




Pardasus
Members
-
Joined
-
Last visited
-
Moin zusammen, ich habe bei mir etwas umgebaut und habe mein Home Assistant ein paar Wochen auf einen eigenen Rechner laufen lassen. Nun habe ich mein unRAID Rechner wieder eingerichtet und das HA Backup zurückgespielt. Dabei habe ich exakt das gleiche beobachtet wie bei fschubi. Alle Matter Geräte, welche über Thread angebunden sind, sind nicht mehr erreichbar. Auch können Sie nicht neu hinzugefügt werden. Ich bin dann auch auf den Beitrag "Update issues with Matter container "Network is unreachable"" gestoßen. Ich habe kein Ahnung was ich da als Route eintragen soll. IPv4 kein Problem aber bei IPv6 bin ich raus. Ich hatte nun das Glück noch einen zweiten unRAID Rechner (Backup-System) laufen zu habe. Dieser läuft noch auf 7.0.0 und ich konnte die Route von dort einfach abschreiben und sie auf mein Hauptsystem wieder hinzufügen. Rechner neu gestartet und nun kann ich zumindest wieder Geräte anlernen. Bestehende bleiben aber offline. Aber ist das jetzt ein Bug von 7.0.1 ? In den Beitrag "Update issues with Matter..." steht ja einfach, dass es gelöst ist. Ja aber doch nur weil er für sich ne Lösung gefunden hat. Aber das ja keine generelle Lösung. Ich hatte jetzt auch einfach nur Glück und konnte das von mein noch Laufenden System abschreiben. Ich würde fast behaupten, dass niemand der heute mit unRAID und HA anfängt, Matter bzw. das Thread Protokoll in der VM zum laufen bringen wird da ja anscheinend die Route fehlt, die sonst immer da war?
-
Ich habe es mal auf br0 gestellt und die VM läuft unverändert. Aber wenn ich das richtig verstanden habe, ich das so ein Libvirt ding und kann einfach ignoriert werden? Die Route lässt sich zwar auch dann nicht löschen, aber wird dann ja auch nicht mehr verwendet? Gibt es einen Grund warum man virbr0 statt br0 verwenden sollte?
-
Habe alles beende und es ausgeschaltet und ein Neustart gemacht. Danach waren die Webdienste der einzelnen Docker über den Rechner selbst nicht mehr erreichbar. Ich habe ein Kontrollmonitor an den Rechner mit Maus und Tastatur und greife hin und wieder mal über den Rechner selbst auf die Seiten der Programm zu. Die Route blieb aber drin und lässt sich auch nicht löschen.
-
Bist du dir da sicher? Im Docker sieht das für mich richtig aus, oder bin ich hier falsch?

-
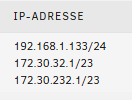
Moin zusammen, in meiner Routing-Tabelle steht ein Netzwerk, dass ich nicht weg bekommen. Selbst wenn ich es lösche, taucht es nach einen Neustart wieder auf. Ich habe kein Docker, der so ein Netzwerk nutzt. Und so sieht meine einzige VM aus, die ich habe. Ich habe aber das Gefühl, das dies durch die VM dort eingetragen. Aber ich finde hier nichts, was diesen Eintrag verursachen könnte. (Home Assistant VM)


-
@DataCollector Bei der Stromversorgung über den USB-Hub könntest du recht haben. Es besteht die Möglichkeit diesen USB-Hub zusätzlich mit Strom zu versorgen. Das habe ich mal gemacht und nun hängt da noch ein Netzgerät dran. Das btrfs hat mir unRAID damals eingerichtet. Ich habe nur die Platten hinzugefügt. Dies funktioniert aber bis jetzt absolut zuverlässig und fehlerfrei. @alturismo Das ist mit USB-Platten Problem gibt, war mir nicht bekannt. Deshalb habe ich es auch gar nicht erwähnt. Hatte auch bis jetzt nie Problem damit. Auch das zweit System läuft mit der gleichen Konfiguration komplett fehlerfrei und Performant. Wie ich oben schon zu DataCollector geschrieben habe, hat mir unRAID die Platten als btrfs