




BigChris
Members
-
Joined
-
Last visited
Everything posted by BigChris
-
Hast du die Leistungsaufnahme bei dir gemessen?
-
Ich habe in meinem alten Dell T30 eine Xeon E3 1275 V5 CPU, mit 32GB ram, ene Nvme, eine SSD und 3 HDD im 24 Stunden durchschnitt 26W. Idle ca 22, wobei der nie wirklich im Idle ist wegen ioBroker.
-
Es soll ein neuer Unraid-Server aufgesetzt werden. Der alte soll in Betrieb bleiben, bis der neue läuft. Dazu ist eine Testversion auf dem Stick USB-neu. Wenn ich fertig bin, wie ziehe ich die Lizenz um? Aus dem Ordner /config einfach die .key Datei auf den neuen Stick kopieren?
-
Ich denke von den kodinerds. Oder yavdr, aber das ist länger her
-
Wie planst du denn die 3 nvme einzubinden? Die beiden 4TB im Array? Die mitgelieferte als Cache?
-
Das mache ich auch. Ich sichere intern jede Nacht mit dem backitup Adapter von iobroker. Wahrscheinlich kann ich das bei appdata einfach aussparen. Sonst gefällt mir das schon richtig gut!
-
Das ist ein bisschen eine Philosophiefrage. Einmal habe ich Angst, dass beim Neustart was hängt. Das hängt mit Sicherheit damit zusammen, dass für mich Docker immer noch nicht so ganz greifbar ist. Dann haut es mir immer in die Logs rein, bis alles gestartet ist kommen ja doch schon einige Einträge. Wahrscheinlich ist es aber völlig egal und das ist nur meine Unsicherheit. Bisher läuft es ja wirklich gut mit den Dockern und unraid!
-
Ich habe mich auch erst mal für den Docker entschieden. Ich bin mir nir noch nicht sicher, ob es mit gefällt das der für ein appdata backup gestoppt wird jede Nacht
-
@Curiosity Es ist eine Weile her, dass ich aufgesetzt habe und dazu noch unter Proxmox Ich bin gerade dabei alles zu unraid umzuziehen und habe das jetzt mal vorgezogen um zu schauen was los ist. Das erste: Ja, Calibre-Web kann offensichtlich keine Datenbank anlegen - mann muss ihm eine geben. Das hast du gemacht? Wie schaut es denn bei dir aus, wenn du nun auf books gehst auf der linken Seite, ist die Datenbank leer? Dir fehlt wahrscheinlich noch die Konfiguration für den Upload-Button. Geh oben rechts auf Admin Dann auf Konfiguaration -> Basiskonfiguration Dort machst du "Feature-Konfiguration" auf und setzt den Haken bei Hochladen aktivieren ganz unten auf speichern drücken. Dann solltest du jetzt oben rechts neben deinem Namen einen Upload Button haben. Eine Anleitung hätte ich auch nicht, wir fuchsen uns da schon rein
-
Ich würde empfehlen eine eigene Redis Instanz aufzusetzen. Wenn du mal einen redis verlierst, warum auch immer, funktionieren die anderen dienste noch. Ich lege mir dafür jeweils für die hauptanwendung ein eigenes dockernetz an, so dass sich redis und paperless ohne switch etc. direkt unterhalten können. Und du musst keine ports nach aussen legen, paperless hat dann exklusiv zugriff auf redis. Das halte ich für performant und sicher.
-
Ich nutze Calibre-Web bei mir.
-
Beim IoBroker musste ich ab und auch mal eine andere Version vom JS-Controller oder so was übergangsweise einspielen. Geht das beim Docker auch? Ich bin mit Docker noch nicht so vertraut und finde die Möglichkeiten immer sehr beschränkt
-
Guten Tag, ich wollte einmal fragen ob es Erfahrungen hier gibt mit dem Betrieb von IoBroker unter Unraid. Ich würde den gerne von meinem Proxmox zu Unraid verlagern, da ich Proxmox abschalten möchte. Ich kann mir vorstellen, dass es bei einem System wie IoBroker Vorteile haben kann, mal was eigenes nach zu installieren oder anzupassen, was bei dem Docker vielleicht schwerer wird? Zigbee Sticks oder ähnliches müsste ich keine Durchreichen, ich habe netzwerkangeschlossene Koordinatoren. Wie sind Eure Erfahrungen?
