich9-ehci1'> <alias name='usb'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x7'/> </controller> <controller type='usb' index='0' model='ich9-uhci1'> <alias name='usb'/> <master startport='0'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x0' multifunction='on'/> </controller> <controller type='usb' index='0' model='ich9-uhci2'> <alias name='usb'/> <master startport='2'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x1'/> </controller> <controller type='usb' index='0' model='ich9-uhci3'> <alias name='usb'/> <master startport='4'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x2'/> </controller> <filesystem type='mount' accessmode='passthrough'> <driver type='virtiofs' queue='1024'/> <binary path='/usr/libexec/virtiofsd' xattr='on'> <cache mode='always'/> <sandbox mode='chroot'/> </binary> <source dir='/mnt/user/craigmdennis'/> <target dir='craigmdennis'/> <alias name='fs0'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x02' function='0x0'/> </filesystem> <interface type='bridge'> <mac address='52:54:00:39:84:e6'/> <source bridge='br0'/> <target dev='vnet1'/> <model type='virtio-net'/> <alias name='net0'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x03' function='0x0'/> </interface> <serial type='pty'> <source path='/dev/pts/0'/> <target type='isa-serial' port='0'> <model name='isa-serial'/> </target> <alias name='serial0'/> </serial> <console type='pty' tty='/dev/pts/0'> <source path='/dev/pts/0'/> <target type='serial' port='0'/> <alias name='serial0'/> </console> <channel type='unix'> <source mode='bind' path='/var/lib/libvirt/qemu/channel/target/domain-2-Windows 11/org.qemu.guest_agent.0'/> <target type='virtio' name='org.qemu.guest_agent.0' state='disconnected'/> <alias name='channel0'/> <address type='virtio-serial' controller='0' bus='0' port='1'/> </channel> <input type='tablet' bus='usb'> <alias name='input0'/> <address type='usb' bus='0' port='1'/> </input> <input type='mouse' bus='ps2'> <alias name='input1'/> </input> <input type='keyboard' bus='ps2'> <alias name='input2'/> </input> <tpm model='tpm-tis'> <backend type='emulator' version='2.0' persistent_state='yes'/> <alias name='tpm0'/> </tpm> <audio id='1' type='none'/> <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x01' slot='0x00' function='0x0'/> </source> <alias name='hostdev0'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x08' function='0x0'/> </hostdev> <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x01' slot='0x00' function='0x1'/> </source> <alias name='hostdev1'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x09' function='0x0'/> </hostdev> <memballoon model='none'/> </devices> <seclabel type='dynamic' model='dac' relabel='yes'> <label>+0:+100</label> <imagelabel>+0:+100</imagelabel> </seclabel> </domain> System log May 2 09:43:37 Sakaar kernel: Linux version 6.1.27-Unraid (root@Develop) (gcc (GCC) 12.2.0, GNU ld version 2.40-slack151) #1 SMP PREEMPT_DYNAMIC Mon May 1 10:47:29 PDT 2023 May 2 09:43:37 Sakaar kernel: Command line: BOOT_IMAGE=/bzimage initrd=/bzroot May 2 09:43:37 Sakaar kernel: x86/fpu: Supporting XSAVE feature 0x001: 'x87 floating point registers' May 2 09:43:37 Sakaar kernel: x86/fpu: Supporting XSAVE feature 0x002: 'SSE registers' May 2 09:43:37 Sakaar kernel: x86/fpu: Supporting XSAVE feature 0x004: 'AVX registers' May 2 09:43:37 Sakaar kernel: x86/fpu: Supporting XSAVE feature 0x008: 'MPX bounds registers' May 2 09:43:37 Sakaar kernel: x86/fpu: Supporting XSAVE feature 0x010: 'MPX CSR' May 2 09:43:37 Sakaar kernel: x86/fpu: Supporting XSAVE feature 0x020: 'AVX-512 opmask' May 2 09:43:37 Sakaar kernel: x86/fpu: Supporting XSAVE feature 0x040: 'AVX-512 Hi256' May 2 09:43:37 Sakaar kernel: x86/fpu: Supporting XSAVE feature 0x080: 'AVX-512 ZMM_Hi256' May 2 09:43:37 Sakaar kernel: x86/fpu: Supporting XSAVE feature 0x200: 'Protection Keys User registers' May 2 09:43:37 Sakaar kernel: x86/fpu: xstate_offset[2]: 576, xstate_sizes[2]: 256 May 2 09:43:37 Sakaar kernel: x86/fpu: xstate_offset[3]: 832, xstate_sizes[3]: 64 May 2 09:43:37 Sakaar kernel: x86/fpu: xstate_offset[4]: 896, xstate_sizes[4]: 64 May 2 09:43:37 Sakaar kernel: x86/fpu: xstate_offset[5]: 960, xstate_sizes[5]: 64 May 2 09:43:37 Sakaar kernel: x86/fpu: xstate_offset[6]: 1024, xstate_sizes[6]: 512 May 2 09:43:37 Sakaar kernel: x86/fpu: xstate_offset[7]: 1536, xstate_sizes[7]: 1024 May 2 09:43:37 Sakaar kernel: x86/fpu: xstate_offset[9]: 2560, xstate_sizes[9]: 8 May 2 09:43:37 Sakaar kernel: x86/fpu: Enabled xstate features 0x2ff, context size is 2568 bytes, using 'compacted' format. May 2 09:43:37 Sakaar kernel: signal: max sigframe size: 3632 May 2 09:43:37 Sakaar kernel: BIOS-provided physical RAM map: May 2 09:43:37 Sakaar kernel: BIOS-e820: [mem 0x0000000000000000-0x000000000005dfff] usable May 2 09:43:37 Sakaar kernel: BIOS-e820: [mem 0x000000000005e000-0x000000000005efff] reserved May 2 09:43:37 Sakaar kernel: BIOS-e820: [mem 0x000000000005f000-0x000000000009ffff] usable May 2 09:43:37 Sakaar kernel: BIOS-e820: [mem 0x00000000000a0000-0x00000000000fffff] reserved May 2 09:43:37 Sakaar kernel: BIOS-e820: [mem 0x0000000000100000-0x00000000329b8fff] usable May 2 09:43:37 Sakaar kernel: BIOS-e820: [mem 0x00000000329b9000-0x0000000034eb8fff] reserved May 2 09:43:37 Sakaar kernel: BIOS-e820: [mem 0x0000000034eb9000-0x0000000035138fff] ACPI data May 2 09:43:37 Sakaar kernel: BIOS-e820: [mem 0x0000000035139000-0x0000000035606fff] ACPI NVS May 2 09:43:37 Sakaar kernel: BIOS-e820: [mem 0x0000000035607000-0x0000000035ffefff] reserved May 2 09:43:37 Sakaar kernel: BIOS-e820: [mem 0x0000000035fff000-0x0000000035ffffff] usable May 2 09:43:37 Sakaar kernel: BIOS-e820: [mem 0x0000000036000000-0x000000003f7fffff] reserved May 2 09:43:37 Sakaar kernel: BIOS-e820: [mem 0x00000000e0000000-0x00000000efffffff] reserved May 2 09:43:37 Sakaar kernel: BIOS-e820: [mem 0x00000000fc000000-0x00000000fc00ffff] reserved May 2 09:43:37 Sakaar kernel: BIOS-e820: [mem 0x00000000fe000000-0x00000000fe010fff] reserved May 2 09:43:37 Sakaar kernel: BIOS-e820: [mem 0x00000000fec00000-0x00000000fec00fff] reserved May 2 09:43:37 Sakaar kernel: BIOS-e820: [mem 0x00000000fed00000-0x00000000fed00fff] reserved May 2 09:43:37 Sakaar kernel: BIOS-e820: [mem 0x00000000fed20000-0x00000000fed7ffff] reserved May 2 09:43:37 Sakaar kernel: BIOS-e820: [mem 0x00000000fee00000-0x00000000fee00fff] reserved May 2 09:43:37 Sakaar kernel: BIOS-e820: [mem 0x00000000ff000000-0x00000000ffffffff] reserved May 2 09:43:37 Sakaar kernel: BIOS-e820: [mem 0x0000000100000000-0x00000008c07fffff] usable May 2 09:43:37 Sakaar kernel: NX (Execute Disable) protection: active May 2 09:43:37 Sakaar kernel: e820: update [mem 0x2b201018-0x2b220a57] usable ==> usable ### [PREVIOUS LINE REPEATED 1 TIMES] ### May 2 09:43:37 Sakaar kernel: e820: update [mem 0x25d64018-0x25db0a57] usable ==> usable ### [PREVIOUS LINE REPEATED 1 TIMES] ### May 2 09:43:37 Sakaar kernel: e820: update [mem 0x2b37e018-0x2b38d057] usable ==> usable ### [PREVIOUS LINE REPEATED 1 TIMES] ### May 2 09:43:37 Sakaar kernel: extended physical RAM map: May 2 09:43:37 Sakaar kernel: reserve setup_data: [mem 0x0000000000000000-0x000000000005dfff] usable May 2 09:43:37 Sakaar kernel: reserve setup_data: [mem 0x000000000005e000-0x000000000005efff] reserved May 2 09:43:37 Sakaar kernel: reserve setup_data: [mem 0x000000000005f000-0x000000000009ffff] usable May 2 09:43:37 Sakaar kernel: reserve setup_data: [mem 0x00000000000a0000-0x00000000000fffff] reserved May 2 09:43:37 Sakaar kernel: reserve setup_data: [mem 0x0000000000100000-0x0000000025d64017] usable May 2 09:43:37 Sakaar kernel: reserve setup_data: [mem 0x0000000025d64018-0x0000000025db0a57] usable May 2 09:43:37 Sakaar kernel: reserve setup_data: [mem 0x0000000025db0a58-0x000000002b201017] usable May 2 09:43:37 Sakaar kernel: reserve setup_data: [mem 0x000000002b201018-0x000000002b220a57] usable May 2 09:43:37 Sakaar kernel: reserve setup_data: [mem 0x000000002b220a58-0x000000002b37e017] usable May 2 09:43:37 Sakaar kernel: reserve setup_data: [mem 0x000000002b37e018-0x000000002b38d057] usable May 2 09:43:37 Sakaar kernel: reserve setup_data: [mem 0x000000002b38d058-0x00000000329b8fff] usable May 2 09:43:37 Sakaar kernel: reserve setup_data: [mem 0x00000000329b9000-0x0000000034eb8fff] reserved May 2 09:43:37 Sakaar kernel: reserve setup_data: [mem 0x0000000034eb9000-0x0000000035138fff] ACPI data May 2 09:43:37 Sakaar kernel: reserve setup_data: [mem 0x0000000035139000-0x0000000035606fff] ACPI NVS May 2 09:43:37 Sakaar kernel: reserve setup_data: [mem 0x0000000035607000-0x0000000035ffefff] reserved May 2 09:43:37 Sakaar kernel: reserve setup_data: [mem 0x0000000035fff000-0x0000000035ffffff] usable May 2 09:43:37 Sakaar kernel: reserve setup_data: [mem 0x0000000036000000-0x000000003f7fffff] reserved May 2 09:43:37 Sakaar kernel: reserve setup_data: [mem 0x00000000e0000000-0x00000000efffffff] reserved May 2 09:43:37 Sakaar kernel: reserve setup_data: [mem 0x00000000fc000000-0x00000000fc00ffff] reserved May 2 09:43:37 Sakaar kernel: reserve setup_data: [mem 0x00000000fe000000-0x00000000fe010fff] reserved May 2 09:43:37 Sakaar kernel: reserve setup_data: [mem 0x00000000fec00000-0x00000000fec00fff] reserved May 2 09:43:37 Sakaar kernel: reserve setup_data: [mem 0x00000000fed00000-0x00000000fed00fff] reserved May 2 09:43:37 Sakaar kernel: reserve setup_data: [mem 0x00000000fed20000-0x00000000fed7ffff] reserved May 2 09:43:37 Sakaar kernel: reserve setup_data: [mem 0x00000000fee00000-0x00000000fee00fff] reserved May 2 09:43:37 Sakaar kernel: reserve setup_data: [mem 0x00000000ff000000-0x00000000ffffffff] reserved May 2 09:43:37 Sakaar kernel: reserve setup_data: [mem 0x0000000100000000-0x00000008c07fffff] usable May 2 09:43:37 Sakaar kernel: efi: EFI v2.70 by American Megatrends May 2 09:43:37 Sakaar kernel: efi: ACPI=0x35584000 ACPI 2.0=0x35584014 TPMFinalLog=0x35552000 SMBIOS=0x35d0f000 SMBIOS 3.0=0x35d0e000 MEMATTR=0x2b622418 ESRT=0x306c8b98 RNG=0x3501c018 TPMEventLog=0x2b38e018 May 2 09:43:37 Sakaar kernel: SMBIOS 3.3.0 present. May 2 09:43:37 Sakaar kernel: DMI: Gigabyte Technology Co., Ltd. B560M AORUS PRO AX/B560M AORUS PRO AX, BIOS F11 03/10/2023 May 2 09:43:37 Sakaar kernel: tsc: Detected 3600.000 MHz processor May 2 09:43:37 Sakaar kernel: e820: update [mem 0x00000000-0x00000fff] usable ==> reserved May 2 09:43:37 Sakaar kernel: e820: remove [mem 0x000a0000-0x000fffff] usable May 2 09:43:37 Sakaar kernel: last_pfn = 0x8c0800 max_arch_pfn = 0x400000000 May 2 09:43:37 Sakaar kernel: x86/PAT: Configuration [0-7]: WB WC UC- UC WB WP UC- WT May 2 09:43:37 Sakaar kernel: last_pfn = 0x36000 max_arch_pfn = 0x400000000 May 2 09:43:37 Sakaar kernel: found SMP MP-table at [mem 0x000fcea0-0x000fceaf] May 2 09:43:37 Sakaar kernel: esrt: Reserving ESRT space from 0x00000000306c8b98 to 0x00000000306c8c48. May 2 09:43:37 Sakaar kernel: e820: update [mem 0x306c8000-0x306c8fff] usable ==> reserved May 2 09:43:37 Sakaar kernel: Using GB pages for direct mapping May 2 09:43:37 Sakaar kernel: Secure boot disabled May 2 09:43:37 Sakaar kernel: RAMDISK: [mem 0x25db1000-0x274adfff] May 2 09:43:37 Sakaar kernel: ACPI: Early table checksum verification disabled May 2 09:43:37 Sakaar kernel: ACPI: RSDP 0x0000000035584014 000024 (v02 ALASKA) May 2 09:43:37 Sakaar kernel: ACPI: XSDT 0x0000000035583728 00010C (v01 ALASKA A M I 01072009 AMI 01000013) May 2 09:43:37 Sakaar kernel: ACPI: FACP 0x0000000035135000 000114 (v06 ALASKA A M I 01072009 AMI 01000013) May 2 09:43:37 Sakaar kernel: ACPI: DSDT 0x00000000350E0000 054E59 (v02 ALASKA A M I 01072009 INTL 20180209) May 2 09:43:37 Sakaar kernel: ACPI: FACS 0x0000000035606000 000040 May 2 09:43:37 Sakaar kernel: ACPI: MCFG 0x0000000035136000 00003C (v01 ALASKA A M I 01072009 MSFT 00000097) May 2 09:43:37 Sakaar kernel: ACPI: FIDT 0x00000000350DF000 00009C (v01 ALASKA A M I 01072009 AMI 00010013) May 2 09:43:37 Sakaar kernel: ACPI: SSDT 0x00000000350D5000 009858 (v02 GBT GSWApp 00000001 INTL 20180209) May 2 09:43:37 Sakaar kernel: ACPI: SSDT 0x00000000350D2000 002604 (v02 CpuRef CpuSsdt 00003000 INTL 20180209) May 2 09:43:37 Sakaar kernel: ACPI: SSDT 0x0000000035138000 000341 (v02 PmRef ItbmSci 00003000 INTL 20180209) May 2 09:43:37 Sakaar kernel: ACPI: SSDT 0x00000000350CD000 00441C (v02 SaSsdt SaSsdt 00003000 INTL 20180209) May 2 09:43:37 Sakaar kernel: ACPI: SSDT 0x00000000350C9000 0032CD (v02 INTEL IgfxSsdt 00003000 INTL 20180209) May 2 09:43:37 Sakaar kernel: ACPI: HPET 0x0000000035137000 000038 (v01 ALASKA A M I 01072009 AMI 01000013) May 2 09:43:37 Sakaar kernel: ACPI: APIC 0x00000000350C8000 000164 (v04 ALASKA A M I 01072009 AMI 01000013) May 2 09:43:37 Sakaar kernel: ACPI: SSDT 0x00000000350C1000 0065AE (v02 ALASKA A M I 00001000 INTL 20180209) May 2 09:43:37 Sakaar kernel: ACPI: SSDT 0x00000000350C0000 000E66 (v02 ALASKA A M I 00001000 INTL 20180209) May 2 09:43:37 Sakaar kernel: ACPI: SSDT 0x00000000350BE000 001078 (v02 INTEL xh_rksu4 00000000 INTL 20180209) May 2 09:43:37 Sakaar kernel: ACPI: NHLT 0x00000000350BC000 0017F1 (v00 ALASKA A M I 01072009 AMI 01000013) May 2 09:43:37 Sakaar kernel: ACPI: SSDT 0x00000000350B9000 002266 (v02 INTEL DTbtSsdt 00001000 INTL 20180209) May 2 09:43:37 Sakaar kernel: ACPI: LPIT 0x00000000350B8000 0000CC (v01 ALASKA A M I 01072009 AMI 01000013) May 2 09:43:37 Sakaar kernel: ACPI: SSDT 0x00000000350B4000 002720 (v02 ALASKA A M I 00001000 INTL 20180209) May 2 09:43:37 Sakaar kernel: ACPI: SSDT 0x00000000350B3000 000B52 (v02 ALASKA A M I 00000000 INTL 20180209) May 2 09:43:37 Sakaar kernel: ACPI: DBGP 0x00000000350B2000 000034 (v01 ALASKA A M I 01072009 AMI 01000013) May 2 09:43:37 Sakaar kernel: ACPI: DBG2 0x00000000350B1000 000054 (v00 ALASKA A M I 01072009 AMI 01000013) May 2 09:43:37 Sakaar kernel: ACPI: SSDT 0x00000000350AF000 0015B7 (v02 ALASKA A M I 00001000 INTL 20180209) May 2 09:43:37 Sakaar kernel: ACPI: DMAR 0x00000000350AE000 000088 (v02 INTEL EDK2 00000002 01000013) May 2 09:43:37 Sakaar kernel: ACPI: SSDT 0x00000000350AD000 000144 (v02 Intel ADebTabl 00001000 INTL 20180209) May 2 09:43:37 Sakaar kernel: ACPI: BGRT 0x00000000350AC000 000038 (v01 ALASKA A M I 01072009 AMI 00010013) May 2 09:43:37 Sakaar kernel: ACPI: TPM2 0x00000000350AB000 00004C (v04 ALASKA A M I 00000001 AMI 00000000) May 2 09:43:37 Sakaar kernel: ACPI: WPBT 0x000000003501F000 000038 (v01 ALASKA A M I 00000001 GBT 20181220) May 2 09:43:37 Sakaar kernel: ACPI: PTDT 0x000000003501E000 000CF0 (v00 ALASKA A M I 00000005 MSFT 0100000D) May 2 09:43:37 Sakaar kernel: ACPI: WSMT 0x00000000350B7000 000028 (v01 ALASKA A M I 01072009 AMI 00010013) May 2 09:43:37 Sakaar kernel: ACPI: FPDT 0x000000003501D000 000044 (v01 ALASKA A M I 01072009 AMI 01000013) May 2 09:43:37 Sakaar kernel: ACPI: Reserving FACP table memory at [mem 0x35135000-0x35135113] May 2 09:43:37 Sakaar kernel: ACPI: Reserving DSDT table memory at [mem 0x350e0000-0x35134e58] May 2 09:43:37 Sakaar kernel: ACPI: Reserving FACS table memory at [mem 0x35606000-0x3560603f] May 2 09:43:37 Sakaar kernel: ACPI: Reserving MCFG table memory at [mem 0x35136000-0x3513603b] May 2 09:43:37 Sakaar kernel: ACPI: Reserving FIDT table memory at [mem 0x350df000-0x350df09b] May 2 09:43:37 Sakaar kernel: ACPI: Reserving SSDT table memory at [mem 0x350d5000-0x350de857] May 2 09:43:37 Sakaar kernel: ACPI: Reserving SSDT table memory at [mem 0x350d2000-0x350d4603] May 2 09:43:37 Sakaar kernel: ACPI: Reserving SSDT table memory at [mem 0x35138000-0x35138340] May 2 09:43:37 Sakaar kernel: ACPI: Reserving SSDT table memory at [mem 0x350cd000-0x350d141b] May 2 09:43:37 Sakaar kernel: ACPI: Reserving SSDT table memory at [mem 0x350c9000-0x350cc2cc] May 2 09:43:37 Sakaar kernel: ACPI: Reserving HPET table memory at [mem 0x35137000-0x35137037] May 2 09:43:37 Sakaar kernel: ACPI: Reserving APIC table memory at [mem 0x350c8000-0x350c8163] May 2 09:43:37 Sakaar kernel: ACPI: Reserving SSDT table memory at [mem 0x350c1000-0x350c75ad] May 2 09:43:37 Sakaar kernel: ACPI: Reserving SSDT table memory at [mem 0x350c0000-0x350c0e65] May 2 09:43:37 Sakaar kernel: ACPI: Reserving SSDT table memory at [mem 0x350be000-0x350bf077] May 2 09:43:37 Sakaar kernel: ACPI: Reserving NHLT table memory at [mem 0x350bc000-0x350bd7f0] May 2 09:43:37 Sakaar kernel: ACPI: Reserving SSDT table memory at [mem 0x350b9000-0x350bb265] May 2 09:43:37 Sakaar kernel: ACPI: Reserving LPIT table memory at [mem 0x350b8000-0x350b80cb] May 2 09:43:37 Sakaar kernel: ACPI: Reserving SSDT table memory at [mem 0x350b4000-0x350b671f] May 2 09:43:37 Sakaar kernel: ACPI: Reserving SSDT table memory at [mem 0x350b3000-0x350b3b51] May 2 09:43:37 Sakaar kernel: ACPI: Reserving DBGP table memory at [mem 0x350b2000-0x350b2033] May 2 09:43:37 Sakaar kernel: ACPI: Reserving DBG2 table memory at [mem 0x350b1000-0x350b1053] May 2 09:43:37 Sakaar kernel: ACPI: Reserving SSDT table memory at [mem 0x350af000-0x350b05b6] May 2 09:43:37 Sakaar kernel: ACPI: Reserving DMAR table memory at [mem 0x350ae000-0x350ae087] May 2 09:43:37 Sakaar kernel: ACPI: Reserving SSDT table memory at [mem 0x350ad000-0x350ad143] May 2 09:43:37 Sakaar kernel: ACPI: Reserving BGRT table memory at [mem 0x350ac000-0x350ac037] May 2 09:43:37 Sakaar kernel: ACPI: Reserving TPM2 table memory at [mem 0x350ab000-0x350ab04b] May 2 09:43:37 Sakaar kernel: ACPI: Reserving WPBT table memory at [mem 0x3501f000-0x3501f037] May 2 09:43:37 Sakaar kernel: ACPI: Reserving PTDT table memory at [mem 0x3501e000-0x3501ecef] May 2 09:43:37 Sakaar kernel: ACPI: Reserving WSMT table memory at [mem 0x350b7000-0x350b7027] May 2 09:43:37 Sakaar kernel: ACPI: Reserving FPDT table memory at [mem 0x3501d000-0x3501d043] May 2 09:43:37 Sakaar kernel: No NUMA configuration found May 2 09:43:37 Sakaar kernel: Faking a node at [mem 0x0000000000000000-0x00000008c07fffff] May 2 09:43:37 Sakaar kernel: NODE_DATA(0) allocated [mem 0x8c07f9000-0x8c07fefff] May 2 09:43:37 Sakaar kernel: Zone ranges: May 2 09:43:37 Sakaar kernel: DMA [mem 0x0000000000001000-0x0000000000ffffff] May 2 09:43:37 Sakaar kernel: DMA32 [mem 0x0000000001000000-0x00000000ffffffff] May 2 09:43:37 Sakaar kernel: Normal [mem 0x0000000100000000-0x00000008c07fffff] May 2 09:43:37 Sakaar kernel: Device empty May 2 09:43:37 Sakaar kernel: Movable zone start for each node May 2 09:43:37 Sakaar kernel: Early memory node ranges May 2 09:43:37 Sakaar kernel: node 0: [mem 0x0000000000001000-0x000000000005dfff] May 2 09:43:37 Sakaar kernel: node 0: [mem 0x000000000005f000-0x000000000009ffff] May 2 09:43:37 Sakaar kernel: node 0: [mem 0x0000000000100000-0x00000000329b8fff] May 2 09:43:37 Sakaar kernel: node 0: [mem 0x0000000035fff000-0x0000000035ffffff] May 2 09:43:37 Sakaar kernel: node 0: [mem 0x0000000100000000-0x00000008c07fffff] May 2 09:43:37 Sakaar kernel: Initmem setup node 0 [mem 0x0000000000001000-0x00000008c07fffff] May 2 09:43:37 Sakaar kernel: On node 0, zone DMA: 1 pages in unavailable ranges ### [PREVIOUS LINE REPEATED 1 TIMES] ### May 2 09:43:37 Sakaar kernel: On node 0, zone DMA: 96 pages in unavailable ranges May 2 09:43:37 Sakaar kernel: On node 0, zone DMA32: 13894 pages in unavailable ranges May 2 09:43:37 Sakaar kernel: On node 0, zone Normal: 8192 pages in unavailable ranges May 2 09:43:37 Sakaar kernel: On node 0, zone Normal: 30720 pages in unavailable ranges May 2 09:43:37 Sakaar kernel: Reserving Intel graphics memory at [mem 0x3b800000-0x3f7fffff] May 2 09:43:37 Sakaar kernel: ACPI: PM-Timer IO Port: 0x1808 May 2 09:43:37 Sakaar kernel: ACPI: LAPIC_NMI (acpi_id[0x01] high edge lint[0x1]) May 2 09:43:37 Sakaar kernel: ACPI: LAPIC_NMI (acpi_id[0x02] high edge lint[0x1]) May 2 09:43:37 Sakaar kernel: ACPI: LAPIC_NMI (acpi_id[0x03] high edge lint[0x1]) May 2 09:43:37 Sakaar kernel: ACPI: LAPIC_NMI (acpi_id[0x04] high edge lint[0x1]) May 2 09:43:37 Sakaar kernel: ACPI: LAPIC_NMI (acpi_id[0x05] high edge lint[0x1]) May 2 09:43:37 Sakaar kernel: ACPI: LAPIC_NMI (acpi_id[0x06] high edge lint[0x1]) May 2 09:43:37 Sakaar kernel: ACPI: LAPIC_NMI (acpi_id[0x07] high edge lint[0x1]) May 2 09:43:37 Sakaar kernel: ACPI: LAPIC_NMI (acpi_id[0x08] high edge lint[0x1]) May 2 09:43:37 Sakaar kernel: ACPI: LAPIC_NMI (acpi_id[0x09] high edge lint[0x1]) May 2 09:43:37 Sakaar kernel: ACPI: LAPIC_NMI (acpi_id[0x0a] high edge lint[0x1]) May 2 09:43:37 Sakaar kernel: ACPI: LAPIC_NMI (acpi_id[0x0b] high edge lint[0x1]) May 2 09:43:37 Sakaar kernel: ACPI: LAPIC_NMI (acpi_id[0x0c] high edge lint[0x1]) May 2 09:43:37 Sakaar kernel: ACPI: LAPIC_NMI (acpi_id[0x0d] high edge lint[0x1]) May 2 09:43:37 Sakaar kernel: ACPI: LAPIC_NMI (acpi_id[0x0e] high edge lint[0x1]) May 2 09:43:37 Sakaar kernel: ACPI: LAPIC_NMI (acpi_id[0x0f] high edge lint[0x1]) May 2 09:43:37 Sakaar kernel: ACPI: LAPIC_NMI (acpi_id[0x10] high edge lint[0x1]) May 2 09:43:37 Sakaar kernel: ACPI: LAPIC_NMI (acpi_id[0x11] high edge lint[0x1]) May 2 09:43:37 Sakaar kernel: ACPI: LAPIC_NMI (acpi_id[0x12] high edge lint[0x1]) May 2 09:43:37 Sakaar kernel: ACPI: LAPIC_NMI (acpi_id[0x13] high edge lint[0x1]) May 2 09:43:37 Sakaar kernel: ACPI: LAPIC_NMI (acpi_id[0x14] high edge lint[0x1]) May 2 09:43:37 Sakaar kernel: IOAPIC[0]: apic_id 2, version 32, address 0xfec00000, GSI 0-119 May 2 09:43:37 Sakaar kernel: ACPI: INT_SRC_OVR (bus 0 bus_irq 0 global_irq 2 dfl dfl) May 2 09:43:37 Sakaar kernel: ACPI: INT_SRC_OVR (bus 0 bus_irq 9 global_irq 9 high level) May 2 09:43:37 Sakaar kernel: ACPI: Using ACPI (MADT) for SMP configuration information May 2 09:43:37 Sakaar kernel: ACPI: HPET id: 0x8086a201 base: 0xfed00000 May 2 09:43:37 Sakaar kernel: e820: update [mem 0x2b886000-0x2b947fff] usable ==> reserved May 2 09:43:37 Sakaar kernel: TSC deadline timer available May 2 09:43:37 Sakaar kernel: smpboot: Allowing 16 CPUs, 0 hotplug CPUs May 2 09:43:37 Sakaar kernel: [mem 0x3f800000-0xdfffffff] available for PCI devices May 2 09:43:37 Sakaar kernel: Booting paravirtualized kernel on bare hardware May 2 09:43:37 Sakaar kernel: clocksource: refined-jiffies: mask: 0xffffffff max_cycles: 0xffffffff, max_idle_ns: 1910969940391419 ns May 2 09:43:37 Sakaar kernel: setup_percpu: NR_CPUS:256 nr_cpumask_bits:16 nr_cpu_ids:16 nr_node_ids:1 May 2 09:43:37 Sakaar kernel: percpu: Embedded 56 pages/cpu s190824 r8192 d30360 u262144 May 2 09:43:37 Sakaar kernel: pcpu-alloc: s190824 r8192 d30360 u262144 alloc=1*2097152 May 2 09:43:37 Sakaar kernel: pcpu-alloc: [0] 00 01 02 03 04 05 06 07 [0] 08 09 10 11 12 13 14 15 May 2 09:43:37 Sakaar kernel: Fallback order for Node 0: 0 May 2 09:43:37 Sakaar kernel: Built 1 zonelists, mobility grouping on. Total pages: 8205299 May 2 09:43:37 Sakaar kernel: Policy zone: Normal May 2 09:43:37 Sakaar kernel: Kernel command line: BOOT_IMAGE=/bzimage initrd=/bzroot May 2 09:43:37 Sakaar kernel: Unknown kernel command line parameters "BOOT_IMAGE=/bzimage", will be passed to user space. May 2 09:43:37 Sakaar kernel: Dentry cache hash table entries: 4194304 (order: 13, 33554432 bytes, linear) May 2 09:43:37 Sakaar kernel: Inode-cache hash table entries: 2097152 (order: 12, 16777216 bytes, linear) May 2 09:43:37 Sakaar kernel: mem auto-init: stack:off, heap alloc:off, heap free:off May 2 09:43:37 Sakaar kernel: software IO TLB: area num 16. May 2 09:43:37 Sakaar kernel: Memory: 32544020K/33342816K available (12295K kernel code, 1749K rwdata, 3648K rodata, 1864K init, 3704K bss, 798540K reserved, 0K cma-reserved) May 2 09:43:37 Sakaar kernel: SLUB: HWalign=64, Order=0-3, MinObjects=0, CPUs=16, Nodes=1 May 2 09:43:37 Sakaar kernel: ftrace: allocating 42754 entries in 168 pages May 2 09:43:37 Sakaar kernel: ftrace: allocated 168 pages with 3 groups May 2 09:43:37 Sakaar kernel: Dynamic Preempt: voluntary May 2 09:43:37 Sakaar kernel: rcu: Preemptible hierarchical RCU implementation. May 2 09:43:37 Sakaar kernel: rcu: RCU event tracing is enabled. May 2 09:43:37 Sakaar kernel: rcu: RCU restricting CPUs from NR_CPUS=256 to nr_cpu_ids=16. May 2 09:43:37 Sakaar kernel: Trampoline variant of Tasks RCU enabled. May 2 09:43:37 Sakaar kernel: Rude variant of Tasks RCU enabled. May 2 09:43:37 Sakaar kernel: Tracing variant of Tasks RCU enabled. May 2 09:43:37 Sakaar kernel: rcu: RCU calculated value of scheduler-enlistment delay is 100 jiffies. May 2 09:43:37 Sakaar kernel: rcu: Adjusting geometry for rcu_fanout_leaf=16, nr_cpu_ids=16 May 2 09:43:37 Sakaar kernel: NR_IRQS: 16640, nr_irqs: 2184, preallocated irqs: 16 May 2 09:43:37 Sakaar kernel: rcu: srcu_init: Setting srcu_struct sizes based on contention. May 2 09:43:37 Sakaar kernel: Console: colour dummy device 80x25 May 2 09:43:37 Sakaar kernel: printk: console [tty0] enabled May 2 09:43:37 Sakaar kernel: ACPI: Core revision 20220331 May 2 09:43:37 Sakaar kernel: clocksource: hpet: mask: 0xffffffff max_cycles: 0xffffffff, max_idle_ns: 79635855245 ns May 2 09:43:37 Sakaar kernel: APIC: Switch to symmetric I/O mode setup May 2 09:43:37 Sakaar kernel: DMAR: Host address width 39 May 2 09:43:37 Sakaar kernel: DMAR: DRHD base: 0x000000fed90000 flags: 0x0 May 2 09:43:37 Sakaar kernel: DMAR: dmar0: reg_base_addr fed90000 ver 4:0 cap 1c0000c40660462 ecap 69e2ff0505e May 2 09:43:37 Sakaar kernel: DMAR: DRHD base: 0x000000fed91000 flags: 0x1 May 2 09:43:37 Sakaar kernel: DMAR: dmar1: reg_base_addr fed91000 ver 1:0 cap d2008c40660462 ecap f050da May 2 09:43:37 Sakaar kernel: DMAR: RMRR base: 0x0000003b000000 end: 0x0000003f7fffff May 2 09:43:37 Sakaar kernel: DMAR-IR: IOAPIC id 2 under DRHD base 0xfed91000 IOMMU 1 May 2 09:43:37 Sakaar kernel: DMAR-IR: HPET id 0 under DRHD base 0xfed91000 May 2 09:43:37 Sakaar kernel: DMAR-IR: Queued invalidation will be enabled to support x2apic and Intr-remapping. May 2 09:43:37 Sakaar kernel: DMAR-IR: Enabled IRQ remapping in x2apic mode May 2 09:43:37 Sakaar kernel: x2apic enabled May 2 09:43:37 Sakaar kernel: Switched APIC routing to cluster x2apic. May 2 09:43:37 Sakaar kernel: ..TIMER: vector=0x30 apic1=0 pin1=2 apic2=-1 pin2=-1 May 2 09:43:37 Sakaar kernel: clocksource: tsc-early: mask: 0xffffffffffffffff max_cycles: 0x33e452fbb2f, max_idle_ns: 440795236593 ns May 2 09:43:37 Sakaar kernel: Calibrating delay loop (skipped), value calculated using timer frequency.. 