so Partitioniert und Formatiert. Ich dachte mir damals, wenn unRAID das vorgibt, wird es schon das richtige sein. Aber gut zu wissen, falls ich da mal Probleme mit bekommen sollte. Es gab auch schon 2-3x wo sich unRAID aufgehängt hat und ich hart ausschalten musste. Aber das btrfs hat mir das nie übel genommen. Aber gut, mein Rechner läuft wieder wie er immer lief. Mehr als ausreichend schnell und ohne Fehlermeldung, nachdem ich die HDD entfernt habe. Bei den anderen mache ich noch ein Ausführlichen Smart-Test um sicher zu gehen. Danke für eure Unterstützung 🙂
-
Ich habe das System nun schon seit über ein Jahr mit den externen HDDs (USB). Läuft absolut einwandfrei. Auch die Performance ist mehr als ausreichend. Hatte nur vorher SSDs in den USB-Gehäusen. Habe die dann vor ca. 190 Tagen gegen HDDs getauscht und vor 1 Monat ist mir eine davon kaputt gegangen. Wurde nicht mehr erkannt und hat klack Geräusche gemacht. Das jetzt noch eine defekt ist, ist schon sehr ärgerlich. Aber sonst kann ich mich absolut nicht beklagen. Wie schon geschrieben, nutze ich die Hauptsächlich zum Speichern von Daten. Die ganze "action" findet auf den internen NVMe´s statt. Was spricht beim NVMe Pool gegen btrfs ? Muss zugegen, da kenne ich mich nur sehr oberflächlich aus. Wenn sich jetzt noch gefragt wird "Warum nutzt er bitte USB Laufwerke?!"... na, wegen der Optik Links Produktiv, rechts das Backup-System. Denn, was bringen mir Datenbackups, wenn die Hardware kaputt geht so kann ich direkt auf den ersatz Rechner umstellen. Die Synchronisation der Daten zwischen den Rechner, findet über "Syncthing" statt.

-
Trotzdem sollten sie sich nicht in kb Bereich bewegen, bei der Datenübertragung. Ich habe nun die Vermutlich defekte Platte entfernt und alles läuft wieder normal und die Datenübertragunsrate lieg bei um 80-100MB/s. Hätte aber nie gedacht, dass eine "halb" defekte Festplatte zu einer stark erhöhten CPU-Last führt. Ich habe mich damals bewusst für die 2,5" entschieden, da ich alle Platten extern betreiben muss. Mein Mini-PC hat nur platz für 2x NVMe. Der Speed reich mir völlig, bei den HDDs. Es werden nur drei Video Streams drauf gespeichert und der rest an Daten liegt da eigentlich nur rum. Die NVMe, die sind wichtig für mich. Da laufen alle Docker und die VM drauf.
-
Das sind 3x WD20SPZX-22UA7T0. Ich konnte im Netz nichts dazu finden.
-
Das kann ich dir gar nicht genau sagen. Im Datenblatt der Festplatte steht davon nichts. Allerdings lief das System ein halbes Jahr, mit den Platten, fehlerfrei. Dann ist die erste Platte ausgestiegen und wurde getauscht. Jetzt sieht es fast so aus, als wäre die nächste Platte defekt. Ein kurzer SMART-Test war fehlerfrei. Der erweiterte Test läuft nun aber schon 24h und hängt seit 12h bei 90% fest. Ich habe diesen bei einer Platte einmal angeworfen. Tja, ich werde den Test noch bei den anderen machen, aber es sieht so aus als wäre die nächste WD Blue HDD defekt. Dabei habe ich extra auf HDD gesetzt und nicht auf SSD damit sie länger halten...
-
So, ich bin wieder schlauer geworden. Ich habe die Paritätsplatte mal entfernt und zack, alles läuft wieder wie es soll. Dann habe ich die Partition gelöscht und sie erneut hinzugefügt. Als die Parität dann wiederhergestellt wurde, hat er die 1h noch normal schnell gearbeitet, um dann wieder in den kb Speed Bereich zurück zu fallen. Also habe ich sie erst mal wieder entfernt und werde nun meine Daten mal verschieben. Danach das gesamte Array Platt machen und neu aufbauen.
