




SelfSD
Members
-
Joined
-
Last visited
Everything posted by SelfSD
-
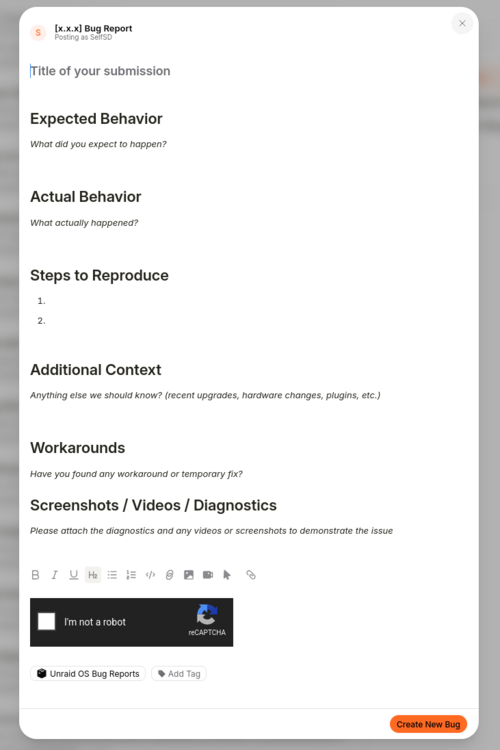
Strange... I don't see those field at all. I have now tried it on Firefox, Chrome and a fresh install of Chromium and it doesn't show up on any browser. Happens on 2 PCs as well as my phone which I tested on my local network and mobile internet 😵💫
-
Attached submission form of what I see on my end.
-
Hi! I'm trying to post a 7.3.0 bug report on the bug report forum but it gives me an error "Unraid Version field is mandatory". I've tried to add the Unraid version in the title with no luck. I've also selected the Unraid version in the tags with no luck. Where is the version field supposed to be at?
-
It's working again for me as well. I also found the CrashPlan status page. Looks like they've had an issue for over a week. https://status.crashplan.com/
-
@watevriwanabi Same here. Both my instances has been unable to connect for 2 days.
-
I'm currently stuck on this issue as well. I've only tried 4 different endpoints so far, rebooting my server, pulling different versions of the container, reinstalling the container and reading up and down the forum and FAQ with no luck. Deleting the OpenVPN folder when on Wireguard didn't help on my end and switching temporarily to OpenVPN also didn't help. I don't actively watch the container so I can't say how long it's been dead either. Last time I interacted with it was 5 days ago. Update: It started working again, so maybe the issue was on PIA's side.
-
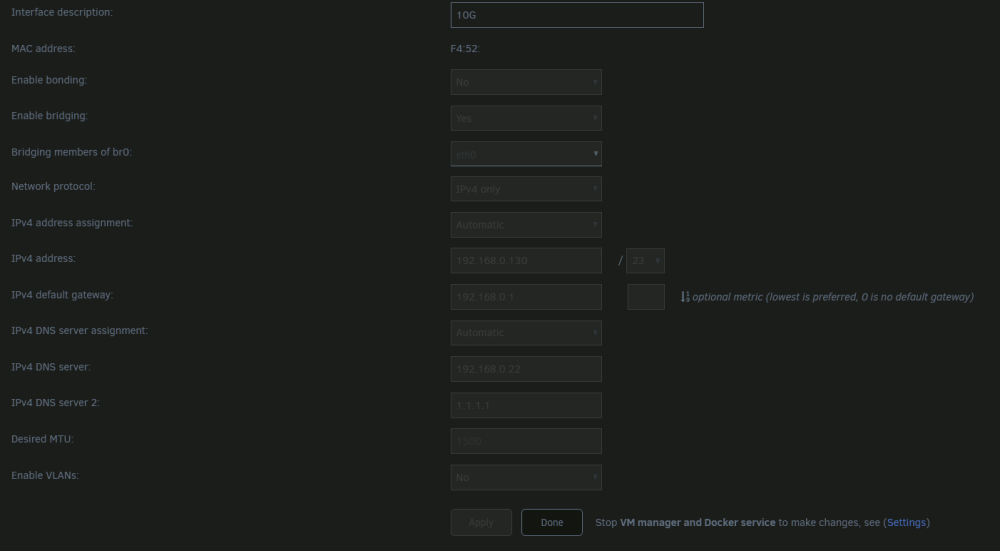
I ended up changing the IP address of the backup Pihole to the primary for now until I get my second server up and running. Still odd that Unraid doesn't apply both DNS servers to the configuration file from DHCP.
