




QuestForTori
Members
-
Joined
-
Last visited
Everything posted by QuestForTori
-
I recently started getting an error where Sonarr will finish downloading a file, but will keep it as a .lnk file and be unable to import it due to a permission error which looks like this: 2025-03-02 10:35:54.5|Error|DownloadedEpisodesImportService|Import failed, path does not exist or is not accessible by Sonarr: /downloads/tv-sonarr/Invincible.S03E07.1080p.AMZN.WEBRip.AAC5.1.mkv/Invincible.S03E07.1080p.AMZN.WEBRip.AAC5.1.mkv.lnk. Ensure the path exists and the user running Sonarr has the correct permissions to access this file/folder This happens for nearly all new downloads for torrents and usenet, but mainly seems to affect torrents as far as I can tell. What could be the issue here?
-
Thanks! I put that variable in, but now I get a different error: (I'm sure that the database container is running and accepting connections, on the same virtual network as MySQL
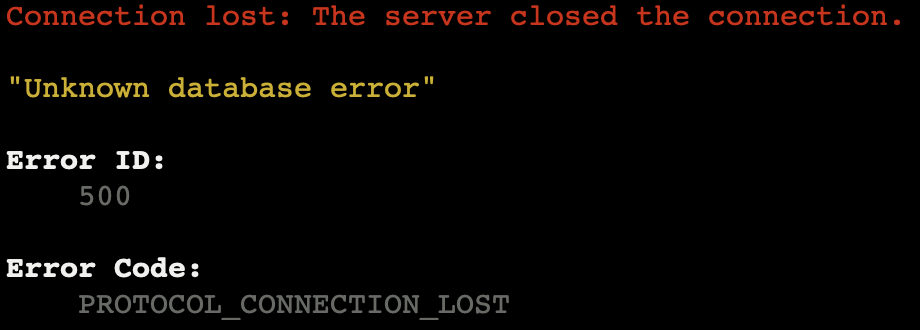
-
Having some trouble getting the Ghost docker container set up. I set up a MySQL8 docker to act as its database and set the username, password, and database name in the Ghost docker definition. The only thing I had to change is the port of the MySQL container since it uses the same port as my MariaDB container. I changed it, but the Ghost container doesn't have a place to specify a port for the database IP, and adding one seems to cause a connection error. When I use the raw IP and the correct login info, I get this error when starting the Ghost container:
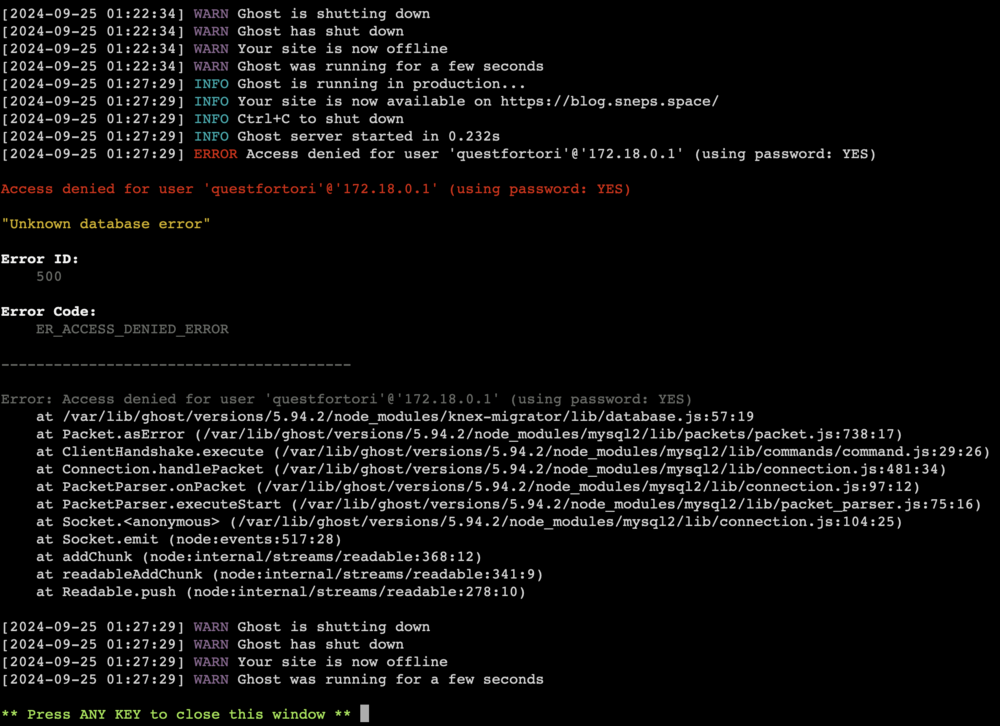
-
Thank you so much, I look forward to it!
