




thespooler
Members
-
Joined
-
Last visited
-
The previous advice doesn't work for me as the docker user created doesn't have access to the /root/ folders it defaults to putting appdata in. The Docker can start now, but it's not writing to appdata, but inside the docker volume. I modified the template as follows in advanced mode by adding three environment variables and removing one. Web UI: 6806 Container Port: 6806 Workspace Mount: /mnt/user/appdata/siyuan Container Path: /siyuan/workspace/ Location on Unraid for data Workspace Path: /siyuan/workspace/ Container Variable: SIYUAN_WORKSPACE_PATH Name of the workspace mount Auth Code: Container Variable: SIYUAN_ACCESS_AUTH_CODE Password (optional) Disable Auth Code: True Container Variable: SIYUAN_ACCESS_AUTH_CODE_BYPASS
-
That's the problem with manual intervention. When the docker recreates, it will be lost. You could probably take advantage of the linuxserver.io base to installed that for you. I had to do that once to customize something. Regardless, I don't know what the benefits of 1.9.x are, but I'm happy to wait for the repo fix. I'm pretty sure it was the latest as it updates every Friday, and I found it dead on Saturday still requiring libatomic.
-
I came here also looking for the answer. In the mean time, rolling back will fix it: Edit the docker repository from 1activegeek/airconnect:latest to 1activegeek/airconnect:1.8.3
-
Was wanting to benchmark a NVME plugged into a USB3 enclosure to see if it was faster than my current cache drive, but still no option to do so. If you're worried about USB lowering the results, just give them a checkbox they need to click so they're aware of the interface potentially being a limiting factor.
-
This docker is old and big. I think I got this from a CA recommendation, but honestly no real privacy concerns so just use the original website: https://explainshell.com/ SpaceInvaderOne's own docker script shows: 2640MB - spaceinvaderone/explainshell 0B (virtual 2.64GB) Is being taken up by spaceinvaderone/explainshell ID 5301fcd9bc0a1b719303ad302fe1a4e520e526e95812a565ec9609e95da73ffd This volume connected to explainshell has a size of 643M And then there is this Yarn package manager cache directory... root@445a674973fb:/usr/local/share/.cache/yarn# du -hx -d1 233M ./v1
-
I had a hard lock a couple of days ago. Had to restart with the power button. Minor changes of the array can happen at night from Sonarr, otherwise everything stays on the cache. It came back up and it started a parity check. I cancelled it as the end of the month is near and I decided it was time to address my macvlan problems as reported by Fix Common Problems and upgrade at the same time. I think I was 6.12.8, now 6.12.13. 1 day later, power outage! I believe anyways as my desktop was restarted with no apps loaded. Unraid seemed okay since that hard lock, but of course it started another parity check with I guess automatic correction. How does one tell this? Noticed all of these P corrected errors in the logs by fluke. There are no notifications for these?!? Seems kind of important if you're running a correcting check, at least on the first one. I have this line in the Main tab parity area: "Sync errors corrected: 6000". Does the wording change based on the checked flag? Seems like there should be an easier way to know if you're correcting parity or not. Just found it is indicated in syslog if you know what to look for. Unraid has decided to stop logging these corrections all together. They ones reported appear to be sequential, but now I'm unsure if it's stopped reporting all corrections to save the logs or if it's smart enough to report the next non sequential error. In otherwords I can't assess how much damage is done, if any. Is there a drive issue or just power dropping before parity calculations. Since the parity check is now paused and the lack of log report, I can't tell if the corrections are ongoing or not. I have over 6000 corrections so far. Sounds terrible, but if it's 6000*512 byte sector size, then I guess that could be a single file mover was moving at the time? Due to the power outage the next day, my log is slim. I only see an error about some slow ata8. Which seems to be /sdi from poking around the logs. But not sure what to make of that. I guess I can assume this was a one off related to the hang and not a drive issue? And the correct course of action is to resume the check, and see if the monthly check in 1 day finds 0 errors? Thanks tera-diagnostics-20240929-1428.zip
-
