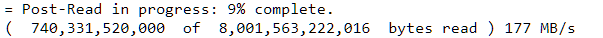papnikol
Members
-
Joined
-
Last visited
Everything posted by papnikol
-
Some thoughts: - You do not mention, but I am guessing that the disconnection happens after preclear is completed. Otherwise the signature not being valid is expected since it is the last think that happens when preclearing. If the disconnection happens earlier, you will naturally not have a valid signature. - Did you check the smart stats on the drive? - The only solution I can think of, until someone more knowledgable chimes in, is to try another drive, if you have one.
-
To make what binhex says even clearer: - There is one plugin by gfjardim that works as a front end to the preclear script. This works fine. - There are 3 actual scripts that can perform the preclear action The original script by the great JoeL (which has not been updated for some time) The faster script by bjp999 which stresses the disk equally but is (obviously) faster The script by gfjardim which is probably the most efficient one and is used by default by the plugin At the moment the only script working is the bjp999 one, patched by binhex (link here). In order to take advantage of its faster post-read option it should be invoked with the -f argument. When gfjardim fixes the bugs (which will be announced in this thread), one should probably revert to using his script.
-
Thanks for the clarification gfjardim. I did not expect that, tbh, since my respective times are ~180Mb/s and ~60Mb/s. That means that the (sum + verify zero sum) portion roughly takes twice the time than the reading portion ...
-
I think 65MB/s might be normal at the end of the disk, but is that the case for rvoosterhout? Because I am also preclearing an 8TB Seagate archive and although speeds for preread and zeroing were normal, I am getting a postread speed of 57 MB/s but I am only at 8% (I dont remember if I clicked the fast post-read option, still too slow). EDIT: I might be misunderstanding something because the web gui shows that: but the log (pressing the eye icon) shows that:

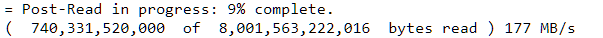
-
. Will do. It will be some time as it is an 8tb disk. I will post the results in the thread you mentioned
-
I am trying it now. One difference I noticed is that the starting preread speed is different, although this could be inherent to the scripts. The gfjardim script started at 175MB/s and the bjp666 one started at 133MB/s
-
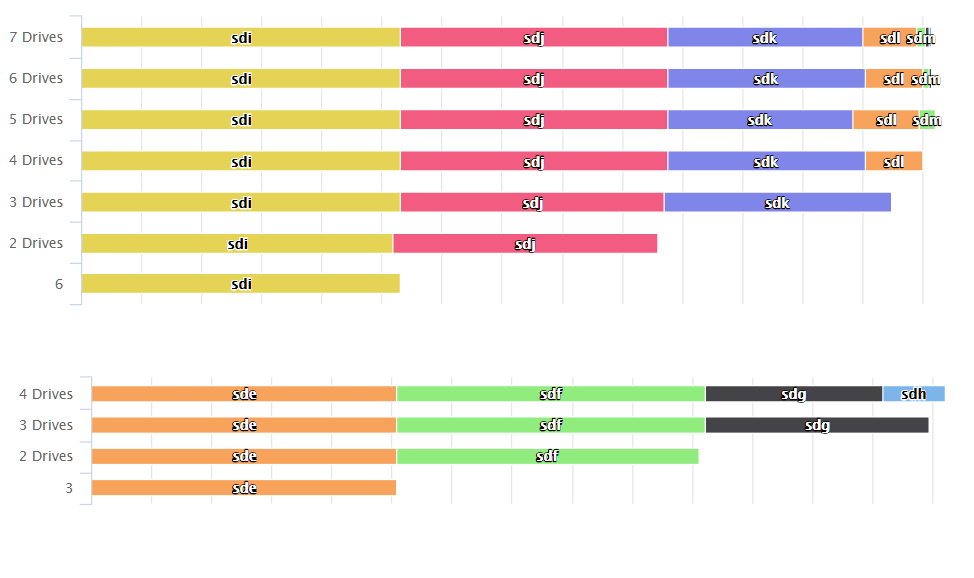
Wow, I like your graph much more than mine. So, my array has 2 AOC-SASLP controllers with 8 and 3 HDDs respectivelly. I moved one drive so that there are 7 and 4 HDDs on each controller, in order to exceed both controllers' max bandwidth. The balancing problem appears in both controllers. Maybe it is a problem with the controller settings. Maybe I should try disabling int 13h (although I never understood what that is)....