-
Sure, thank you for the help! When looking in the Chooser, I don't see any servers appear.
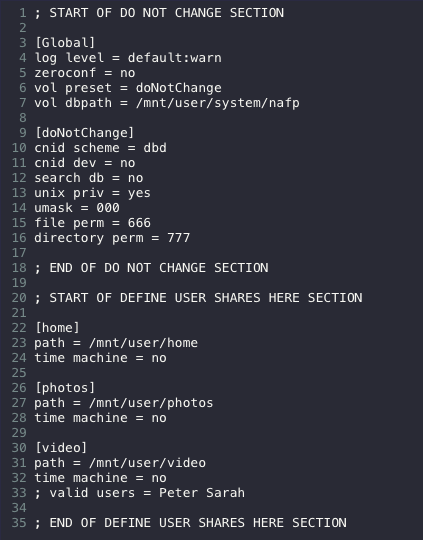
-
Has anyone successfully gotten this working with classic (Pre-OS X) versions of MacOS? I'm trying to get the share to appear on System 7.5.3 but the shares don't appear in Chooser.
-
Looks like turning off AdGuard and rebooting made the errors stop! I'll probably go and ask around specifically about the AdGuard docker, then - this seems like it might be a bug in the container.
-
Gotcha, here you go: skaianet-diagnostics-20231016-1051.zip
-
Hmm, I'm still seeing these same errors in the logs after switching to ipvlan, should I still be worried?
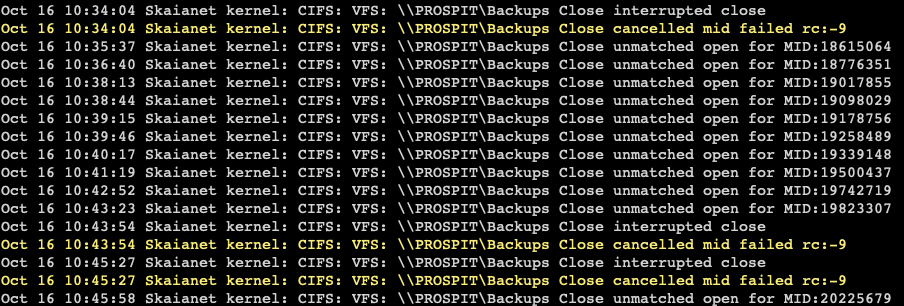
-
Thanks for the tip, I'll give that a try and I'll report back if I keep getting crashes!
-
You mean I should just run the command umount /var/lib/docker after upgrading?
-