1. Add a new share 2. Select the 'Read settings from ' option from the upper right and pick an existing share 3. 'Include Drives' and 'Exclude Drives' drop downs disappear (In Brave anyways) 4. If you click on 'Help', it completely covers the drive boxes 4. 'Reset' at the bottom and just set it up manually to continue
-
I just installed my first docker with this, and while trying to edit stack - > compose file, after hitting save, I've lost all the UI buttons at the bottom and the UI is now inserted into the edit description area. It seems rather permanent, leaving the Docker page and coming back does not fix it. UPDATE: I was able to Edit the description to just be My Description and brought everything back. I swear it had HTML in that field to begin with as I thought that was odd and I guess I removed the textarea closing tag. Raw html in a field is usually a security no-no for this very reason of modifying beyond the intent. IMGUR
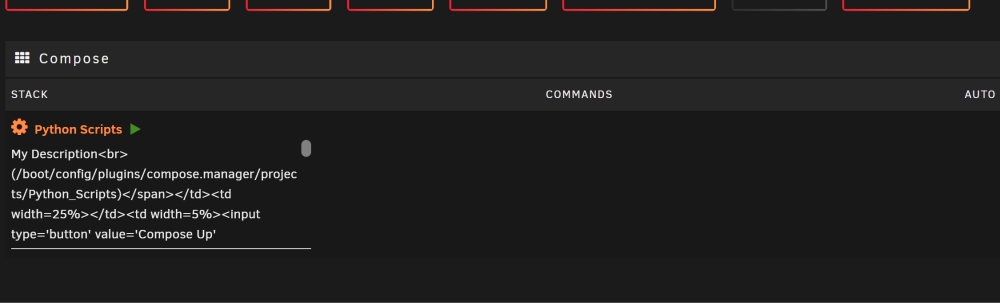
-
I managed to get it to run by only providing a filename in the DB_FILEPATH variable. Knowing the database wouldn't survive an update, I just wanted to take it for spin. The docker user is not 'nobody', so there's going to be permission issues with appdata. Best solution for me was to just switch to the linuxserver.io container and everything worked flawlessly.
-
Lost all my shows to a bug in 0.8. 0.8.1 is out now. How soon does the docker get updated? I see the last build was manual.
-
I acknowledge this isn't so much of a bug, but it cost me 20 minutes of resorting all of my dockers. Clicking anything in a table header should not be destructive. The icon looks just like the icon generally used to change the table display from icons, grids, details, etc. I clicked it before the tool tip showed up because again, clicking anything in the header should not be destructive, it just effects the sorting order. Since there is already a row of buttons below the dockers, it should be included down there as a "Reset Starting Order" button.
-
My post is only one page back... Give it a try.
-
"Do not overlap with autoupdate" What does this line mean? The plugin is called Auto Update, the tabs say Auto Update, so what does autoupdate refer to? Is there some unraid setting I'm not aware of? If this is suggesting don't configure Plugin and Docker auto update frequency at the same time, does that mean they both can't run daily for example? Or in fact, they can both be set to Daily, just at different times, in which case, wouldn't the message be more informative if displayed under the scheduled time? Perhaps "Do no overlap with plugin schedule" would be more clear?
-
PROBLEMS: Black screen Stuck on Apple logo Can't reach recovery servers / no network I followed the video EXACTLY and I hit all of these issues one after another. I went back 10 pages and see these issues showing up repeatedly. The solution to all 3 of these, is to skip ahead in the video to the 14 minute mark and add your server name to the script. Run the script a second time and now you jump back to the 8:50 mark and install for the first time. I don't know why this issue is plaguing so many of us first time installers. Of course, you'll still end up with Catalina until that's fixed. I was going to update the ID for Big Sur and start over, but decided that xcode 12 still runs under Catalina, so I'll try that first. I'm just curious how responsive it is compared to my older Macbook Pro. But man, for a walk through video this has now taken me 6 hours from start to where I am now which is just installing the OS. The walkthrough video needs a walkthrough video.
-
This was a surprisingly easy Docker to set up! And to think I avoided it for so long... Incase anyone else is using Caddy v2 for their reverse proxy, or I suffer a huge failure one day: Modify /config/config.php as follows (for completeness, I know this is repeated over and over in this forum): 'trusted_domains' => array ( 0 => 'unraid_IP:unraid_PORT', 1 => 'cloud.your_Domain.your_TLD', ), 'trusted_proxies' => array('unraid_IP'), 'forwarded_for_headers' => array('HTTP_X_FORWARDED_FOR'), 'overwritehost' => 'cloud.your_Domain.your_TLD', 'overwriteprotocol' => 'https', 'overwrite.cli.url' => 'https://cloud.your_Domain.your_TLD', And in your caddyfile: cloud.your_Domain.your_TLD { reverse_proxy https://unraid_IP:unraid_PORT { transport http { tls_insecure_skip_verify } } encode gzip tls [email protected] { } header { # don't advertise "Caddy" as server -Server # docker ngix server contains all the necessary security headers already - instant A+ at https://scan.nextcloud.com/ Strict-Transport-Security "max-age=31536000; includeSubDomains;" } }