7200.00 BogoMIPS (lpj=3600000) May 2 09:43:37 Sakaar kernel: pid_max: default: 32768 minimum: 301 May 2 09:43:37 Sakaar kernel: Mount-cache hash table entries: 65536 (order: 7, 524288 bytes, linear) May 2 09:43:37 Sakaar kernel: Mountpoint-cache hash table entries: 65536 (order: 7, 524288 bytes, linear) May 2 09:43:37 Sakaar kernel: CPU0: Thermal monitoring enabled (TM1) May 2 09:43:37 Sakaar kernel: x86/cpu: User Mode Instruction Prevention (UMIP) activated May 2 09:43:37 Sakaar kernel: process: using mwait in idle threads May 2 09:43:37 Sakaar kernel: Last level iTLB entries: 4KB 0, 2MB 0, 4MB 0 May 2 09:43:37 Sakaar kernel: Last level dTLB entries: 4KB 0, 2MB 0, 4MB 0, 1GB 0 May 2 09:43:37 Sakaar kernel: Spectre V1 : Mitigation: usercopy/swapgs barriers and __user pointer sanitization May 2 09:43:37 Sakaar kernel: Spectre V2 : Mitigation: Enhanced IBRS May 2 09:43:37 Sakaar kernel: Spectre V2 : Spectre v2 / SpectreRSB mitigation: Filling RSB on context switch May 2 09:43:37 Sakaar kernel: Spectre V2 : Spectre v2 / PBRSB-eIBRS: Retire a single CALL on VMEXIT May 2 09:43:37 Sakaar kernel: RETBleed: Mitigation: Enhanced IBRS May 2 09:43:37 Sakaar kernel: Spectre V2 : mitigation: Enabling conditional Indirect Branch Prediction Barrier May 2 09:43:37 Sakaar kernel: Speculative Store Bypass: Mitigation: Speculative Store Bypass disabled via prctl May 2 09:43:37 Sakaar kernel: MMIO Stale Data: Mitigation: Clear CPU buffers May 2 09:43:37 Sakaar kernel: Freeing SMP alternatives memory: 24K May 2 09:43:37 Sakaar kernel: smpboot: CPU0: 11th Gen Intel(R) Core(TM) i7-11700K @ 3.60GHz (family: 0x6, model: 0xa7, stepping: 0x1) May 2 09:43:37 Sakaar kernel: cblist_init_generic: Setting adjustable number of callback queues. May 2 09:43:37 Sakaar kernel: cblist_init_generic: Setting shift to 4 and lim to 1. ### [PREVIOUS LINE REPEATED 2 TIMES] ### May 2 09:43:37 Sakaar kernel: Performance Events: PEBS fmt4+-baseline, AnyThread deprecated, Icelake events, 32-deep LBR, full-width counters, Intel PMU driver. May 2 09:43:37 Sakaar kernel: ... version: 5 May 2 09:43:37 Sakaar kernel: ... bit width: 48 May 2 09:43:37 Sakaar kernel: ... generic registers: 8 May 2 09:43:37 Sakaar kernel: ... value mask: 0000ffffffffffff May 2 09:43:37 Sakaar kernel: ... max period: 00007fffffffffff May 2 09:43:37 Sakaar kernel: ... fixed-purpose events: 4 May 2 09:43:37 Sakaar kernel: ... event mask: 0001000f000000ff May 2 09:43:37 Sakaar kernel: Estimated ratio of average max frequency by base frequency (times 1024): 1393 May 2 09:43:37 Sakaar kernel: rcu: Hierarchical SRCU implementation. May 2 09:43:37 Sakaar kernel: rcu: Max phase no-delay instances is 400. May 2 09:43:37 Sakaar kernel: smp: Bringing up secondary CPUs ... May 2 09:43:37 Sakaar kernel: x86: Booting SMP configuration: May 2 09:43:37 Sakaar kernel: .... node #0, CPUs: #1 #2 #3 #4 #5 #6 #7 #8 May 2 09:43:37 Sakaar kernel: MMIO Stale Data CPU bug present and SMT on, data leak possible. See https://www.kernel.org/doc/html/latest/admin-guide/hw-vuln/processor_mmio_stale_data.html for more details. May 2 09:43:37 Sakaar kernel: #9 #10 #11 #12 #13 #14 #15 May 2 09:43:37 Sakaar kernel: smp: Brought up 1 node, 16 CPUs May 2 09:43:37 Sakaar kernel: smpboot: Max logical packages: 1 May 2 09:43:37 Sakaar kernel: smpboot: Total of 16 processors activated (115200.00 BogoMIPS) May 2 09:43:37 Sakaar kernel: devtmpfs: initialized May 2 09:43:37 Sakaar kernel: x86/mm: Memory block size: 128MB May 2 09:43:37 Sakaar kernel: ACPI: PM: Registering ACPI NVS region [mem 0x35139000-0x35606fff] (5038080 bytes) May 2 09:43:37 Sakaar kernel: clocksource: jiffies: mask: 0xffffffff max_cycles: 0xffffffff, max_idle_ns: 1911260446275000 ns May 2 09:43:37 Sakaar kernel: futex hash table entries: 4096 (order: 6, 262144 bytes, linear) May 2 09:43:37 Sakaar kernel: pinctrl core: initialized pinctrl subsystem May 2 09:43:37 Sakaar kernel: NET: Registered PF_NETLINK/PF_ROUTE protocol family May 2 09:43:37 Sakaar kernel: thermal_sys: Registered thermal governor 'fair_share' May 2 09:43:37 Sakaar kernel: thermal_sys: Registered thermal governor 'bang_bang' May 2 09:43:37 Sakaar kernel: thermal_sys: Registered thermal governor 'step_wise' May 2 09:43:37 Sakaar kernel: thermal_sys: Registered thermal governor 'user_space' May 2 09:43:37 Sakaar kernel: cpuidle: using governor ladder May 2 09:43:37 Sakaar kernel: cpuidle: using governor menu May 2 09:43:37 Sakaar kernel: ACPI FADT declares the system doesn't support PCIe ASPM, so disable it May 2 09:43:37 Sakaar kernel: PCI: MMCONFIG for domain 0000 [bus 00-ff] at [mem 0xe0000000-0xefffffff] (base 0xe0000000) May 2 09:43:37 Sakaar kernel: PCI: MMCONFIG at [mem 0xe0000000-0xefffffff] reserved in E820 May 2 09:43:37 Sakaar kernel: PCI: Using configuration type 1 for base access May 2 09:43:37 Sakaar kernel: kprobes: kprobe jump-optimization is enabled. All kprobes are optimized if possible. May 2 09:43:37 Sakaar kernel: HugeTLB: registered 1.00 GiB page size, pre-allocated 0 pages May 2 09:43:37 Sakaar kernel: HugeTLB: 16380 KiB vmemmap can be freed for a 1.00 GiB page May 2 09:43:37 Sakaar kernel: HugeTLB: registered 2.00 MiB page size, pre-allocated 0 pages May 2 09:43:37 Sakaar kernel: HugeTLB: 28 KiB vmemmap can be freed for a 2.00 MiB page May 2 09:43:37 Sakaar kernel: raid6: avx512x4 gen() 57996 MB/s May 2 09:43:37 Sakaar kernel: raid6: avx512x2 gen() 59863 MB/s May 2 09:43:37 Sakaar kernel: raid6: avx512x1 gen() 52571 MB/s May 2 09:43:37 Sakaar kernel: raid6: avx2x4 gen() 42001 MB/s May 2 09:43:37 Sakaar kernel: raid6: avx2x2 gen() 43546 MB/s May 2 09:43:37 Sakaar kernel: raid6: avx2x1 gen() 33770 MB/s May 2 09:43:37 Sakaar kernel: raid6: using algorithm avx512x2 gen() 59863 MB/s May 2 09:43:37 Sakaar kernel: raid6: .... xor() 34397 MB/s, rmw enabled May 2 09:43:37 Sakaar kernel: raid6: using avx512x2 recovery algorithm May 2 09:43:37 Sakaar kernel: ACPI: Added _OSI(Module Device) May 2 09:43:37 Sakaar kernel: ACPI: Added _OSI(Processor Device) May 2 09:43:37 Sakaar kernel: ACPI: Added _OSI(3.0 _SCP Extensions) May 2 09:43:37 Sakaar kernel: ACPI: Added _OSI(Processor Aggregator Device) May 2 09:43:37 Sakaar kernel: ACPI: 14 ACPI AML tables successfully acquired and loaded May 2 09:43:37 Sakaar kernel: ACPI: Dynamic OEM Table Load: May 2 09:43:37 Sakaar kernel: ACPI: SSDT 0xFFFF8881013B5600 0001CB (v02 PmRef Cpu0Psd 00003000 INTL 20180209) May 2 09:43:37 Sakaar kernel: ACPI: \_SB_.PR00: _OSC native thermal LVT Acked May 2 09:43:37 Sakaar kernel: ACPI: Dynamic OEM Table Load: May 2 09:43:37 Sakaar kernel: ACPI: SSDT 0xFFFF888101023800 000455 (v02 PmRef Cpu0Cst 00003001 INTL 20180209) May 2 09:43:37 Sakaar kernel: ACPI: Dynamic OEM Table Load: May 2 09:43:37 Sakaar kernel: ACPI: SSDT 0xFFFF888101024000 0006CB (v02 PmRef Cpu0Ist 00003000 INTL 20180209) May 2 09:43:37 Sakaar kernel: ACPI: Dynamic OEM Table Load: May 2 09:43:37 Sakaar kernel: ACPI: SSDT 0xFFFF888101015800 000286 (v02 PmRef Cpu0Hwp 00003000 INTL 20180209) May 2 09:43:37 Sakaar kernel: ACPI: Dynamic OEM Table Load: May 2 09:43:37 Sakaar kernel: ACPI: SSDT 0xFFFF88810101A000 0008E7 (v02 PmRef ApIst 00003000 INTL 20180209) May 2 09:43:37 Sakaar kernel: ACPI: Dynamic OEM Table Load: May 2 09:43:37 Sakaar kernel: ACPI: SSDT 0xFFFF888101025800 00048A (v02 PmRef ApHwp 00003000 INTL 20180209) May 2 09:43:37 Sakaar kernel: ACPI: Dynamic OEM Table Load: May 2 09:43:37 Sakaar kernel: ACPI: SSDT 0xFFFF888101026000 0004D4 (v02 PmRef ApPsd 00003000 INTL 20180209) May 2 09:43:37 Sakaar kernel: ACPI: Dynamic OEM Table Load: May 2 09:43:37 Sakaar kernel: ACPI: SSDT 0xFFFF888101026800 00048A (v02 PmRef ApCst 00003000 INTL 20180209) May 2 09:43:37 Sakaar kernel: ACPI: Interpreter enabled May 2 09:43:37 Sakaar kernel: ACPI: PM: (supports S0 S3 S5) May 2 09:43:37 Sakaar kernel: ACPI: Using IOAPIC for interrupt routing May 2 09:43:37 Sakaar kernel: PCI: Using host bridge windows from ACPI; if necessary, use "pci=nocrs" and report a bug May 2 09:43:37 Sakaar kernel: PCI: Ignoring E820 reservations for host bridge windows May 2 09:43:37 Sakaar kernel: ACPI: Enabled 6 GPEs in block 00 to 7F May 2 09:43:37 Sakaar kernel: ACPI: PM: Power Resource [WRST] May 2 09:43:37 Sakaar kernel: ACPI: PM: Power Resource [DRST] May 2 09:43:37 Sakaar kernel: ACPI: PM: Power Resource [PAUD] May 2 09:43:37 Sakaar kernel: ACPI: PM: Power Resource [PXTC] May 2 09:43:37 Sakaar kernel: ACPI: PM: Power Resource [WRST] May 2 09:43:37 Sakaar kernel: ACPI: PM: Power Resource [SPR0] May 2 09:43:37 Sakaar kernel: ACPI: PM: Power Resource [SPR1] May 2 09:43:37 Sakaar kernel: ACPI: PM: Power Resource [SPR2] May 2 09:43:37 Sakaar kernel: ACPI: PM: Power Resource [SPR3] May 2 09:43:37 Sakaar kernel: ACPI: PM: Power Resource [SPR5] May 2 09:43:37 Sakaar kernel: ACPI: PM: Power Resource [V0PR] May 2 09:43:37 Sakaar kernel: ACPI: PM: Power Resource [V1PR] May 2 09:43:37 Sakaar kernel: ACPI: PM: Power Resource [V2PR] May 2 09:43:37 Sakaar kernel: ACPI: PM: Power Resource [FN00] May 2 09:43:37 Sakaar kernel: ACPI: PM: Power Resource [FN01] May 2 09:43:37 Sakaar kernel: ACPI: PM: Power Resource [FN02] May 2 09:43:37 Sakaar kernel: ACPI: PM: Power Resource [FN03] May 2 09:43:37 Sakaar kernel: ACPI: PM: Power Resource [FN04] May 2 09:43:37 Sakaar kernel: ACPI: PM: Power Resource [PIN] May 2 09:43:37 Sakaar kernel: ACPI: PCI Root Bridge [PC00] (domain 0000 [bus 00-fe]) May 2 09:43:37 Sakaar kernel: acpi PNP0A08:00: _OSC: OS supports [ExtendedConfig ASPM ClockPM Segments MSI HPX-Type3] May 2 09:43:37 Sakaar kernel: acpi PNP0A08:00: _OSC: OS now controls [PME AER PCIeCapability LTR] May 2 09:43:37 Sakaar kernel: acpi PNP0A08:00: FADT indicates ASPM is unsupported, using BIOS configuration May 2 09:43:37 Sakaar kernel: PCI host bridge to bus 0000:00 May 2 09:43:37 Sakaar kernel: pci_bus 0000:00: root bus resource [io 0x0000-0x0cf7 window] May 2 09:43:37 Sakaar kernel: pci_bus 0000:00: root bus resource [io 0x0d00-0xffff window] May 2 09:43:37 Sakaar kernel: pci_bus 0000:00: root bus resource [mem 0x000a0000-0x000bffff window] May 2 09:43:37 Sakaar kernel: pci_bus 0000:00: root bus resource [mem 0x3f800000-0xdfffffff window] May 2 09:43:37 Sakaar kernel: pci_bus 0000:00: root bus resource [bus 00-fe] May 2 09:43:37 Sakaar kernel: pci 0000:00:00.0: [8086:4c43] type 00 class 0x060000 May 2 09:43:37 Sakaar kernel: pci 0000:00:01.0: [8086:4c01] type 01 class 0x060400 May 2 09:43:37 Sakaar kernel: pci 0000:00:01.0: PME# supported from D0 D3hot D3cold May 2 09:43:37 Sakaar kernel: pci 0000:00:02.0: [8086:4c8a] type 00 class 0x030000 May 2 09:43:37 Sakaar kernel: pci 0000:00:02.0: reg 0x10: [mem 0x62000000-0x62ffffff 64bit] May 2 09:43:37 Sakaar kernel: pci 0000:00:02.0: reg 0x18: [mem 0x40000000-0x4fffffff 64bit pref] May 2 09:43:37 Sakaar kernel: pci 0000:00:02.0: reg 0x20: [io 0x5000-0x503f] May 2 09:43:37 Sakaar kernel: pci 0000:00:02.0: BAR 2: assigned to efifb May 2 09:43:37 Sakaar kernel: pci 0000:00:02.0: DMAR: Skip IOMMU disabling for graphics May 2 09:43:37 Sakaar kernel: pci 0000:00:02.0: Video device with shadowed ROM at [mem 0x000c0000-0x000dffff] May 2 09:43:37 Sakaar kernel: pci 0000:00:06.0: [8086:4c09] type 01 class 0x060400 May 2 09:43:37 Sakaar kernel: pci 0000:00:06.0: PME# supported from D0 D3hot D3cold May 2 09:43:37 Sakaar kernel: pci 0000:00:14.0: [8086:43ed] type 00 class 0x0c0330 May 2 09:43:37 Sakaar kernel: pci 0000:00:14.0: reg 0x10: [mem 0x64800000-0x6480ffff 64bit] May 2 09:43:37 Sakaar kernel: pci 0000:00:14.0: PME# supported from D3hot D3cold May 2 09:43:37 Sakaar kernel: pci 0000:00:14.2: [8086:43ef] type 00 class 0x050000 May 2 09:43:37 Sakaar kernel: pci 0000:00:14.2: reg 0x10: [mem 0x64814000-0x64817fff 64bit] May 2 09:43:37 Sakaar kernel: pci 0000:00:14.2: reg 0x18: [mem 0x6481e000-0x6481efff 64bit] May 2 09:43:37 Sakaar kernel: pci 0000:00:16.0: [8086:43e0] type 00 class 0x078000 May 2 09:43:37 Sakaar kernel: pci 0000:00:16.0: reg 0x10: [mem 0x6481d000-0x6481dfff 64bit] May 2 09:43:37 Sakaar kernel: pci 0000:00:16.0: PME# supported from D3hot May 2 09:43:37 Sakaar kernel: pci 0000:00:17.0: [8086:43d2] type 00 class 0x010601 May 2 09:43:37 Sakaar kernel: pci 0000:00:17.0: reg 0x10: [mem 0x64818000-0x64819fff] May 2 09:43:37 Sakaar kernel: pci 0000:00:17.0: reg 0x14: [mem 0x6481c000-0x6481c0ff] May 2 09:43:37 Sakaar kernel: pci 0000:00:17.0: reg 0x18: [io 0x5090-0x5097] May 2 09:43:37 Sakaar kernel: pci 0000:00:17.0: reg 0x1c: [io 0x5080-0x5083] May 2 09:43:37 Sakaar kernel: pci 0000:00:17.0: reg 0x20: [io 0x5060-0x507f] May 2 09:43:37 Sakaar kernel: pci 0000:00:17.0: reg 0x24: [mem 0x6481b000-0x6481b7ff] May 2 09:43:37 Sakaar kernel: pci 0000:00:17.0: PME# supported from D3hot May 2 09:43:37 Sakaar kernel: pci 0000:00:1b.0: [8086:43c4] type 01 class 0x060400 May 2 09:43:37 Sakaar kernel: pci 0000:00:1b.0: PME# supported from D0 D3hot D3cold May 2 09:43:37 Sakaar kernel: pci 0000:00:1c.0: [8086:43bc] type 01 class 0x060400 May 2 09:43:37 Sakaar kernel: pci 0000:00:1c.0: PME# supported from D0 D3hot D3cold May 2 09:43:37 Sakaar kernel: pci 0000:00:1c.7: [8086:43bf] type 01 class 0x060400 May 2 09:43:37 Sakaar kernel: pci 0000:00:1c.7: PME# supported from D0 D3hot D3cold May 2 09:43:37 Sakaar kernel: pci 0000:00:1d.0: [8086:43b0] type 01 class 0x060400 May 2 09:43:37 Sakaar kernel: pci 0000:00:1d.0: PME# supported from D0 D3hot D3cold May 2 09:43:37 Sakaar kernel: pci 0000:00:1f.0: [8086:4387] type 00 class 0x060100 May 2 09:43:37 Sakaar kernel: pci 0000:00:1f.3: [8086:43c8] type 00 class 0x040300 May 2 09:43:37 Sakaar kernel: pci 0000:00:1f.3: reg 0x10: [mem 0x64810000-0x64813fff 64bit] May 2 09:43:37 Sakaar kernel: pci 0000:00:1f.3: reg 0x20: [mem 0x64100000-0x641fffff 64bit] May 2 09:43:37 Sakaar kernel: pci 0000:00:1f.3: PME# supported from D3hot D3cold May 2 09:43:37 Sakaar kernel: pci 0000:00:1f.4: [8086:43a3] type 00 class 0x0c0500 May 2 09:43:37 Sakaar kernel: pci 0000:00:1f.4: reg 0x10: [mem 0x6481a000-0x6481a0ff 64bit] May 2 09:43:37 Sakaar kernel: pci 0000:00:1f.4: reg 0x20: [io 0xefa0-0xefbf] May 2 09:43:37 Sakaar kernel: pci 0000:00:1f.5: [8086:43a4] type 00 class 0x0c8000 May 2 09:43:37 Sakaar kernel: pci 0000:00:1f.5: reg 0x10: [mem 0xfe010000-0xfe010fff] May 2 09:43:37 Sakaar kernel: pci 0000:01:00.0: [10de:1f82] type 00 class 0x030000 May 2 09:43:37 Sakaar kernel: pci 0000:01:00.0: reg 0x10: [mem 0x63000000-0x63ffffff] May 2 09:43:37 Sakaar kernel: pci 0000:01:00.0: reg 0x14: [mem 0x50000000-0x5fffffff 64bit pref] May 2 09:43:37 Sakaar kernel: pci 0000:01:00.0: reg 0x1c: [mem 0x60000000-0x61ffffff 64bit pref] May 2 09:43:37 Sakaar kernel: pci 0000:01:00.0: reg 0x24: [io 0x4000-0x407f] May 2 09:43:37 Sakaar kernel: pci 0000:01:00.0: reg 0x30: [mem 0x64000000-0x6407ffff pref] May 2 09:43:37 Sakaar kernel: pci 0000:01:00.0: PME# supported from D0 D3hot D3cold May 2 09:43:37 Sakaar kernel: pci 0000:01:00.1: [10de:10fa] type 00 class 0x040300 May 2 09:43:37 Sakaar kernel: pci 0000:01:00.1: reg 0x10: [mem 0x64080000-0x64083fff] May 2 09:43:37 Sakaar kernel: pci 0000:00:01.0: PCI bridge to [bus 01] May 2 09:43:37 Sakaar kernel: pci 0000:00:01.0: bridge window [io 0x4000-0x4fff] May 2 09:43:37 Sakaar kernel: pci 0000:00:01.0: bridge window [mem 0x63000000-0x640fffff] May 2 09:43:37 Sakaar kernel: pci 0000:00:01.0: bridge window [mem 0x50000000-0x61ffffff 64bit pref] May 2 09:43:37 Sakaar kernel: pci 0000:02:00.0: [15b7:5009] type 00 class 0x010802 May 2 09:43:37 Sakaar kernel: pci 0000:02:00.0: reg 0x10: [mem 0x64700000-0x64703fff 64bit] May 2 09:43:37 Sakaar kernel: pci 0000:02:00.0: reg 0x20: [mem 0x64704000-0x647040ff 64bit] May 2 09:43:37 Sakaar kernel: pci 0000:00:06.0: PCI bridge to [bus 02] May 2 09:43:37 Sakaar kernel: pci 0000:00:06.0: bridge window [mem 0x64700000-0x647fffff] May 2 09:43:37 Sakaar kernel: pci 0000:03:00.0: [1000:0087] type 00 class 0x010700 May 2 09:43:37 Sakaar kernel: pci 0000:03:00.0: reg 0x10: [io 0x3000-0x30ff] May 2 09:43:37 Sakaar kernel: pci 0000:03:00.0: reg 0x14: [mem 0x64540000-0x6454ffff 64bit] May 2 09:43:37 Sakaar kernel: pci 0000:03:00.0: reg 0x1c: [mem 0x64500000-0x6453ffff 64bit] May 2 09:43:37 Sakaar kernel: pci 0000:03:00.0: reg 0x30: [mem 0x64400000-0x644fffff pref] May 2 09:43:37 Sakaar kernel: pci 0000:03:00.0: supports D1 D2 May 2 09:43:37 Sakaar kernel: pci 0000:03:00.0: 31.504 Gb/s available PCIe bandwidth, limited by 8.0 GT/s PCIe x4 link at 0000:00:1b.0 (capable of 63.008 Gb/s with 8.0 GT/s PCIe x8 link) May 2 09:43:37 Sakaar kernel: pci 0000:00:1b.0: PCI bridge to [bus 03] May 2 09:43:37 Sakaar kernel: pci 0000:00:1b.0: bridge window [io 0x3000-0x3fff] May 2 09:43:37 Sakaar kernel: pci 0000:00:1b.0: bridge window [mem 0x64400000-0x645fffff] May 2 09:43:37 Sakaar kernel: pci 0000:04:00.0: [8086:15f3] type 00 class 0x020000 May 2 09:43:37 Sakaar kernel: pci 0000:04:00.0: reg 0x10: [mem 0x64200000-0x642fffff] May 2 09:43:37 Sakaar kernel: pci 0000:04:00.0: reg 0x1c: [mem 0x64300000-0x64303fff] May 2 09:43:37 Sakaar kernel: pci 0000:04:00.0: PME# supported from D0 D3hot D3cold May 2 09:43:37 Sakaar kernel: pci 0000:00:1c.0: PCI bridge to [bus 04] May 2 09:43:37 Sakaar kernel: pci 0000:00:1c.0: bridge window [mem 0x64200000-0x643fffff] May 2 09:43:37 Sakaar kernel: pci 0000:05:00.0: [8086:2723] type 00 class 0x028000 May 2 09:43:37 Sakaar kernel: pci 0000:05:00.0: reg 0x10: [mem 0x64600000-0x64603fff 64bit] May 2 09:43:37 Sakaar kernel: pci 0000:05:00.0: PME# supported from D0 D3hot D3cold May 2 09:43:37 Sakaar kernel: pci 0000:00:1c.7: PCI bridge to [bus 05] May 2 09:43:37 Sakaar kernel: pci 0000:00:1c.7: bridge window [mem 0x64600000-0x646fffff] May 2 09:43:37 Sakaar kernel: pci 0000:00:1d.0: PCI bridge to [bus 06] May 2 09:43:37 Sakaar kernel: ACPI: PCI: Interrupt link LNKA configured for IRQ 0 May 2 09:43:37 Sakaar kernel: ACPI: PCI: Interrupt link LNKB configured for IRQ 1 May 2 09:43:37 Sakaar kernel: ACPI: PCI: Interrupt link LNKC configured for IRQ 0 May 2 09:43:37 Sakaar kernel: ACPI: PCI: Interrupt link LNKD configured for IRQ 0 May 2 09:43:37 Sakaar kernel: ACPI: PCI: Interrupt link LNKE configured for IRQ 0 May 2 09:43:37 Sakaar kernel: ACPI: PCI: Interrupt link LNKF configured for IRQ 0 May 2 09:43:37 Sakaar kernel: ACPI: PCI: Interrupt link LNKG configured for IRQ 0 May 2 09:43:37 Sakaar kernel: ACPI: PCI: Interrupt link LNKH configured for IRQ 0 May 2 09:43:37 Sakaar kernel: iommu: Default domain type: Passthrough May 2 09:43:37 Sakaar kernel: SCSI subsystem initialized May 2 09:43:37 Sakaar kernel: libata version 3.00 loaded. May 2 09:43:37 Sakaar kernel: ACPI: bus type USB registered May 2 09:43:37 Sakaar kernel: usbcore: registered new interface driver usbfs May 2 09:43:37 Sakaar kernel: usbcore: registered new interface driver hub May 2 09:43:37 Sakaar kernel: usbcore: registered new device driver usb May 2 09:43:37 Sakaar kernel: pps_core: LinuxPPS API ver. 1 registered May 2 09:43:37 Sakaar kernel: pps_core: Software ver. 5.3.6 - Copyright 2005-2007 Rodolfo Giometti <[email protected]> May 2 09:43:37 Sakaar kernel: PTP clock support registered May 2 09:43:37 Sakaar kernel: Registered efivars operations May 2 09:43:37 Sakaar kernel: PCI: Using ACPI for IRQ routing May 2 09:43:37 Sakaar kernel: PCI: pci_cache_line_size set to 64 bytes May 2 09:43:37 Sakaar kernel: pci 0000:00:1f.5: can't claim BAR 0 [mem 0xfe010000-0xfe010fff]: no compatible bridge window May 2 09:43:37 Sakaar kernel: e820: reserve RAM buffer [mem 0x0005e000-0x0005ffff] May 2 09:43:37 Sakaar kernel: e820: reserve RAM buffer [mem 0x25d64018-0x27ffffff] May 2 09:43:37 Sakaar kernel: e820: reserve RAM buffer [mem 0x2b201018-0x2bffffff] May 2 09:43:37 Sakaar kernel: e820: reserve RAM buffer [mem 0x2b37e018-0x2bffffff] May 2 09:43:37 Sakaar kernel: e820: reserve RAM buffer [mem 0x2b886000-0x2bffffff] May 2 09:43:37 Sakaar kernel: e820: reserve RAM buffer [mem 0x306c8000-0x33ffffff] May 2 09:43:37 Sakaar kernel: e820: reserve RAM buffer [mem 0x329b9000-0x33ffffff] May 2 09:43:37 Sakaar kernel: e820: reserve RAM buffer [mem 0x36000000-0x37ffffff] May 2 09:43:37 Sakaar kernel: e820: reserve RAM buffer [mem 0x8c0800000-0x8c3ffffff] May 2 09:43:37 Sakaar kernel: pci 0000:00:02.0: vgaarb: setting as boot VGA device May 2 09:43:37 Sakaar kernel: pci 0000:00:02.0: vgaarb: bridge control possible May 2 09:43:37 Sakaar kernel: pci 0000:00:02.0: vgaarb: VGA device added: decodes=io+mem,owns=io+mem,locks=none May 2 09:43:37 Sakaar kernel: pci 0000:01:00.0: vgaarb: bridge control possible May 2 09:43:37 Sakaar kernel: pci 0000:01:00.0: vgaarb: VGA device added: decodes=io+mem,owns=none,locks=none May 2 09:43:37 Sakaar kernel: vgaarb: loaded May 2 09:43:37 Sakaar kernel: hpet0: at MMIO 0xfed00000, IRQs 2, 8, 0, 0, 0, 0, 0, 0 May 2 09:43:37 Sakaar kernel: hpet0: 8 comparators, 64-bit 24.000000 MHz counter May 2 09:43:37 Sakaar kernel: clocksource: Switched to clocksource tsc-early May 2 09:43:37 Sakaar kernel: FS-Cache: Loaded May 2 09:43:37 Sakaar kernel: pnp: PnP ACPI init May 2 09:43:37 Sakaar kernel: system 00:00: [io 0x0a00-0x0a2f] has been reserved May 2 09:43:37 Sakaar kernel: system 00:00: [io 0x0a30-0x0a3f] has been reserved May 2 09:43:37 Sakaar kernel: system 00:00: [io 0x0a40-0x0a4f] has been reserved May 2 09:43:37 Sakaar kernel: pnp 00:01: [dma 0 disabled] May 2 09:43:37 Sakaar kernel: system 00:02: [io 0x0680-0x069f] has been reserved May 2 09:43:37 Sakaar kernel: system 00:02: [io 0x164e-0x164f] has been reserved May 2 09:43:37 Sakaar kernel: system 00:03: [io 0x1854-0x1857] has been reserved May 2 09:43:37 Sakaar kernel: system 00:04: [mem 0xfed10000-0xfed17fff] has been reserved May 2 09:43:37 Sakaar kernel: system 00:04: [mem 0xfeda0000-0xfeda0fff] has been reserved May 2 09:43:37 Sakaar kernel: system 00:04: [mem 0xfeda1000-0xfeda1fff] has been reserved May 2 09:43:37 Sakaar kernel: system 00:04: [mem 0xe0000000-0xefffffff] has been reserved May 2 09:43:37 Sakaar kernel: system 00:04: [mem 0xfed20000-0xfed7ffff] could not be reserved May 2 09:43:37 Sakaar kernel: system 00:04: [mem 0xfed90000-0xfed93fff] could not be