I already did upgrade to 6.12.4, then I tried downgrading to 6.12.3 to see if it would fix the problem, and it didn't. Is there anything else I could try?
-
Sure, here is the output zip from the diagnostics menu from my server (Though this is before has crashed yet on this power-on cycle). Also, the remote server is an x86 Synology NAS on the same network. skaianet-diagnostics-20231015-1838.zip
-
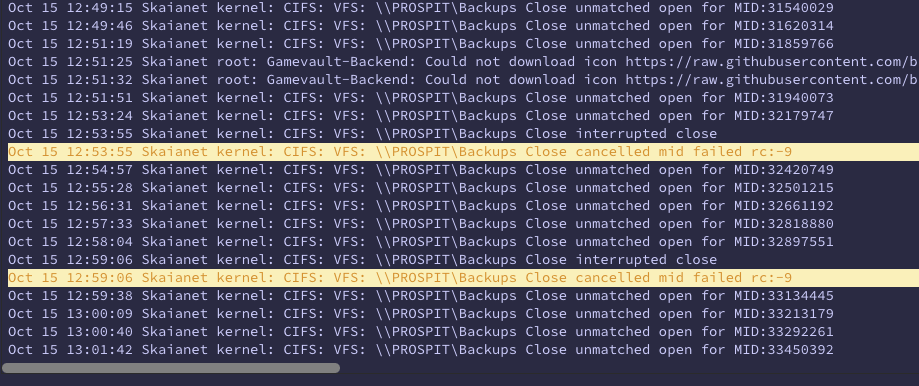
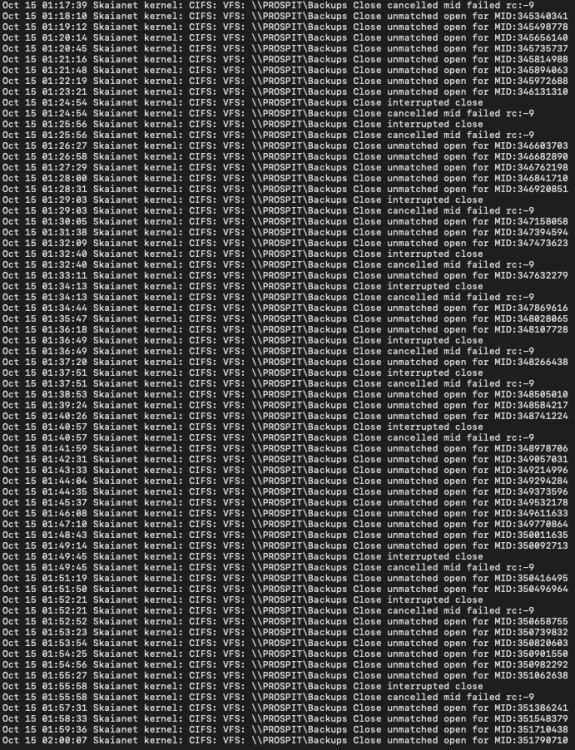
After updating past Unraid 6.10, I get constant log errors regarding the network share I have mounted. I can't even unmount it because it says it's always busy. Can anyone offer help? This seems to keep crashing my whole server every day or two.
-
Thank you so much, it's working now!
-
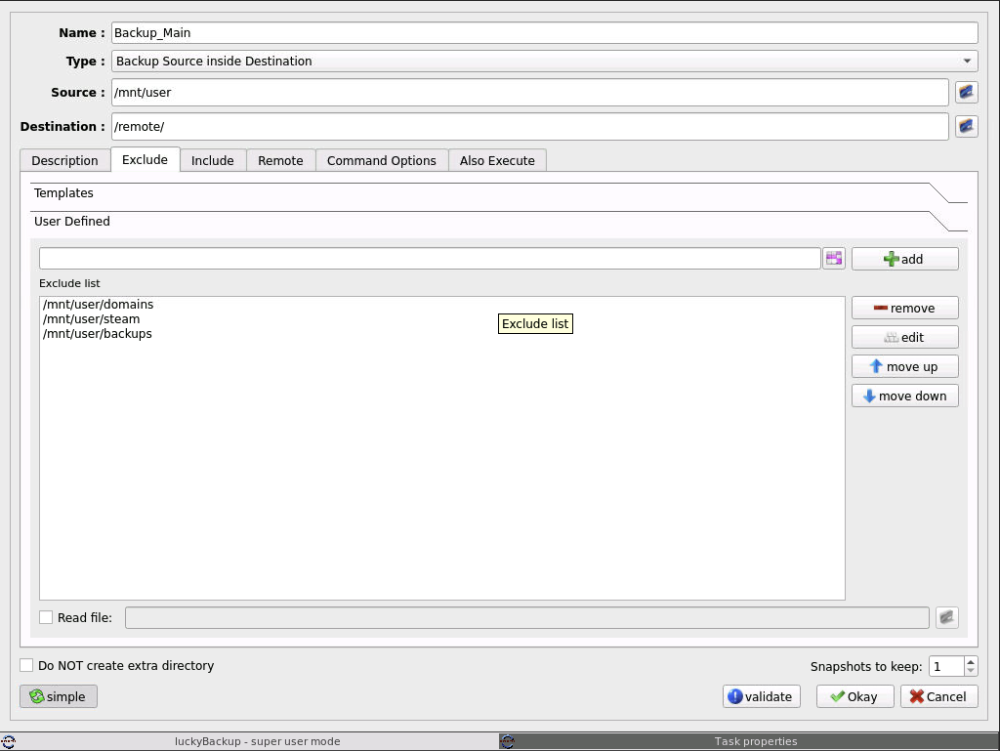
Even when adding /* to the end of each path, it still tries to back them up. (i.e /mnt/user/domains/*) Did you mean that the "/mnt/user/" should be deleted, as well?
