



.jpg.5ae2f92187bdbff1d7c0edfb6f4d26ca.jpg)
heffe2001
Members
-
Joined
-
In the past when I've tried to just re-add a drive back in that had been triggered bad, I'd had to wipe it to get it to accept it again. What would be the procedure to NOT have to do that in this instance? Drop the disk from the array, add it back and then rebuild, or will it allow me to do that? In the past when I've had drives drop due to issues like this, I've usually precleared it again just to make sure the smart attributes and all hadn't been incremented or anything like that, but in this instance, I know EXACTLY what happened, lol. Went ahead and dropped it from the array, started, stopped, added it back, and now it's rebuilding. Like I said, I've always run the clear again in the past to 'test' the drive, but I don't think it's necessary in this case.
-
I have a few empty drive sleds in a Compellant SC200, and went to pull one to zero out a 6tb SAS drive. I didn't pay close enough attention, and pulled an active drive in the array (the light on that sled is extremely dim, not bright like the rest), and the drive entered an error state (not for any write errors, but 1 read error). Upon reboot, it's got he drive marked as bad, and being emulated, even though it's not ACTUALLY bad. What's the best way to handle this and get the drive back into the array? Pull it, reboot, then reinstall and run a preclear is the process I've run in the past, or would I just be better off dropping the parity drive, readding it, and just rebuilding parity? I'm 99.999% certain there's no data errors (mover wasn't running, and I don't have any processes that write directly to the array disks). Either way I'm going to have to preclear and I'm guessing either way is going to require one a drive rebuild, but parity is larger (10tb), where this was an 8tb, so it'd (i'm guessing) be faster to go that route. Just wondering what other folks process for bone-head moves like this, lol.
-
The larger drive size was reported on 6.12.1, and reported correctly on the older 6.11.5 version. Both drives passed preclear this last attempt (the one running the preclear docker went through all the steps, except on the post-read, it got to 63% before the docker process hung, but it still passed the drive anyway). The one difference on the 6.11.5 VM preclear, the output during the operations looked very different from the normal preclear on the self-updating status screen. I'm wondering if that has something to do as to how Proxmox passed that drive through to the VM though. I took that drive, put it in my main unraid box, and it verified the preclear signature, so it appears it did at least complete correctly (I've verified both drives at this point, both got valid signatures). I also had already done a media validation on both drives before this last preclear operation doing a format and DD passes by hand, so I'm pretty confident that the drives are fully functional. I'm currently rebuilding my array with one of them replacing a very old 4tb drive, and as soon as that's done, I plan on replacing another with the 2nd drive. I NEED to replace a pre-fail ST8000AS0002 (slowly starting to get correctable media errors), but apparently the HGST 8tb I got, plus the EROS drive format out to just a touch smaller than the AS0002, so they won't work for that.. I'm debating just dropping parity, moving the data from that drive by hand to the new drives, and having the system completely rebuild parity again (I'd split the data from that failing 8tb over to the excess new free space on those replaced 4tb's if I do that). It's either that, or start looking into larger sas drives (my parity is currently only a 10gb drive, so might just grab a couple 10tb sas models and throw them in the mix, lol). Not sure if you've noticed or not though, several posts above yours DLandon says he's having an issue with larger drives and read failures, but that the preclear docker works on those issue-causing drives (it's using the older preclear script I believe), so if you're just wanting to get them all cleared and set up, that would probably be a good way to go to get around the issue with the current preclear plugin script issues.
-
I'm seeing a very similar problem using the plugin version of the preclear script on 2 8tb SAS drives I got last week. Both get to near the end of the zero phase, hang, and keep restarting until failure (I got the same restart at 0% on I think the 3rd retry attempt). I installed the preclear docker image to test the original preclear script on my server (running 6.12.1 at the moment), and the first drive I tried has so far completed all the zeroing process with the preclear script that's included with the docker version, and is in the final read phase on the drive. This was with 2 different manufacturers (one HGST, one Seagate Exos, both 8tb). The Seagate ran through the zero process 3 total attempts, with 3 retries per attempt, and failed every time, the HGST failed a 3 retry pass before I started it using the docker. I've currently got the Exos drive running a preclear on a virgin 6.11.5 install with just the preclear & UD plugins installed as a VM on my Proxmox server, with the drive passed through to that VM, and it's SO FAR at 83% and still going (VERY slowly, it's at I think 38 hrs on JUST the zero phase, lol, getting I think about 54m/s zero rate). I'll let it go until it either completes, or fails on the zero, and move it back into my primary rig if it passes, and try it under the docker image too. I DO notice that the Exos drive was shown as having a reported size of 8001563222016 total on the preclear plugin version n 6.12.1, where under 6.11.5 it's showing 7865536647168, so I'm not sure where, exactly it was getting the larger size from.. Same controller in both machines, only difference is it's being passed through to the VM directly, and not directly on bare metal. As far as the HGST drive being in the final step (final read), I changed NOTHING on the server or plugins, just installed the plugin docker image (reports Docker 1.22), and started it using that instead of the canned preclear script with it's defaults..
-
I had the same issue, and if I remember correctly, I had to move some directories/folders around in the data folder. It was either that, or the actual mount point. On mine, it was looking for another directory inside the data folder, THEN the blocklists under that. I'd assumed it was because I was coming from another person's technitium app, and not something with the official one though. Below is my directory structure under the appdata/ts-dnsserver directory. My definition for the data directory on the docker page: If that doesn't work, look at how the permissions are set. I'm now getting the issue where it tells me version information is 'Not Available' since I switched over to the official. I can force-update it, but it never shows that there's an actual update available or that I'm 'Up To Date'. No biggie I guess, since I was coming from a version that was WAY behind the actual releases (6.x I think).
-
It ended up failing again after 3 reboots. Those lines aren't in my syslinux.cfg. It's definitely not my usb keys (I've tried many, and even bought new Samsung brand keys).
-
Just wanted to add that this doesn't just apply to Dell servers, I've been having issues booting my flash on my HP DL380p Gen8 machine for months, to the point I changed out all my usb keys, and have to do all updates by hand (and attempt to boot them a dozen times or more till it just happens to work). Added the lines above to my syslinux.cfg file, and it boots every time. As long as updates don't rewrite the syslinux.cfg, it should survive updates now too (haven't been able to do an automatic update since the 6.10.x series started in RC...).
-
Just a FYI, 2020.05.27a took care of my issue, details are shown now with no issues.
-
Yep, sure do. I'm currently a version behind latest, waiting to update after everyone here goes to bed, lol. I've verified that I do have director information on my movies, so not sure why it's getting an error on that line. Updated this morning to the latest Plex Pass version, and still the same.
-
Still not able to get any detailed info on any show that comes up, gives me the same error still as posted above.
-
When I click on detail, I'm getting the following error on every movie I've tested: Warning: Invalid argument supplied for foreach() in /usr/local/emhttp/plugins/plexstreams/movieDetails.php on line 63 Year: Rating:
-
Seems everything survived through 2 reboots (for other reasons), so it would appear it was that dynamix plugin causing the issue.. On another note, would it be possible to add an option to hide passed-thru drives?
-
After removing that dynamix SCSI devices plugin I get the desired results.. SO if anybody is having the issue of SAS drives (or raid containers) not showing up on UD, and have that dynamix plugin installed (and aren't using a Areca controller), try removing it and see if it helps.
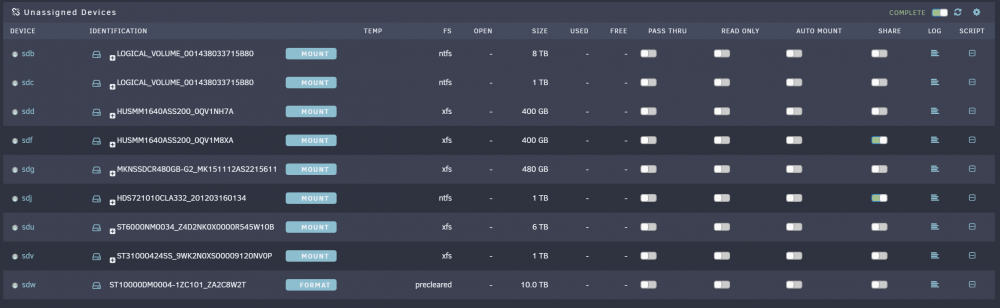
-
With Preclear removed it still shows the same (none of the SCSI- drives are listed). I'll look at the ST6000, it's not been used and I honestly can't even remember buying it let alone installing it, lol. I do have the dynamix SCSI Devices plugin installed from when I had an Areca controller in the machine (long since removed). I wonder if that's got anything to do with the issues? I may try uninstalling it soon as my docker restore is done and restarting the machine to see if it makes any difference.

-
Those would be the ones. The've been giving those 2 warnings since installation, but have worked without issue up to now (and still seem to work ok when I manually mount them). UD won't actually see any of the scsi- devices (I have a couple raid arrays set up on a hp 420 controller that I use directly mapped to a windows VM, but it didn't see them before I mapped them either). Looks like it's basically not finding a grown defect list by that 'error': 0x1C 0x02 GROWN DEFECT LIST NOT FOUND It's not seeing any of these devices: scsi-HUSMM1640ASS200_0QV1M8XA@ scsi-LOGICAL_VOLUME_001438033715B80-part1@ scsi-ST31000424SS_9WK2N0XS00009120NV0P-part1@ scsi-HUSMM1640ASS200_0QV1M8XA-part1@ scsi-LOGICAL_VOLUME_001438033715B80-part2@ scsi-ST6000NM0034_Z4D2NK0X0000R545W10B@ scsi-HUSMM1640ASS200_0QV1NH7A@ scsi-LOGICAL_VOLUME_001438033715B80-part3@ scsi-ST6000NM0034_Z4D2NK0X0000R545W10B-part1@ scsi-HUSMM1640ASS200_0QV1NH7A-part1@ scsi-LOGICAL_VOLUME_001438033715B80-part4@ scsi-LOGICAL_VOLUME_001438033715B80@ scsi-ST31000424SS_9WK2N0XS00009120NV0P@ I'd forgotten about even putting that ST6000 in there at all, since neither the system nor the UD detected it, lol.
.thumb.jpg.3a77b2fd7693ae4dd1dce532b1a29e70.jpg)