-
Another update. I unplugged and reconnected my server to see if it would update the DNS servers with my backup Pihole. Curiously enough, it only added the first DNS server to resolv.conf and not both even though .22 and .23 are both in the GUI as IPv4 DNS servers. resolv.conf is as follows: # Generated by dhcpcd from br0.dhcp domain KTS20 nameserver 192.168.0.22 It lost the second DNS server At least now I know how to manually add the second DNS server, so thank you @ljm42 for the link! The log says the following: Mar 19 13:32:07 UnRaid kernel: mlx4_en: eth0: Link Down Mar 19 13:32:07 UnRaid kernel: br0: port 1(eth0) entered disabled state Mar 19 13:32:27 UnRaid avahi-dnsconfd[18816]: DNS Server 192.168.0.22 removed (interface: 7.IPv4) Mar 19 13:32:27 UnRaid dnsmasq[19036]: no servers found in /etc/resolv.conf, will retry Mar 19 13:32:27 UnRaid dnsmasq[19036]: reading /etc/resolv.conf Mar 19 13:32:27 UnRaid dnsmasq[19036]: using nameserver 192.168.0.22#53 Mar 19 13:32:43 UnRaid kernel: mlx4_en: eth0: Link Up Mar 19 13:32:43 UnRaid kernel: br0: port 1(eth0) entered blocking state Mar 19 13:32:43 UnRaid kernel: br0: port 1(eth0) entered forwarding state Mar 19 13:34:16 UnRaid avahi-dnsconfd[18816]: New DNS Server 192.168.0.22 (interface: 7.IPv4) Mar 19 13:34:16 UnRaid dnsmasq[19036]: no servers found in /etc/resolv.conf, will retry Mar 19 13:34:16 UnRaid dnsmasq[19036]: reading /etc/resolv.conf Mar 19 13:34:16 UnRaid dnsmasq[19036]: using nameserver 192.168.0.22#53
-
After I used nano to see if the /etc/resolv.conf file had any config in it, saving out of habit without modifying anything and closing it, my server does now reach out to the secondary DNS server. Although each request takes about 5 seconds as I'm guessing it's trying to use the primary each time and timing out it works for now. The server log added this so maybe it just needed a refresher: Mar 19 13:10:51 UnRaid dnsmasq[19036]: reading /etc/resolv.conf Mar 19 13:10:51 UnRaid dnsmasq[19036]: using nameserver 192.168.0.22#53 Mar 19 13:10:51 UnRaid dnsmasq[19036]: using nameserver 192.168.0.23#53
-
Like I wrote in the initial post, my Pihole is down and all my other devices are currently using 1.1.1.1 without issues. Only my Unraid is not using the secondary DNS server for some reason. Virtual machines are using DNS 2 and docker containers are still running fine so I assume they are also doing so. It's just the host struggling. ☹️
-
It's all through DHCP.
-
Hey guys! So my second Unraid server that runs Pihole has a dead motherboard and I figured it's time to set up a backup Pihole instead of using a public DNS service as backup. However at the moment my second DNS server is 1.1.1.1 and Unraid won't use it at all even when the primary DNS server is down. Server was rebooted not too long ago as I thought that would fix it but no luck. Is this a bug in Unraid or do I have to configure something more than just have 2 DNS servers specified? unraid-diagnostics-20230318-2257.zip
-
Hi @KluthR! I just updated to your version and found a small bug. With multiple archives enabled, pressing "Abort" in the UI only stops the current archive being made and it continues to the next one. I started the backup to see if everything was working and had to adjust something I forgot to change so I wanted to stop it. I had to press abort 5 times to cancel the whole backup process 😅
-
That's a good question... The only thing I managed to find about it is this article which didn't really help: My maintenance license is expiring within a month so I guess I'll find out after that once the docker gets an update.
-
Just updated both my servers! About to try out ipvlan on my problematic server to see if it will be more stable.
-
I gave up all those tools. Goodsync had the same limit. I ended up on Bvckup 2 which has no issues maxing out the network.
-
Same happened here. I was woken up by emails saying my NVMEs were overheating. Having automatic file management enabled had moved almost everything over to the config/qBittorent/downloads folder in appdata for the past 7 hours. For anyone else who may have to google how to downgrade their docker container; edit the container and change "Repository" to "binhex/arch-qbittorrentvpn:4.3.9-2-01" without the quotes.
-
I ended up changing the paths after the new update. It was a breeze to change and resync the backup storage path and the remote share was automatically re-detected as a remote mount point. 👍
-
I'll go this route if it breaks on the next update again. Thank you.
-
Really? Crap. Maybe I should go over all my docker containers. I have modified the defaults on more of them and never paid any attention to it as they continue to work...
-
It appears that the "Storage" path has been added a second time without any interaction from me. I don't know how that could happen unless updating a container can re-add modified default maps? I changed the default Storage mount from /mnt/remotes on the host to /storage/remotes/ in the container to better fit my needs, and the new one is set up with the buttons always hidden, mounting /mnt/user to /storage on the container. Removing the new storage path fixed it. Thank you.
-
Hi! My CloudBerry container won't start anymore. I haven't paid much attention to it as it's only doing non-critical backups at the moment so I'm guessing it happened after the update 11 days ago. I have it set to mount Unassigned Devices' "/mnt/remotes" folder which worked before. It has been mounted as Read Only Slave but I tried to set it to Read/Write Slave as well but no change. When I start the container, I get the following error: Dec 4 12:53:06 UNAS rc.docker: CloudBerryBackup: Error response from daemon: OCI runtime create failed: container_linux.go:367: starting container process caused: process_linux.go:495: container init caused: rootfs_linux.go:60: mounting "/mnt/remotes" to rootfs at "/var/lib/docker/btrfs/subvolumes/83f665b66417da7f5de3b2ce1cd4e0d64408e0fab3599b35a844ef1990e0f344/storage/remotes" caused: mkdir /var/lib/docker/btrfs/subvolumes/83f665b66417da7f5de3b2ce1cd4e0d64408e0fab3599b35a844ef1990e0f344/storage/remotes: read-only file system: unknown
-
In the share setting (has to be set for each share) change "Case-sensitive names" to Yes.
-
After converting the pool to raid1 and restarting the array, the device delete was successful! Everything is running smoothly. Diagnostics attached. unas-diagnostics-20210819-1215.zip
-
I'm in the process of changing a raid1c3 pool to a 2 disk raid1 pool without balancing to raid1 beforehand and Unraid was unable to delete the missing device. There were no warning given that the devise delete was unsuccessful. The only log entry about it is "Aug 19 07:35:14 UNAS emhttpd: shcmd (851638): /sbin/btrfs device delete missing /mnt/pool_name &" When attempting to do it manually, I got the following error: "error removing device 'missing': unable to go below three devices on raid1c3". Is there any way for Unraid to monitor the output of the btrfs command in case it fails? Diagnostics will be attached soon.