-
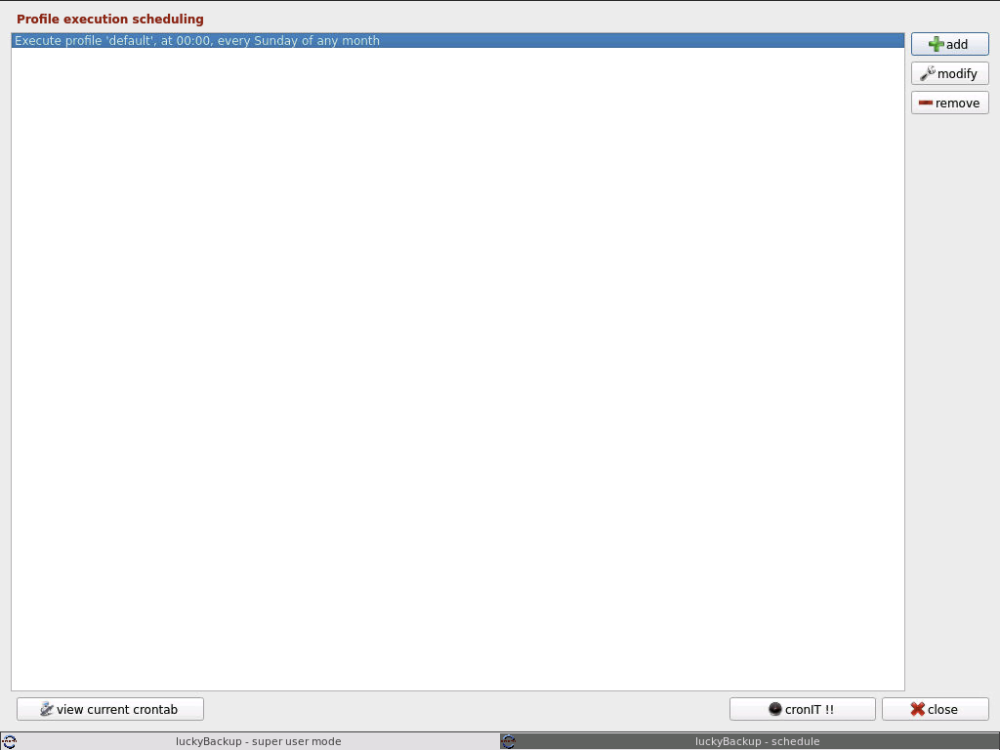
Sure, here are the Excluded and Schedule screens: The folders marked as excluded still get backed up, and a backup does not start at the specified time.
-
I'm running LuckyBackup, but it seems to totally ignore the folders I marked as excluded, and the backup doesn't auto-run when it's scheduled to. There don't seem to be any logs showing anything out of the ordinary - what could be the issue?
-
Oh no, now after restarting the container, the webUI isn't even working and the logs are looking even MORE dire: https://pastebin.com/VS4LZE8U EDIT: I wiped all my data and started fresh, and even now, requesting a brand new SSL cert still gives an internal error, and in the logs, shows this: [3/16/2023] [9:20:53 AM] [Express ] › ⚠ warning Command failed: certbot certonly --config "/etc/letsencrypt.ini" --cert-name "npm-1" --agree-tos --authenticator webroot --email "[EMAIL REDACTED]" --preferred-challenges "dns,http" --domains "[URL REDACTED]"
-
Should I run a chmod on the affected directory, or is there another solution?
-
Is there any way to get it working again after deleting unused certs and proxies? Whenever I try and perform any action in NPM now, it just shows an "Internal Error" in the webUI, and shows this in the log: [3/16/2023] [9:04:28 AM] [Express ] › ⚠ warning Command failed: /usr/sbin/nginx -t -g "error_log off;" nginx: [emerg] cannot load certificate "/etc/letsencrypt/live/npm-6/fullchain.pem": BIO_new_file() failed (SSL: error:02001002:system library:fopen:No such file or directory:fopen('/etc/letsencrypt/live/npm-6/fullchain.pem','r') error:2006D080:BIO routines:BIO_new_file:no such file) nginx: configuration file /etc/nginx/nginx.conf test failed
-
The latest update to NPM today seems to have broken SSL and thus none of my redirects are working anymore - is anyone else seeing this issue? All my SSL certs expired recently, and when I try and renew them, it always fails. Making a new cert seems to fail too, just showing "Internal Error" in the webUI, and the logs show a failure, too. Log: https://pastebin.com/Gf59VdS3
-
I just bought this app today and I can't connect via my WAN IP, but I can just in Safari - is this app no longer supported? I hope I didn't waste 5 bucks, lol