reserved May 2 09:43:37 Sakaar kernel: system 00:04: [mem 0xfed45000-0xfed8ffff] could not be reserved May 2 09:43:37 Sakaar kernel: system 00:04: [mem 0xfee00000-0xfeefffff] could not be reserved May 2 09:43:37 Sakaar kernel: system 00:05: [mem 0xfc000000-0xfc00ffff] has been reserved May 2 09:43:37 Sakaar kernel: system 00:06: [io 0x1800-0x18fe] could not be reserved May 2 09:43:37 Sakaar kernel: system 00:06: [mem 0xfe000000-0xfe01ffff] could not be reserved May 2 09:43:37 Sakaar kernel: system 00:06: [mem 0xfe04c000-0xfe04ffff] has been reserved May 2 09:43:37 Sakaar kernel: system 00:06: [mem 0xfe050000-0xfe0affff] has been reserved May 2 09:43:37 Sakaar kernel: system 00:06: [mem 0xfe0d0000-0xfe0fffff] has been reserved May 2 09:43:37 Sakaar kernel: system 00:06: [mem 0xfe200000-0xfe7fffff] has been reserved May 2 09:43:37 Sakaar kernel: system 00:06: [mem 0xff000000-0xffffffff] has been reserved May 2 09:43:37 Sakaar kernel: system 00:06: [mem 0xfd000000-0xfd68ffff] has been reserved May 2 09:43:37 Sakaar kernel: system 00:06: [mem 0xfd6c0000-0xfd6cffff] has been reserved May 2 09:43:37 Sakaar kernel: system 00:06: [mem 0xfd6f0000-0xfdffffff] has been reserved May 2 09:43:37 Sakaar kernel: system 00:07: [io 0x2000-0x20fe] has been reserved May 2 09:43:37 Sakaar kernel: pnp: PnP ACPI: found 9 devices May 2 09:43:37 Sakaar kernel: clocksource: acpi_pm: mask: 0xffffff max_cycles: 0xffffff, max_idle_ns: 2085701024 ns May 2 09:43:37 Sakaar kernel: NET: Registered PF_INET protocol family May 2 09:43:37 Sakaar kernel: IP idents hash table entries: 262144 (order: 9, 2097152 bytes, linear) May 2 09:43:37 Sakaar kernel: tcp_listen_portaddr_hash hash table entries: 16384 (order: 6, 262144 bytes, linear) May 2 09:43:37 Sakaar kernel: Table-perturb hash table entries: 65536 (order: 6, 262144 bytes, linear) May 2 09:43:37 Sakaar kernel: TCP established hash table entries: 262144 (order: 9, 2097152 bytes, linear) May 2 09:43:37 Sakaar kernel: TCP bind hash table entries: 65536 (order: 9, 2097152 bytes, linear) May 2 09:43:37 Sakaar kernel: TCP: Hash tables configured (established 262144 bind 65536) May 2 09:43:37 Sakaar kernel: UDP hash table entries: 16384 (order: 7, 524288 bytes, linear) May 2 09:43:37 Sakaar kernel: UDP-Lite hash table entries: 16384 (order: 7, 524288 bytes, linear) May 2 09:43:37 Sakaar kernel: pci 0000:00:1d.0: bridge window [io 0x1000-0x0fff] to [bus 06] add_size 1000 May 2 09:43:37 Sakaar kernel: pci 0000:00:1d.0: bridge window [mem 0x00100000-0x000fffff 64bit pref] to [bus 06] add_size 200000 add_align 100000 May 2 09:43:37 Sakaar kernel: pci 0000:00:1d.0: bridge window [mem 0x00100000-0x000fffff] to [bus 06] add_size 200000 add_align 100000 May 2 09:43:37 Sakaar kernel: pci 0000:00:1d.0: BAR 14: assigned [mem 0x3f800000-0x3f9fffff] May 2 09:43:37 Sakaar kernel: pci 0000:00:1d.0: BAR 15: assigned [mem 0x3fa00000-0x3fbfffff 64bit pref] May 2 09:43:37 Sakaar kernel: pci 0000:00:1d.0: BAR 13: assigned [io 0x6000-0x6fff] May 2 09:43:37 Sakaar kernel: pci 0000:00:1f.5: BAR 0: assigned [mem 0x3fc00000-0x3fc00fff] May 2 09:43:37 Sakaar kernel: pci 0000:00:01.0: PCI bridge to [bus 01] May 2 09:43:37 Sakaar kernel: pci 0000:00:01.0: bridge window [io 0x4000-0x4fff] May 2 09:43:37 Sakaar kernel: pci 0000:00:01.0: bridge window [mem 0x63000000-0x640fffff] May 2 09:43:37 Sakaar kernel: pci 0000:00:01.0: bridge window [mem 0x50000000-0x61ffffff 64bit pref] May 2 09:43:37 Sakaar kernel: pci 0000:00:06.0: PCI bridge to [bus 02] May 2 09:43:37 Sakaar kernel: pci 0000:00:06.0: bridge window [mem 0x64700000-0x647fffff] May 2 09:43:37 Sakaar kernel: pci 0000:00:1b.0: PCI bridge to [bus 03] May 2 09:43:37 Sakaar kernel: pci 0000:00:1b.0: bridge window [io 0x3000-0x3fff] May 2 09:43:37 Sakaar kernel: pci 0000:00:1b.0: bridge window [mem 0x64400000-0x645fffff] May 2 09:43:37 Sakaar kernel: pci 0000:00:1c.0: PCI bridge to [bus 04] May 2 09:43:37 Sakaar kernel: pci 0000:00:1c.0: bridge window [mem 0x64200000-0x643fffff] May 2 09:43:37 Sakaar kernel: pci 0000:00:1c.7: PCI bridge to [bus 05] May 2 09:43:37 Sakaar kernel: pci 0000:00:1c.7: bridge window [mem 0x64600000-0x646fffff] May 2 09:43:37 Sakaar kernel: pci 0000:00:1d.0: PCI bridge to [bus 06] May 2 09:43:37 Sakaar kernel: pci 0000:00:1d.0: bridge window [io 0x6000-0x6fff] May 2 09:43:37 Sakaar kernel: pci 0000:00:1d.0: bridge window [mem 0x3f800000-0x3f9fffff] May 2 09:43:37 Sakaar kernel: pci 0000:00:1d.0: bridge window [mem 0x3fa00000-0x3fbfffff 64bit pref] May 2 09:43:37 Sakaar kernel: pci_bus 0000:00: resource 4 [io 0x0000-0x0cf7 window] May 2 09:43:37 Sakaar kernel: pci_bus 0000:00: resource 5 [io 0x0d00-0xffff window] May 2 09:43:37 Sakaar kernel: pci_bus 0000:00: resource 6 [mem 0x000a0000-0x000bffff window] May 2 09:43:37 Sakaar kernel: pci_bus 0000:00: resource 7 [mem 0x3f800000-0xdfffffff window] May 2 09:43:37 Sakaar kernel: pci_bus 0000:01: resource 0 [io 0x4000-0x4fff] May 2 09:43:37 Sakaar kernel: pci_bus 0000:01: resource 1 [mem 0x63000000-0x640fffff] May 2 09:43:37 Sakaar kernel: pci_bus 0000:01: resource 2 [mem 0x50000000-0x61ffffff 64bit pref] May 2 09:43:37 Sakaar kernel: pci_bus 0000:02: resource 1 [mem 0x64700000-0x647fffff] May 2 09:43:37 Sakaar kernel: pci_bus 0000:03: resource 0 [io 0x3000-0x3fff] May 2 09:43:37 Sakaar kernel: pci_bus 0000:03: resource 1 [mem 0x64400000-0x645fffff] May 2 09:43:37 Sakaar kernel: pci_bus 0000:04: resource 1 [mem 0x64200000-0x643fffff] May 2 09:43:37 Sakaar kernel: pci_bus 0000:05: resource 1 [mem 0x64600000-0x646fffff] May 2 09:43:37 Sakaar kernel: pci_bus 0000:06: resource 0 [io 0x6000-0x6fff] May 2 09:43:37 Sakaar kernel: pci_bus 0000:06: resource 1 [mem 0x3f800000-0x3f9fffff] May 2 09:43:37 Sakaar kernel: pci_bus 0000:06: resource 2 [mem 0x3fa00000-0x3fbfffff 64bit pref] May 2 09:43:37 Sakaar kernel: pci 0000:01:00.1: D0 power state depends on 0000:01:00.0 May 2 09:43:37 Sakaar kernel: PCI: CLS 64 bytes, default 64 May 2 09:43:37 Sakaar kernel: DMAR: No ATSR found May 2 09:43:37 Sakaar kernel: DMAR: No SATC found May 2 09:43:37 Sakaar kernel: DMAR: IOMMU feature fl1gp_support inconsistent May 2 09:43:37 Sakaar kernel: DMAR: IOMMU feature pgsel_inv inconsistent May 2 09:43:37 Sakaar kernel: DMAR: IOMMU feature nwfs inconsistent May 2 09:43:37 Sakaar kernel: DMAR: IOMMU feature pds inconsistent May 2 09:43:37 Sakaar kernel: DMAR: IOMMU feature dit inconsistent May 2 09:43:37 Sakaar kernel: DMAR: IOMMU feature eafs inconsistent May 2 09:43:37 Sakaar kernel: DMAR: IOMMU feature prs inconsistent May 2 09:43:37 Sakaar kernel: DMAR: IOMMU feature nest inconsistent May 2 09:43:37 Sakaar kernel: DMAR: IOMMU feature mts inconsistent May 2 09:43:37 Sakaar kernel: DMAR: IOMMU feature sc_support inconsistent May 2 09:43:37 Sakaar kernel: DMAR: IOMMU feature dev_iotlb_support inconsistent May 2 09:43:37 Sakaar kernel: DMAR: dmar0: Using Queued invalidation May 2 09:43:37 Sakaar kernel: DMAR: dmar1: Using Queued invalidation May 2 09:43:37 Sakaar kernel: Unpacking initramfs... May 2 09:43:37 Sakaar kernel: pci 0000:00:02.0: Adding to iommu group 0 May 2 09:43:37 Sakaar kernel: pci 0000:00:00.0: Adding to iommu group 1 May 2 09:43:37 Sakaar kernel: pci 0000:00:01.0: Adding to iommu group 2 May 2 09:43:37 Sakaar kernel: pci 0000:00:06.0: Adding to iommu group 3 May 2 09:43:37 Sakaar kernel: pci 0000:00:14.0: Adding to iommu group 4 May 2 09:43:37 Sakaar kernel: pci 0000:00:14.2: Adding to iommu group 4 May 2 09:43:37 Sakaar kernel: pci 0000:00:16.0: Adding to iommu group 5 May 2 09:43:37 Sakaar kernel: pci 0000:00:17.0: Adding to iommu group 6 May 2 09:43:37 Sakaar kernel: pci 0000:00:1b.0: Adding to iommu group 7 May 2 09:43:37 Sakaar kernel: pci 0000:00:1c.0: Adding to iommu group 8 May 2 09:43:37 Sakaar kernel: pci 0000:00:1c.7: Adding to iommu group 9 May 2 09:43:37 Sakaar kernel: pci 0000:00:1d.0: Adding to iommu group 10 May 2 09:43:37 Sakaar kernel: pci 0000:00:1f.0: Adding to iommu group 11 May 2 09:43:37 Sakaar kernel: pci 0000:00:1f.3: Adding to iommu group 11 May 2 09:43:37 Sakaar kernel: pci 0000:00:1f.4: Adding to iommu group 11 May 2 09:43:37 Sakaar kernel: pci 0000:00:1f.5: Adding to iommu group 11 May 2 09:43:37 Sakaar kernel: pci 0000:01:00.0: Adding to iommu group 12 May 2 09:43:37 Sakaar kernel: pci 0000:01:00.1: Adding to iommu group 12 May 2 09:43:37 Sakaar kernel: pci 0000:02:00.0: Adding to iommu group 13 May 2 09:43:37 Sakaar kernel: pci 0000:03:00.0: Adding to iommu group 14 May 2 09:43:37 Sakaar kernel: pci 0000:04:00.0: Adding to iommu group 15 May 2 09:43:37 Sakaar kernel: pci 0000:05:00.0: Adding to iommu group 16 May 2 09:43:37 Sakaar kernel: DMAR: Intel(R) Virtualization Technology for Directed I/O May 2 09:43:37 Sakaar kernel: PCI-DMA: Using software bounce buffering for IO (SWIOTLB) May 2 09:43:37 Sakaar kernel: software IO TLB: mapped [mem 0x0000000021d64000-0x0000000025d64000] (64MB) May 2 09:43:37 Sakaar kernel: clocksource: tsc: mask: 0xffffffffffffffff max_cycles: 0x33e452fbb2f, max_idle_ns: 440795236593 ns May 2 09:43:37 Sakaar kernel: clocksource: Switched to clocksource tsc May 2 09:43:37 Sakaar kernel: platform rtc_cmos: registered platform RTC device (no PNP device found) May 2 09:43:37 Sakaar kernel: workingset: timestamp_bits=40 max_order=23 bucket_order=0 May 2 09:43:37 Sakaar kernel: squashfs: version 4.0 (2009/01/31) Phillip Lougher May 2 09:43:37 Sakaar kernel: fuse: init (API version 7.37) May 2 09:43:37 Sakaar kernel: xor: automatically using best checksumming function avx May 2 09:43:37 Sakaar kernel: Key type asymmetric registered May 2 09:43:37 Sakaar kernel: Block layer SCSI generic (bsg) driver version 0.4 loaded (major 249) May 2 09:43:37 Sakaar kernel: io scheduler mq-deadline registered May 2 09:43:37 Sakaar kernel: io scheduler kyber registered May 2 09:43:37 Sakaar kernel: io scheduler bfq registered May 2 09:43:37 Sakaar kernel: pcieport 0000:00:01.0: PME: Signaling with IRQ 122 May 2 09:43:37 Sakaar kernel: pcieport 0000:00:01.0: AER: enabled with IRQ 122 May 2 09:43:37 Sakaar kernel: pcieport 0000:00:06.0: PME: Signaling with IRQ 123 May 2 09:43:37 Sakaar kernel: pcieport 0000:00:06.0: AER: enabled with IRQ 123 May 2 09:43:37 Sakaar kernel: pcieport 0000:00:1b.0: PME: Signaling with IRQ 124 May 2 09:43:37 Sakaar kernel: pcieport 0000:00:1b.0: AER: enabled with IRQ 124 May 2 09:43:37 Sakaar kernel: pcieport 0000:00:1c.0: PME: Signaling with IRQ 125 May 2 09:43:37 Sakaar kernel: pcieport 0000:00:1c.0: AER: enabled with IRQ 125 May 2 09:43:37 Sakaar kernel: pcieport 0000:00:1c.7: PME: Signaling with IRQ 126 May 2 09:43:37 Sakaar kernel: pcieport 0000:00:1c.7: AER: enabled with IRQ 126 May 2 09:43:37 Sakaar kernel: pcieport 0000:00:1d.0: PME: Signaling with IRQ 127 May 2 09:43:37 Sakaar kernel: Monitor-Mwait will be used to enter C-1 state May 2 09:43:37 Sakaar kernel: Monitor-Mwait will be used to enter C-2 state May 2 09:43:37 Sakaar kernel: Monitor-Mwait will be used to enter C-3 state May 2 09:43:37 Sakaar kernel: ACPI: \_SB_.PR00: Found 3 idle states May 2 09:43:37 Sakaar kernel: IPMI message handler: version 39.2 May 2 09:43:37 Sakaar kernel: Serial: 8250/16550 driver, 4 ports, IRQ sharing disabled May 2 09:43:37 Sakaar kernel: 00:01: ttyS0 at I/O 0x3f8 (irq = 4, base_baud = 115200) is a 16550A May 2 09:43:37 Sakaar kernel: Freeing initrd memory: 23540K May 2 09:43:37 Sakaar kernel: lp: driver loaded but no devices found May 2 09:43:37 Sakaar kernel: Hangcheck: starting hangcheck timer 0.9.1 (tick is 180 seconds, margin is 60 seconds). May 2 09:43:37 Sakaar kernel: AMD-Vi: AMD IOMMUv2 functionality not available on this system - This is not a bug. May 2 09:43:37 Sakaar kernel: Floppy drive(s): fd0 is unknown type 15 (usb?), fd1 is unknown type 13 (usb?) May 2 09:43:37 Sakaar kernel: loop: module loaded May 2 09:43:37 Sakaar kernel: Rounding down aligned max_sectors from 4294967295 to 4294967288 May 2 09:43:37 Sakaar kernel: db_root: cannot open: /etc/target May 2 09:43:37 Sakaar kernel: VFIO - User Level meta-driver version: 0.3 May 2 09:43:37 Sakaar kernel: xhci_hcd 0000:00:14.0: xHCI Host Controller May 2 09:43:37 Sakaar kernel: xhci_hcd 0000:00:14.0: new USB bus registered, assigned bus number 1 May 2 09:43:37 Sakaar kernel: xhci_hcd 0000:00:14.0: hcc params 0x20007fc1 hci version 0x120 quirks 0x0000000200009810 May 2 09:43:37 Sakaar kernel: xhci_hcd 0000:00:14.0: xHCI Host Controller May 2 09:43:37 Sakaar kernel: xhci_hcd 0000:00:14.0: new USB bus registered, assigned bus number 2 May 2 09:43:37 Sakaar kernel: xhci_hcd 0000:00:14.0: Host supports USB 3.2 Enhanced SuperSpeed May 2 09:43:37 Sakaar kernel: hub 1-0:1.0: USB hub found May 2 09:43:37 Sakaar kernel: hub 1-0:1.0: 16 ports detected May 2 09:43:37 Sakaar kernel: hub 2-0:1.0: USB hub found May 2 09:43:37 Sakaar kernel: hub 2-0:1.0: 5 ports detected May 2 09:43:37 Sakaar kernel: usbcore: registered new interface driver usb-storage May 2 09:43:37 Sakaar kernel: i8042: PNP: No PS/2 controller found. May 2 09:43:37 Sakaar kernel: mousedev: PS/2 mouse device common for all mice May 2 09:43:37 Sakaar kernel: usbcore: registered new interface driver synaptics_usb May 2 09:43:37 Sakaar kernel: input: PC Speaker as /devices/platform/pcspkr/input/input0 May 2 09:43:37 Sakaar kernel: rtc_cmos rtc_cmos: RTC can wake from S4 May 2 09:43:37 Sakaar kernel: rtc_cmos rtc_cmos: registered as rtc0 May 2 09:43:37 Sakaar kernel: rtc_cmos rtc_cmos: setting system clock to 2023-05-02T08:43:07 UTC (1683016987) May 2 09:43:37 Sakaar kernel: rtc_cmos rtc_cmos: alarms up to one month, y3k, 114 bytes nvram May 2 09:43:37 Sakaar kernel: intel_pstate: Intel P-state driver initializing May 2 09:43:37 Sakaar kernel: intel_pstate: HWP enabled May 2 09:43:37 Sakaar kernel: efifb: probing for efifb May 2 09:43:37 Sakaar kernel: efifb: framebuffer at 0x40000000, using 8100k, total 8100k May 2 09:43:37 Sakaar kernel: efifb: mode is 1920x1080x32, linelength=7680, pages=1 May 2 09:43:37 Sakaar kernel: efifb: scrolling: redraw May 2 09:43:37 Sakaar kernel: efifb: Truecolor: size=8:8:8:8, shift=24:16:8:0 May 2 09:43:37 Sakaar kernel: Console: switching to colour frame buffer device 240x67 May 2 09:43:37 Sakaar kernel: fb0: EFI VGA frame buffer device May 2 09:43:37 Sakaar kernel: pstore: Registered efi as persistent store backend May 2 09:43:37 Sakaar kernel: hid: raw HID events driver (C) Jiri Kosina May 2 09:43:37 Sakaar kernel: usbcore: registered new interface driver usbhid May 2 09:43:37 Sakaar kernel: usbhid: USB HID core driver May 2 09:43:37 Sakaar kernel: ipip: IPv4 and MPLS over IPv4 tunneling driver May 2 09:43:37 Sakaar kernel: NET: Registered PF_INET6 protocol family May 2 09:43:37 Sakaar kernel: Segment Routing with IPv6 May 2 09:43:37 Sakaar kernel: RPL Segment Routing with IPv6 May 2 09:43:37 Sakaar kernel: In-situ OAM (IOAM) with IPv6 May 2 09:43:37 Sakaar kernel: 9pnet: Installing 9P2000 support May 2 09:43:37 Sakaar kernel: microcode: sig=0xa0671, pf=0x2, revision=0x57 May 2 09:43:37 Sakaar kernel: microcode: Microcode Update Driver: v2.2. May 2 09:43:37 Sakaar kernel: IPI shorthand broadcast: enabled May 2 09:43:37 Sakaar kernel: sched_clock: Marking stable (2738800534, 4673934)->(2751986437, -8511969) May 2 09:43:37 Sakaar kernel: registered taskstats version 1 May 2 09:43:37 Sakaar kernel: Btrfs loaded, crc32c=crc32c-generic, zoned=no, fsverity=no May 2 09:43:37 Sakaar kernel: pstore: Using crash dump compression: deflate May 2 09:43:37 Sakaar kernel: usb 1-4: new high-speed USB device number 2 using xhci_hcd May 2 09:43:37 Sakaar kernel: hub 1-4:1.0: USB hub found May 2 09:43:37 Sakaar kernel: hub 1-4:1.0: 4 ports detected May 2 09:43:37 Sakaar kernel: usb 2-3: new SuperSpeed USB device number 2 using xhci_hcd May 2 09:43:37 Sakaar kernel: hub 2-3:1.0: USB hub found May 2 09:43:37 Sakaar kernel: hub 2-3:1.0: 4 ports detected May 2 09:43:37 Sakaar kernel: usb 1-8: new full-speed USB device number 3 using xhci_hcd May 2 09:43:37 Sakaar kernel: hid-generic 0003:051D:0003.0001: hiddev96,hidraw0: USB HID v1.11 Device [American Power Conversion Smart-UPS_1000 FW:UPS 04.6 / ID=1018] on usb-0000:00:14.0-8/input0 May 2 09:43:37 Sakaar kernel: usb 1-9: new high-speed USB device number 4 using xhci_hcd May 2 09:43:37 Sakaar kernel: hub 1-9:1.0: USB hub found May 2 09:43:37 Sakaar kernel: hub 1-9:1.0: 4 ports detected May 2 09:43:37 Sakaar kernel: usb 1-10: new high-speed USB device number 5 using xhci_hcd May 2 09:43:37 Sakaar kernel: hub 1-10:1.0: USB hub found May 2 09:43:37 Sakaar kernel: hub 1-10:1.0: 4 ports detected May 2 09:43:37 Sakaar kernel: usb 1-9.1: new high-speed USB device number 6 using xhci_hcd May 2 09:43:37 Sakaar kernel: usb-storage 1-9.1:1.0: USB Mass Storage device detected May 2 09:43:37 Sakaar kernel: scsi host0: usb-storage 1-9.1:1.0 May 2 09:43:37 Sakaar kernel: usb 1-11: new full-speed USB device number 7 using xhci_hcd May 2 09:43:37 Sakaar kernel: hid-generic 0003:048D:5702.0002: hiddev97,hidraw1: USB HID v1.12 Device [ITE Tech. Inc. ITE Device] on usb-0000:00:14.0-11/input0 May 2 09:43:37 Sakaar kernel: usb 1-9.2: new high-speed USB device number 8 using xhci_hcd May 2 09:43:37 Sakaar kernel: input: PiKVM Composite KVM Device as /devices/pci0000:00/0000:00:14.0/usb1/1-9/1-9.2/1-9.2:1.0/0003:1D6B:0104.0003/input/input1 May 2 09:43:37 Sakaar kernel: hid-generic 0003:1D6B:0104.0003: input,hidraw2: USB HID v1.01 Keyboard [PiKVM Composite KVM Device] on usb-0000:00:14.0-9.2/input0 May 2 09:43:37 Sakaar kernel: input: PiKVM Composite KVM Device as /devices/pci0000:00/0000:00:14.0/usb1/1-9/1-9.2/1-9.2:1.1/0003:1D6B:0104.0004/input/input2 May 2 09:43:37 Sakaar kernel: hid-generic 0003:1D6B:0104.0004: input,hidraw3: USB HID v1.01 Mouse [PiKVM Composite KVM Device] on usb-0000:00:14.0-9.2/input1 May 2 09:43:37 Sakaar kernel: input: PiKVM Composite KVM Device as /devices/pci0000:00/0000:00:14.0/usb1/1-9/1-9.2/1-9.2:1.2/0003:1D6B:0104.0005/input/input3 May 2 09:43:37 Sakaar kernel: hid-generic 0003:1D6B:0104.0005: input,hidraw4: USB HID v1.01 Mouse [PiKVM Composite KVM Device] on usb-0000:00:14.0-9.2/input2 May 2 09:43:37 Sakaar kernel: usb-storage 1-9.2:1.3: USB Mass Storage device detected May 2 09:43:37 Sakaar kernel: scsi host1: usb-storage 1-9.2:1.3 May 2 09:43:37 Sakaar kernel: usb 1-14: new full-speed USB device number 9 using xhci_hcd May 2 09:43:37 Sakaar kernel: scsi 0:0:0:0: Direct-Access SanDisk' Cruzer Fit 1.00 PQ: 0 ANSI: 6 May 2 09:43:37 Sakaar kernel: sd 0:0:0:0: Attached scsi generic sg0 type 0 May 2 09:43:37 Sakaar kernel: sd 0:0:0:0: [sda] 121061376 512-byte logical blocks: (62.0 GB/57.7 GiB) May 2 09:43:37 Sakaar kernel: sd 0:0:0:0: [sda] Write Protect is off May 2 09:43:37 Sakaar kernel: sd 0:0:0:0: [sda] Mode Sense: 43 00 00 00 May 2 09:43:37 Sakaar kernel: sd 0:0:0:0: [sda] Write cache: disabled, read cache: enabled, doesn't support DPO or FUA May 2 09:43:37 Sakaar kernel: sda: sda1 May 2 09:43:37 Sakaar kernel: sd 0:0:0:0: [sda] Attached SCSI removable disk May 2 09:43:37 Sakaar kernel: scsi 1:0:0:0: Direct-Access PiKVM CD-ROM Drive 0515 PQ: 0 ANSI: 2 May 2 09:43:37 Sakaar kernel: sd 1:0:0:0: Attached scsi generic sg1 type 0 May 2 09:43:37 Sakaar kernel: sd 1:0:0:0: Power-on or device reset occurred May 2 09:43:37 Sakaar kernel: sd 1:0:0:0: [sdb] Media removed, stopped polling May 2 09:43:37 Sakaar kernel: sd 1:0:0:0: [sdb] Attached SCSI removable disk May 2 09:43:37 Sakaar kernel: floppy0: no floppy controllers found May 2 09:43:37 Sakaar kernel: Freeing unused kernel image (initmem) memory: 1864K May 2 09:43:37 Sakaar kernel: Write protecting the kernel read-only data: 18432k May 2 09:43:37 Sakaar kernel: Freeing unused kernel image (text/rodata gap) memory: 2040K May 2 09:43:37 Sakaar kernel: Freeing unused kernel image (rodata/data gap) memory: 448K May 2 09:43:37 Sakaar kernel: rodata_test: all tests were successful May 2 09:43:37 Sakaar kernel: Run /init as init process May 2 09:43:37 Sakaar kernel: with arguments: May 2 09:43:37 Sakaar kernel: /init May 2 09:43:37 Sakaar kernel: with environment: May 2 09:43:37 Sakaar kernel: HOME=/ May 2 09:43:37 Sakaar kernel: TERM=linux May 2 09:43:37 Sakaar kernel: BOOT_IMAGE=/bzimage May 2 09:43:37 Sakaar kernel: random: crng init done May 2 09:43:37 Sakaar kernel: loop0: detected capacity change from 0 to 121440 May 2 09:43:37 Sakaar kernel: loop1: detected capacity change from 0 to 732024 May 2 09:43:37 Sakaar kernel: NET: Registered PF_UNIX/PF_LOCAL protocol family May 2 09:43:37 Sakaar kernel: Console: switching to colour dummy device 80x25 May 2 09:43:37 Sakaar kernel: vfio-pci 0000:01:00.0: vgaarb: changed VGA decodes: olddecodes=io+mem,decodes=io+mem:owns=none May 2 09:43:37 Sakaar kernel: input: Sleep Button as /devices/LNXSYSTM:00/LNXSYBUS:00/PNP0C0E:00/input/input4 May 2 09:43:37 Sakaar kernel: ACPI: button: Sleep Button [SLPB] May 2 09:43:37 Sakaar kernel: input: Power Button as /devices/LNXSYSTM:00/LNXSYBUS:00/PNP0C0C:00/input/input5 May 2 09:43:37 Sakaar kernel: ACPI: button: Power Button [PWRB] May 2 09:43:37 Sakaar kernel: input: Power Button as /devices/LNXSYSTM:00/LNXPWRBN:00/input/input6 May 2 09:43:37 Sakaar kernel: intel_pmc_core INT33A1:00: initialized May 2 09:43:37 Sakaar kernel: ACPI: button: Power Button [PWRF] May 2 09:43:37 Sakaar kernel: ahci 0000:00:17.0: version 3.0 May 2 09:43:37 Sakaar kernel: Intel(R) 2.5G Ethernet Linux Driver May 2 09:43:37 Sakaar kernel: Copyright(c) 2018 Intel Corporation. May 2 09:43:37 Sakaar kernel: Linux agpgart interface v0.103 May 2 09:43:37 Sakaar kernel: igc 0000:04:00.0: PCIe PTM not supported by PCIe bus/controller May 2 09:43:37 Sakaar kernel: nvme 0000:02:00.0: platform quirk: setting simple suspend May 2 09:43:37 Sakaar kernel: i801_smbus 0000:00:1f.4: SPD Write Disable is set May 2 09:43:37 Sakaar kernel: i801_smbus 0000:00:1f.4: SMBus using PCI interrupt May 2 09:43:37 Sakaar kernel: nvme nvme0: pci function 0000:02:00.0 May 2 09:43:37 Sakaar kernel: mei_me 0000:00:16.0: enabling device (0000 -> 0002) May 2 09:43:37 Sakaar kernel: i2c i2c-0: 2/4 memory slots populated (from DMI) May 2 09:43:37 Sakaar kernel: i2c i2c-0: Successfully instantiated SPD at 0x51 May 2 09:43:37 Sakaar kernel: i2c i2c-0: Successfully instantiated SPD at 0x53 May 2 09:43:37 Sakaar kernel: ahci 0000:00:17.0: AHCI 0001.0301 32 slots 6 ports 6 Gbps 0x3f impl SATA mode May 2 09:43:37 Sakaar kernel: ahci 0000:00:17.0: flags: 64bit ncq sntf clo only pio slum part ems deso sadm sds May 2 09:43:37 Sakaar kernel: scsi host2: ahci May 2 09:43:37 Sakaar kernel: scsi host3: ahci May 2 09:43:37 Sakaar kernel: scsi host4: ahci May 2 09:43:37 Sakaar kernel: scsi host5: ahci May 2 09:43:37 Sakaar kernel: scsi host6: ahci May 2 09:43:37 Sakaar kernel: scsi host7: ahci May 2 09:43:37 Sakaar kernel: ata1: SATA max UDMA/133 abar m2048@0x6481b000 port 0x6481b100 irq 129 May 2 09:43:37 Sakaar kernel: ata2: SATA max UDMA/133 abar m2048@0x6481b000 port 0x6481b180 irq 129 May 2 09:43:37 Sakaar kernel: ata3: SATA max UDMA/133 abar m2048@0x6481b000 port 0x6481b200 irq 129 May 2 09:43:37 Sakaar kernel: ata4: SATA max UDMA/133 abar m2048@0x6481b000 port 0x6481b280 irq 129 May 2 09:43:37 Sakaar kernel: ata5: SATA max UDMA/133 abar m2048@0x6481b000 port 0x6481b300 irq 129 May 2 09:43:37 Sakaar kernel: ata6: SATA max UDMA/133 abar m2048@0x6481b000 port 0x6481b380 irq 129 May 2 09:43:37 Sakaar kernel: nvme nvme0: allocated 32 MiB host memory buffer. May 2 09:43:37 Sakaar kernel: nvme nvme0: 16/0/0 default/read/poll queues May 2 09:43:37 Sakaar kernel: nvme0n1: p1 May 2 09:43:37 Sakaar kernel: pps pps0: new PPS source ptp0 May 2 09:43:37 Sakaar kernel: igc 0000:04:00.0 (unnamed net_device) (uninitialized): PHC added May 2 09:43:37 Sakaar kernel: mpt3sas version 43.100.00.00 loaded May 2 09:43:37 Sakaar kernel: mpt3sas 0000:03:00.0: can't disable ASPM; OS doesn't have ASPM control May 2 09:43:37 Sakaar kernel: mpt2sas_cm0: 64 BIT PCI BUS DMA ADDRESSING SUPPORTED, total mem (32673140 kB) May 2 09:43:37 Sakaar kernel: Bluetooth: Core ver 2.22 May 2 09:43:37 Sakaar kernel: NET: Registered PF_BLUETOOTH protocol family May 2 09:43:37 Sakaar kernel: Bluetooth: HCI