-
Thanks for your prompt response, it works. It is difficult to follow all this stuff if you get out of touch for a few months. Does the same patch work on the bjp666 script? i.e. could i try sed -i -e "s/print \$9 /print \$8 /" -e "s/sfdisk -R /blockdev --rereadpt /" preclear_bjp.sh instead of sed -i -e "s/print \$9 /print \$8 /" -e "s/sfdisk -R /blockdev --rereadpt /" preclear_disk.sh ?
-
I tried using the JoeL or bjp666 preclear scripts since the webgui gfjardim script is currently not working. I get errors with both of them. Have they become obsolete for Unraid 6.5?
-
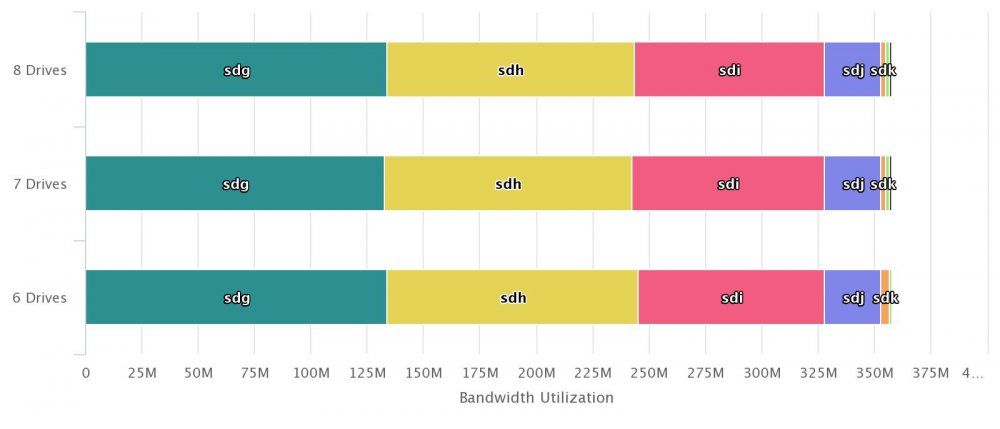
Hi. I run diskspeed for a controller that has 8 disks attached (attached file). The controller is an AOC-SASLp-MV8 (PCIe x4). Do those results indicate that the 4x PCIe lanes are saturated by the 4 first drives? Or could it be something else?
-
In network settings, try setting a static DNS addresses of 8.8.8.8 and 8.8.4.4 and try again thanks, that solved the problem, although I do not understand why Google's DNS is helping
-
Hi, I am tryin to install the plugin through the unRAID Plugin Manager I get the following: plugin: installing: https://raw.githubusercontent.com/theone11/serverlayout_plugin/master/serverlayout-package-2015.09.25.tar.gz plugin: downloading https://raw.githubusercontent.com/theone11/serverlayout_plugin/master/serverlayout-package-2015.09.25.tar.gz plugin: downloading: https://raw.githubusercontent.com/theone11/serverlayout_plugin/master/serverlayout-package-2015.09.25.tar.gz ... done Warning: simplexml_load_file(): /tmp/plugins/serverlayout-package-2015.09.25.tar.gz:1: parser error : Start tag expected, '<' not found in /usr/local/emhttp/plugins/dynamix.plugin.manager/scripts/plugin on line 193 Warning: simplexml_load_file(): ??V in /usr/local/emhttp/plugins/dynamix.plugin.manager/scripts/plugin on line 193 Warning: simplexml_load_file(): ^ in /usr/local/emhttp/plugins/dynamix.plugin.manager/scripts/plugin on line 193 plugin: xml parse error Can someone help?