-
Kein ding hatte mich schon gewundert 😄 Aber wir kommen der Sache näher. Die Performance der Platten ist absolut unterirdisch und bewegt sich in kb/s Bereich. Ich habe noch zwei NVMe als Cache Pool, der ist weiterhin super schnell. Aber irgendwas muss da passiert sein, als ich die Paritätsplatte wieder neu hinzugefügt habe. Nun könnte ich die Daten abziehen und auf mein unRAID Backup-System schieben, aber wenn das so langsam ist wird das Monate dauern. Bin gerade etwas ratlos. p.s.: ein S.M.A.R.T Test verlief fehlerfrei.
-
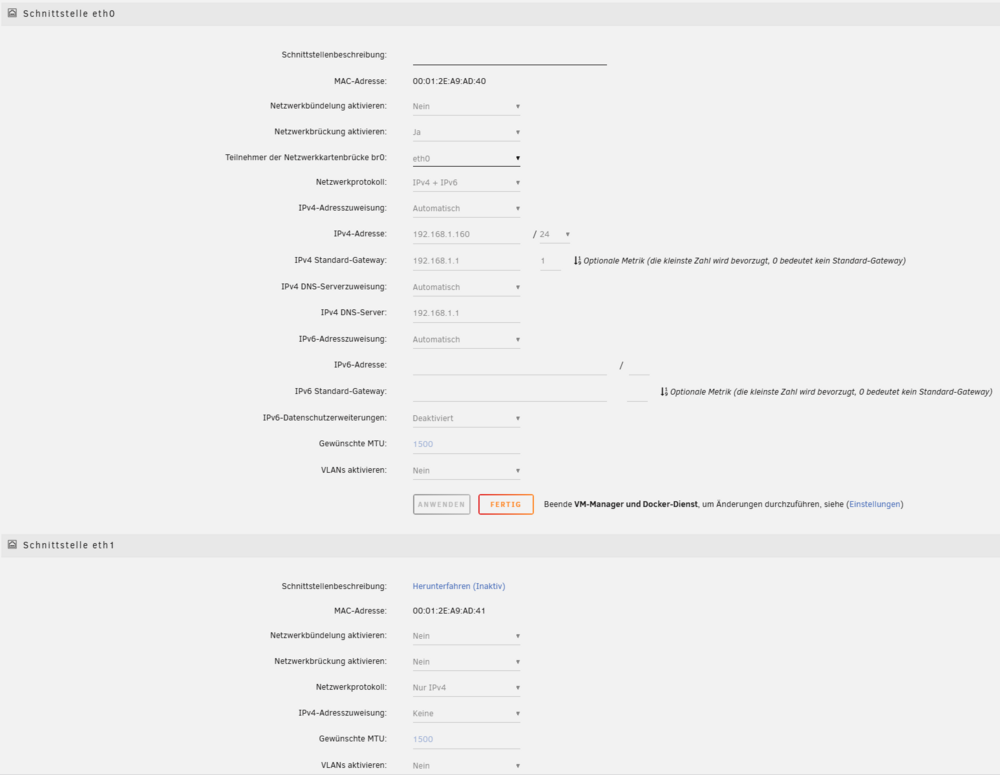
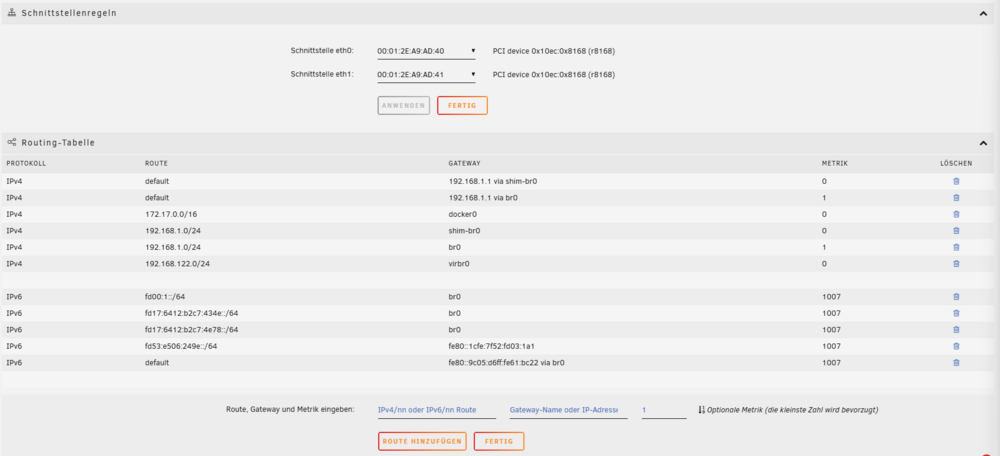
Ich habe vier Netzwerkkarten eingerichtet? Die Hardware hat zwei, wovon ich nur eine nutze. Das kommt mir hier aber etwas komisch vor. Woher kommt das shim-br0? Und bei IPv6 sieht das auch irgendwie doppelt aus. (ich brauche IPv6 da ich vieles über Matter laufen lasse und Home Assistant seitdem besser mit den Geräten Kommuniziert)
-
Erstmal danke für eine mühe 🙂 @alturismo ich hatte es bewusst auf IPVLAN gestellt, um zu sehen ob es damit evtl. besser wird. Sonst habe ich immer macvlan an. Habe es nun auch wieder aktiviert. Als Netzwerk verwendet ich Unifi. Mein System besteht aus einen Pool von 3x 2TB Platten, wovon eine die Paritätsplatte ist. Diese ist vor ca. 1 Monat ausgefallen und ich habe das System ohne weiter laufen lassen. Vor ca. einer Woche habe ich dann vom Hersteller eine neue bekomme. Diese habe ich eingebaut und nun sind es wieder drei. Ich bin mir nicht 100%ig sicher, aber es könnte sein das es genau dann angefangen hat. unRAID hat gerade ein Parität-Check gestartet und sagt, er brauch zwischen 30-60 Tagen, teilweise geht es auf 100+ Tage hoch 😮vielleicht stimmt was mit den Platten nicht? EDIT: wenn ihr jetzt keine Ideen mehr habt, werde ich alle Daten auf mein Backup unRAID System verschieben und das Array einmal komplett neu aufbauen (Partition löschen etc.) Ich habe gerade noch mal die Diagnostics erstellt, das hat nun nur ein paar Sekunden gedauert. smarthomeserver-diagnostics-20241015-1955.zip
-
Moin zusammen, nach ein paar Tagen des herum Probierens, finde ich einfach den Fehler nicht. Ich habe ein recht Potentes unRAID System schon seit fast einem Jahr laufen. Aber seit ca. 1 Woche dreht die CPU-Last immer wieder hoch. Ich betreibe eine VM und eine reihe von Docker. Aber alles nichts ungewöhnliches. Ich habe sogar das Docker img gelöscht und alle Docker neu erstellt. Ich habe aber das Gefühl, dass es an unRAID selbst liegt. Ich nutze die 7.0.0-beta.3, habe aber auch schon ein Downgrade auf beta 2 gemacht, ohne Änderung. Eine Zeitlang hatte ich keine Paritäts Platte, da sie kaputt war. Nach dem ersetzen der Platte, ging es glaube ich los. Kann auch 1-2 Tage später gewesen sein. Ich bin jetzt auch kein Laie und weis eigentlich was ich hier mache, aber ich finde einfach den Grund nicht. Bemerkt habe ich das Problem eigentlich auch erst durch meine Monitoring Software, welche fast in Minuten Takt meldet, dass der "scrypted" Docker, bzw. die Webseite, nur sehr schwer erreichbar ist. Bis hin zu kurzen ausfällen wo dann für ein paar Sekunden gar nichts mehr geht. Ich nutze "scrypted" auch nicht erst seit gestern und glaube auch nicht das dies das Problem ist, sondern mehr "das Opfer" was unter der hohen Systemlast leidet. Ich habe mal meine Diagnostics angehängt. Das erstellen der Datei hat auch 2-3 Minuten gedauert. Kommt mir etwas lang vor. smarthomeserver-diagnostics-20241014-1939.zip