device and connection manager initialized May 2 09:43:37 Sakaar kernel: Bluetooth: HCI socket layer initialized May 2 09:43:37 Sakaar kernel: Bluetooth: L2CAP socket layer initialized May 2 09:43:37 Sakaar kernel: Bluetooth: SCO socket layer initialized May 2 09:43:37 Sakaar kernel: igc 0000:04:00.0: 4.000 Gb/s available PCIe bandwidth (5.0 GT/s PCIe x1 link) May 2 09:43:37 Sakaar kernel: igc 0000:04:00.0 eth0: MAC: 18:c0:4d:eb:92:60 May 2 09:43:37 Sakaar kernel: mpt2sas_cm0: CurrentHostPageSize is 0: Setting default host page size to 4k May 2 09:43:37 Sakaar kernel: mpt2sas_cm0: MSI-X vectors supported: 16 May 2 09:43:37 Sakaar kernel: no of cores: 16, max_msix_vectors: -1 May 2 09:43:37 Sakaar kernel: mpt2sas_cm0: 0 16 16 May 2 09:43:37 Sakaar kernel: mpt2sas_cm0: High IOPs queues : disabled May 2 09:43:37 Sakaar kernel: mpt2sas0-msix0: PCI-MSI-X enabled: IRQ 153 May 2 09:43:37 Sakaar kernel: mpt2sas0-msix1: PCI-MSI-X enabled: IRQ 154 May 2 09:43:37 Sakaar kernel: mpt2sas0-msix2: PCI-MSI-X enabled: IRQ 155 May 2 09:43:37 Sakaar kernel: mpt2sas0-msix3: PCI-MSI-X enabled: IRQ 156 May 2 09:43:37 Sakaar kernel: mpt2sas0-msix4: PCI-MSI-X enabled: IRQ 157 May 2 09:43:37 Sakaar kernel: mpt2sas0-msix5: PCI-MSI-X enabled: IRQ 158 May 2 09:43:37 Sakaar kernel: mpt2sas0-msix6: PCI-MSI-X enabled: IRQ 159 May 2 09:43:37 Sakaar kernel: mpt2sas0-msix7: PCI-MSI-X enabled: IRQ 160 May 2 09:43:37 Sakaar kernel: mpt2sas0-msix8: PCI-MSI-X enabled: IRQ 161 May 2 09:43:37 Sakaar kernel: mpt2sas0-msix9: PCI-MSI-X enabled: IRQ 162 May 2 09:43:37 Sakaar kernel: mpt2sas0-msix10: PCI-MSI-X enabled: IRQ 163 May 2 09:43:37 Sakaar kernel: mpt2sas0-msix11: PCI-MSI-X enabled: IRQ 164 May 2 09:43:37 Sakaar kernel: mpt2sas0-msix12: PCI-MSI-X enabled: IRQ 165 May 2 09:43:37 Sakaar kernel: mpt2sas0-msix13: PCI-MSI-X enabled: IRQ 166 May 2 09:43:37 Sakaar kernel: mpt2sas0-msix14: PCI-MSI-X enabled: IRQ 167 May 2 09:43:37 Sakaar kernel: mpt2sas0-msix15: PCI-MSI-X enabled: IRQ 168 May 2 09:43:37 Sakaar kernel: mpt2sas_cm0: iomem(0x0000000064540000), mapped(0x0000000010710498), size(65536) May 2 09:43:37 Sakaar kernel: mpt2sas_cm0: ioport(0x0000000000003000), size(256) May 2 09:43:37 Sakaar kernel: mpt2sas_cm0: CurrentHostPageSize is 0: Setting default host page size to 4k May 2 09:43:37 Sakaar kernel: mpt2sas_cm0: sending message unit reset !! May 2 09:43:37 Sakaar kernel: mpt2sas_cm0: message unit reset: SUCCESS May 2 09:43:37 Sakaar kernel: mpt2sas_cm0: scatter gather: sge_in_main_msg(1), sge_per_chain(9), sge_per_io(128), chains_per_io(15) May 2 09:43:37 Sakaar kernel: mpt2sas_cm0: request pool(0x0000000031a7746d) - dma(0x130000000): depth(10261), frame_size(128), pool_size(1282 kB) May 2 09:43:37 Sakaar kernel: mpt2sas_cm0: sense pool(0x00000000dfe46fd4) - dma(0x131900000): depth(10000), element_size(96), pool_size (937 kB) May 2 09:43:37 Sakaar kernel: mpt2sas_cm0: reply pool(0x0000000043e3b107) - dma(0x130200000): depth(10325), frame_size(128), pool_size(1290 kB) May 2 09:43:37 Sakaar kernel: mpt2sas_cm0: config page(0x0000000045815e53) - dma(0x131843000): size(512) May 2 09:43:37 Sakaar kernel: mpt2sas_cm0: Allocated physical memory: size(24875 kB) May 2 09:43:37 Sakaar kernel: mpt2sas_cm0: Current Controller Queue Depth(9997),Max Controller Queue Depth(10240) May 2 09:43:37 Sakaar kernel: mpt2sas_cm0: Scatter Gather Elements per IO(128) May 2 09:43:37 Sakaar kernel: mpt2sas_cm0: LSISAS2308: FWVersion(20.00.02.00), ChipRevision(0x05), BiosVersion(07.39.00.00) May 2 09:43:37 Sakaar kernel: mpt2sas_cm0: Protocol=(Initiator,Target), Capabilities=(TLR,EEDP,Snapshot Buffer,Diag Trace Buffer,Task Set Full,NCQ) May 2 09:43:37 Sakaar kernel: scsi host8: Fusion MPT SAS Host May 2 09:43:37 Sakaar kernel: mpt2sas_cm0: sending port enable !! May 2 09:43:37 Sakaar kernel: mpt2sas_cm0: hba_port entry: 00000000300d9fba, port: 255 is added to hba_port list May 2 09:43:37 Sakaar kernel: mpt2sas_cm0: host_add: handle(0x0001), sas_addr(0x500605b00a007010), phys(8) May 2 09:43:37 Sakaar kernel: mpt2sas_cm0: handle(0x9) sas_address(0x4433221100000000) port_type(0x1) May 2 09:43:37 Sakaar kernel: mpt2sas_cm0: handle(0xa) sas_address(0x4433221101000000) port_type(0x1) May 2 09:43:37 Sakaar kernel: mpt2sas_cm0: handle(0xc) sas_address(0x4433221102000000) port_type(0x1) May 2 09:43:37 Sakaar kernel: mpt2sas_cm0: handle(0xb) sas_address(0x4433221103000000) port_type(0x1) May 2 09:43:37 Sakaar kernel: mpt2sas_cm0: handle(0xe) sas_address(0x4433221104000000) port_type(0x1) May 2 09:43:37 Sakaar kernel: mpt2sas_cm0: handle(0xd) sas_address(0x4433221105000000) port_type(0x1) May 2 09:43:37 Sakaar kernel: mpt2sas_cm0: handle(0xf) sas_address(0x4433221106000000) port_type(0x1) May 2 09:43:37 Sakaar kernel: mpt2sas_cm0: handle(0x10) sas_address(0x4433221107000000) port_type(0x1) May 2 09:43:37 Sakaar kernel: mpt2sas_cm0: port enable: SUCCESS May 2 09:43:37 Sakaar kernel: scsi 8:0:0:0: Direct-Access ATA TOSHIBA HDWN160 FS1M PQ: 0 ANSI: 6 May 2 09:43:37 Sakaar kernel: scsi 8:0:0:0: SATA: handle(0x000b), sas_addr(0x4433221103000000), phy(3), device_name(0x500003995b9818a8) May 2 09:43:37 Sakaar kernel: scsi 8:0:0:0: enclosure logical id (0x500605b00a007010), slot(0) May 2 09:43:37 Sakaar kernel: scsi 8:0:0:0: atapi(n), ncq(y), asyn_notify(n), smart(y), fua(y), sw_preserve(y) May 2 09:43:37 Sakaar kernel: scsi 8:0:0:0: qdepth(32), tagged(1), scsi_level(7), cmd_que(1) May 2 09:43:37 Sakaar kernel: scsi 8:0:0:0: Attached scsi generic sg2 type 0 May 2 09:43:37 Sakaar kernel: end_device-8:0: add: handle(0x000b), sas_addr(0x4433221103000000) May 2 09:43:37 Sakaar kernel: sd 8:0:0:0: [sdc] 11721045168 512-byte logical blocks: (6.00 TB/5.46 TiB) May 2 09:43:37 Sakaar kernel: sd 8:0:0:0: [sdc] 4096-byte physical blocks May 2 09:43:37 Sakaar kernel: scsi 8:0:1:0: Direct-Access ATA TOSHIBA HDWG21C 0601 PQ: 0 ANSI: 6 May 2 09:43:37 Sakaar kernel: scsi 8:0:1:0: SATA: handle(0x0009), sas_addr(0x4433221100000000), phy(0), device_name(0x5000039b58e14d3b) May 2 09:43:37 Sakaar kernel: scsi 8:0:1:0: enclosure logical id (0x500605b00a007010), slot(3) May 2 09:43:37 Sakaar kernel: scsi 8:0:1:0: atapi(n), ncq(y), asyn_notify(n), smart(y), fua(y), sw_preserve(y) May 2 09:43:37 Sakaar kernel: scsi 8:0:1:0: qdepth(32), tagged(1), scsi_level(7), cmd_que(1) May 2 09:43:37 Sakaar kernel: scsi 8:0:1:0: Attached scsi generic sg3 type 0 May 2 09:43:37 Sakaar kernel: end_device-8:1: add: handle(0x0009), sas_addr(0x4433221100000000) May 2 09:43:37 Sakaar kernel: sd 8:0:1:0: [sdd] 23437770752 512-byte logical blocks: (12.0 TB/10.9 TiB) May 2 09:43:37 Sakaar kernel: sd 8:0:1:0: [sdd] 4096-byte physical blocks May 2 09:43:37 Sakaar kernel: scsi 8:0:2:0: Direct-Access ATA TOSHIBA HDWG11A 0603 PQ: 0 ANSI: 6 May 2 09:43:37 Sakaar kernel: scsi 8:0:2:0: SATA: handle(0x000a), sas_addr(0x4433221101000000), phy(1), device_name(0x5000039b38c98f9f) May 2 09:43:37 Sakaar kernel: scsi 8:0:2:0: enclosure logical id (0x500605b00a007010), slot(2) May 2 09:43:37 Sakaar kernel: scsi 8:0:2:0: atapi(n), ncq(y), asyn_notify(n), smart(y), fua(y), sw_preserve(y) May 2 09:43:37 Sakaar kernel: scsi 8:0:2:0: qdepth(32), tagged(1), scsi_level(7), cmd_que(1) May 2 09:43:37 Sakaar kernel: sd 8:0:1:0: [sdd] Write Protect is off May 2 09:43:37 Sakaar kernel: sd 8:0:1:0: [sdd] Mode Sense: 7f 00 10 08 May 2 09:43:37 Sakaar kernel: sd 8:0:1:0: [sdd] Write cache: enabled, read cache: enabled, supports DPO and FUA May 2 09:43:37 Sakaar kernel: sd 8:0:2:0: Attached scsi generic sg4 type 0 May 2 09:43:37 Sakaar kernel: end_device-8:2: add: handle(0x000a), sas_addr(0x4433221101000000) May 2 09:43:37 Sakaar kernel: sd 8:0:2:0: [sde] 19532873728 512-byte logical blocks: (10.0 TB/9.10 TiB) May 2 09:43:37 Sakaar kernel: sd 8:0:2:0: [sde] 4096-byte physical blocks May 2 09:43:37 Sakaar kernel: sd 8:0:2:0: [sde] Write Protect is off May 2 09:43:37 Sakaar kernel: sd 8:0:2:0: [sde] Mode Sense: 7f 00 10 08 May 2 09:43:37 Sakaar kernel: sd 8:0:2:0: [sde] Write cache: enabled, read cache: enabled, supports DPO and FUA May 2 09:43:37 Sakaar kernel: ata4: SATA link down (SStatus 4 SControl 300) May 2 09:43:37 Sakaar kernel: ata5: SATA link up 6.0 Gbps (SStatus 133 SControl 300) May 2 09:43:37 Sakaar kernel: ata2: SATA link down (SStatus 4 SControl 300) May 2 09:43:37 Sakaar kernel: ata6: SATA link up 1.5 Gbps (SStatus 113 SControl 300) May 2 09:43:37 Sakaar kernel: ata1: SATA link down (SStatus 4 SControl 300) May 2 09:43:37 Sakaar kernel: ata3: SATA link down (SStatus 4 SControl 300) May 2 09:43:37 Sakaar kernel: ata5.00: ATA-9: Samsung SSD 840 Series, DXT07B0Q, max UDMA/133 May 2 09:43:37 Sakaar kernel: ata5.00: NCQ Send/Recv Log not supported May 2 09:43:37 Sakaar kernel: ata5.00: 234441648 sectors, multi 16: LBA48 NCQ (depth 32), AA May 2 09:43:37 Sakaar kernel: ata5.00: Features: Dev-Sleep May 2 09:43:37 Sakaar kernel: ata5.00: NCQ Send/Recv Log not supported May 2 09:43:37 Sakaar kernel: ata5.00: configured for UDMA/133 May 2 09:43:37 Sakaar kernel: scsi 6:0:0:0: Direct-Access ATA Samsung SSD 840 7B0Q PQ: 0 ANSI: 5 May 2 09:43:37 Sakaar kernel: sd 6:0:0:0: Attached scsi generic sg5 type 0 May 2 09:43:37 Sakaar kernel: ata5.00: Enabling discard_zeroes_data May 2 09:43:37 Sakaar kernel: sd 6:0:0:0: [sdf] 234441648 512-byte logical blocks: (120 GB/112 GiB) May 2 09:43:37 Sakaar kernel: sd 6:0:0:0: [sdf] Write Protect is off May 2 09:43:37 Sakaar kernel: sd 6:0:0:0: [sdf] Mode Sense: 00 3a 00 00 May 2 09:43:37 Sakaar kernel: sd 6:0:0:0: [sdf] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA May 2 09:43:37 Sakaar kernel: sd 6:0:0:0: [sdf] Preferred minimum I/O size 512 bytes May 2 09:43:37 Sakaar kernel: ata5.00: Enabling discard_zeroes_data May 2 09:43:37 Sakaar kernel: ata6.00: ATAPI: PIONEER BD-RW BDRUD03AS, 1.00, max UDMA/100 May 2 09:43:37 Sakaar kernel: sdd: sdd1 May 2 09:43:37 Sakaar kernel: sd 8:0:1:0: [sdd] Attached SCSI disk May 2 09:43:37 Sakaar kernel: sdf: sdf1 May 2 09:43:37 Sakaar kernel: sd 6:0:0:0: [sdf] Attached SCSI disk May 2 09:43:37 Sakaar kernel: scsi 8:0:3:0: Direct-Access ATA ST6000VN0033-2EE SC60 PQ: 0 ANSI: 6 May 2 09:43:37 Sakaar kernel: scsi 8:0:3:0: SATA: handle(0x000c), sas_addr(0x4433221102000000), phy(2), device_name(0x5000c500b354f00e) May 2 09:43:37 Sakaar kernel: scsi 8:0:3:0: enclosure logical id (0x500605b00a007010), slot(1) May 2 09:43:37 Sakaar kernel: scsi 8:0:3:0: atapi(n), ncq(y), asyn_notify(n), smart(y), fua(y), sw_preserve(y) May 2 09:43:37 Sakaar kernel: scsi 8:0:3:0: qdepth(32), tagged(1), scsi_level(7), cmd_que(1) May 2 09:43:37 Sakaar kernel: ata6.00: configured for UDMA/100 May 2 09:43:37 Sakaar kernel: sde: sde1 May 2 09:43:37 Sakaar kernel: sd 8:0:2:0: [sde] Attached SCSI disk May 2 09:43:37 Sakaar kernel: scsi 7:0:0:0: CD-ROM PIONEER BD-RW BDRUD03AS 1.00 PQ: 0 ANSI: 5 May 2 09:43:37 Sakaar kernel: sd 8:0:3:0: Attached scsi generic sg6 type 0 May 2 09:43:37 Sakaar kernel: end_device-8:3: add: handle(0x000c), sas_addr(0x4433221102000000) May 2 09:43:37 Sakaar kernel: sd 8:0:3:0: [sdg] 11721045168 512-byte logical blocks: (6.00 TB/5.46 TiB) May 2 09:43:37 Sakaar kernel: sd 8:0:3:0: [sdg] 4096-byte physical blocks May 2 09:43:37 Sakaar kernel: scsi 8:0:4:0: Direct-Access ATA ST12000VN0008-2Y SC60 PQ: 0 ANSI: 6 May 2 09:43:37 Sakaar kernel: scsi 8:0:4:0: SATA: handle(0x000e), sas_addr(0x4433221104000000), phy(4), device_name(0x5000c500e48c5634) May 2 09:43:37 Sakaar kernel: scsi 8:0:4:0: enclosure logical id (0x500605b00a007010), slot(7) May 2 09:43:37 Sakaar kernel: scsi 8:0:4:0: atapi(n), ncq(y), asyn_notify(n), smart(y), fua(y), sw_preserve(y) May 2 09:43:37 Sakaar kernel: scsi 8:0:4:0: qdepth(32), tagged(1), scsi_level(7), cmd_que(1) May 2 09:43:37 Sakaar kernel: scsi 7:0:0:0: Attached scsi generic sg7 type 5 May 2 09:43:37 Sakaar kernel: sd 8:0:4:0: Attached scsi generic sg8 type 0 May 2 09:43:37 Sakaar kernel: end_device-8:4: add: handle(0x000e), sas_addr(0x4433221104000000) May 2 09:43:37 Sakaar kernel: sd 8:0:4:0: [sdh] 23437770752 512-byte logical blocks: (12.0 TB/10.9 TiB) May 2 09:43:37 Sakaar kernel: sd 8:0:4:0: [sdh] 4096-byte physical blocks May 2 09:43:37 Sakaar kernel: sd 8:0:4:0: [sdh] Write Protect is off May 2 09:43:37 Sakaar kernel: sd 8:0:4:0: [sdh] Mode Sense: 7f 00 10 08 May 2 09:43:37 Sakaar kernel: scsi 8:0:5:0: Direct-Access ATA TOSHIBA MG06ACA1 0104 PQ: 0 ANSI: 6 May 2 09:43:37 Sakaar kernel: scsi 8:0:5:0: SATA: handle(0x000d), sas_addr(0x4433221105000000), phy(5), device_name(0x5000039a08c8efa7) May 2 09:43:37 Sakaar kernel: scsi 8:0:5:0: enclosure logical id (0x500605b00a007010), slot(6) May 2 09:43:37 Sakaar kernel: scsi 8:0:5:0: atapi(n), ncq(y), asyn_notify(n), smart(y), fua(y), sw_preserve(y) May 2 09:43:37 Sakaar kernel: scsi 8:0:5:0: qdepth(32), tagged(1), scsi_level(7), cmd_que(1) May 2 09:43:37 Sakaar kernel: sd 8:0:4:0: [sdh] Write cache: enabled, read cache: enabled, supports DPO and FUA May 2 09:43:37 Sakaar kernel: sdh: sdh1 May 2 09:43:37 Sakaar kernel: sd 8:0:4:0: [sdh] Attached SCSI disk May 2 09:43:37 Sakaar kernel: sd 8:0:3:0: [sdg] Write Protect is off May 2 09:43:37 Sakaar kernel: sd 8:0:3:0: [sdg] Mode Sense: 7f 00 10 08 May 2 09:43:37 Sakaar kernel: sd 8:0:3:0: [sdg] Write cache: enabled, read cache: enabled, supports DPO and FUA May 2 09:43:37 Sakaar kernel: sd 8:0:5:0: Attached scsi generic sg9 type 0 May 2 09:43:37 Sakaar kernel: end_device-8:5: add: handle(0x000d), sas_addr(0x4433221105000000) May 2 09:43:37 Sakaar kernel: sd 8:0:5:0: [sdi] 19532873728 512-byte logical blocks: (10.0 TB/9.10 TiB) May 2 09:43:37 Sakaar kernel: sd 8:0:5:0: [sdi] 4096-byte physical blocks May 2 09:43:37 Sakaar kernel: sd 8:0:5:0: [sdi] Write Protect is off May 2 09:43:37 Sakaar kernel: sd 8:0:5:0: [sdi] Mode Sense: 7f 00 10 08 May 2 09:43:37 Sakaar kernel: sd 8:0:5:0: [sdi] Write cache: enabled, read cache: enabled, supports DPO and FUA May 2 09:43:37 Sakaar kernel: scsi 8:0:6:0: Direct-Access ATA ST6000VN001-2BB1 SC60 PQ: 0 ANSI: 6 May 2 09:43:37 Sakaar kernel: scsi 8:0:6:0: SATA: handle(0x000f), sas_addr(0x4433221106000000), phy(6), device_name(0x5000c500e3147d71) May 2 09:43:37 Sakaar kernel: scsi 8:0:6:0: enclosure logical id (0x500605b00a007010), slot(5) May 2 09:43:37 Sakaar kernel: scsi 8:0:6:0: atapi(n), ncq(y), asyn_notify(n), smart(y), fua(y), sw_preserve(y) May 2 09:43:37 Sakaar kernel: scsi 8:0:6:0: qdepth(32), tagged(1), scsi_level(7), cmd_que(1) May 2 09:43:37 Sakaar kernel: sd 8:0:0:0: [sdc] Write Protect is off May 2 09:43:37 Sakaar kernel: sd 8:0:0:0: [sdc] Mode Sense: 7f 00 10 08 May 2 09:43:37 Sakaar kernel: sd 8:0:0:0: [sdc] Write cache: enabled, read cache: enabled, supports DPO and FUA May 2 09:43:37 Sakaar kernel: sdg: sdg1 May 2 09:43:37 Sakaar kernel: sd 8:0:3:0: [sdg] Attached SCSI disk May 2 09:43:37 Sakaar kernel: sdi: sdi1 May 2 09:43:37 Sakaar kernel: sd 8:0:5:0: [sdi] Attached SCSI disk May 2 09:43:37 Sakaar kernel: sd 8:0:6:0: Attached scsi generic sg10 type 0 May 2 09:43:37 Sakaar kernel: end_device-8:6: add: handle(0x000f), sas_addr(0x4433221106000000) May 2 09:43:37 Sakaar kernel: scsi 8:0:7:0: Direct-Access ATA WDC WD60EFAX-68S 0A82 PQ: 0 ANSI: 6 May 2 09:43:37 Sakaar kernel: scsi 8:0:7:0: SATA: handle(0x0010), sas_addr(0x4433221107000000), phy(7), device_name(0x50014ee26694fc9d) May 2 09:43:37 Sakaar kernel: scsi 8:0:7:0: enclosure logical id (0x500605b00a007010), slot(4) May 2 09:43:37 Sakaar kernel: scsi 8:0:7:0: atapi(n), ncq(y), asyn_notify(n), smart(y), fua(y), sw_preserve(y) May 2 09:43:37 Sakaar kernel: scsi 8:0:7:0: qdepth(32), tagged(1), scsi_level(7), cmd_que(1) May 2 09:43:37 Sakaar kernel: sd 8:0:6:0: [sdj] 11721045168 512-byte logical blocks: (6.00 TB/5.46 TiB) May 2 09:43:37 Sakaar kernel: sd 8:0:6:0: [sdj] 4096-byte physical blocks May 2 09:43:37 Sakaar kernel: sd 8:0:7:0: Attached scsi generic sg11 type 0 May 2 09:43:37 Sakaar kernel: end_device-8:7: add: handle(0x0010), sas_addr(0x4433221107000000) May 2 09:43:37 Sakaar kernel: sd 8:0:7:0: [sdk] 11721045168 512-byte logical blocks: (6.00 TB/5.46 TiB) May 2 09:43:37 Sakaar kernel: sd 8:0:7:0: [sdk] 4096-byte physical blocks May 2 09:43:37 Sakaar kernel: sd 8:0:7:0: [sdk] Write Protect is off May 2 09:43:37 Sakaar kernel: sd 8:0:7:0: [sdk] Mode Sense: 7f 00 10 08 May 2 09:43:37 Sakaar kernel: sd 8:0:7:0: [sdk] Write cache: enabled, read cache: enabled, supports DPO and FUA May 2 09:43:37 Sakaar kernel: sdk: sdk1 May 2 09:43:37 Sakaar kernel: sd 8:0:7:0: [sdk] Attached SCSI disk May 2 09:43:37 Sakaar kernel: sd 8:0:6:0: [sdj] Write Protect is off May 2 09:43:37 Sakaar kernel: sd 8:0:6:0: [sdj] Mode Sense: 7f 00 10 08 May 2 09:43:37 Sakaar kernel: sd 8:0:6:0: [sdj] Write cache: enabled, read cache: enabled, supports DPO and FUA May 2 09:43:37 Sakaar kernel: sdj: sdj1 May 2 09:43:37 Sakaar kernel: sd 8:0:6:0: [sdj] Attached SCSI disk May 2 09:43:37 Sakaar kernel: sdc: sdc1 May 2 09:43:37 Sakaar kernel: sd 8:0:0:0: [sdc] Attached SCSI disk May 2 09:43:37 Sakaar kernel: cryptd: max_cpu_qlen set to 1000 May 2 09:43:37 Sakaar kernel: usbcore: registered new interface driver btusb May 2 09:43:37 Sakaar kernel: AVX2 version of gcm_enc/dec engaged. May 2 09:43:37 Sakaar kernel: AES CTR mode by8 optimization enabled May 2 09:43:37 Sakaar kernel: ACPI: bus type drm_connector registered May 2 09:43:37 Sakaar kernel: Bluetooth: hci0: Found device firmware: intel/ibt-20-1-3.sfi May 2 09:43:37 Sakaar kernel: Bluetooth: hci0: Boot Address: 0x24800 May 2 09:43:37 Sakaar kernel: Bluetooth: hci0: Firmware Version: 15-45.22 May 2 09:43:37 Sakaar kernel: Bluetooth: hci0: Firmware already loaded May 2 09:43:37 Sakaar kernel: sr 7:0:0:0: [sr0] scsi3-mmc drive: 62x/62x writer dvd-ram cd/rw xa/form2 cdda tray May 2 09:43:37 Sakaar kernel: cdrom: Uniform CD-ROM driver Revision: 3.20 May 2 09:43:37 Sakaar kernel: sr 7:0:0:0: Attached scsi CD-ROM sr0 May 2 09:43:37 Sakaar kernel: i915 0000:00:02.0: [drm] VT-d active for gfx access May 2 09:43:37 Sakaar kernel: i915 0000:00:02.0: vgaarb: deactivate vga console May 2 09:43:37 Sakaar kernel: i915 0000:00:02.0: [drm] Using Transparent Hugepages May 2 09:43:37 Sakaar kernel: i915 0000:00:02.0: vgaarb: changed VGA decodes: olddecodes=io+mem,decodes=none:owns=io+mem May 2 09:43:37 Sakaar kernel: vfio-pci 0000:01:00.0: vgaarb: changed VGA decodes: olddecodes=io+mem,decodes=io+mem:owns=none May 2 09:43:37 Sakaar kernel: mei_hdcp 0000:00:16.0-b638ab7e-94e2-4ea2-a552-d1c54b627f04: bound 0000:00:02.0 (ops i915_hdcp_component_ops [i915]) May 2 09:43:37 Sakaar kernel: i915 0000:00:02.0: [drm] Finished loading DMC firmware i915/rkl_dmc_ver2_03.bin (v2.3) May 2 09:43:37 Sakaar kernel: mei_pxp 0000:00:16.0-fbf6fcf1-96cf-4e2e-a6a6-1bab8cbe36b1: bound 0000:00:02.0 (ops i915_pxp_tee_component_ops [i915]) May 2 09:43:37 Sakaar kernel: i915 0000:00:02.0: [drm] Protected Xe Path (PXP) protected content support initialized May 2 09:43:37 Sakaar kernel: [drm] Initialized i915 1.6.0 20201103 for 0000:00:02.0 on minor 0 May 2 09:43:37 Sakaar kernel: ACPI: video: Video Device [GFX0] (multi-head: yes rom: no post: no) May 2 09:43:37 Sakaar kernel: input: Video Bus as /devices/LNXSYSTM:00/LNXSYBUS:00/PNP0A08:00/LNXVIDEO:00/input/input7 May 2 09:43:37 Sakaar kernel: fbcon: i915drmfb (fb0) is primary device May 2 09:43:37 Sakaar kernel: Console: switching to colour frame buffer device 240x67 May 2 09:43:37 Sakaar kernel: i915 0000:00:02.0: [drm] fb0: i915drmfb frame buffer device May 2 09:43:37 Sakaar kernel: ACPI: \_TZ_.TZ10: Invalid passive threshold May 2 09:43:37 Sakaar kernel: thermal LNXTHERM:00: registered as thermal_zone1 May 2 09:43:37 Sakaar kernel: ACPI: thermal: Thermal Zone [TZ10] (17 C) May 2 09:43:37 Sakaar kernel: thermal LNXTHERM:01: registered as thermal_zone2 May 2 09:43:37 Sakaar kernel: ACPI: thermal: Thermal Zone [TZ00] (28 C) May 2 09:43:37 Sakaar rc.inet1: ip -4 addr add 127.0.0.1/8 dev lo May 2 09:43:37 Sakaar rc.inet1: ip -6 addr add ::1/128 dev lo May 2 09:43:37 Sakaar rc.inet1: ip link set lo up May 2 09:43:37 Sakaar rc.inet1: ip link add name br0 type bridge stp_state 0 forward_delay 0 May 2 09:43:37 Sakaar rc.inet1: ip link set br0 up May 2 09:43:37 Sakaar kernel: bridge: filtering via arp/ip/ip6tables is no longer available by default. Update your scripts to load br_netfilter if you need this. May 2 09:43:37 Sakaar rc.inet1: ip link set eth0 down May 2 09:43:37 Sakaar rc.inet1: ip -4 addr flush dev eth0 May 2 09:43:37 Sakaar rc.inet1: ip -6 addr flush dev eth0 May 2 09:43:37 Sakaar rc.inet1: ip link set eth0 promisc on master br0 up May 2 09:43:37 Sakaar kernel: br0: port 1(eth0) entered blocking state May 2 09:43:37 Sakaar kernel: br0: port 1(eth0) entered disabled state May 2 09:43:37 Sakaar kernel: device eth0 entered promiscuous mode May 2 09:43:38 Sakaar rsyslogd: [origin software="rsyslogd" swVersion="8.2102.0" x-pid="1203" x-info="https://www.rsyslog.com"] start May 2 09:43:38 Sakaar rc.inet1: ip -4 addr add 192.168.1.106/255.255.255.0 dev br0 May 2 09:43:39 Sakaar rc.inet1: polling up to 60 sec for DHCP server on interface br0 May 2 09:43:39 Sakaar rc.inet1: timeout 60 dhcpcd -w -q -t 10 -h Sakaar -6 br0 May 2 09:43:39 Sakaar dhcpcd[1368]: dhcpcd-9.4.1 starting May 2 09:43:39 Sakaar dhcpcd[1371]: DUID 00:04:03:c0:02:18:04:4d:05:eb:92:06:60:07:00:08:00:09 May 2 09:43:39 Sakaar kernel: 8021q: 802.1Q VLAN Support v1.8 May 2 09:43:40 Sakaar dhcpcd[1371]: br0: waiting for carrier May 2 09:43:44 Sakaar kernel: igc 0000:04:00.0 eth0: NIC Link is Up 1000 Mbps Full Duplex, Flow Control: RX/TX May 2 09:43:44 Sakaar kernel: IPv6: ADDRCONF(NETDEV_CHANGE): eth0: link becomes ready May 2 09:43:44 Sakaar kernel: br0: port 1(eth0) entered blocking state May 2 09:43:44 Sakaar kernel: br0: port 1(eth0) entered forwarding state May 2 09:43:44 Sakaar kernel: IPv6: ADDRCONF(NETDEV_CHANGE): br0: link becomes ready May 2 09:43:44 Sakaar dhcpcd[1371]: br0: carrier acquired May 2 09:43:44 Sakaar dhcpcd[1371]: br0: IAID 4d:eb:92:60 May 2 09:43:44 Sakaar dhcpcd[1371]: br0: adding address fe80::1ac0:4dff:feeb:9260 May 2 09:43:44 Sakaar dhcpcd[1371]: br0: soliciting an IPv6 router May 2 09:43:57 Sakaar dhcpcd[1371]: br0: no IPv6 Routers available May 2 09:44:39 Sakaar dhcpcd[1371]: received SIGTERM, stopping May 2 09:44:39 Sakaar dhcpcd[1371]: br0: removing interface May 2 09:44:39 Sakaar rc.inet1: can't obtain IP address, continue polling in background on interface br0 May 2 09:44:39 Sakaar rc.inet1: dhcpcd -b -q -t 10 -h Sakaar -6 br0 May 2 09:44:39 Sakaar dhcpcd[1395]: dhcpcd-9.4.1 starting May 2 09:44:39 Sakaar dhcpcd[1398]: DUID 00:04:03:c0:02:18:04:4d:05:eb:92:06:60:07:00:08:00:09 May 2 09:44:40 Sakaar rc.inet1: ip link set br0 up May 2 09:44:40 Sakaar rc.inet1: ip -4 route add default via 192.168.1.1 dev br0 May 2 09:44:40 Sakaar dhcpcd[1398]: br0: IAID 4d:eb:92:60 May 2 09:44:40 Sakaar mcelog: failed to prefill DIMM database from DMI data May 2 09:44:40 Sakaar mcelog: Kernel does not support page offline interface May 2 09:44:40 Sakaar elogind-daemon[1468]: New seat seat0. May 2 09:44:40 Sakaar elogind-daemon[1468]: Watching system buttons on /dev/input/event6 (Power Button) May 2 09:44:40 Sakaar elogind-daemon[1468]: Watching system buttons on /dev/input/event5 (Power Button) May 2 09:44:40 Sakaar elogind-daemon[1468]: Watching system buttons on /dev/input/event4 (Sleep Button) May 2 09:44:40 Sakaar elogind-daemon[1468]: Watching system buttons on /dev/input/event1 (PiKVM Composite KVM Device) May 2 09:44:40 Sakaar sshd[1491]: Server listening on 0.0.0.0 port 22. May 2 09:44:40 Sakaar sshd[1491]: Server listening on :: port 22. May 2 09:44:40 Sakaar ntpd[1500]: ntpd [email protected] Fri Jun 3 04:17:10 UTC 2022 (1): Starting May 2 09:44:40 Sakaar ntpd[1500]: Command line: /usr/sbin/ntpd -g -u ntp:ntp May 2 09:44:40 Sakaar ntpd[1500]: ---------------------------------------------------- May 2 09:44:40 Sakaar ntpd[1500]: ntp-4 is maintained by Network Time Foundation, May 2 09:44:40 Sakaar ntpd[1500]: Inc. (NTF), a non-profit 501(c)(3) public-benefit May 2 09:44:40 Sakaar ntpd[1500]: corporation. Support and training for ntp-4 are May 2 09:44:40 Sakaar ntpd[1500]: available at