-
Nein, da habe ich mich unglücklich ausgedrückt bzw. Informationen weggelassen. Ich habe das dockerthema in unraid nicht verstanden (backups, durchreichen von Geräten, was mache ich im Fehlerfall) und es hatte mich gestört das die Platten oft angelaufen sind. Dann habe ich mir einen Lenovo Tiny geholt und Proxmox getestet und mich auch ein bisschen darin verliebt. Und auf dem Proxmox läuft omv für unsere persönlichen Daten. Zu viele Systeme sind aber zu viel Pflegeaufwand, zumindestens für mich. Proxmox ist schon cool, was die HA angeht, aber ob ich das so brauche? Und das erkaufe ich mir mit der unflexibilität (in meinen Augen) was die Speicherweiterung HDD angeht. Daher ist nun die neue Überlegung, wieder alles zurück zum unraid zu ziehe un das verrückte hinbund her mounten zwischen den physischen Rechnern nicht mehr zu haben. OMV wird im dem Zuge deaktiviert. Ich würde erstmal mit 32GB durchstarten und schauen ob es nicht reicht. Da sind die Investitionskosten nicht gleich wieder so hoch.
-
Ja, es ist schwierig zur Zeit und tatsächlich recht teuer. Ich überlege auch, ob ich es erst mal versuche den Dell T30 mit mehr RAM auszurüsten und schauen ob der Xeon Xeon® Prozessor E3-1225 v3 das noch schaffen kann. Vom Strom her ist der ok, ich mache mir nur sorgen ob das gute Teil noch genug Performance hat.
-
Das würde dann bedeuten, evt. auf ein System mit DDR5 zu gehen? Ich habe mich lange nicht mit Hardware und Preisen beschäftigt muss ich gestehen.
-
Guten Morgen, bei mir ist so einiges gewachsen - teils aus unwissen, teils aus - ich weiß es auch nicht Ich überlege hier mal alles auf neue Hardware umzustellen nur noch einen (unraid)Server zu haben. Aktuell laufen bei mir folgende Rechner, Dienste: 1: Dell T30 mit Unraid und 3 x 6TB. Einsatz als NAS (Teilzeit) / Backuplösung. 2: Lenovo Tiny 720q. Mit 3 Festplatten jeweil 2TB drin. SSD und NVME. VMS paperless-ngx openmediavault (24/7 NAS) immich proxmox-backup-server LXC unifi-controller iobroker wikimedia nginxproxy calibre-web wireguard homepage 3: Lenovo Tiny 720q mit Frigate und Coral TPU und auch einer SSD als 24/7 Videoüberwachung mit 3 Kameras Die Landschaft würde ich also gerne auf einen Rechner umziehen. Das stelle ich aktuell mir so vor. Eine Cacheplatte (evt. einen Pool) 1TB Ein Array mit anfangs den 3 x 6TB Platten, der wahrscheinlich wachsen muss / wird. Um die "dicken" Platten nicht dauerhaft laufen zu lassen (Strombedarf) , die Videoüberwachung entweder im Cache abbilden oder als zusätzliche SSD einbinden? Die Trennung 3,5" HDD