-
Hi NAS I was wondering if you have found a solution. I seem to have a similar problem with you. After I used mc, my previously funtional cache_dirs command: cache_dirs -d 2 -m 3 -M 4 -w -F never stops. I even tried to decrease the depth but to no avail. I wonder if you have found a solution. PS: I have 2.5GB of ram (and 1.5 GB seem to be free) and i am using cache_dirs 1.6.5. i also get this: Executed find in 838.856452 seconds, weighted avg=841.972656 seconds, now sleeping 4 seconds which I know is normal but I thought it was supposed to start after cache_dirs has fully scanned my disks
-
thing is, most of the market wont do any kind of testing. unraid is a small niche of people who will do that but most common people wont test the hard drive. most shops that will sell you a custom pc wont do any testing either. Also, fixing the drives might cost but, in the long run, replacing them could cost more (although i guess they estimate that).
-
Looks good ya? Took a while Elapsed Time: 74:50:01 seems ok to me. but 3 days? it takes 25-30hrs for a 2TB WD EARS in my pc (and it is quite old, sata I - not that it makes any much difference) when nothing else is running
-
come to think of it now, isnt that supposed to be one of the seagate drives that cave to have their firmware update because of the "click of death" issue? If it came with the old firmware, that might be your problem. I hope you now understand how important and useful preclear is, Joe (just kidding)
-
larson might have a point. although i could not think of a practical solution, i have a possible conspiracy theory explanation: is it possible that this drive has been actually used before, returned and then sent again as new? that would explain your problems...
-
Userpaul, it seems your rig has created a lot of envy which 8 port sata cards are you using? I myself am using the saslp-mv8 and they get quite hot. so, i was wondering where you got those fans that fit underneath the saslp? UPDATE: i found some in amazon.co.uk ( i live in europe using keywords: pci + fan) http://www.amazon.co.uk/s/ref=nb_sb_noss?url=search-alias%3Daps&field-keywords=pci+fan&x=0&y=0 So i am just wondering if yours is silent? if yes i would rather buy the same type as yours than a fan about which i know nothing... I have the same cards as you I bought mine from the local Maplin store just up the road (impulse purchase). Whilst I was preclearing my HDD's I noticed that the saslp-mv8 cards got very very hot so I had a fan propped on the psu cooling them down. These are the fans. http://www.maplin.co.uk/Module.aspx?ModuleNo=28679 Both fans are controlled with the Skythe fan speed controller and I have a temp sensor on each card. The fans reduce the temps of the cards by around 20 C The advantage of having the fans managed by the Skythe controller is I can strike a balance between fan speed and noise level. I plan to install a small fan onto the heatsink and I am currently looking at kits to do that. thanx for the info unfortunately this creates more questions (at least to me): 1. the temp sensor is something that comes with the fan speed controller or something you bought separately? 2. i have never had a fan controller but i was thinking of buying one. How does it work? does it provide power straight to the fan thus working like a dimmer?
-
Userpaul, it seems your rig has created a lot of envy which 8 port sata cards are you using? I myself am using the saslp-mv8 and they get quite hot. so, i was wondering where you got those fans that fit underneath the saslp? UPDATE: i found some in amazon.co.uk ( i live in europe using keywords: pci + fan) http://www.amazon.co.uk/s/ref=nb_sb_noss?url=search-alias%3Daps&field-keywords=pci+fan&x=0&y=0 So i am just wondering if yours is silent? if yes i would rather buy the same type as yours than a fan about which i know nothing...