https://www.nwtime.org/support May 2 09:44:40 Sakaar ntpd[1500]: ---------------------------------------------------- May 2 09:44:40 Sakaar ntpd[1502]: proto: precision = 0.031 usec (-25) May 2 09:44:40 Sakaar ntpd[1502]: basedate set to 2022-05-22 May 2 09:44:40 Sakaar ntpd[1502]: gps base set to 2022-05-22 (week 2211) May 2 09:44:40 Sakaar ntpd[1502]: Listen normally on 0 lo 127.0.0.1:123 May 2 09:44:40 Sakaar ntpd[1502]: Listen normally on 1 br0 192.168.1.106:123 May 2 09:44:40 Sakaar ntpd[1502]: Listen normally on 2 lo [::1]:123 May 2 09:44:40 Sakaar ntpd[1502]: Listen normally on 3 br0 [fe80::1ac0:4dff:feeb:9260%4]:123 May 2 09:44:40 Sakaar ntpd[1502]: Listening on routing socket on fd #20 for interface updates May 2 09:44:40 Sakaar ntpd[1502]: kernel reports TIME_ERROR: 0x41: Clock Unsynchronized ### [PREVIOUS LINE REPEATED 1 TIMES] ### May 2 09:44:40 Sakaar crond[1527]: /usr/sbin/crond 4.5 dillon's cron daemon, started with loglevel notice May 2 09:44:40 Sakaar smbd[1539]: [2023/05/02 09:44:40.344644, 0] ../../source3/smbd/server.c:1741(main) May 2 09:44:40 Sakaar smbd[1539]: smbd version 4.17.7 started. May 2 09:44:40 Sakaar smbd[1539]: Copyright Andrew Tridgell and the Samba Team 1992-2022 May 2 09:44:40 Sakaar nmbd[1542]: [2023/05/02 09:44:40.370320, 0] ../../source3/nmbd/nmbd.c:901(main) May 2 09:44:40 Sakaar nmbd[1542]: nmbd version 4.17.7 started. May 2 09:44:40 Sakaar nmbd[1542]: Copyright Andrew Tridgell and the Samba Team 1992-2022 May 2 09:44:40 Sakaar acpid: starting up with netlink and the input layer May 2 09:44:40 Sakaar acpid: 1 rule loaded May 2 09:44:40 Sakaar acpid: waiting for events: event logging is off May 2 09:44:40 Sakaar wsdd2[1555]: starting. May 2 09:44:40 Sakaar winbindd[1556]: [2023/05/02 09:44:40.452494, 0] ../../source3/winbindd/winbindd.c:1440(main) May 2 09:44:40 Sakaar winbindd[1556]: winbindd version 4.17.7 started. May 2 09:44:40 Sakaar winbindd[1556]: Copyright Andrew Tridgell and the Samba Team 1992-2022 May 2 09:44:40 Sakaar winbindd[1558]: [2023/05/02 09:44:40.460883, 0] ../../source3/winbindd/winbindd_cache.c:3116(initialize_winbindd_cache) May 2 09:44:40 Sakaar winbindd[1558]: initialize_winbindd_cache: clearing cache and re-creating with version number 2 May 2 09:44:40 Sakaar dhcpcd[1398]: br0: soliciting an IPv6 router May 2 09:44:41 Sakaar root: Installing plugins May 2 09:44:41 Sakaar root: plugin: installing: appdata.backup.plg May 2 09:44:41 Sakaar root: Executing hook script: pre_plugin_checks May 2 09:44:41 Sakaar root: plugin: running: anonymous May 2 09:44:41 Sakaar root: Checking some pre-install things... May 2 09:44:41 Sakaar root: Plugin files were not present. Fresh install May 2 09:44:41 Sakaar root: Creating plugin files directory... May 2 09:44:41 Sakaar root: plugin: checking: /boot/config/plugins/appdata.backup/appdata.backup-2023.04.27.tgz - SHA256 May 2 09:44:41 Sakaar root: plugin: skipping: /boot/config/plugins/appdata.backup/appdata.backup-2023.04.27.tgz already exists May 2 09:44:41 Sakaar root: plugin: running: anonymous May 2 09:44:41 Sakaar root: Extracting plugin files... May 2 09:44:41 Sakaar root: plugin: running: anonymous May 2 09:44:41 Sakaar root: Checking cron. May 2 09:44:41 Sakaar root: Checking cron succeeded! May 2 09:44:41 Sakaar root: plugin: running: anonymous ### [PREVIOUS LINE REPEATED 1 TIMES] ### May 2 09:44:41 Sakaar root: May 2 09:44:41 Sakaar root: ---------------------------------------------------- May 2 09:44:41 Sakaar root: appdata.backup has been installed. May 2 09:44:41 Sakaar root: (previously known as ca.backup2) May 2 09:44:41 Sakaar root: May 2 09:44:41 Sakaar root: 2022-2023, Robin Kluth May 2 09:44:41 Sakaar root: Version: 2023.04.27 May 2 09:44:41 Sakaar root: ---------------------------------------------------- May 2 09:44:41 Sakaar root: May 2 09:44:41 Sakaar root: plugin: appdata.backup.plg installed ### [PREVIOUS LINE REPEATED 1 TIMES] ### May 2 09:44:41 Sakaar root: Executing hook script: post_plugin_checks May 2 09:44:41 Sakaar root: plugin: installing: ca.update.applications.plg May 2 09:44:41 Sakaar root: Executing hook script: pre_plugin_checks May 2 09:44:41 Sakaar root: plugin: running: anonymous May 2 09:44:41 Sakaar root: May 2 09:44:41 Sakaar root: plugin: running: anonymous May 2 09:44:41 Sakaar root: plugin: checking: /boot/config/plugins/ca.update.applications/ca.update.applications-2023.02.20-x86_64-1.txz - MD5 May 2 09:44:41 Sakaar root: plugin: skipping: /boot/config/plugins/ca.update.applications/ca.update.applications-2023.02.20-x86_64-1.txz already exists May 2 09:44:41 Sakaar root: plugin: running: upgradepkg --install-new /boot/config/plugins/ca.update.applications/ca.update.applications-2023.02.20-x86_64-1.txz May 2 09:44:41 Sakaar root: May 2 09:44:41 Sakaar root: +============================================================================== May 2 09:44:41 Sakaar root: | Installing new package /boot/config/plugins/ca.update.applications/ca.update.applications-2023.02.20-x86_64-1.txz May 2 09:44:41 Sakaar root: +============================================================================== May 2 09:44:41 Sakaar root: May 2 09:44:41 Sakaar root: Verifying package ca.update.applications-2023.02.20-x86_64-1.txz. May 2 09:44:41 Sakaar root: Installing package ca.update.applications-2023.02.20-x86_64-1.txz: May 2 09:44:41 Sakaar root: PACKAGE DESCRIPTION: May 2 09:44:41 Sakaar root: Package ca.update.applications-2023.02.20-x86_64-1.txz installed. May 2 09:44:41 Sakaar root: plugin: running: anonymous May 2 09:44:41 Sakaar root: May 2 09:44:41 Sakaar root: ---------------------------------------------------- May 2 09:44:41 Sakaar root: ca.update.applications has been installed. May 2 09:44:41 Sakaar root: Copyright 2015-2021, Andrew Zawadzki May 2 09:44:41 Sakaar root: Version: 2023.02.20 May 2 09:44:41 Sakaar root: ---------------------------------------------------- May 2 09:44:41 Sakaar root: May 2 09:44:41 Sakaar root: plugin: ca.update.applications.plg installed ### [PREVIOUS LINE REPEATED 1 TIMES] ### May 2 09:44:41 Sakaar root: Executing hook script: post_plugin_checks May 2 09:44:41 Sakaar root: plugin: installing: community.applications.plg May 2 09:44:41 Sakaar root: Executing hook script: pre_plugin_checks May 2 09:44:41 Sakaar root: plugin: running: anonymous May 2 09:44:41 Sakaar root: ### [PREVIOUS LINE REPEATED 1 TIMES] ### May 2 09:44:41 Sakaar root: Cleaning Up Old Versions May 2 09:44:41 Sakaar root: Fixing pinned apps May 2 09:44:41 Sakaar root: Setting up cron for background notifications May 2 09:44:41 Sakaar root: May 2 09:44:41 Sakaar root: plugin: running: anonymous May 2 09:44:41 Sakaar root: plugin: checking: /boot/config/plugins/community.applications/community.applications-2023.04.27-x86_64-1.txz - MD5 May 2 09:44:41 Sakaar root: plugin: skipping: /boot/config/plugins/community.applications/community.applications-2023.04.27-x86_64-1.txz already exists May 2 09:44:41 Sakaar root: plugin: running: upgradepkg --install-new --reinstall /boot/config/plugins/community.applications/community.applications-2023.04.27-x86_64-1.txz May 2 09:44:41 Sakaar root: May 2 09:44:41 Sakaar root: +============================================================================== May 2 09:44:41 Sakaar root: | Installing new package /boot/config/plugins/community.applications/community.applications-2023.04.27-x86_64-1.txz May 2 09:44:41 Sakaar root: +============================================================================== May 2 09:44:41 Sakaar root: May 2 09:44:41 Sakaar root: Verifying package community.applications-2023.04.27-x86_64-1.txz. May 2 09:44:41 Sakaar root: Installing package community.applications-2023.04.27-x86_64-1.txz: May 2 09:44:41 Sakaar root: PACKAGE DESCRIPTION: May 2 09:44:41 Sakaar root: Package community.applications-2023.04.27-x86_64-1.txz installed. May 2 09:44:41 Sakaar root: plugin: running: anonymous May 2 09:44:41 Sakaar root: Creating Directories May 2 09:44:41 Sakaar root: May 2 09:44:41 Sakaar root: Adjusting icon for Unraid version May 2 09:44:41 Sakaar root: May 2 09:44:41 Sakaar root: ---------------------------------------------------- May 2 09:44:41 Sakaar root: community.applications has been installed. May 2 09:44:41 Sakaar root: Copyright 2015-2023, Andrew Zawadzki May 2 09:44:41 Sakaar root: Version: 2023.04.27 May 2 09:44:41 Sakaar root: ---------------------------------------------------- May 2 09:44:41 Sakaar root: May 2 09:44:41 Sakaar root: plugin: community.applications.plg installed ### [PREVIOUS LINE REPEATED 1 TIMES] ### May 2 09:44:41 Sakaar root: Executing hook script: post_plugin_checks May 2 09:44:42 Sakaar root: plugin: installing: dynamix.s3.sleep.plg May 2 09:44:42 Sakaar root: Executing hook script: pre_plugin_checks May 2 09:44:42 Sakaar root: plugin: running: anonymous May 2 09:44:42 Sakaar root: plugin: checking: /boot/config/plugins/dynamix.s3.sleep/dynamix.s3.sleep.txz - MD5 May 2 09:44:42 Sakaar root: plugin: skipping: /boot/config/plugins/dynamix.s3.sleep/dynamix.s3.sleep.txz already exists May 2 09:44:42 Sakaar root: plugin: running: upgradepkg --install-new --reinstall /boot/config/plugins/dynamix.s3.sleep/dynamix.s3.sleep.txz May 2 09:44:42 Sakaar root: May 2 09:44:42 Sakaar root: +============================================================================== May 2 09:44:42 Sakaar root: | Installing new package /boot/config/plugins/dynamix.s3.sleep/dynamix.s3.sleep.txz May 2 09:44:42 Sakaar root: +============================================================================== May 2 09:44:42 Sakaar root: May 2 09:44:42 Sakaar root: Verifying package dynamix.s3.sleep.txz. May 2 09:44:42 Sakaar root: Installing package dynamix.s3.sleep.txz: May 2 09:44:42 Sakaar root: PACKAGE DESCRIPTION: May 2 09:44:42 Sakaar root: Package dynamix.s3.sleep.txz installed. May 2 09:44:42 Sakaar root: plugin: creating: /tmp/start_service - from INLINE content May 2 09:44:42 Sakaar root: plugin: setting: /tmp/start_service - mode to 0770 May 2 09:44:42 Sakaar root: plugin: running: anonymous May 2 09:44:42 Sakaar root: May 2 09:44:42 Sakaar root: ----------------------------------------------------------- May 2 09:44:42 Sakaar root: Plugin dynamix.s3.sleep is installed. May 2 09:44:42 Sakaar root: This plugin requires Dynamix webGui to operate May 2 09:44:42 Sakaar root: Copyright 2023, Bergware International May 2 09:44:42 Sakaar root: Version: 2023.03.23 May 2 09:44:42 Sakaar root: ----------------------------------------------------------- May 2 09:44:42 Sakaar root: May 2 09:44:42 Sakaar root: plugin: dynamix.s3.sleep.plg installed ### [PREVIOUS LINE REPEATED 1 TIMES] ### May 2 09:44:42 Sakaar root: Executing hook script: post_plugin_checks May 2 09:44:42 Sakaar root: plugin: installing: dynamix.system.temp.plg May 2 09:44:42 Sakaar root: Executing hook script: pre_plugin_checks May 2 09:44:42 Sakaar root: plugin: running: anonymous May 2 09:44:42 Sakaar root: plugin: checking: /boot/config/plugins/dynamix.system.temp/dynamix.system.temp.txz - MD5 May 2 09:44:42 Sakaar root: plugin: skipping: /boot/config/plugins/dynamix.system.temp/dynamix.system.temp.txz already exists May 2 09:44:42 Sakaar root: plugin: running: upgradepkg --install-new --reinstall /boot/config/plugins/dynamix.system.temp/dynamix.system.temp.txz May 2 09:44:42 Sakaar root: May 2 09:44:42 Sakaar root: +============================================================================== May 2 09:44:42 Sakaar root: | Installing new package /boot/config/plugins/dynamix.system.temp/dynamix.system.temp.txz May 2 09:44:42 Sakaar root: +============================================================================== May 2 09:44:42 Sakaar root: May 2 09:44:42 Sakaar root: Verifying package dynamix.system.temp.txz. May 2 09:44:42 Sakaar root: Installing package dynamix.system.temp.txz: May 2 09:44:42 Sakaar root: PACKAGE DESCRIPTION: May 2 09:44:42 Sakaar root: Package dynamix.system.temp.txz installed. May 2 09:44:42 Sakaar root: plugin: skipping: sensors-detect - Unraid version too high, requires at most version 6.7.2 ### [PREVIOUS LINE REPEATED 1 TIMES] ### May 2 09:44:42 Sakaar root: plugin: running: anonymous May 2 09:44:42 Sakaar root: May 2 09:44:42 Sakaar root: ----------------------------------------------------------- May 2 09:44:42 Sakaar root: Plugin dynamix.system.temp is installed. May 2 09:44:42 Sakaar root: This plugin requires Dynamix webGui to operate May 2 09:44:42 Sakaar root: Copyright 2023, Bergware International May 2 09:44:42 Sakaar root: Version: 2023.02.04b May 2 09:44:42 Sakaar root: ----------------------------------------------------------- May 2 09:44:42 Sakaar root: May 2 09:44:42 Sakaar root: plugin: dynamix.system.temp.plg installed ### [PREVIOUS LINE REPEATED 1 TIMES] ### May 2 09:44:42 Sakaar root: Executing hook script: post_plugin_checks May 2 09:44:42 Sakaar root: plugin: installing: dynamix.unraid.net.plg May 2 09:44:42 Sakaar root: Executing hook script: pre_plugin_checks May 2 09:44:42 Sakaar root: plugin: running: anonymous May 2 09:44:42 Sakaar root: Installing dynamix.unraid.net.plg 2023.05.01.1138 with Unraid API 3.1.0 May 2 09:44:42 Sakaar root: plugin: running: anonymous May 2 09:44:42 Sakaar root: Checking DNS... May 2 09:44:42 Sakaar root: May 2 09:44:42 Sakaar root: ⚠️ Do not close this window yet May 2 09:44:42 Sakaar root: May 2 09:44:42 Sakaar root: Validating /boot/config/plugins/dynamix.my.servers/dynamix.unraid.net.txz... ok. May 2 09:44:43 Sakaar root: Validating /boot/config/plugins/dynamix.my.servers/unraid-api.tgz... ok. May 2 09:44:43 Sakaar root: plugin: checking: /boot/config/plugins/dynamix.my.servers/dynamix.unraid.net.txz - SHA256 May 2 09:44:43 Sakaar root: plugin: skipping: /boot/config/plugins/dynamix.my.servers/dynamix.unraid.net.txz already exists May 2 09:44:43 Sakaar root: plugin: checking: /boot/config/plugins/dynamix.my.servers/unraid-api.tgz - SHA256 May 2 09:44:43 Sakaar root: plugin: skipping: /boot/config/plugins/dynamix.my.servers/unraid-api.tgz already exists May 2 09:44:43 Sakaar root: plugin: running: anonymous ### [PREVIOUS LINE REPEATED 1 TIMES] ### May 2 09:44:44 Sakaar root: May 2 09:44:44 Sakaar root: ⚠️ Do not close this window yet May 2 09:44:44 Sakaar root: May 2 09:44:44 Sakaar root: 🕹️ Installing JavaScript web components May 2 09:44:44 Sakaar root: ✅ Finished installing web components May 2 09:44:44 Sakaar root: May 2 09:44:44 Sakaar root: ⚠️ Do not close this window yet May 2 09:44:44 Sakaar root: May 2 09:44:44 Sakaar root: plugin: running: anonymous May 2 09:44:44 Sakaar root: ### [PREVIOUS LINE REPEATED 1 TIMES] ### May 2 09:44:44 Sakaar root: plugin: running: anonymous May 2 09:44:44 Sakaar root: May 2 09:44:44 Sakaar root: ⚠️ Do not close this window yet May 2 09:44:44 Sakaar root: May 2 09:44:44 Sakaar root: plugin: running: anonymous May 2 09:44:44 Sakaar root: May 2 09:44:44 Sakaar root: ⚠️ Do not close this window yet May 2 09:44:44 Sakaar root: ### [PREVIOUS LINE REPEATED 1 TIMES] ### May 2 09:44:44 Sakaar root: +============================================================================== May 2 09:44:44 Sakaar root: | Installing new package /boot/config/plugins/dynamix.my.servers/dynamix.unraid.net.txz May 2 09:44:44 Sakaar root: +============================================================================== May 2 09:44:44 Sakaar root: May 2 09:44:44 Sakaar root: Verifying package dynamix.unraid.net.txz. May 2 09:44:44 Sakaar root: Installing package dynamix.unraid.net.txz: May 2 09:44:44 Sakaar root: PACKAGE DESCRIPTION: May 2 09:44:44 Sakaar root: Package dynamix.unraid.net.txz installed. May 2 09:44:44 Sakaar root: May 2 09:44:44 Sakaar root: ⚠️ Do not close this window yet May 2 09:44:44 Sakaar root: ### [PREVIOUS LINE REPEATED 1 TIMES] ### May 2 09:44:44 Sakaar root: ⚠️ Do not close this window yet May 2 09:44:44 Sakaar root: ### [PREVIOUS LINE REPEATED 2 TIMES] ### May 2 09:44:44 Sakaar root: ✅ Installation is complete, it is safe to close this window May 2 09:44:44 Sakaar root: May 2 09:44:44 Sakaar root: plugin: dynamix.unraid.net.plg installed ### [PREVIOUS LINE REPEATED 1 TIMES] ### May 2 09:44:44 Sakaar root: Executing hook script: post_plugin_checks May 2 09:44:44 Sakaar root: plugin: installing: fix.common.problems.plg May 2 09:44:44 Sakaar root: Executing hook script: pre_plugin_checks May 2 09:44:44 Sakaar root: plugin: checking: /boot/config/plugins/fix.common.problems/fix.common.problems-2023.04.26-x86_64-1.txz - MD5 May 2 09:44:44 Sakaar root: plugin: skipping: /boot/config/plugins/fix.common.problems/fix.common.problems-2023.04.26-x86_64-1.txz already exists May 2 09:44:44 Sakaar root: plugin: running: upgradepkg --install-new /boot/config/plugins/fix.common.problems/fix.common.problems-2023.04.26-x86_64-1.txz May 2 09:44:44 Sakaar root: May 2 09:44:44 Sakaar root: +============================================================================== May 2 09:44:44 Sakaar root: | Installing new package /boot/config/plugins/fix.common.problems/fix.common.problems-2023.04.26-x86_64-1.txz May 2 09:44:44 Sakaar root: +============================================================================== May 2 09:44:44 Sakaar root: May 2 09:44:44 Sakaar root: Verifying package fix.common.problems-2023.04.26-x86_64-1.txz. May 2 09:44:44 Sakaar root: Installing package fix.common.problems-2023.04.26-x86_64-1.txz: May 2 09:44:44 Sakaar root: PACKAGE DESCRIPTION: May 2 09:44:44 Sakaar root: Package fix.common.problems-2023.04.26-x86_64-1.txz installed. May 2 09:44:44 Sakaar root: plugin: running: anonymous May 2 09:44:44 Sakaar root: ### [PREVIOUS LINE REPEATED 1 TIMES] ### May 2 09:44:44 Sakaar root: ---------------------------------------------------- May 2 09:44:44 Sakaar root: fix.common.problems has been installed. May 2 09:44:44 Sakaar root: Copyright 2016-2022, Andrew Zawadzki May 2 09:44:44 Sakaar root: Version: 2023.04.26 May 2 09:44:44 Sakaar root: ---------------------------------------------------- May 2 09:44:44 Sakaar root: May 2 09:44:44 Sakaar root: plugin: fix.common.problems.plg installed ### [PREVIOUS LINE REPEATED 1 TIMES] ### May 2 09:44:44 Sakaar root: Executing hook script: post_plugin_checks May 2 09:44:44 Sakaar root: plugin: installing: intel-gpu-top.plg May 2 09:44:44 Sakaar root: Executing hook script: pre_plugin_checks May 2 09:44:44 Sakaar root: plugin: running: anonymous May 2 09:44:44 Sakaar root: plugin: checking: /boot/config/plugins/intel-gpu-top/intel.gpu.top-2023.02.15.txz - MD5 May 2 09:44:44 Sakaar root: plugin: skipping: /boot/config/plugins/intel-gpu-top/intel.gpu.top-2023.02.15.txz already exists May 2 09:44:44 Sakaar root: plugin: running: upgradepkg --install-new /boot/config/plugins/intel-gpu-top/intel.gpu.top-2023.02.15.txz May 2 09:44:44 Sakaar root: May 2 09:44:44 Sakaar root: +============================================================================== May 2 09:44:44 Sakaar root: | Installing new package /boot/config/plugins/intel-gpu-top/intel.gpu.top-2023.02.15.txz May 2 09:44:44 Sakaar root: +============================================================================== May 2 09:44:44 Sakaar root: May 2 09:44:44 Sakaar root: Verifying package intel.gpu.top-2023.02.15.txz. May 2 09:44:44 Sakaar root: Installing package intel.gpu.top-2023.02.15.txz: May 2 09:44:44 Sakaar root: PACKAGE DESCRIPTION: May 2 09:44:44 Sakaar root: Package intel.gpu.top-2023.02.15.txz installed. May 2 09:44:44 Sakaar root: plugin: creating: /usr/local/emhttp/plugins/intel-gpu-top/README.md - from INLINE content May 2 09:44:44 Sakaar root: plugin: running: anonymous May 2 09:44:44 Sakaar root: May 2 09:44:44 Sakaar root: -----Intel Kernel Module already enabled!------ May 2 09:44:44 Sakaar root: May 2 09:44:44 Sakaar root: ----Installation of Intel GPU TOP complete----- May 2 09:44:44 Sakaar root: plugin: intel-gpu-top.plg installed ### [PREVIOUS LINE REPEATED 1 TIMES] ### May 2 09:44:44 Sakaar root: Executing hook script: post_plugin_checks May 2 09:44:44 Sakaar root: plugin: installing: nut.plg May 2 09:44:44 Sakaar root: Executing hook script: pre_plugin_checks May 2 09:44:44 Sakaar root: plugin: checking: /boot/config/plugins/nut/nut-2.7.4.20200318-x86_64-1.txz - MD5 May 2 09:44:45 Sakaar root: plugin: skipping: /boot/config/plugins/nut/nut-2.7.4.20200318-x86_64-1.txz already exists May 2 09:44:45 Sakaar root: plugin: running: upgradepkg --install-new /boot/config/plugins/nut/nut-2.7.4.20200318-x86_64-1.txz May 2 09:44:45 Sakaar root: May 2 09:44:45 Sakaar root: +============================================================================== May 2 09:44:45 Sakaar root: | Installing new package /boot/config/plugins/nut/nut-2.7.4.20200318-x86_64-1.txz May 2 09:44:45 Sakaar root: +============================================================================== May 2 09:44:45 Sakaar root: May 2 09:44:45 Sakaar root: Verifying package nut-2.7.4.20200318-x86_64-1.txz. May 2 09:44:45 Sakaar root: Installing package nut-2.7.4.20200318-x86_64-1.txz: May 2 09:44:45 Sakaar root: PACKAGE DESCRIPTION: May 2 09:44:45 Sakaar root: # nut (Network UPS Tools) May 2 09:44:45 Sakaar root: # May 2 09:44:45 Sakaar root: # The Network UPS Tools is a collection of programs which provide a May 2 09:44:45 Sakaar root: # common interface for monitoring and administering UPS hardware. May 2 09:44:45 Sakaar root: # It uses a layered apporoach to connect all the components. Drivers May 2 09:44:45 Sakaar root: # are provided for a wide assortment of equipment. The primary goal of May 2 09:44:45 Sakaar root: # the NUT project is to provide reliable monitoring of UPS hardware May 2 09:44:45 Sakaar root: # and ensure safe shutdowns of the systems which are connected. May 2 09:44:45 Sakaar root: # May 2 09:44:45 Sakaar root: # Homepage: http://www.networkupstools.org May 2 09:44:45 Sakaar root: # May 2 09:44:45 Sakaar root: Executing install script for nut-2.7.4.20200318-x86_64-1.txz. May 2 09:44:45 Sakaar root: Package nut-2.7.4.20200318-x86_64-1.txz installed. May 2 09:44:45 Sakaar root: plugin: skipping: nut-2.7.4.20181125-x86_64-1.txz - Unraid version too high, requires at most version 6.7.99 May 2 09:44:45 Sakaar root: plugin: skipping: nut-2.7.4.20171129-x86_64-1.txz - Unraid version too high, requires at most version 6.4.99 May 2 09:44:45 Sakaar root: plugin: checking: /boot/config/plugins/nut/net-snmp-5.7.3-x86_64-4.txz - MD5 May 2 09:44:45 Sakaar root: plugin: skipping: /boot/config/plugins/nut/net-snmp-5.7.3-x86_64-4.txz already exists May 2 09:44:45 Sakaar root: plugin: running: upgradepkg --install-new /boot/config/plugins/nut/net-snmp-5.7.3-x86_64-4.txz May 2 09:44:45 Sakaar root: May 2 09:44:45 Sakaar root: +============================================================================== May 2 09:44:45 Sakaar root: | Installing new package /boot/config/plugins/nut/net-snmp-5.7.3-x86_64-4.txz May 2 09:44:45 Sakaar root: +============================================================================== May 2 09:44:45 Sakaar root: May 2 09:44:45 Sakaar root: Verifying package net-snmp-5.7.3-x86_64-4.txz. May 2 09:44:45 Sakaar root: Installing package net-snmp-5.7.3-x86_64-4.txz: May 2 09:44:45 Sakaar root: PACKAGE DESCRIPTION: May 2 09:44:45 Sakaar root: # net-snmp (Simple Network Management Protocol tools) May 2 09:44:45 Sakaar root: # May 2 09:44:45 Sakaar root: # Various tools relating to the Simple Network Management Protocol: May 2 09:44:45 Sakaar root: # May 2 09:44:45 Sakaar root: # An extensible agent May 2 09:44:45 Sakaar root: # An SNMP library May 2 09:44:45 Sakaar root: # Tools to request or set information from SNMP agents May 2 09:44:45 Sakaar root: # Tools to generate and handle SNMP traps May 2 09:44:45 Sakaar root: # A version of the UNIX 'netstat' command using SNMP May 2 09:44:45 Sakaar root: # A graphical Perl/Tk/SNMP based mib browser May 2 09:44:45 Sakaar root: # May 2 09:44:45 Sakaar root: Executing install script for net-snmp-5.7.3-x86_64-4.txz. May 2 09:44:45 Sakaar root: Package net-snmp-5.7.3-x86_64-4.txz installed. May 2 09:44:45 Sakaar root: plugin: skipping: /boot/config/plugins/nut/nut-plugin-2023.02.14-x86_64-1.txz already exists May 2 09:44:45 Sakaar root: plugin: skipping: /boot/config/plugins/nut/nut-plugin-2023.02.14-x86_64-1.md5 already exists May 2 09:44:45 Sakaar root: plugin: creating: /tmp/start_nut - from INLINE content May 2 09:44:45 Sakaar root: plugin: setting: /tmp/start_nut - mode to 0770 May 2 09:44:45 Sakaar root: plugin: running: anonymous May 2 09:44:45 Sakaar root: May 2 09:44:45 Sakaar root: +============================================================================== May 2 09:44:45 Sakaar root: | Installing new package /boot/config/plugins/nut/nut-plugin-2023.02.14-x86_64-1.txz May 2 09:44:45 Sakaar root: +============================================================================== May 2 09:44:45 Sakaar root: May 2 09:44:45 Sakaar root: Verifying package nut-plugin-2023.02.14-x86_64-1.txz. May 2 09:44:45 Sakaar root: Installing package nut-plugin-2023.02.14-x86_64-1.txz: May 2 09:44:45 Sakaar root: PACKAGE DESCRIPTION: May 2 09:44:45 Sakaar root: # NUT - Network UPS Tools (a collection of ups tools) unRAID Plugin May 2 09:44:45 Sakaar root: # May 2 09:44:45 Sakaar root: # The Network UPS Tools is a collection of programs which provide a May 2 09:44:45 Sakaar root: # common interface for monitoring and administering UPS hardware. It May 2 09:44:45 Sakaar root: # users a layered approach to connect all the components. Drivers are May 2 09:44:45 Sakaar root: # provided for a wide assortment of equipment. The primary goal of May 2 09:44:45 Sakaar root: # the NUT project is to provide reliable monitoring of UPS hardware May 2 09:44:45 Sakaar root: # and ensure safe shutdowns of the systems which are connected. May 2 09:44:45 Sakaar root: # This package includes the tools needed to monitor your UPS over the May 2 09:44:45 Sakaar root: # web and it also includes the upsclient library. May 2 09:44:45 Sakaar root: # May 2 09:44:45 Sakaar root: # https://github.com/dmacias72/unRAID-plugins May 2 09:44:45 Sakaar root: Executing install script for nut-plugin-2023.02.14-x86_64-1.txz. May 2 09:44:45 Sakaar groupadd[3187]: group added to /etc/group: name=nut, GID=218 May 2 09:44:45 Sakaar groupadd[3187]: group added to /etc/gshadow: name=nut May 2 09:44:45 Sakaar groupadd[3187]: new group: name=nut, GID=218 May 2 09:44:46 Sakaar useradd[3195]: new user: name=nut, UID=218, GID=218, home=/home/nut, shell=/bin/false, from=none May 2 09:44:46 Sakaar root: Package nut-plugin-2023.02.14-x86_64-1.txz installed. May 2 09:44:46 Sakaar root: stopping services... May 2 09:44:47 Sakaar root: Writing nut config May 2 09:44:47 Sakaar root: Updating permissions... May 2 09:44:47 Sakaar root: Adding UDEV lines to rc.6 May 2 09:44:47 Sakaar root: Adding UPS shutdown lines to rc.6 May 2 09:44:48 Sakaar root: Stopping the UPS services... May 2 09:44:50 Sakaar root: Network UPS Tools - UPS driver controller 2.7.4.1 May 2 09:44:50 Sakaar root: checking network ups tools configuration... May 2 09:44:51 Sakaar root: May 2 09:44:51 Sakaar root: ----------------------------------------------------------- May 2 09:44:51 Sakaar root: nut has been installed. May 2 09:44:51 Sakaar root: Copyright 2015, macester May 2 09:44:51 Sakaar root: Copyright 2020, gfjardim May 2 09:44:51 Sakaar root: Copyright 2015-2022, SimonFair May 2 09:44:51 Sakaar root: Version: 2023.02.14 May 2 09:44:51 Sakaar root: ----------------------------------------------------------- May 2 09:44:51 Sakaar root: May 2 09:44:51 Sakaar root: plugin: nut.plg installed ### [PREVIOUS LINE REPEATED 1 TIMES] ### May 2 09:44:51 Sakaar root: Executing hook script: post_plugin_checks May 2 09:44:51 Sakaar root: plugin: installing: parity.check.tuning.plg May 2 09:44:51 Sakaar root: Executing hook script: pre_plugin_checks May 2 09:44:51 Sakaar root: plugin: running: anonymous May 2 09:44:51 Sakaar root: plugin: skipping: /boot/config/plugins/parity.check.tuning/parity.check.tuning-2023.04.30.txz already exists May 2 09:44:51 Sakaar root: plugin: running: upgradepkg --install-new /boot/config/plugins/parity.check.tuning/parity.check.tuning-2023.04.30.txz May 2 09:44:51 Sakaar root: May 2 09:44:51 Sakaar root: +============================================================================== May 2 09:44:51 Sakaar root: | Installing new package /boot/config/plugins/parity.check.tuning/parity.check.tuning-2023.04.30.txz May 2 09:44:51 Sakaar root: +============================================================================== May 2 09:44:51 Sakaar root: May 2 09:44:51 Sakaar root: Verifying package parity.check.tuning-2023.04.30.txz. May 2 09:44:51 Sakaar root: Installing package parity.check.tuning-2023.04.30.txz: May 2 09:44:51 Sakaar root: PACKAGE DESCRIPTION: May 2 09:44:51 Sakaar root: Package parity.check.tuning-2023.04.30.txz installed. May 2 09:44:51 Sakaar root: plugin: running: anonymous May 2 09:44:51 Sakaar root: May 2 09:44:51 Sakaar root: ---------------------------------------------------- May 2 09:44:51 Sakaar root: parity.check.tuning has been installed. May 2 09:44:51 Sakaar root: Copyright 2019-2023, Dave Walker (itimpi) May 2 09:44:51 Sakaar root: Version: 2023.04.30 May 2 09:44:51 Sakaar root: ---------------------------------------------------- May 2 09:44:51 Sakaar root: May 2 09:44:51 Sakaar root: plugin: parity.check.tuning.plg installed ### [PREVIOUS LINE REPEATED 1 TIMES] ### May 2 09:44:51 Sakaar root: Executing hook script: post_plugin_checks May 2 09:44:51 Sakaar root: plugin: installing: unassigned.devices-plus.plg May 2 09:44:51 Sakaar root: Executing hook script: pre_plugin_checks May 2 09:44:51 Sakaar root: plugin: running: anonymous May 2 09:44:51 Sakaar root: plugin: checking: /boot/config/plugins/unassigned.devices-plus/packages/parted-3.3-x86_64-1.txz - MD5 May 2 09:44:51 Sakaar root: plugin: skipping: /boot/config/plugins/unassigned.devices-plus/packages/parted-3.3-x86_64-1.txz already exists May 2 09:44:51 Sakaar root: plugin: running: upgradepkg --install-new /boot/config/plugins/unassigned.devices-plus/packages/parted-3.3-x86_64-1.txz May 2 09:44:51 Sakaar root: May 2 09:44:51 Sakaar root: +============================================================================== May 2 09:44:51 Sakaar root: | Installing new package /boot/config/plugins/unassigned.devices-plus/packages/parted-3.3-x86_64-1.txz May 2 09:44:51 Sakaar root: +============================================================================== May 2 09:44:51 Sakaar root: May 2 09:44:51 Sakaar root: Verifying package parted-3.3-x86_64-1.txz. May 2 09:44:51 Sakaar root: Installing package parted-3.3-x86_64-1.txz: May 2 09:44:51 Sakaar root: PACKAGE DESCRIPTION: May 2 09:44:51 Sakaar root: # parted (GNU disk partitioning tool) May 2 09:44:51 Sakaar root: # May 2 09:44:51 Sakaar root: # GNU Parted is a program for creating, destroying, resizing, checking May 2 09:44:51 Sakaar root: # and copying partitions, and the filesystems on them. This is useful May 2 09:44:51 Sakaar root: # for creating space for new operating systems, reorganizing disk May 2 09:44:51 Sakaar root: # usage, copying data between hard disks, and disk imaging. May 2 09:44:51 Sakaar root: # May 2 09:44:51 Sakaar root: Executing install script for parted-3.3-x86_64-1.txz. May 2 09:44:51 Sakaar root: Package parted-3.3-x86_64-1.txz installed. May 2 09:44:51 Sakaar root: plugin: checking: /boot/config/plugins/unassigned.devices-plus/packages/parted-3.6-x86_64-1.txz - MD5 May 2 09:44:51 Sakaar root: plugin: skipping: /boot/config/plugins/unassigned.devices-plus/packages/parted-3.6-x86_64-1.txz already exists May 2 09:44:51 Sakaar root: plugin: running: upgradepkg --install-new /boot/config/plugins/unassigned.devices-plus/packages/parted-3.6-x86_64-1.txz May 2 09:44:51 Sakaar root: May 2 09:44:51 Sakaar root: +============================================================================== May 2 09:44:51 Sakaar root: | Upgrading parted-3.3-x86_64-1 package using /boot/config/plugins/unassigned.devices-plus/packages/parted-3.6-x86_64-1.txz May 2 09:44:51 Sakaar root: +============================================================================== May 2 09:44:51 Sakaar root: Pre-installing package parted-3.6-x86_64-1... May 2 09:44:51 Sakaar root: Removing package: parted-3.3-x86_64-1-upgraded-2023-05-02,09:44:51 May 2 09:44:51 Sakaar root: --> Deleting /usr/doc/parted-3.3/API May 2 09:44:51 Sakaar root: --> Deleting /usr/doc/parted-3.3/AUTHORS May 2 09:44:51 Sakaar root: --> Deleting /usr/doc/parted-3.3/BUGS May 2 09:44:51 Sakaar root: --> Deleting /usr/doc/parted-3.3/COPYING May 2 09:44:51 Sakaar root: --> Deleting /usr/doc/parted-3.3/ChangeLog May 2 09:44:51 Sakaar root: --> Deleting /usr/doc/parted-3.3/FAT May 2 09:44:51 Sakaar root: --> Deleting /usr/doc/parted-3.3/NEWS May 2 09:44:51 Sakaar root: --> Deleting /usr/doc/parted-3.3/README May 2 09:44:51 Sakaar root: --> Deleting /usr/doc/parted-3.3/THANKS May 2 09:44:51 Sakaar root: --> Deleting /usr/doc/parted-3.3/TODO May 2 09:44:51 Sakaar root: --> Deleting /usr/doc/parted-3.3/USER.jp May 2 09:44:51 Sakaar root: --> Deleting /usr/lib64/libparted-fs-resize.so.0.0.2 May 2 09:44:51 Sakaar root: --> Deleting /usr/lib64/libparted.so.2.0.2 May 2 09:44:51 Sakaar root: --> Deleting empty directory /usr/doc/parted-3.3/ May 2 09:44:51 Sakaar root: Verifying package parted-3.6-x86_64-1.txz. May 2 09:44:51 Sakaar root: Installing package parted-3.6-x86_64-1.txz: May 2 09:44:51 Sakaar root: PACKAGE DESCRIPTION: May 2 09:44:51 Sakaar root: # parted (GNU disk partitioning tool) May 2 09:44:51 Sakaar root: # May 2 09:44:51 Sakaar root: # GNU Parted is a program for creating, destroying, resizing, checking May 2 09:44:51 Sakaar root: # and copying partitions, and the filesystems on them. This is useful May 2 09:44:51 Sakaar root: # for creating space for new operating systems, reorganizing disk May 2 09:44:51 Sakaar root: # usage, copying data between hard disks, and disk imaging. May 2 09:44:51 Sakaar root: # May 2 09:44:51 Sakaar root: Executing install script for parted-3.6-x86_64-1.txz. May 2 09:44:51 Sakaar root: Package parted-3.6-x86_64-1.txz installed. May 2 09:44:51 Sakaar root: Package parted-3.3-x86_64-1 upgraded with new package /boot/config/plugins/unassigned.devices-plus/packages/parted-3.6-x86_64-1.txz. May 2 09:44:51 Sakaar root: plugin: checking: /boot/config/plugins/unassigned.devices-plus/packages/exfat-utils-1.3.0-x86_64-1_slonly.txz - MD5 May 2 09:44:51 Sakaar root: plugin: skipping: /boot/config/plugins/unassigned.devices-plus/packages/exfat-utils-1.3.0-x86_64-1_slonly.txz already exists May 2 09:44:51 Sakaar root: plugin: running: upgradepkg --install-new /boot/config/plugins/unassigned.devices-plus/packages/exfat-utils-1.3.0-x86_64-1_slonly.txz May 2 09:44:51 Sakaar root: May 2 09:44:51 Sakaar root: +============================================================================== May 2 09:44:51 Sakaar root: | Installing new package /boot/config/plugins/unassigned.devices-plus/packages/exfat-utils-1.3.0-x86_64-1_slonly.txz May 2 09:44:51 Sakaar root: +============================================================================== May 2 09:44:51 Sakaar root: May 2 09:44:52 Sakaar root: Verifying package exfat-utils-1.3.0-x86_64-1_slonly.txz. May 2 09:44:52 Sakaar root: Installing package exfat-utils-1.3.0-x86_64-1_slonly.txz: May 2 09:44:52 Sakaar root: PACKAGE DESCRIPTION: May 2 09:44:52 Sakaar root: # exfat-utils (exFAT system utilities) May 2 09:44:52 Sakaar root: # May 2 09:44:52 Sakaar root: # This project aims to provide a full-featured exFAT file system May 2 09:44:52 Sakaar root: # implementation for GNU/Linux and other Unix-like systems as a FUSE May 2 09:44:52 Sakaar root: # module and a set of utilities. May 2 09:44:52 Sakaar root: # module. May 2 09:44:52 Sakaar root: # May 2 09:44:52 Sakaar root: # This package contains the utilities. May 2 09:44:52 Sakaar root: # May 2 09:44:52 Sakaar root: # Homepage: https://github.com/relan/exfat May 2 09:44:52 Sakaar root: # May 2 09:44:52 Sakaar root: Executing install script for exfat-utils-1.3.0-x86_64-1_slonly.txz. May 2 09:44:52 Sakaar root: Package exfat-utils-1.3.0-x86_64-1_slonly.txz installed. May 2 09:44:52 Sakaar root: plugin: checking: /boot/config/plugins/unassigned.devices-plus/packages/fuse-exfat-1.3.0-x86_64-1_slonly.txz - MD5 May 2 09:44:52 Sakaar root: plugin: skipping: /boot/config/plugins/unassigned.devices-plus/packages/fuse-exfat-1.3.0-x86_64-1_slonly.txz already exists May 2 09:44:52 Sakaar root: plugin: running: upgradepkg --install-new /boot/config/plugins/unassigned.devices-plus/packages/fuse-exfat-1.3.0-x86_64-1_slonly.txz May 2 09:44:52 Sakaar root: May 2 09:44:52 Sakaar root: +============================================================================== May 2 09:44:52 Sakaar root: | Installing new package /boot/config/plugins/unassigned.devices-plus/packages/fuse-exfat-1.3.0-x86_64-1_slonly.txz May 2 09:44:52 Sakaar root: +============================================================================== May 2 09:44:52 Sakaar root: May 2 09:44:52 Sakaar root: Verifying package fuse-exfat-1.3.0-x86_64-1_slonly.txz. May 2 09:44:52 Sakaar root: Installing package fuse-exfat-1.3.0-x86_64-1_slonly.txz: May 2 09:44:52 Sakaar root: PACKAGE DESCRIPTION: May 2 09:44:52 Sakaar root: # fuse-exfat (exFAT FUSE module) May 2 09:44:52 Sakaar root: # May 2 09:44:52 Sakaar root: # This project aims to provide a full-featured exFAT file system May 2 09:44:52 Sakaar root: # implementation for GNU/Linux and other Unix-like systems as a FUSE May 2 09:44:52 Sakaar root: # module and a set of utilities. May 2 09:44:52 Sakaar root: # module. May 2 09:44:52 Sakaar root: # May 2 09:44:52 Sakaar root: # This package contains the FUSE module. May 2 09:44:52 Sakaar root: # May 2 09:44:52 Sakaar root: # Homepage: https://github.com/relan/exfat May 2 09:44:52 Sakaar root: # May 2 09:44:52 Sakaar root: Executing install script for fuse-exfat-1.3.0-x86_64-1_slonly.txz. May 2 09:44:52 Sakaar root: Package fuse-exfat-1.3.0-x86_64-1_slonly.txz installed. May 2 09:44:52 Sakaar root: plugin: checking: /boot/config/plugins/unassigned.devices-plus/packages/hfsprogs-332.25-x86_64-2sl.txz - MD5 May 2 09:44:52 Sakaar root: plugin: skipping: /boot/config/plugins/unassigned.devices-plus/packages/hfsprogs-332.25-x86_64-2sl.txz already exists May 2 09:44:52 Sakaar root: plugin: running: upgradepkg --install-new /boot/config/plugins/unassigned.devices-plus/packages/hfsprogs-332.25-x86_64-2sl.txz May 2 09:44:52 Sakaar root: May 2 09:44:52 Sakaar root: +============================================================================== May 2 09:44:52 Sakaar root: | Installing new package /boot/config/plugins/unassigned.devices-plus/packages/hfsprogs-332.25-x86_64-2sl.txz May 2 09:44:52 Sakaar root: +============================================================================== May 2 09:44:52 Sakaar root: May 2 09:44:52 Sakaar root: Verifying package hfsprogs-332.25-x86_64-2sl.txz. May 2 09:44:52 Sakaar root: Installing package hfsprogs-332.25-x86_64-2sl.txz: May 2 09:44:52 Sakaar root: PACKAGE DESCRIPTION: May 2 09:44:52 Sakaar root: # hfsprogs - hfs+ user space utils May 2 09:44:52 Sakaar root: # May 2 09:44:52 Sakaar root: # The HFS+ file system used by Apple Computer for their Mac OS is May 2 09:44:52 Sakaar root: # supported by the Linux kernel. Apple provides mkfs and fsck for May 2 09:44:52 Sakaar root: # HFS+ with the Unix core of their operating system, Darwin. May 2 09:44:52 Sakaar root: # May 2 09:44:52 Sakaar root: # This package is a port of Apple's tools for HFS+ filesystems. May 2 09:44:52 Sakaar root: # May 2 09:44:52 Sakaar root: # http://www.opensource.apple.com May 2 09:44:52 Sakaar root: Package hfsprogs-332.25-x86_64-2sl.txz installed. May 2 09:44:52 Sakaar root: plugin: checking: /boot/config/plugins/unassigned.devices-plus/packages/libbsd-0.11.7-x86_64-1cf.txz - MD5 May 2 09:44:52 Sakaar root: plugin: skipping: /boot/config/plugins/unassigned.devices-plus/packages/libbsd-0.11.7-x86_64-1cf.txz already exists May 2 09:44:52 Sakaar root: plugin: running: upgradepkg --install-new /boot/config/plugins/unassigned.devices-plus/packages/libbsd-0.11.7-x86_64-1cf.txz May 2 09:44:52 Sakaar root: May 2 09:44:52 Sakaar root: +============================================================================== May 2 09:44:52 Sakaar root: | Installing new package /boot/config/plugins/unassigned.devices-plus/packages/libbsd-0.11.7-x86_64-1cf.txz May 2 09:44:52 Sakaar root: +============================================================================== May 2 09:44:52 Sakaar root: May 2 09:44:52 Sakaar root: Verifying package libbsd-0.11.7-x86_64-1cf.txz. May 2 09:44:52 Sakaar root: Installing package libbsd-0.11.7-x86_64-1cf.txz: May 2 09:44:52 Sakaar root: PACKAGE DESCRIPTION: May 2 09:44:52 Sakaar root: # libbsd (library of BSD functions) May 2 09:44:52 Sakaar root: # May 2 09:44:52 Sakaar root: # This library provides useful functions commonly found on BSD systems, May 2 09:44:52 Sakaar root: # and lacking on others like GNU systems, thus making it easier to port May 2 09:44:52 Sakaar root: # projects with strong BSD origins, without needing to embed the same May 2 09:44:52 Sakaar root: # code over and over again on each project. May 2 09:44:52 Sakaar root: # May 2 09:44:52 Sakaar usbhid-ups[4442]: Startup successful May 2 09:44:52 Sakaar root: Executing install script for libbsd-0.11.7-x86_64-1cf.txz. May 2 09:44:52 Sakaar root: Package libbsd-0.11.7-x86_64-1cf.txz installed. May 2 09:44:52 Sakaar root: plugin: checking: /boot/config/plugins/unassigned.devices-plus/packages/apfsfuse-v20200708-x86_64-1.txz - MD5 May 2 09:44:52 Sakaar root: plugin: skipping: /boot/config/plugins/unassigned.devices-plus/packages/apfsfuse-v20200708-x86_64-1.txz already exists May 2 09:44:52 Sakaar root: plugin: running: upgradepkg --install-new /boot/config/plugins/unassigned.devices-plus/packages/apfsfuse-v20200708-x86_64-1.txz May 2 09:44:52 Sakaar root: May 2 09:44:52 Sakaar root: +============================================================================== May 2 09:44:52 Sakaar root: | Installing new package /boot/config/plugins/unassigned.devices-plus/packages/apfsfuse-v20200708-x86_64-1.txz May 2 09:44:52 Sakaar root: +============================================================================== May 2 09:44:52 Sakaar root: May 2 09:44:52 Sakaar root: Verifying package apfsfuse-v20200708-x86_64-1.txz. May 2 09:44:52 Sakaar root: Installing package apfsfuse-v20200708-x86_64-1.txz: May 2 09:44:52 Sakaar root: PACKAGE DESCRIPTION: May 2 09:44:52 Sakaar root: # apfs-fuse v20200708 May 2 09:44:52 Sakaar root: # May 2 09:44:52 Sakaar root: # Custom apfs-fuse v20200708 package for Unraid by ich777 May 2 09:44:52 Sakaar root: # https://github.com/sgan81/apfs-fuse May 2 09:44:52 Sakaar root: Package apfsfuse-v20200708-x86_64-1.txz installed. May 2 09:44:52 Sakaar root: plugin: creating: /usr/local/emhttp/plugins/unassigned.devices-plus/README.md - from INLINE content May 2 09:44:52 Sakaar root: plugin: running: anonymous May 2 09:44:52 Sakaar root: May 2 09:44:52 Sakaar root: ----------------------------------------------------------- May 2 09:44:52 Sakaar root: unassigned.devices-plus has been installed. May 2 09:44:52 Sakaar root: Copyright 2015, gfjardim May 2 09:44:52 Sakaar root: Copyright 2016-2023, dlandon May 2 09:44:52 Sakaar root: Version: 2023.04.15 May 2 09:44:52 Sakaar root: ----------------------------------------------------------- May 2 09:44:52 Sakaar root: May 2 09:44:52 Sakaar root: plugin: unassigned.devices-plus.plg installed ### [PREVIOUS LINE REPEATED 1 TIMES] ### May 2 09:44:52 Sakaar root: Executing hook script: post_plugin_checks May 2 09:44:52 Sakaar root: plugin: installing: unassigned.devices.plg May 2 09:44:52 Sakaar root: Executing hook script: pre_plugin_checks May 2 09:44:52 Sakaar root: plugin: checking: /boot/config/plugins/unassigned.devices/unassigned.devices-2023.04.30.tgz - MD5 May 2 09:44:52 Sakaar root: plugin: skipping: /boot/config/plugins/unassigned.devices/unassigned.devices-2023.04.30.tgz already exists May 2 09:44:52 Sakaar root: plugin: running: anonymous May 2 09:44:52 Sakaar root: plugin: creating: /tmp/start_unassigned_devices - from INLINE content May 2 09:44:52 Sakaar root: plugin: setting: /tmp/start_unassigned_devices - mode to 0770 May 2 09:44:52 Sakaar root: plugin: skipping: /boot/config/plugins/unassigned.devices/unassigned.devices.cfg already exists May 2 09:44:52 Sakaar root: plugin: skipping: /boot/config/plugins/unassigned.devices/samba_mount.cfg already exists May 2 09:44:52 Sakaar root: plugin: skipping: /boot/config/plugins/unassigned.devices/iso_mount.cfg already exists May 2 09:44:52 Sakaar root: plugin: creating: /tmp/unassigned.devices/add-smb - from INLINE content May 2 09:44:52 Sakaar root: plugin: setting: /tmp/unassigned.devices/add-smb - mode to 0770 May 2 09:44:52 Sakaar root: plugin: running: anonymous May 2 09:44:52 Sakaar root: May 2 09:44:52 Sakaar root: ----------------------------------------------------------- May 2 09:44:52 Sakaar root: unassigned.devices has been installed. May 2 09:44:52 Sakaar root: Copyright 2015, gfjardim May 2 09:44:52 Sakaar root: Copyright 2016-2023, dlandon May 2 09:44:52 Sakaar root: Version: 2023.04.30 May 2 09:44:52 Sakaar root: May 2 09:44:52 Sakaar root: Note: May 2 09:44:52 Sakaar root: Install the Unassigned Devices Plus plugin if you need to May 2 09:44:52 Sakaar root: mount exFAT, HFS+, apfs file formats or format disks. May 2 09:44:52 Sakaar root: ----------------------------------------------------------- May 2 09:44:52 Sakaar root: May 2 09:44:52 Sakaar root: plugin: unassigned.devices.plg installed ### [PREVIOUS LINE REPEATED 1 TIMES] ### May 2 09:44:52 Sakaar root: Executing hook script: post_plugin_checks May 2 09:44:52 Sakaar unassigned.devices: Updating share settings... May 2 09:44:52 Sakaar root: plugin: installing: user.scripts.plg May 2 09:44:52 Sakaar root: Executing hook script: pre_plugin_checks May 2 09:44:52 Sakaar root: plugin: checking: /boot/config/plugins/user.scripts/user.scripts-2023.03.29-x86_64-1.txz - MD5 May 2 09:44:52 Sakaar root: plugin: skipping: /boot/config/plugins/user.scripts/user.scripts-2023.03.29-x86_64-1.txz already exists May 2 09:44:52 Sakaar root: plugin: running: upgradepkg --install-new /boot/config/plugins/user.scripts/user.scripts-2023.03.29-x86_64-1.txz May 2 09:44:52 Sakaar root: May 2 09:44:52 Sakaar root: +============================================================================== May 2 09:44:52 Sakaar root: | Installing new package /boot/config/plugins/user.scripts/user.scripts-2023.03.29-x86_64-1.txz May 2 09:44:52 Sakaar root: +============================================================================== May 2 09:44:52 Sakaar root: May 2 09:44:52 Sakaar unassigned.devices: Share settings updated. May 2 09:44:52 Sakaar root: Verifying package user.scripts-2023.03.29-x86_64-1.txz. May 2 09:44:52 Sakaar root: Installing package user.scripts-2023.03.29-x86_64-1.txz: May 2 09:44:52 Sakaar root: PACKAGE DESCRIPTION: May 2 09:44:52 Sakaar dhcpcd[1398]: br0: no IPv6 Routers available May 2 09:44:52 Sakaar root: Package user.scripts-2023.03.29-x86_64-1.txz installed. May 2 09:44:52 Sakaar root: plugin: running: anonymous May 2 09:44:52 Sakaar root: ### [PREVIOUS LINE REPEATED 2 TIMES] ### May 2 09:44:52 Sakaar root: plugin: running: anonymous May 2 09:44:52 Sakaar root: May 2 09:44:52 Sakaar root: ---------------------------------------------------- May 2 09:44:52 Sakaar root: user.scripts has been installed. May 2 09:44:52 Sakaar root: Copyright 2016-2023, Andrew Zawadzki May 2 09:44:52 Sakaar root: Version: 2023.03.29 May 2 09:44:52 Sakaar root: ---------------------------------------------------- May 2 09:44:52 Sakaar root: May 2 09:44:52 Sakaar root: plugin: user.scripts.plg installed ### [PREVIOUS LINE REPEATED 1 TIMES] ### May 2 09:44:52 Sakaar root: Executing hook script: post_plugin_checks May 2 09:44:52 Sakaar root: Installing language packs May 2 09:44:52 Sakaar root: Starting go script May 2 09:44:52 Sakaar root: Starting emhttpd May 2 09:44:52 Sakaar emhttpd: Unraid(tm) System Management Utility version 6.12.0-rc5 May 2 09:44:52 Sakaar emhttpd: Copyright (C) 2005-2023, Lime Technology, Inc. May 2 09:44:53 Sakaar emhttpd: shcmd (3): /usr/local/emhttp/webGui/scripts/update_access May 2 09:44:53 Sakaar sshd[1491]: Received signal 15; terminating. May 2 09:44:53 Sakaar upsd[5005]: listening on 0.0.0.0 port 3493 May 2 09:44:53 Sakaar upsd[5005]: Connected to UPS [ups]: usbhid-ups-ups May 2 09:44:53 Sakaar upsd[5006]: Startup successful May 2 09:44:53 Sakaar upsmon[5009]: Startup successful May 2 09:44:53 Sakaar upsd[5006]: User [email protected] logged into UPS [ups] May 2 09:44:54 Sakaar sshd[5017]: Server listening on 0.0.0.0 port 22. May 2 09:44:54 Sakaar sshd[5017]: Server listening on :: port 22. May 2 09:44:55 Sakaar emhttpd: shcmd (5): /sbin/modprobe md-mod super=/boot/config/super.dat May 2 09:44:55 Sakaar kernel: md: unRAID driver 2.9.27 installed May 2 09:44:55 Sakaar emhttpd: Plus key detected, GUID: 0..8 FILE: /boot/config/Plus.key May 2 09:44:55 Sakaar emhttpd: Device inventory: May 2 09:44:55 Sakaar emhttpd: ST6000VN001-2BB186_ZR12J796 (sdj) 512 11721045168 May 2 09:44:55 Sakaar emhttpd: WDC_WD60EFAX-68SHWN0_WD-WX21D39PL4U0 (sdk) 512 11721045168 May 2 09:44:55 Sakaar emhttpd: ST12000VN0008-2YS101_ZRT085FE (sdh) 512 23437770752 May 2 09:44:55 Sakaar emhttpd: ST6000VN0033-2EE110_ZAD6JM5Q (sdg) 512 11721045168 May 2 09:44:55 Sakaar emhttpd: TOSHIBA_HDWG21C_Z1U0A03TFP8G (sdd) 512 23437770752 May 2 09:44:55 Sakaar emhttpd: TOSHIBA_HDWG11A_X150A09EFATG (sde) 512 19532873728 May 2 09:44:55 Sakaar emhttpd: Samsung_SSD_840_Series_S14CNEBD106747W (sdf) 512 234441648 May 2 09:44:55 Sakaar emhttpd: TOSHIBA_HDWN160_69I6K0K3FAXG (sdc) 512 11721045168 May 2 09:44:55 Sakaar emhttpd: WDC_WDS100T2B0C_21334A466205 (nvme0n1) 512 1953525168 May 2 09:44:55 Sakaar emhttpd: TOSHIBA_MG06ACA10TE_3040A0FNFKQE (sdi) 512 19532873728 May 2 09:44:55 Sakaar emhttpd: SanDisk__Cruzer_Fit_00004903061421211718-0:0 (sda) 512 121061376 May 2 09:44:55 Sakaar kernel: mdcmd (1): import 0 sdd 64 11718885324 0 TOSHIBA_HDWG21C_Z1U0A03TFP8G May 2 09:44:55 Sakaar kernel: md: import disk0: (sdd) TOSHIBA_HDWG21C_Z1U0A03TFP8G size: 11718885324 May 2 09:44:55 Sakaar kernel: mdcmd (2): import 1 sdc 64 5860522532 0 TOSHIBA_HDWN160_69I6K0K3FAXG May 2 09:44:55 Sakaar kernel: md: import disk1: (sdc) TOSHIBA_HDWN160_69I6K0K3FAXG size: 5860522532 May 2 09:44:55 Sakaar kernel: mdcmd (3): import 2 sdk 64 5860522532 0 WDC_WD60EFAX-68SHWN0_WD-WX21D39PL4U0 May 2 09:44:55 Sakaar kernel: md: import disk2: (sdk) WDC_WD60EFAX-68SHWN0_WD-WX21D39PL4U0 size: 5860522532 May 2 09:44:55 Sakaar kernel: mdcmd (4): import 3 sdi 64 9766436812 0 TOSHIBA_MG06ACA10TE_3040A0FNFKQE May 2 09:44:55 Sakaar kernel: md: import disk3: (sdi) TOSHIBA_MG06ACA10TE_3040A0FNFKQE size: 9766436812 May 2 09:44:55 Sakaar kernel: mdcmd (5): import 4 sdg 64 5860522532 0 ST6000VN0033-2EE110_ZAD6JM5Q May 2 09:44:55 Sakaar kernel: md: import disk4: (sdg) ST6000VN0033-2EE110_ZAD6JM5Q size: 5860522532 May 2 09:44:55 Sakaar kernel: mdcmd (6): import 5 sdj 64 5860522532 0 ST6000VN001-2BB186_ZR12J796 May 2 09:44:55 Sakaar kernel: md: import disk5: (sdj) ST6000VN001-2BB186_ZR12J796 size: 5860522532 May 2 09:44:55 Sakaar kernel: mdcmd (7): import 6 sde 64 9766436812 0 TOSHIBA_HDWG11A_X150A09EFATG May 2 09:44:55 Sakaar kernel: md: import disk6: (sde) TOSHIBA_HDWG11A_X150A09EFATG size: 9766436812 May 2 09:44:55 Sakaar kernel: mdcmd (8): import 7 sdh 64 11718885324 0 ST12000VN0008-2YS101_ZRT085FE May 2 09:44:55 Sakaar kernel: md: import disk7: (sdh) ST12000VN0008-2YS101_ZRT085FE size: 11718885324 May 2 09:44:55 Sakaar kernel: mdcmd (9): import 8 May 2 09:44:55 Sakaar kernel: mdcmd (10): import 9 May 2 09:44:55 Sakaar kernel: mdcmd (11): import 10 May 2 09:44:55 Sakaar kernel: mdcmd (12): import 11 May 2 09:44:55 Sakaar kernel: mdcmd (13): import 12 May 2 09:44:55 Sakaar kernel: mdcmd (14): import 13 May 2 09:44:55 Sakaar kernel: mdcmd (15): import 14 May 2 09:44:55 Sakaar kernel: mdcmd (16): import 15 May 2 09:44:55 Sakaar kernel: mdcmd (17): import 16 May 2 09:44:55 Sakaar kernel: mdcmd (18): import 17 May 2 09:44:55 Sakaar kernel: mdcmd (19): import 18 May 2 09:44:55 Sakaar kernel: mdcmd (20): import 19 May 2 09:44:55 Sakaar kernel: mdcmd (21): import 20 May 2 09:44:55 Sakaar kernel: mdcmd (22): import 21 May 2 09:44:55 Sakaar kernel: mdcmd (23): import 22 May 2 09:44:55 Sakaar kernel: mdcmd (24): import 23 May 2 09:44:55 Sakaar kernel: mdcmd (25): import 24 May 2 09:44:55 Sakaar kernel: mdcmd (26): import 25 May 2 09:44:55 Sakaar kernel: mdcmd (27): import 26 May 2 09:44:55 Sakaar kernel: mdcmd (28): import 27 May 2 09:44:55 Sakaar kernel: mdcmd (29): import 28 May 2 09:44:55 Sakaar kernel: mdcmd (30): import 29 May 2 09:44:55 Sakaar kernel: md: import_slot: 29 empty May 2 09:44:55 Sakaar emhttpd: import 30 cache device: (nvme0n1) WDC_WDS100T2B0C_21334A466205 May 2 09:44:55 Sakaar emhttpd: import flash device: sda May 2 09:44:55 Sakaar emhttpd: read SMART /dev/sdj May 2 09:44:55 Sakaar emhttpd: read SMART /dev/sdk May 2 09:44:55 Sakaar emhttpd: read SMART /dev/sdh May 2 09:44:55 Sakaar emhttpd: read SMART /dev/sdg May 2 09:44:55 Sakaar emhttpd: read SMART /dev/sdd May 2 09:44:55 Sakaar emhttpd: read SMART /dev/sde May 2 09:44:55 Sakaar emhttpd: read SMART /dev/sdf May 2 09:44:55 Sakaar emhttpd: read SMART /dev/sdc May 2 09:44:55 Sakaar emhttpd: read SMART /dev/nvme0n1 May 2 09:44:55 Sakaar emhttpd: read SMART /dev/sdi May 2 09:44:55 Sakaar emhttpd: read SMART /dev/sda May 2 09:44:55 Sakaar emhttpd: Starting services... May 2 09:44:55 Sakaar emhttpd: shcmd (24): /etc/rc.d/rc.samba restart May 2 09:44:55 Sakaar wsdd2[1555]: 'Terminated' signal received. May 2 09:44:55 Sakaar winbindd[1558]: [2023/05/02 09:44:55.559816, 0] ../../source3/winbindd/winbindd_dual.c:1957(winbindd_sig_term_handler) May 2 09:44:55 Sakaar winbindd[1558]: Got sig[15] terminate (is_parent=1) May 2 09:44:55 Sakaar nmbd[1545]: [2023/05/02 09:44:55.559813, 0] ../../source3/nmbd/nmbd.c:59(terminate) May 2 09:44:55 Sakaar nmbd[1545]: Got SIGTERM: going down... May 2 09:44:55 Sakaar winbindd[1568]: [2023/05/02 09:44:55.559816, 0] ../../source3/winbindd/winbindd_dual.c:1957(winbindd_sig_term_handler) May 2 09:44:55 Sakaar winbindd[1568]: Got sig[15] terminate (is_parent=0) May 2 09:44:55 Sakaar winbindd[3188]: [2023/05/02 09:44:55.559833, 0] ../../source3/winbindd/winbindd_dual.c:1957(winbindd_sig_term_handler) May 2 09:44:55 Sakaar winbindd[3188]: Got sig[15] terminate (is_parent=0) May 2 09:44:55 Sakaar wsdd2[1555]: terminating. May 2 09:44:57 Sakaar root: Starting Samba: /usr/sbin/smbd -D May 2 09:44:57 Sakaar smbd[5123]: [2023/05/02 09:44:57.701610, 0] ../../source3/smbd/server.c:1741(main) May 2 09:44:57 Sakaar smbd[5123]: smbd version 4.17.7 started. May 2 09:44:57 Sakaar smbd[5123]: Copyright Andrew Tridgell and the Samba Team 1992-2022 May 2 09:44:57 Sakaar root: /usr/sbin/nmbd -D May 2 09:44:57 Sakaar nmbd[5125]: [2023/05/02 09:44:57.712349, 0] ../../source3/nmbd/nmbd.c:901(main) May 2 09:44:57 Sakaar nmbd[5125]: nmbd version 4.17.7 started. May 2 09:44:57 Sakaar nmbd[5125]: Copyright Andrew Tridgell and the Samba Team 1992-2022 May 2 09:44:57 Sakaar root: /usr/sbin/wsdd2 -d May 2 09:44:57 Sakaar root: /usr/sbin/winbindd -D May 2 09:44:57 Sakaar wsdd2[5139]: starting. May 2 09:44:57 Sakaar winbindd[5140]: [2023/05/02 09:44:57.757481, 0] ../../source3/winbindd/winbindd.c:1440(main) May 2 09:44:57 Sakaar winbindd[5140]: winbindd version 4.17.7 started. May 2 09:44:57 Sakaar winbindd[5140]: Copyright Andrew Tridgell and the Samba Team 1992-2022 May 2 09:44:57 Sakaar winbindd[5142]: [2023/05/02 09:44:57.759602, 0] ../../source3/winbindd/winbindd_cache.c:3116(initialize_winbindd_cache) May 2 09:44:57 Sakaar winbindd[5142]: initialize_winbindd_cache: clearing cache and re-creating with version number 2 May 2 09:44:57 Sakaar emhttpd: shcmd (28): /etc/rc.d/rc.avahidaemon start May 2 09:44:57 Sakaar root: Starting Avahi mDNS/DNS-SD Daemon: /usr/sbin/avahi-daemon -D May 2 09:44:57 Sakaar avahi-daemon[5169]: Found user 'avahi' (UID 61) and group 'avahi' (GID 214). May 2 09:44:57 Sakaar avahi-daemon[5169]: Successfully dropped root privileges. May 2 09:44:57 Sakaar avahi-daemon[5169]: avahi-daemon 0.8 starting up. May 2 09:44:57 Sakaar avahi-daemon[5169]: Successfully called chroot(). May 2 09:44:57 Sakaar avahi-daemon[5169]: Successfully dropped remaining capabilities. May 2 09:44:57 Sakaar avahi-daemon[5169]: Loading service file /services/sftp-ssh.service. May 2 09:44:57 Sakaar avahi-daemon[5169]: Loading service file /services/smb.service. May 2 09:44:57 Sakaar avahi-daemon[5169]: Loading service file /services/ssh.service. May 2 09:44:57 Sakaar avahi-daemon[5169]: Joining mDNS multicast group on interface br0.IPv6 with address fe80::1ac0:4dff:feeb:9260. May 2 09:44:57 Sakaar avahi-daemon[5169]: New relevant interface br0.IPv6 for mDNS. May 2 09:44:57 Sakaar avahi-daemon[5169]: Joining mDNS multicast group on interface br0.IPv4 with address 192.168.1.106. May 2 09:44:57 Sakaar avahi-daemon[5169]: New relevant interface br0.IPv4 for mDNS. May 2 09:44:57 Sakaar avahi-daemon[5169]: Network interface enumeration completed. May 2 09:44:57 Sakaar avahi-daemon[5169]: Registering new address record for fe80::1ac0:4dff:feeb:9260 on br0.*. May 2 09:44:57 Sakaar avahi-daemon[5169]: Registering new address record for 192.168.1.106 on br0.IPv4. May 2 09:44:57 Sakaar emhttpd: shcmd (29): /etc/rc.d/rc.avahidnsconfd start May 2 09:44:57 Sakaar root: Starting Avahi mDNS/DNS-SD DNS Server Configuration Daemon: /usr/sbin/avahi-dnsconfd -D May 2 09:44:57 Sakaar avahi-dnsconfd[5178]: Successfully connected to Avahi daemon. May 2 09:44:57 Sakaar emhttpd: Autostart enabled May 2 09:44:58 Sakaar avahi-daemon[5169]: Server startup complete. Host name is Sakaar.local. Local service cookie is 2557488284. May 2 09:44:59 Sakaar avahi-daemon[5169]: Service "Sakaar" (/services/ssh.service) successfully established. May 2 09:44:59 Sakaar avahi-daemon[5169]: Service "Sakaar" (/services/smb.service) successfully established. May 2 09:44:59 Sakaar avahi-daemon[5169]: Service "Sakaar" (/services/sftp-ssh.service) successfully established. May 2 09:44:59 Sakaar emhttpd: shcmd (34): /etc/rc.d/rc.php-fpm start May 2 09:44:59 Sakaar root: Starting php-fpm done May 2 09:44:59 Sakaar emhttpd: shcmd (35): /etc/rc.d/rc.unraid-api install May 2 09:45:00 Sakaar root: unraid-api installed May 2 09:45:00 Sakaar emhttpd: shcmd (36): /etc/rc.d/rc.nginx start May 2 09:45:00 Sakaar root: Starting Nginx server daemon... May 2 09:45:00 Sakaar root: Starting [email protected] May 2 09:45:01 Sakaar root: Watch Setup on Config Path: /boot/config/plugins/dynamix.my.servers/myservers.cfg May 2 09:45:01 Sakaar emhttpd: shcmd (37): /etc/rc.d/rc.flash_backup start May 2 09:45:01 Sakaar flash_backup: flush: /usr/local/emhttp/plugins/dynamix.my.servers/scripts/UpdateFlashBackup update May 2 09:45:01 Sakaar flash_backup: start watching for file changes May 2 09:45:02 Sakaar kernel: mdcmd (31): set md_num_stripes 1280 May 2 09:45:02 Sakaar kernel: mdcmd (32): set md_queue_limit 80 May 2 09:45:02 Sakaar kernel: mdcmd (33): set md_sync_limit 5 May 2 09:45:02 Sakaar kernel: mdcmd (34): set md_write_method May 2 09:45:02 Sakaar kernel: mdcmd (35): start STOPPED May 2 09:45:02 Sakaar kernel: unraid: allocating 46470K for 1280 stripes (9 disks) May 2 09:45:02 Sakaar kernel: md1p1: running, size: 5860522532 blocks May 2 09:45:02 Sakaar kernel: md2p1: running, size: 5860522532 blocks May 2 09:45:02 Sakaar kernel: md3p1: running, size: 9766436812 blocks May 2 09:45:02 Sakaar kernel: md4p1: running, size: 5860522532 blocks May 2 09:45:02 Sakaar kernel: md5p1: running, size: 5860522532 blocks May 2 09:45:02 Sakaar kernel: md6p1: running, size: 9766436812 blocks May 2 09:45:02 Sakaar kernel: md7p1: running, size: 11718885324 blocks May 2 09:45:02 Sakaar emhttpd: shcmd (39): udevadm settle May 2 09:45:02 Sakaar emhttpd: Opening encrypted volumes... May 2 09:45:02 Sakaar emhttpd: shcmd (40): touch /boot/config/forcesync May 2 09:45:02 Sakaar unraid-api[5774]: ✔️ UNRAID API started successfully! May 2 09:45:02 Sakaar emhttpd: Mounting disks... May 2 09:45:02 Sakaar emhttpd: mounting /mnt/disk1 May 2 09:45:02 Sakaar emhttpd: shcmd (41): mkdir -p /mnt/disk1 May 2 09:45:02 Sakaar emhttpd: shcmd (42): mount -t xfs -o noatime,nouuid /dev/md1p1 /mnt/disk1 May 2 09:45:02 Sakaar kernel: SGI XFS with ACLs, security attributes, no debug enabled May 2 09:45:02 Sakaar kernel: XFS (md1p1): Mounting V5 Filesystem May 2 09:45:03 Sakaar kernel: XFS (md1p1): Ending clean mount May 2 09:45:03 Sakaar kernel: xfs filesystem being mounted at /mnt/disk1 supports timestamps until 2038 (0x7fffffff) May 2 09:45:03 Sakaar emhttpd: shcmd (43): xfs_growfs /mnt/disk1 May 2 09:45:03 Sakaar root: meta-data=/dev/md1p1 isize=512 agcount=6, agsize=268435455 blks May 2 09:45:03 Sakaar root: = sectsz=512 attr=2, projid32bit=1 May 2 09:45:03 Sakaar root: = crc=1 finobt=1, sparse=1, rmapbt=0 May 2 09:45:03 Sakaar root: = reflink=1 bigtime=0 inobtcount=0 nrext64=0 May 2 09:45:03 Sakaar root: data = bsize=4096 blocks=1465130633, imaxpct=5 May 2 09:45:03 Sakaar root: = sunit=0 swidth=0 blks May 2 09:45:03 Sakaar root: naming =version 2 bsize=4096 ascii-ci=0, ftype=1 May 2 09:45:03 Sakaar root: log =internal log bsize=4096 blocks=521728, version=2 May 2 09:45:03 Sakaar root: = sectsz=512 sunit=0 blks, lazy-count=1 May 2 09:45:03 Sakaar root: realtime =none extsz=4096 blocks=0, rtextents=0 May 2 09:45:03 Sakaar emhttpd: mounting /mnt/disk2 May 2 09:45:03 Sakaar emhttpd: shcmd (44): mkdir -p /mnt/disk2 May 2 09:45:03 Sakaar emhttpd: shcmd (45): mount -t xfs -o noatime,nouuid /dev/md2p1 /mnt/disk2 May 2 09:45:03 Sakaar kernel: XFS (md2p1): Mounting V5 Filesystem May 2 09:45:03 Sakaar kernel: XFS (md2p1): Ending clean mount May 2 09:45:03 Sakaar emhttpd: shcmd (46): xfs_growfs /mnt/disk2 May 2 09:45:03 Sakaar kernel: xfs filesystem being mounted at /mnt/disk2 supports timestamps until 2038 (0x7fffffff) May 2 09:45:03 Sakaar root: meta-data=/dev/md2p1 isize=512 agcount=6, agsize=268435455 blks May 2 09:45:03 Sakaar root: = sectsz=512 attr=2, projid32bit=1 May 2 09:45:03 Sakaar root: = crc=1 finobt=1, sparse=1, rmapbt=0 May 2 09:45:03 Sakaar root: = reflink=1 bigtime=0 inobtcount=0 nrext64=0 May 2 09:45:03 Sakaar root: data = bsize=4096 blocks=1465130633, imaxpct=5 May 2 09:45:03 Sakaar root: = sunit=0 swidth=0 blks May 2 09:45:03 Sakaar root: naming =version 2 bsize=4096 ascii-ci=0, ftype=1 May 2 09:45:03 Sakaar root: log =internal log bsize=4096 blocks=521728, version=2 May 2 09:45:03 Sakaar root: = sectsz=512 sunit=0 blks, lazy-count=1 May 2 09:45:03 Sakaar root: realtime =none extsz=4096 blocks=0, rtextents=0 May 2 09:45:03 Sakaar emhttpd: mounting /mnt/disk3 May 2 09:45:03 Sakaar emhttpd: shcmd (47): mkdir -p /mnt/disk3 May 2 09:45:03 Sakaar emhttpd: shcmd (48): mount -t xfs -o noatime,nouuid /dev/md3p1 /mnt/disk3 May 2 09:45:03 Sakaar kernel: XFS (md3p1): Mounting V5 Filesystem May 2 09:45:04 Sakaar emhttpd: shcmd (49): xfs_growfs /mnt/disk3 May 2 09:45:04 Sakaar kernel: XFS (md3p1): Ending clean mount May 2 09:45:04 Sakaar kernel: xfs filesystem being mounted at /mnt/disk3 supports timestamps until 2038 (0x7fffffff) May 2 09:45:04 Sakaar root: meta-data=/dev/md3p1 isize=512 agcount=10, agsize=268435455 blks May 2 09:45:04 Sakaar root: = sectsz=512 attr=2, projid32bit=1 May 2 09:45:04 Sakaar root: = crc=1 finobt=1, sparse=1, rmapbt=0 May 2 09:45:04 Sakaar root: = reflink=1 bigtime=0 inobtcount=0 nrext64=0 May 2 09:45:04 Sakaar root: data = bsize=4096 blocks=2441609203, imaxpct=5 May 2 09:45:04 Sakaar root: = sunit=0 swidth=0 blks May 2 09:45:04 Sakaar root: naming =version 2 bsize=4096 ascii-ci=0, ftype=1 May 2 09:45:04 Sakaar root: log =internal log bsize=4096 blocks=521728, version=2 May 2 09:45:04 Sakaar root: = sectsz=512 sunit=0 blks, lazy-count=1 May 2 09:45:04 Sakaar root: realtime =none extsz=4096 blocks=0, rtextents=0 May 2 09:45:04 Sakaar emhttpd: mounting /mnt/disk4 May 2 09:45:04 Sakaar emhttpd: shcmd (50): mkdir -p /mnt/disk4 May 2 09:45:04 Sakaar emhttpd: shcmd (51): mount -t xfs -o noatime,nouuid /dev/md4p1 /mnt/disk4 May 2 09:45:04 Sakaar kernel: XFS (md4p1): Mounting V5 Filesystem May 2 09:45:04 Sakaar kernel: XFS (md4p1): Ending clean mount May 2 09:45:04 Sakaar emhttpd: shcmd (52): xfs_growfs /mnt/disk4 May 2 09:45:04 Sakaar kernel: xfs filesystem being mounted at /mnt/disk4 supports timestamps until 2038 (0x7fffffff) May 2 09:45:04 Sakaar root: meta-data=/dev/md4p1 isize=512 agcount=6, agsize=268435455 blks May 2 09:45:04 Sakaar root: = sectsz=512 attr=2, projid32bit=1 May 2 09:45:04 Sakaar root: = crc=1 finobt=1, sparse=1, rmapbt=0 May 2 09:45:04 Sakaar root: = reflink=1 bigtime=0 inobtcount=0 nrext64=0 May 2 09:45:04 Sakaar root: data = bsize=4096 blocks=1465130633, imaxpct=5 May 2 09:45:04 Sakaar root: = sunit=0 swidth=0 blks May 2 09:45:04 Sakaar root: naming =version 2 bsize=4096 ascii-ci=0, ftype=1 May 2 09:45:04 Sakaar root: log =internal log bsize=4096 blocks=521728, version=2 May 2 09:45:04 Sakaar root: = sectsz=512 sunit=0 blks, lazy-count=1 May 2 09:45:04 Sakaar root: realtime =none extsz=4096 blocks=0, rtextents=0 May 2 09:45:04 Sakaar emhttpd: mounting /mnt/disk5 May 2 09:45:04 Sakaar emhttpd: shcmd (53): mkdir -p /mnt/disk5 May 2 09:45:04 Sakaar emhttpd: shcmd (54): mount -t xfs -o noatime,nouuid /dev/md5p1 /mnt/disk5 May 2 09:45:04 Sakaar kernel: XFS (md5p1): Mounting V5 Filesystem May 2 09:45:05 Sakaar emhttpd: shcmd (55): xfs_growfs /mnt/disk5 May 2 09:45:05 Sakaar kernel: XFS (md5p1): Ending clean mount May 2 09:45:05 Sakaar kernel: xfs filesystem being mounted at /mnt/disk5 supports timestamps until 2038 (0x7fffffff) May 2 09:45:05 Sakaar root: meta-data=/dev/md5p1 isize=512 agcount=6, agsize=268435455 blks May 2 09:45:05 Sakaar root: = sectsz=512 attr=2, projid32bit=1 May 2 09:45:05 Sakaar root: = crc=1 finobt=1, sparse=1, rmapbt=0 May 2 09:45:05 Sakaar root: = reflink=1 bigtime=0 inobtcount=0 nrext64=0 May 2 09:45:05 Sakaar root: data = bsize=4096 blocks=1465130633, imaxpct=5 May 2 09:45:05 Sakaar root: = sunit=0 swidth=0 blks May 2 09:45:05 Sakaar root: naming =version 2 bsize=4096 ascii-ci=0, ftype=1 May 2 09:45:05 Sakaar root: log =internal log bsize=4096 blocks=521728, version=2 May 2 09:45:05 Sakaar root: = sectsz=512 sunit=0 blks, lazy-count=1 May 2 09:45:05 Sakaar root: realtime =none extsz=4096 blocks=0, rtextents=0 May 2 09:45:05 Sakaar emhttpd: mounting /mnt/disk6 May 2 09:45:05 Sakaar emhttpd: shcmd (56): mkdir -p /mnt/disk6 May 2 09:45:05 Sakaar emhttpd: shcmd (57): mount -t xfs -o noatime,nouuid /dev/md6p1 /mnt/disk6 May 2 09:45:05 Sakaar kernel: XFS (md6p1): Mounting V5 Filesystem May 2 09:45:05 Sakaar kernel: XFS (md6p1): Ending clean mount May 2 09:45:05 Sakaar kernel: xfs filesystem being mounted at /mnt/disk6 supports timestamps until 2038 (0x7fffffff) May 2 09:45:05 Sakaar emhttpd: shcmd (58): xfs_growfs /mnt/disk6 May 2 09:45:05 Sakaar root: meta-data=/dev/md6p1 isize=512 agcount=10, agsize=268435455 blks May 2 09:45:05 Sakaar root: = sectsz=512 attr=2, projid32bit=1 May 2 09:45:05 Sakaar root: = crc=1 finobt=1, sparse=1, rmapbt=0 May 2 09:45:05 Sakaar root: = reflink=1 bigtime=0 inobtcount=0 nrext64=0 May 2 09:45:05 Sakaar root: data = bsize=4096 blocks=2441609203, imaxpct=5 May 2 09:45:05 Sakaar root: = sunit=0 swidth=0 blks May 2 09:45:05 Sakaar root: naming =version 2 bsize=4096 ascii-ci=0, ftype=1 May 2 09:45:05 Sakaar root: log =internal log bsize=4096 blocks=521728, version=2 May 2 09:45:05 Sakaar root: = sectsz=512 sunit=0 blks, lazy-count=1 May 2 09:45:05 Sakaar root: realtime =none extsz=4096 blocks=0, rtextents=0 May 2 09:45:05 Sakaar emhttpd: mounting /mnt/disk7 May 2 09:45:05 Sakaar emhttpd: shcmd (59): mkdir -p /mnt/disk7 May 2 09:45:05 Sakaar emhttpd: shcmd (60): mount -t xfs -o noatime,nouuid /dev/md7p1 /mnt/disk7 May 2 09:45:05 Sakaar kernel: XFS (md7p1): Mounting V5 Filesystem May 2 09:45:06 Sakaar kernel: XFS (md7p1): Ending clean mount May 2 09:45:06 Sakaar emhttpd: shcmd (61): xfs_growfs /mnt/disk7 May 2 09:45:06 Sakaar root: meta-data=/dev/md7p1 isize=512 agcount=11, agsize=268435455 blks May 2 09:45:06 Sakaar root: = sectsz=512 attr=2, projid32bit=1 May 2 09:45:06 Sakaar root: = crc=1 finobt=1, sparse=1, rmapbt=0 May 2 09:45:06 Sakaar root: = reflink=1 bigtime=1 inobtcount=1 nrext64=0 May 2 09:45:06 Sakaar root: data = bsize=4096 blocks=2929721331, imaxpct=5 May 2 09:45:06 Sakaar root: = sunit=0 swidth=0 blks May 2 09:45:06 Sakaar root: naming =version 2 bsize=4096 ascii-ci=0, ftype=1 May 2 09:45:06 Sakaar root: log =internal log bsize=4096 blocks=521728, version=2 May 2 09:45:06 Sakaar root: = sectsz=512 sunit=0 blks, lazy-count=1 May 2 09:45:06 Sakaar root: realtime =none extsz=4096 blocks=0, rtextents=0 May 2 09:45:06 Sakaar emhttpd: mounting /mnt/cache May 2 09:45:06 Sakaar emhttpd: shcmd (62): mkdir -p /mnt/cache May 2 09:45:06 Sakaar emhttpd: shcmd (63): mount -t xfs -o noatime,nouuid /dev/nvme0n1p1 /mnt/cache May 2 09:45:06 Sakaar kernel: XFS (nvme0n1p1): Mounting V5 Filesystem May 2 09:45:06 Sakaar emhttpd: shcmd (64): mount -o remount,discard /mnt/cache May 2 09:45:06 Sakaar kernel: XFS (nvme0n1p1): Ending clean mount May 2 09:45:06 Sakaar emhttpd: shcmd (65): /usr/sbin/zfs mount -a May 2 09:45:06 Sakaar root: The ZFS modules are not loaded. May 2 09:45:06 Sakaar root: Try running '/sbin/modprobe zfs' as root to load them. May 2 09:45:06 Sakaar emhttpd: shcmd (65): exit status: 1 May 2 09:45:06 Sakaar emhttpd: shcmd (66): sync May 2 09:45:06 Sakaar emhttpd: shcmd (67): mkdir /mnt/user0 May 2 09:45:06 Sakaar emhttpd: shcmd (68): /usr/local/sbin/shfs /mnt/user0 -disks 254 -o default_permissions,allow_other,noatime |& logger May 2 09:45:06 Sakaar emhttpd: shcmd (69): mkdir /mnt/user May 2 09:45:06 Sakaar shfs: FUSE library version 3.12.0 May 2 09:45:06 Sakaar emhttpd: shcmd (70): /usr/local/sbin/shfs /mnt/user -disks 255 -o default_permissions,allow_other,noatime -o remember=0 |& logger May 2 09:45:06 Sakaar shfs: FUSE library version 3.12.0 May 2 09:45:06 Sakaar emhttpd: shcmd (72): /usr/local/sbin/update_cron May 2 09:45:06 Sakaar emhttpd: shcmd (95): /sbin/mount --bind '/mnt/cache/appdata' '/mnt/user/appdata' May 2 09:45:06 Sakaar root: Delaying execution of fix common problems scan for 10 minutes May 2 09:45:06 Sakaar unassigned.devices: Mounting 'Auto Mount' Devices... May 2 09:45:06 Sakaar emhttpd: Starting services... May 2 09:45:06 Sakaar emhttpd: shcmd (119): /etc/rc.d/rc.samba restart May 2 09:45:06 Sakaar wsdd2[5139]: 'Terminated' signal received. May 2 09:45:06 Sakaar nmbd[5129]: [2023/05/02 09:45:06.959820, 0] ../../source3/nmbd/nmbd.c:59(terminate) May 2 09:45:06 Sakaar nmbd[5129]: Got SIGTERM: going down... May 2 09:45:06 Sakaar winbindd[5144]: [2023/05/02 09:45:06.959838, 0] ../../source3/winbindd/winbindd_dual.c:1957(winbindd_sig_term_handler) May 2 09:45:06 Sakaar winbindd[5144]: Got sig[15] terminate (is_parent=0) May 2 09:45:06 Sakaar winbindd[5142]: [2023/05/02 09:45:06.959839, 0] ../../source3/winbindd/winbindd_dual.c:1957(winbindd_sig_term_handler) May 2 09:45:06 Sakaar winbindd[5142]: Got sig[15] terminate (is_parent=1) May 2 09:45:06 Sakaar winbindd[5264]: [2023/05/02 09:45:06.959883, 0] ../../source3/winbindd/winbindd_dual.c:1957(winbindd_sig_term_handler) May 2 09:45:06 Sakaar winbindd[5264]: Got sig[15] terminate (is_parent=0) May 2 09:45:06 Sakaar wsdd2[5139]: terminating. May 2 09:45:09 Sakaar root: Starting Samba: /usr/sbin/smbd -D May 2 09:45:09 Sakaar smbd[6270]: [2023/05/02 09:45:09.102138, 0] ../../source3/smbd/server.c:1741(main) May 2 09:45:09 Sakaar smbd[6270]: smbd version 4.17.7 started. May 2 09:45:09 Sakaar smbd[6270]: Copyright Andrew Tridgell and the Samba Team 1992-2022 May 2 09:45:09 Sakaar root: /usr/sbin/nmbd -D May 2 09:45:09 Sakaar nmbd[6272]: [2023/05/02 09:45:09.113539, 0] ../../source3/nmbd/nmbd.c:901(main) May 2 09:45:09 Sakaar nmbd[6272]: nmbd version 4.17.7 started. May 2 09:45:09 Sakaar nmbd[6272]: Copyright Andrew Tridgell and the Samba Team 1992-2022 May 2 09:45:09 Sakaar root: /usr/sbin/wsdd2 -d May 2 09:45:09 Sakaar wsdd2[6286]: starting. May 2 09:45:09 Sakaar root: /usr/sbin/winbindd -D May 2 09:45:09 Sakaar winbindd[6287]: [2023/05/02 09:45:09.162699, 0] ../../source3/winbindd/winbindd.c:1440(main) May 2 09:45:09 Sakaar winbindd[6287]: winbindd version 4.17.7 started. May 2 09:45:09 Sakaar winbindd[6287]: Copyright Andrew Tridgell and the Samba Team 1992-2022 May 2 09:45:09 Sakaar winbindd[6289]: [2023/05/02 09:45:09.164807, 0] ../../source3/winbindd/winbindd_cache.c:3116(initialize_winbindd_cache) May 2 09:45:09 Sakaar winbindd[6289]: initialize_winbindd_cache: clearing cache and re-creating with version number 2 May 2 09:45:09 Sakaar emhttpd: shcmd (123): /etc/rc.d/rc.avahidaemon restart May 2 09:45:09 Sakaar root: Stopping Avahi mDNS/DNS-SD Daemon: stopped May 2 09:45:09 Sakaar avahi-daemon[5169]: Got SIGTERM, quitting. May 2 09:45:09 Sakaar avahi-dnsconfd[5178]: read(): EOF May 2 09:45:09 Sakaar avahi-daemon[5169]: Leaving mDNS multicast group on interface br0.IPv6 with address fe80::1ac0:4dff:feeb:9260. May 2 09:45:09 Sakaar avahi-daemon[5169]: Leaving mDNS multicast group on interface br0.IPv4 with address 192.168.1.106. May 2 09:45:09 Sakaar avahi-daemon[5169]: avahi-daemon 0.8 exiting. May 2 09:45:09 Sakaar root: Starting Avahi mDNS/DNS-SD Daemon: /usr/sbin/avahi-daemon -D May 2 09:45:09 Sakaar avahi-daemon[6316]: Found user 'avahi' (UID 61) and group 'avahi' (GID 214). May 2 09:45:09 Sakaar avahi-daemon[6316]: Successfully dropped root privileges. May 2 09:45:09 Sakaar avahi-daemon[6316]: avahi-daemon 0.8 starting up. May 2 09:45:09 Sakaar avahi-daemon[6316]: Successfully called chroot(). May 2 09:45:09 Sakaar avahi-daemon[6316]: Successfully dropped remaining capabilities. May 2 09:45:09 Sakaar avahi-daemon[6316]: Loading service file /services/sftp-ssh.service. May 2 09:45:09 Sakaar avahi-daemon[6316]: Loading service file /services/smb.service. May 2 09:45:09 Sakaar avahi-daemon[6316]: Loading service file /services/ssh.service. May 2 09:45:09 Sakaar avahi-daemon[6316]: Joining mDNS multicast group on interface br0.IPv6 with address fe80::1ac0:4dff:feeb:9260. May 2 09:45:09 Sakaar avahi-daemon[6316]: New relevant interface br0.IPv6 for mDNS. May 2 09:45:09 Sakaar avahi-daemon[6316]: Joining mDNS multicast group on interface br0.IPv4 with address 192.168.1.106. May 2 09:45:09 Sakaar avahi-daemon[6316]: New relevant interface br0.IPv4 for mDNS. May 2 09:45:09 Sakaar avahi-daemon[6316]: Network interface enumeration completed. May 2 09:45:09 Sakaar avahi-daemon[6316]: Registering new address record for fe80::1ac0:4dff:feeb:9260 on br0.