und SSD für 24/7 Anwendungen beschäftigen mich aktuell sehr. Wie mache ich das? Die SSD einfach in das Array hängen ist ja nicht so gut, wegen dem fehlenden Trim? Als Hardware würde ich an so was denken: Gigabyte B760M DS3H DDR4 Intel I3-12100 boxed 2 x 16GB RAM (oder mehr?) PSU 160W maximal 3 x 3,5" HDD mit dem Speicherplatz den ich dann benötige 2 x NVME (1TB oder 2 TB) (Cache) vielleicht noch eine SSD (24/7 Dienste?) Was denkt ihr drüber? Ein sinnvolles System was den Wildwuchs beseitigt? Passt die Hardware? Reicht ein I3? Ist es energetisch effizient? Was ist eigentlich mit den C-States und aktuellen Unraid-Versionen. Muss man basteln oder passt das? Wie trenne ich 24 Stunden Betrieb (Frigate) von den stromhungrigen 3,5" Platten? Oder sollte ich frigate lieber separat auf einem Tiny lassen? Vielleicht auch keine schlechte Idee. Achso, die Backups der wichtigen Daten wird dann entweder auf dem alten T30 gemacht oder einer externe Platte. Mal schauen. Und zusätzlich feuerfest auf der Arbeitsstelle gelagert. Ich bin über Anmerkungen / Kritik sehr dankbar! Grüße Christian
-
Good morning, I am experiencing a phenomenon. My hard drives are no longer displayed in Unraid. The shares are there and I can also view the data - that seems to work. Where has the display gone? fize-data-diagnostics-20250430-0739.zip
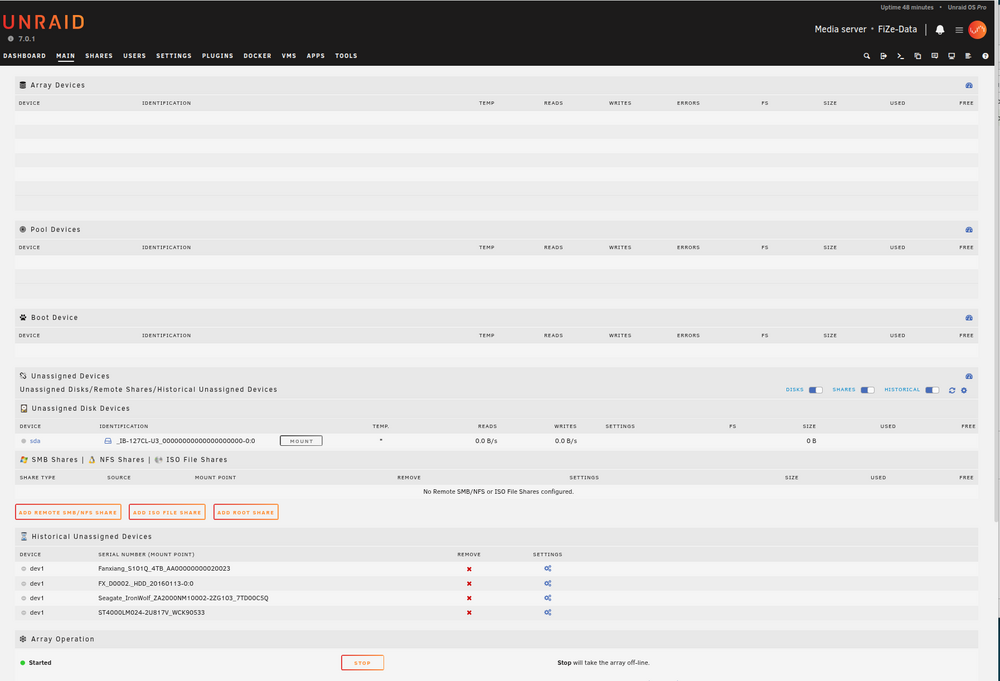
-
Jawohl. Der Fehler zieht mit.
-
Guten Morgen, ich habe ein Phänomen bei mir. Meine Festplatten werden mir nicht mehr angezeigt im Unraid. Die Shares sind da und die Daten kann ich mir auch anschauen - das scheint zu funktionieren. Wo ist die Anzeige hin? fize-data-diagnostics-20250430-0739.zip
-
Ich mache ziemlich lange meine monatlichen Backups, indem ich eine SSD Festplatte per USB an den unraid hänge. Ich kopieren dann in der Regel per MC die Daten stumpf auf das Laufwerk. In der Zwischenzeit kam der Wechsel auf Unraid 7.0.0. Nun habe ich langsame Schreibraten von vielleicht 16 - 22 MB/s und ich kann mir nicht helfen wo das herkommt. Die Platte war immer am gleichen USB Port. Ich habe heute: Die USB-Ports getauscht, die Festplatte getauscht, von 7.0.0 auf 7.0.1 geupdatet. Alles ohne Auswirkung. Es bleibt langsam. Nun schreibe ich aktuell per FTP ein Backup zu meinem Desktop, dass ist stabil mit knapp 110mb/s. Was ist da bei den USB los? System: Dell Poweredge T30 SSD: Seagte Ironwolf 2TB / fanxiang 4TB
-
Hm, ich verstehe es leider immer noch nicht. Also, die Maschinen sind zu dem Zeitpunkt des rsync beide online, das funktioniert zuverlässig. