niwmik
Members
-
Joined
-
Last visited
Everything posted by niwmik
-
I used the following tag to get it back up and running until a more permanent solution comes up linuxserver/nextcloud:24.0.5
-
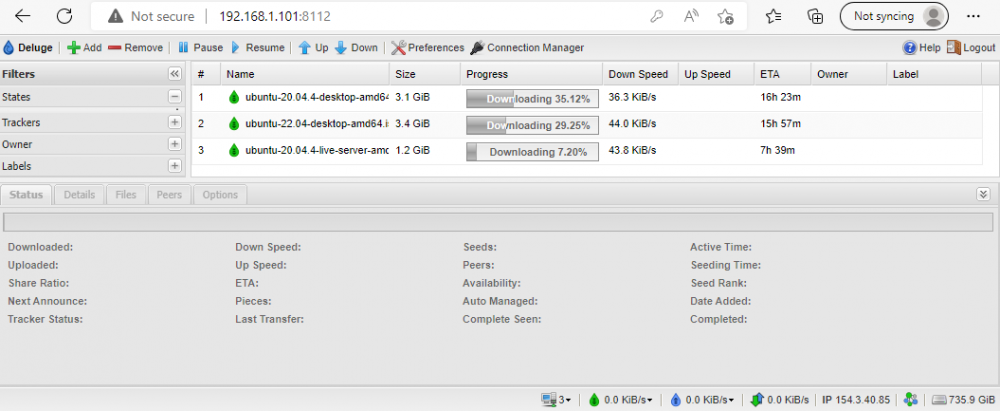
I wanted to continue the issue I'm having with DelugeVPN here. I rebooted the unRaid server 3 times but that didn't completely fix the issue. I'm able to download but it seems to only allow 1 peer per torrent. I changed the PIA wireguard endpoint from ca-toronto.privacy.network to ca-montreal.privacy.network but get the same results. Is this an issue with my configurations or is it an issue with PIA? Thanks.
-
I'm experiencing the same issue with Unraid 6.9.2 and the latest DelugeVPN-binhex which coincidently updated last night. I downgraded to 2.0.5-1-04 but still had this issue. Privoxy works so I'm confident I'm logged into PIA. I have another unraid server with the same configurations and the latest DelugeVPN-binhex is behaving as expected.
-
AutoBackupVM is a script written by an Unraid user that I use to backup my Windows 10 VM. I've never had an issue with it before. I clicked "RUN SCRIPT" in User Scripts to manually run the script so I didn't have access to a terminal screen. As a test, I changed the cron schedule from "Custom" to "Scheduled Monthly" and changed Monthly schedule in Scheduler to run on the 5th. I didn't see anything in the logs this morning but AutoBackupVM did run successfully. As far as I can tell, the script only fails when I set it to a custom cron schedule.
-
Thanks for the tip. I changed the cron schedule to "50 2 * * 4 [ $(date +%d) -le 07 ]" and it appears to have run this morning based on what it is in the logs. Nov 4 02:50:01 Atlas crond[2264]: exit status 2 from user root [ $(date +\%d) -le 07 ] /usr/local/emhttp/plugins/user.scripts/startCustom.php /boot/config/plugins/user.scripts/scripts/AutoBackupVM/script > /dev/null 2>&1 However, AutoBackupVM script doesn't appeared to have ran. I just ran it manually to test and it ran successfully. Is there something else I'm missing?
-
I'm trying to run a script with the following custom cron schedule: 50 2 * * 2 [[ $(date +%e) -le 7 ]] I wanted the script to run the 1st week of every month on Tuesday at 2:50am but it didn't run this past Tuesday. I just copied the cron schedule for my parity check and made some modifications. Do you see anything wrong with this cron schedule?
-
I'm in the process of testing the disks starting with changing the parity disk. I'm in the middle of a parity rebuild and I see the following in the system log. I can't tell which disk has the corruption. Not sure what "dm-2" is. Sep 24 11:08:22 Atlas kernel: XFS (dm-2): Metadata corruption detected at xfs_buf_ioend+0x51/0x284 [xfs], xfs_inode block 0x1796d41c8 xfs_inode_buf_verify Sep 24 11:08:22 Atlas kernel: XFS (dm-2): Unmount and run xfs_repair Sep 24 11:08:22 Atlas kernel: XFS (dm-2): First 128 bytes of corrupted metadata buffer: Sep 24 11:08:22 Atlas kernel: 00000000: 53 f8 8c c5 e2 3f 2c ba bf f3 6c 7f 50 4b 18 fa S....?,...l.PK.. Sep 24 11:08:22 Atlas kernel: 00000010: 4c c8 06 8d 5b b5 0a 13 f6 e4 57 9d 8e e1 b0 86 L...[.....W..... Sep 24 11:08:22 Atlas kernel: 00000020: d9 7e 70 f0 75 a8 8e 17 da b5 51 3a 59 31 38 f9 .~p.u.....Q:Y18. Sep 24 11:08:22 Atlas kernel: 00000030: 2d 20 3f ef 04 d2 89 e5 57 67 5b 9d 6c 92 e7 72 - ?.....Wg[.l..r Sep 24 11:08:22 Atlas kernel: 00000040: 3f 73 f8 9b b4 50 6e ae 74 11 01 27 40 76 3b 38 ?s...Pn.t..'@v;8 Sep 24 11:08:22 Atlas kernel: 00000050: ec 89 37 25 9d 42 11 e3 d3 28 2c 93 a8 e6 5c df ..7%.B...(,...\. Sep 24 11:08:22 Atlas kernel: 00000060: 01 77 8e a9 22 e2 bf 8b 6b 03 f2 c4 ce 23 3f 1e .w.."...k....#?. Sep 24 11:08:22 Atlas kernel: 00000070: ab 06 41 e8 81 d0 07 47 7f 3b ec 97 ba 47 f9 df ..A....G.;...G.. Sep 24 11:08:22 Atlas kernel: XFS (dm-2): metadata I/O error in "xfs_imap_to_bp+0x5c/0xa2 [xfs]" at daddr 0x1796d41c8 len 32 error 117 atlas-diagnostics-20210924-1308.zip
-
How would you go about testing the disks? Thanks for your help by the way.
-
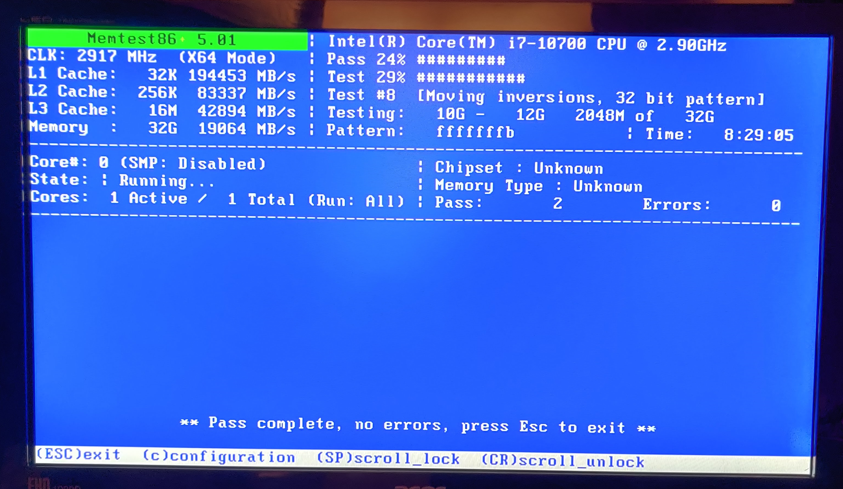
Ran a memtest overnight and did not return any errors. I went ahea d and order some lsi 9201-16e replacement cards.
-
I performed a "New Config" and parity was rebuilt. I then ran a non correcting parity check and it returned errors. I ran a 2nd non correcting parity check and it also returned errors. I've attached the latest diagnostics. Could the lsi 9201-16e cards have gone bad? They are about the only things left that I haven't replaced besides the hard drives and power supply. atlas-diagnostics-20210922-0759.zip
-
atlas-diagnostics-20210919-1551.zipAttached is the latest diagnostics.
-
I have replaced the sata and power connection and now disk ST4000DM000-1F2168_Z304M0WL is now showing up in Unassigned Devices. I then assigned disk 10 to ST4000DM000-1F2168_Z304M0WL and get a warning that the disk data will be erased when the array is started. I'm assuming instead of doing this, I need to do a "New Config" and recreate the parity drives. I'm just not sure what the exact options I need to select on "New Config". Also, will my other settings like Shares, dockers, and VM will still be there or will I really need to start from scratch?
-
disk10 became disabled during the the latest parity check. After building the new computer, I reattached the 6 External Mini SAS cables to the DAS and on boot-up, 4 of the hard drives were not recognized. I unplugged and re-plugged the 6 External Mini SAS cables and on next boot-up all drives were recognized. I then ran the latest parity check. I suspect there's something going on with the SAS connection. I will check all connections and reboot to see if disk10 comes back.
-
In order to fix disk10, would I replace it with another drive and let unRaid rebuild the new drive? How would the previous parity check sync errors affect this rebuild? Is it possible that the new disk10 rebuild will contain bad data?