*. May 2 09:45:09 Sakaar avahi-daemon[6316]: Registering new address record for 192.168.1.106 on br0.IPv4. May 2 09:45:09 Sakaar emhttpd: shcmd (124): /etc/rc.d/rc.avahidnsconfd restart May 2 09:45:09 Sakaar root: Stopping Avahi mDNS/DNS-SD DNS Server Configuration Daemon: stopped May 2 09:45:09 Sakaar root: Starting Avahi mDNS/DNS-SD DNS Server Configuration Daemon: /usr/sbin/avahi-dnsconfd -D May 2 09:45:09 Sakaar avahi-dnsconfd[6325]: Successfully connected to Avahi daemon. May 2 09:45:09 Sakaar emhttpd: shcmd (155): /usr/local/sbin/mount_image '/mnt/user/system/docker/docker.img' /var/lib/docker 20 May 2 09:45:09 Sakaar kernel: loop2: detected capacity change from 0 to 41943040 May 2 09:45:09 Sakaar kernel: BTRFS: device fsid eabe2f22-2595-4a7c-b8a5-9e302b462d19 devid 1 transid 256106 /dev/loop2 scanned by mount (6381) May 2 09:45:09 Sakaar kernel: BTRFS info (device loop2): using crc32c (crc32c-intel) checksum algorithm May 2 09:45:09 Sakaar kernel: BTRFS info (device loop2): using free space tree May 2 09:45:09 Sakaar kernel: BTRFS info (device loop2): enabling ssd optimizations May 2 09:45:09 Sakaar root: Resize device id 1 (/dev/loop2) from 20.00GiB to max May 2 09:45:09 Sakaar emhttpd: shcmd (157): /etc/rc.d/rc.docker start May 2 09:45:09 Sakaar root: starting dockerd ... May 2 09:45:10 Sakaar avahi-daemon[6316]: Server startup complete. Host name is Sakaar.local. Local service cookie is 4267240525. May 2 09:45:10 Sakaar kernel: Bridge firewalling registered May 2 09:45:10 Sakaar kernel: Initializing XFRM netlink socket May 2 09:45:10 Sakaar kernel: br-478eb7d28da2: port 1(veth3bc313b) entered blocking state May 2 09:45:10 Sakaar kernel: br-478eb7d28da2: port 1(veth3bc313b) entered disabled state May 2 09:45:10 Sakaar kernel: device veth3bc313b entered promiscuous mode May 2 09:45:10 Sakaar kernel: br-478eb7d28da2: port 1(veth3bc313b) entered blocking state May 2 09:45:10 Sakaar kernel: br-478eb7d28da2: port 1(veth3bc313b) entered forwarding state May 2 09:45:10 Sakaar kernel: IPv6: ADDRCONF(NETDEV_CHANGE): br-478eb7d28da2: link becomes ready May 2 09:45:10 Sakaar kernel: br-478eb7d28da2: port 1(veth3bc313b) entered disabled state May 2 09:45:10 Sakaar kernel: br-478eb7d28da2: port 2(veth03f2dc1) entered blocking state May 2 09:45:10 Sakaar kernel: br-478eb7d28da2: port 2(veth03f2dc1) entered disabled state May 2 09:45:10 Sakaar kernel: device veth03f2dc1 entered promiscuous mode May 2 09:45:10 Sakaar kernel: br-478eb7d28da2: port 2(veth03f2dc1) entered blocking state May 2 09:45:10 Sakaar kernel: br-478eb7d28da2: port 2(veth03f2dc1) entered forwarding state May 2 09:45:10 Sakaar kernel: br-478eb7d28da2: port 3(vethc3cd47a) entered blocking state May 2 09:45:10 Sakaar kernel: br-478eb7d28da2: port 3(vethc3cd47a) entered disabled state May 2 09:45:10 Sakaar kernel: device vethc3cd47a entered promiscuous mode May 2 09:45:10 Sakaar kernel: br-478eb7d28da2: port 3(vethc3cd47a) entered blocking state May 2 09:45:10 Sakaar kernel: br-478eb7d28da2: port 3(vethc3cd47a) entered forwarding state May 2 09:45:11 Sakaar kernel: br-478eb7d28da2: port 4(veth1cec12d) entered blocking state May 2 09:45:11 Sakaar kernel: br-478eb7d28da2: port 4(veth1cec12d) entered disabled state May 2 09:45:11 Sakaar kernel: device veth1cec12d entered promiscuous mode May 2 09:45:11 Sakaar kernel: br-478eb7d28da2: port 4(veth1cec12d) entered blocking state May 2 09:45:11 Sakaar kernel: br-478eb7d28da2: port 4(veth1cec12d) entered forwarding state May 2 09:45:11 Sakaar avahi-daemon[6316]: Service "Sakaar" (/services/ssh.service) successfully established. May 2 09:45:11 Sakaar avahi-daemon[6316]: Service "Sakaar" (/services/smb.service) successfully established. May 2 09:45:11 Sakaar avahi-daemon[6316]: Service "Sakaar" (/services/sftp-ssh.service) successfully established. May 2 09:45:11 Sakaar kernel: eth0: renamed from veth49b1e60 May 2 09:45:11 Sakaar kernel: IPv6: ADDRCONF(NETDEV_CHANGE): veth03f2dc1: link becomes ready May 2 09:45:11 Sakaar kernel: br-478eb7d28da2: port 3(vethc3cd47a) entered disabled state May 2 09:45:11 Sakaar kernel: br-478eb7d28da2: port 4(veth1cec12d) entered disabled state May 2 09:45:11 Sakaar kernel: eth0: renamed from vethe54ace0 May 2 09:45:11 Sakaar kernel: eth0: renamed from veth80a547b May 2 09:45:11 Sakaar kernel: IPv6: ADDRCONF(NETDEV_CHANGE): veth3bc313b: link becomes ready May 2 09:45:11 Sakaar kernel: br-478eb7d28da2: port 1(veth3bc313b) entered blocking state May 2 09:45:11 Sakaar kernel: br-478eb7d28da2: port 1(veth3bc313b) entered forwarding state May 2 09:45:11 Sakaar kernel: IPv6: ADDRCONF(NETDEV_CHANGE): veth1cec12d: link becomes ready May 2 09:45:11 Sakaar kernel: br-478eb7d28da2: port 4(veth1cec12d) entered blocking state May 2 09:45:11 Sakaar kernel: br-478eb7d28da2: port 4(veth1cec12d) entered forwarding state May 2 09:45:11 Sakaar kernel: eth0: renamed from veth1754799 May 2 09:45:11 Sakaar kernel: IPv6: ADDRCONF(NETDEV_CHANGE): vethc3cd47a: link becomes ready May 2 09:45:11 Sakaar kernel: br-478eb7d28da2: port 3(vethc3cd47a) entered blocking state May 2 09:45:11 Sakaar kernel: br-478eb7d28da2: port 3(vethc3cd47a) entered forwarding state May 2 09:45:12 Sakaar rc.docker: created network br0 with subnets: 192.168.1.0/24; May 2 09:45:12 Sakaar emhttpd: shcmd (193): /usr/local/sbin/mount_image '/mnt/user/system/libvirt/libvirt.img' /etc/libvirt 1 May 2 09:45:12 Sakaar kernel: br-478eb7d28da2: port 5(veth2f1a589) entered blocking state May 2 09:45:12 Sakaar kernel: br-478eb7d28da2: port 5(veth2f1a589) entered disabled state May 2 09:45:12 Sakaar kernel: device veth2f1a589 entered promiscuous mode May 2 09:45:12 Sakaar kernel: br-478eb7d28da2: port 5(veth2f1a589) entered blocking state May 2 09:45:12 Sakaar kernel: br-478eb7d28da2: port 5(veth2f1a589) entered forwarding state May 2 09:45:12 Sakaar kernel: loop3: detected capacity change from 0 to 2097152 May 2 09:45:12 Sakaar kernel: BTRFS: device fsid 8691c6ac-5af3-4797-8559-80829013cb8d devid 1 transid 255 /dev/loop3 scanned by mount (8069) May 2 09:45:12 Sakaar kernel: BTRFS info (device loop3): using crc32c (crc32c-intel) checksum algorithm May 2 09:45:12 Sakaar kernel: BTRFS info (device loop3): using free space tree May 2 09:45:12 Sakaar kernel: BTRFS info (device loop3): enabling ssd optimizations May 2 09:45:12 Sakaar root: Resize device id 1 (/dev/loop3) from 1.00GiB to max May 2 09:45:12 Sakaar emhttpd: shcmd (195): /etc/rc.d/rc.libvirt start May 2 09:45:12 Sakaar root: Starting virtlockd... May 2 09:45:12 Sakaar root: Starting virtlogd... May 2 09:45:12 Sakaar root: Starting libvirtd... May 2 09:45:12 Sakaar kernel: tun: Universal TUN/TAP device driver, 1.6 May 2 09:45:12 Sakaar emhttpd: nothing to sync May 2 09:45:12 Sakaar unassigned.devices: Mounting 'Auto Mount' Remote Shares... May 2 09:45:12 Sakaar kernel: eth0: renamed from vetha8e0668 May 2 09:45:12 Sakaar kernel: IPv6: ADDRCONF(NETDEV_CHANGE): veth2f1a589: link becomes ready May 2 09:45:12 Sakaar rc.docker: changedetection.io: started succesfully! May 2 09:45:12 Sakaar dnsmasq[8394]: started, version 2.89 cachesize 150 May 2 09:45:12 Sakaar dnsmasq[8394]: compile time options: IPv6 GNU-getopt DBus no-UBus i18n IDN2 DHCP DHCPv6 no-Lua TFTP conntrack ipset no-nftset auth cryptohash DNSSEC loop-detect inotify dumpfile May 2 09:45:12 Sakaar dnsmasq-dhcp[8394]: DHCP, IP range 192.168.122.2 -- 192.168.122.254, lease time 1h May 2 09:45:12 Sakaar dnsmasq-dhcp[8394]: DHCP, sockets bound exclusively to interface virbr0 May 2 09:45:12 Sakaar dnsmasq[8394]: reading /etc/resolv.conf May 2 09:45:12 Sakaar dnsmasq[8394]: using nameserver 1.1.1.1#53 May 2 09:45:12 Sakaar dnsmasq[8394]: using nameserver 8.8.8.8#53 May 2 09:45:12 Sakaar dnsmasq[8394]: read /etc/hosts - 3 names May 2 09:45:12 Sakaar dnsmasq[8394]: read /var/lib/libvirt/dnsmasq/default.addnhosts - 0 names May 2 09:45:12 Sakaar dnsmasq-dhcp[8394]: read /var/lib/libvirt/dnsmasq/default.hostsfile May 2 09:45:12 Sakaar kernel: mpt3sas 0000:03:00.0: invalid VPD tag 0x00 (size 0) at offset 0; assume missing optional EEPROM May 2 09:45:12 Sakaar kernel: br-478eb7d28da2: port 6(veth78a80e8) entered blocking state May 2 09:45:12 Sakaar kernel: br-478eb7d28da2: port 6(veth78a80e8) entered disabled state May 2 09:45:12 Sakaar kernel: device veth78a80e8 entered promiscuous mode May 2 09:45:12 Sakaar kernel: br-478eb7d28da2: port 6(veth78a80e8) entered blocking state May 2 09:45:12 Sakaar kernel: br-478eb7d28da2: port 6(veth78a80e8) entered forwarding state May 2 09:45:12 Sakaar kernel: eth0: renamed from veth50b8437 May 2 09:45:12 Sakaar kernel: br-478eb7d28da2: port 6(veth78a80e8) entered disabled state May 2 09:45:12 Sakaar kernel: IPv6: ADDRCONF(NETDEV_CHANGE): veth78a80e8: link becomes ready May 2 09:45:12 Sakaar kernel: br-478eb7d28da2: port 6(veth78a80e8) entered blocking state May 2 09:45:12 Sakaar kernel: br-478eb7d28da2: port 6(veth78a80e8) entered forwarding state May 2 09:45:12 Sakaar rc.docker: plex: started succesfully! May 2 09:45:12 Sakaar kernel: br-478eb7d28da2: port 7(vethe2c45d6) entered blocking state May 2 09:45:12 Sakaar kernel: br-478eb7d28da2: port 7(vethe2c45d6) entered disabled state May 2 09:45:12 Sakaar kernel: device vethe2c45d6 entered promiscuous mode May 2 09:45:12 Sakaar kernel: br-478eb7d28da2: port 7(vethe2c45d6) entered blocking state May 2 09:45:12 Sakaar kernel: br-478eb7d28da2: port 7(vethe2c45d6) entered forwarding state May 2 09:45:13 Sakaar kernel: eth0: renamed from vethef11a2d May 2 09:45:13 Sakaar kernel: IPv6: ADDRCONF(NETDEV_CHANGE): vethe2c45d6: link becomes ready May 2 09:45:13 Sakaar rc.docker: prowlarr: started succesfully! May 2 09:45:13 Sakaar kernel: br-478eb7d28da2: port 8(vethb659a28) entered blocking state May 2 09:45:13 Sakaar kernel: br-478eb7d28da2: port 8(vethb659a28) entered disabled state May 2 09:45:13 Sakaar kernel: device vethb659a28 entered promiscuous mode May 2 09:45:13 Sakaar kernel: br-478eb7d28da2: port 8(vethb659a28) entered blocking state May 2 09:45:13 Sakaar kernel: br-478eb7d28da2: port 8(vethb659a28) entered forwarding state May 2 09:45:13 Sakaar kernel: br0: port 2(vnet0) entered blocking state May 2 09:45:13 Sakaar kernel: br0: port 2(vnet0) entered disabled state May 2 09:45:13 Sakaar kernel: device vnet0 entered promiscuous mode May 2 09:45:13 Sakaar kernel: br0: port 2(vnet0) entered blocking state May 2 09:45:13 Sakaar kernel: br0: port 2(vnet0) entered forwarding state May 2 09:45:13 Sakaar kernel: eth0: renamed from vethb5a130d May 2 09:45:13 Sakaar kernel: IPv6: ADDRCONF(NETDEV_CHANGE): vethb659a28: link becomes ready May 2 09:45:13 Sakaar kernel: device-mapper: ioctl: 4.47.0-ioctl (2022-07-28) initialised: [email protected] May 2 09:45:13 Sakaar kernel: ata5.00: Enabling discard_zeroes_data May 2 09:45:13 Sakaar kernel: sdf: sdf1 May 2 09:45:13 Sakaar rc.docker: readarr: started succesfully! May 2 09:45:13 Sakaar kernel: br-478eb7d28da2: port 9(veth0cf5aee) entered blocking state May 2 09:45:13 Sakaar kernel: br-478eb7d28da2: port 9(veth0cf5aee) entered disabled state May 2 09:45:13 Sakaar kernel: device veth0cf5aee entered promiscuous mode May 2 09:45:13 Sakaar kernel: br-478eb7d28da2: port 9(veth0cf5aee) entered blocking state May 2 09:45:13 Sakaar kernel: br-478eb7d28da2: port 9(veth0cf5aee) entered forwarding state May 2 09:45:13 Sakaar kernel: eth0: renamed from veth3451b8b May 2 09:45:13 Sakaar kernel: IPv6: ADDRCONF(NETDEV_CHANGE): veth0cf5aee: link becomes ready May 2 09:45:13 Sakaar rc.docker: radarr-4k: started succesfully! May 2 09:45:13 Sakaar kernel: br-478eb7d28da2: port 10(veth5a35761) entered blocking state May 2 09:45:13 Sakaar kernel: br-478eb7d28da2: port 10(veth5a35761) entered disabled state May 2 09:45:13 Sakaar kernel: device veth5a35761 entered promiscuous mode May 2 09:45:13 Sakaar kernel: br-478eb7d28da2: port 10(veth5a35761) entered blocking state May 2 09:45:13 Sakaar kernel: br-478eb7d28da2: port 10(veth5a35761) entered forwarding state May 2 09:45:13 Sakaar kernel: br-478eb7d28da2: port 10(veth5a35761) entered disabled state May 2 09:45:14 Sakaar kernel: eth0: renamed from veth1d941d6 May 2 09:45:14 Sakaar kernel: IPv6: ADDRCONF(NETDEV_CHANGE): veth5a35761: link becomes ready May 2 09:45:14 Sakaar kernel: br-478eb7d28da2: port 10(veth5a35761) entered blocking state May 2 09:45:14 Sakaar kernel: br-478eb7d28da2: port 10(veth5a35761) entered forwarding state May 2 09:45:14 Sakaar rc.docker: sonarr: started succesfully! May 2 09:45:14 Sakaar kernel: br-478eb7d28da2: port 11(vethed7b55f) entered blocking state May 2 09:45:14 Sakaar kernel: br-478eb7d28da2: port 11(vethed7b55f) entered disabled state May 2 09:45:14 Sakaar kernel: device vethed7b55f entered promiscuous mode May 2 09:45:14 Sakaar kernel: br-478eb7d28da2: port 11(vethed7b55f) entered blocking state May 2 09:45:14 Sakaar kernel: br-478eb7d28da2: port 11(vethed7b55f) entered forwarding state May 2 09:45:14 Sakaar kernel: eth0: renamed from veth858ce6c May 2 09:45:14 Sakaar kernel: IPv6: ADDRCONF(NETDEV_CHANGE): vethed7b55f: link becomes ready May 2 09:45:14 Sakaar rc.docker: NginxProxyManager: started succesfully! May 2 09:45:14 Sakaar kernel: br-478eb7d28da2: port 12(veth7315072) entered blocking state May 2 09:45:14 Sakaar kernel: br-478eb7d28da2: port 12(veth7315072) entered disabled state May 2 09:45:14 Sakaar kernel: device veth7315072 entered promiscuous mode May 2 09:45:14 Sakaar kernel: br-478eb7d28da2: port 12(veth7315072) entered blocking state May 2 09:45:14 Sakaar kernel: br-478eb7d28da2: port 12(veth7315072) entered forwarding state May 2 09:45:14 Sakaar kernel: eth0: renamed from vethbeed512 May 2 09:45:14 Sakaar kernel: IPv6: ADDRCONF(NETDEV_CHANGE): veth7315072: link becomes ready May 2 09:45:14 Sakaar rc.docker: nzbget: started succesfully! May 2 09:45:14 Sakaar kernel: br-478eb7d28da2: port 13(vetha5d6320) entered blocking state May 2 09:45:14 Sakaar kernel: br-478eb7d28da2: port 13(vetha5d6320) entered disabled state May 2 09:45:14 Sakaar kernel: device vetha5d6320 entered promiscuous mode May 2 09:45:14 Sakaar kernel: process 'subvolumes/901c17ab5cab76cf8654e0ff977305e8d3521970d028496b13f1853e9912e74b/app/nzbget' started with executable stack May 2 09:45:15 Sakaar kernel: eth0: renamed from veth11dffbb May 2 09:45:15 Sakaar kernel: IPv6: ADDRCONF(NETDEV_CHANGE): vetha5d6320: link becomes ready May 2 09:45:15 Sakaar kernel: br-478eb7d28da2: port 13(vetha5d6320) entered blocking state May 2 09:45:15 Sakaar kernel: br-478eb7d28da2: port 13(vetha5d6320) entered forwarding state May 2 09:45:15 Sakaar rc.docker: deluge: started succesfully! May 2 09:45:15 Sakaar kernel: br-478eb7d28da2: port 14(veth8f57272) entered blocking state May 2 09:45:15 Sakaar kernel: br-478eb7d28da2: port 14(veth8f57272) entered disabled state May 2 09:45:15 Sakaar kernel: device veth8f57272 entered promiscuous mode May 2 09:45:15 Sakaar kernel: br-478eb7d28da2: port 14(veth8f57272) entered blocking state May 2 09:45:15 Sakaar kernel: br-478eb7d28da2: port 14(veth8f57272) entered forwarding state May 2 09:45:15 Sakaar kernel: eth0: renamed from vethb0b83a5 May 2 09:45:15 Sakaar kernel: IPv6: ADDRCONF(NETDEV_CHANGE): veth8f57272: link becomes ready May 2 09:45:15 Sakaar rc.docker: bazarr: started succesfully! May 2 09:45:16 Sakaar kernel: vfio-pci 0000:01:00.0: enabling device (0000 -> 0003) May 2 09:45:16 Sakaar kernel: vfio-pci 0000:01:00.0: vfio_ecap_init: hiding ecap 0x1e@0x258 May 2 09:45:16 Sakaar kernel: vfio-pci 0000:01:00.0: vfio_ecap_init: hiding ecap 0x19@0x900 May 2 09:45:17 Sakaar unassigned.devices: Using Gateway '192.168.1.1' to Ping Remote Shares. May 2 09:46:02 Sakaar flash_backup: adding task: /usr/local/emhttp/plugins/dynamix.my.servers/scripts/UpdateFlashBackup update May 2 09:46:08 Sakaar webGUI: Successful login user root from 192.168.1.185 May 2 09:46:33 Sakaar root: plugin: creating: /boot/config/plugins/unassigned.devices/unassigned.devices-2023.05.01.tgz - downloading from URL https://raw.githubusercontent.com/dlandon/unassigned.devices/master/unassigned.devices-2023.05.01.tgz May 2 09:46:33 Sakaar root: plugin: checking: /boot/config/plugins/unassigned.devices/unassigned.devices-2023.05.01.tgz - MD5 May 2 09:46:33 Sakaar root: plugin: running: anonymous May 2 09:46:33 Sakaar root: plugin: creating: /tmp/start_unassigned_devices - from INLINE content May 2 09:46:33 Sakaar root: plugin: setting: /tmp/start_unassigned_devices - mode to 0770 May 2 09:46:33 Sakaar root: plugin: skipping: /boot/config/plugins/unassigned.devices/unassigned.devices.cfg already exists May 2 09:46:33 Sakaar root: plugin: skipping: /boot/config/plugins/unassigned.devices/samba_mount.cfg already exists May 2 09:46:33 Sakaar root: plugin: skipping: /boot/config/plugins/unassigned.devices/iso_mount.cfg already exists May 2 09:46:33 Sakaar root: plugin: creating: /tmp/unassigned.devices/add-smb - from INLINE content May 2 09:46:33 Sakaar root: plugin: setting: /tmp/unassigned.devices/add-smb - mode to 0770 May 2 09:46:33 Sakaar root: plugin: running: anonymous May 2 09:46:33 Sakaar unassigned.devices: Updating share settings... May 2 09:46:33 Sakaar unassigned.devices: Share settings updated. May 2 09:46:33 Sakaar root: plugin: unassigned.devices.plg updated May 2 09:47:02 Sakaar flash_backup: adding task: /usr/local/emhttp/plugins/dynamix.my.servers/scripts/UpdateFlashBackup update May 2 09:48:09 Sakaar kernel: br-478eb7d28da2: port 15(veth550ccd3) entered blocking state May 2 09:48:09 Sakaar kernel: br-478eb7d28da2: port 15(veth550ccd3) entered disabled state May 2 09:48:09 Sakaar kernel: device veth550ccd3 entered promiscuous mode May 2 09:48:09 Sakaar kernel: br-478eb7d28da2: port 15(veth550ccd3) entered blocking state May 2 09:48:09 Sakaar kernel: br-478eb7d28da2: port 15(veth550ccd3) entered forwarding state May 2 09:48:09 Sakaar kernel: br-478eb7d28da2: port 15(veth550ccd3) entered disabled state May 2 09:48:10 Sakaar kernel: eth0: renamed from veth6b05ba4 May 2 09:48:10 Sakaar kernel: IPv6: ADDRCONF(NETDEV_CHANGE): veth550ccd3: link becomes ready May 2 09:48:10 Sakaar kernel: br-478eb7d28da2: port 15(veth550ccd3) entered blocking state May 2 09:48:10 Sakaar kernel: br-478eb7d28da2: port 15(veth550ccd3) entered forwarding state May 2 09:50:20 Sakaar ntpd[1502]: kernel reports TIME_ERROR: 0x41: Clock Unsynchronized May 2 09:50:35 Sakaar kernel: ata5.00: Enabling discard_zeroes_data May 2 09:50:35 Sakaar kernel: br0: port 2(vnet0) entered disabled state May 2 09:50:35 Sakaar kernel: device vnet0 left promiscuous mode May 2 09:50:35 Sakaar kernel: br0: port 2(vnet0) entered disabled state May 2 09:50:35 Sakaar kernel: sdf: sdf1 May 2 09:50:37 Sakaar kernel: ata5.00: Enabling discard_zeroes_data May 2 09:50:37 Sakaar kernel: sdf: sdf1 May 2 09:50:37 Sakaar kernel: ata5.00: Enabling discard_zeroes_data May 2 09:50:37 Sakaar kernel: sdf: sdf1 May 2 09:50:46 Sakaar nmbd[6276]: [2023/05/02 09:50:46.547088, 0] ../../source3/nmbd/nmbd_become_lmb.c:398(become_local_master_stage2) May 2 09:50:46 Sakaar nmbd[6276]: ***** May 2 09:50:46 Sakaar nmbd[6276]: May 2 09:50:46 Sakaar nmbd[6276]: Samba name server SAKAAR is now a local master browser for workgroup WORKGROUP on subnet 192.168.122.1 May 2 09:50:46 Sakaar nmbd[6276]: May 2 09:50:46 Sakaar nmbd[6276]: ***** May 2 09:50:46 Sakaar nmbd[6276]: [2023/05/02 09:50:46.547197, 0] ../../source3/nmbd/nmbd_become_lmb.c:398(become_local_master_stage2) May 2 09:50:46 Sakaar nmbd[6276]: ***** May 2 09:50:46 Sakaar nmbd[6276]: May 2 09:50:46 Sakaar nmbd[6276]: Samba name server SAKAAR is now a local master browser for workgroup WORKGROUP on subnet 172.18.0.1 May 2 09:50:46 Sakaar nmbd[6276]: May 2 09:50:46 Sakaar nmbd[6276]: ***** May 2 09:50:46 Sakaar nmbd[6276]: [2023/05/02 09:50:46.547228, 0] ../../source3/nmbd/nmbd_become_lmb.c:398(become_local_master_stage2) May 2 09:50:46 Sakaar nmbd[6276]: ***** May 2 09:50:46 Sakaar nmbd[6276]: May 2 09:50:46 Sakaar nmbd[6276]: Samba name server SAKAAR is now a local master browser for workgroup WORKGROUP on subnet 172.17.0.1 May 2 09:50:46 Sakaar nmbd[6276]: May 2 09:50:46 Sakaar nmbd[6276]: ***** May 2 09:53:52 Sakaar kernel: br0: port 2(vnet1) entered blocking state May 2 09:53:52 Sakaar kernel: br0: port 2(vnet1) entered disabled state May 2 09:53:52 Sakaar kernel: device vnet1 entered promiscuous mode May 2 09:53:52 Sakaar kernel: br0: port 2(vnet1) entered blocking state May 2 09:53:52 Sakaar kernel: br0: port 2(vnet1) entered forwarding state May 2 09:53:53 Sakaar kernel: ata5.00: Enabling discard_zeroes_data May 2 09:53:53 Sakaar kernel: sdf: sdf1 May 2 09:53:55 Sakaar kernel: vfio-pci 0000:01:00.0: vfio_ecap_init: hiding ecap 0x1e@0x258 May 2 09:53:55 Sakaar kernel: vfio-pci 0000:01:00.0: vfio_ecap_init: hiding ecap 0x19@0x900 May 2 09:55:00 Sakaar root: Fix Common Problems Version 2023.04.26
-
Also having the same issue with notifications from my UDM controller. The mac addresses are different. If I _block_ one, access to unraid is blocked.
-
Ha, ok. Your explanation makes sense at least!
-
Using the latest intel_gpu_top plugin `2021.07.16` my Intel 11700K shows as `Intel Rocketlake (Gen12)`, but it's a Gen11 ? Is this right?
(BraveBrowser)2021-11-13at23_53_49.thumb.png.bb245c6855214e4d0c1b659330d7d46f.png)




(BraveBrowser)2021-11-13at23_53_49.png.0a5466403aff092953b4cd4e453da4b2.png)