-
Hi, I bought an EARS 2TB few days ago and run preclear These were the results i got: root@Tower:~# screen -r 6946 = Step 1 of 10 - Copying zeros to first 2048k bytes DONE = Step 2 of 10 - Copying zeros to remainder of disk to clear it DONE = Step 3 of 10 - Disk is now cleared from MBR onward. DONE = Step 4 of 10 - Clearing MBR bytes for partition 2,3 & 4 DONE = Step 5 of 10 - Clearing MBR code area DONE = Step 6 of 10 - Setting MBR signature bytes DONE = Step 7 of 10 - Setting partition 1 to precleared state DONE = Step 8 of 10 - Notifying kernel we changed the partitioning DONE = Step 9 of 10 - Creating the /dev/disk/by* entries DONE = Step 10 of 10 - Testing if the clear has been successful. DONE = Disk Post-Clear-Read completed DONE Disk Temperature: 30C, Elapsed Time: 27:56:04 ============================================================================ == == Disk /dev/sdc has been successfully precleared == ============================================================================ S.M.A.R.T. error count differences detected after pre-clear note, some 'raw' values may change, but not be an indication of a problem 19,20c19,20 < Offline data collection status: (0x80) Offline data collection activity < was never started. --- > Offline data collection status: (0x84) Offline data collection activity > was suspended by an interrupting command from host. 54c54 < 1 Raw_Read_Error_Rate 0x002f 100 253 051 Pre-fail Always - 0 --- > 1 Raw_Read_Error_Rate 0x002f 200 200 051 Pre-fail Always - 0 58c58 < 7 Seek_Error_Rate 0x002e 100 253 000 Old_age Always - 0 --- > 7 Seek_Error_Rate 0x002e 200 200 000 Old_age Always - 0 63c63 < 193 Load_Cycle_Count 0x0032 200 200 000 Old_age Always - 11 --- > 193 Load_Cycle_Count 0x0032 200 200 000 Old_age Always - 12 67c67 < 199 UDMA_CRC_Error_Count 0x0032 200 253 000 Old_age Always - 0 --- > 199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always - 0 ============================================================================ Having had some problems with an EARS few weeks ago i decided to run preclear a second time, just to be sure. I have been away for some time and when i came back i reconnected using screen. I guess preclear was over and i saw this screen: > Conveyance self-test routine > recommended polling time: ( 5) minutes. > SCT capabilities: (0x3035) SCT Status supported. > SCT Feature Control supported. > SCT Data Table supported. > > SMART Attributes Data Structure revision number: 16 > Vendor Specific SMART Attributes with Thresholds: > ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE > 1 Raw_Read_Error_Rate 0x002f 200 200 051 Pre-fail Always - 0 > 3 Spin_Up_Time 0x0027 253 253 021 Pre-fail Always - 1091 > 4 Start_Stop_Count 0x0032 100 100 000 Old_age Always - 10 > 5 Reallocated_Sector_Ct 0x0033 200 200 140 Pre-fail Always - 0 > 7 Seek_Error_Rate 0x002e 200 200 000 Old_age Always - 0 > 10 Spin_Retry_Count 0x0032 100 253 000 Old_age Always - 0 > 11 Calibration_Retry_Count 0x0032 100 253 000 Old_age Always - 0 > 12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 8 > 192 Power-Off_Retract_Count 0x0032 200 200 000 Old_age Always - 7 > 193 Load_Cycle_Count 0x0032 200 200 000 Old_age Always - 15 > 196 Reallocated_Event_Count 0x0032 200 200 000 Old_age Always - 0 > 197 Current_Pending_Sector 0x0032 200 200 000 Old_age Always - 0 > 198 Offline_Uncorrectable 0x0030 100 253 000 Old_age Offline - 0 > 199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always - 0 > 200 Multi_Zone_Error_Rate 0x0008 100 253 000 Old_age Offline - 0 > > SMART Error Log Version: 1 > No Errors Logged > > SMART Self-test log structure revision number 1 > No self-tests have been logged. [To run self-tests, use: smartctl -t] > > > SMART Selective self-test log data structure revision number 1 > SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS > 1 0 0 Not_testing > 2 0 0 Not_testing > 3 0 0 Not_testing > 4 0 0 Not_testing > 5 0 0 Not_testing > Selective self-test flags (0x0): > After scanning selected spans, do NOT read-scan remainder of disk. > If Selective self-test is pending on power-up, resume after 0 minute delay. > ============================================================================ So, what does that mean? Could preclear, have stoped abruptly?
-
Officially impressed/jealous