-
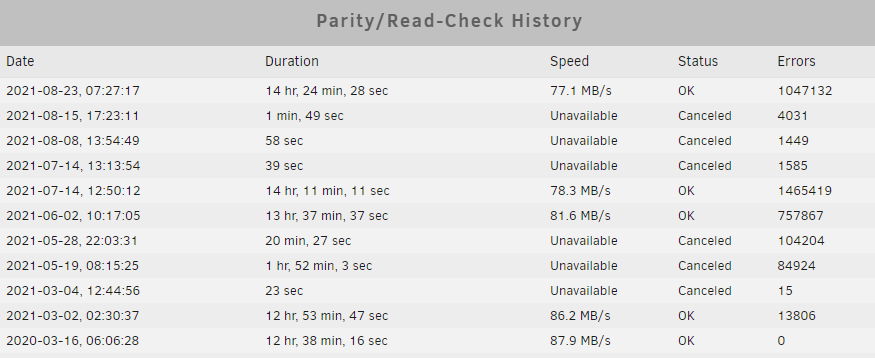
I'm trying to figure what is causing the following parity check errors on my server. So far I have replaced the motherboard, cpu, memory, and psu hoping this would solve the issue. I wanted to upgrades the cpu anyways. This was before the 8/23/2021 parity check but I'm still getting errors. I'm currently running another parity check but sync errors are still coming up. I have not replaced the hard drives, 2 LSI SAS9201-16e cards, 6 External Mini SAS cables, and a DIY DAS made up of 3 Dual Mini SAS SFF-8088 to SAS36P SFF-8087 Adapter and 6 Mini SAS 26Pin (SFF-8088) Male to 4 SATA 7Pin Female Cable. Any ideas on where I should look next? atlas-diagnostics-20210823-0831.zip
-
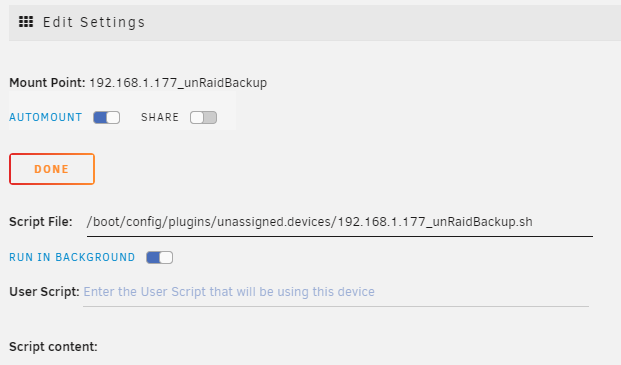
With the recent changes, my remote SMB shares are no longer automounting. I clicked the edit settings icon and then toggle AUTOMOUNT to on. This didn't automount the SMB share after a reboot. I tried adding a new SMB share with automount turned on but that didn't automount after a reboot. I can manually mount the SMB shares. I also notice that if I place my mouse over the settings icon, it correctly displays that the AUTOMOUNT toggle is on. But the SHARE toggle is incorrectly displayed as on. ajax-diagnostics-20210106-0925.zip

-
I'm getting the following error after this morning's update. Any ideas? Jackett v0.17.159 : Option 'ProxyConnection' is unknown. Edit: I see in the release notes for this release that the argument was removed. edce56f36311767f9bff3f1944ea1f0d929ab0e0 core: remove unused cli argument -j (ProxyConnection). resolves #9467 (#10608) Should I removed this argument from the docker run command and put the proxy configuration in the web gui? Will this work the same way?

-
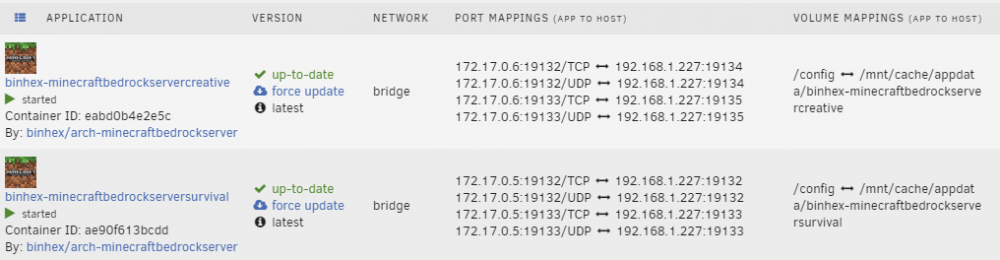
I'm trying to set up both a survival and creative server dockers. I'm able to get into the Survival docker at port 19132 on Android and iOS. My issue is that I can't get into the Creative docker at port 19134 on either Android or iOS. Do see anything wrong with my port mappings?
-
Thanks, that did the trick.
-
bwssytems is recommending to run the webui on port 80 due to some recent changes to Amazon echo devices. I run the following command: root@localhost:# /usr/local/emhttp/plugins/dynamix.docker.manager/scripts/docker run -d --name='habridge' --net='br0' --ip='192.168.1.7' -e TZ="America/Chicago" -e HOST_OS="Unraid" -e 'TCP_PORT_8080'='80' -e 'TCP_PORT_50000'='50000' -e 'SEC_KEY'='Gh#12uis' -e 'PUID'='99' -e 'PGID'='100' -v '/mnt/user/appdata/habridge':'/config':'rw' 'linuxserver/habridge' 1cd31ce78e11edbac7164b5fc9d41154c71deb2842bf26682966600958e2e3e5 But the webui is still running on port 8080. Any ideas on how to fix? Thanks.

-
My solution was to select the 5.14 tag which contains Mono 5.14. Movies are now successfully moved to a SMB share.

-
I believe this is the issue with using a SMB share. Will have to figure out a way to downgrade Mono in the docker. https://www.reddit.com/r/radarr/comments/cikhkw/strange_incomplete_moving_of_files_all_of_a/
-
As a test, I changed the path "/movies" from a SMB share to a user share in the radarr docker. Everything is now working again. I'll leave it like this and manually move the files over to the SMB share until I can figure out what was going on with the previous error.
-
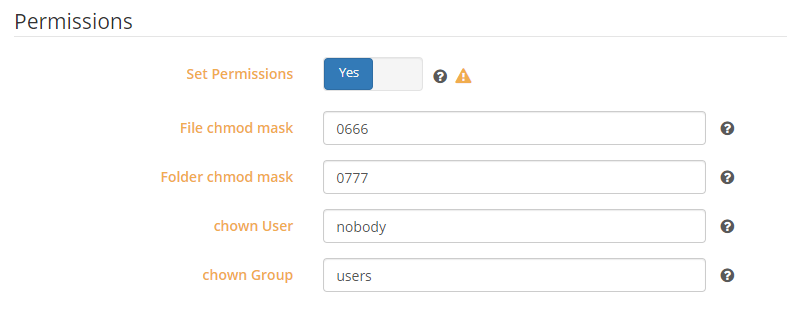
I have been using the following permissions setting in linuxserver/sonarr and linuxserver/radarr and everything has been working fine for some time now. After an automated docker update a couple of days ago, I am now getting the following error in radarr: Unable to apply permissions to: /movies/XXXXX: Error setting file permissions: EPERM NzbDrone.Mono.Disk.LinuxPermissionsException: Error setting file permissions: EPERM at NzbDrone.Mono.Disk.DiskProvider.SetPermissions (System.String path, System.String mask) [0x0003e] in C:\projects\radarr-usby1\src\NzbDrone.Mono\Disk\DiskProvider.cs:125 at NzbDrone.Mono.Disk.DiskProvider.SetPermissions (System.String path, System.String mask, System.String user, System.String group) [0x00000] in C:\projects\radarr-usby1\src\NzbDrone.Mono\Disk\DiskProvider.cs:74 at NzbDrone.Core.MediaFiles.MediaFileAttributeService.SetMonoPermissions (System.String path, System.String permissions) [0x0000f] in C:\projects\radarr-usby1\src\NzbDrone.Core\MediaFiles\MediaFileAttributeService.cs:88 From what I can tell, sonarr works fine because it's saving to a user share. radarr is setup to save to a SMB share (another unRaid server) with the RW/Slave option. I've changed from nobody / users to 99 / 100 in the radarr settings but still get the same error. Eventually the Unassigned Devices plugin will hang. I believe this is caused by radarr repeatedly attempting to save to the SMB share. Any dockers using the Unassigned Devices smb shares also hang and I have to then do a hard reset on the unraid machine. Both unRaid is 6.7.2 and all dockers/plugins are updated to the latest. Any ideas as why this happening?
-
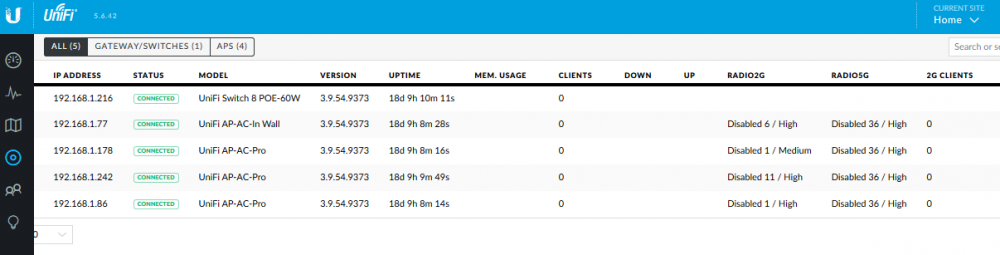
The solution for me was to switch from LTS to 5.9 and then restore from my 5.6.40 backup. I can now see all my clients.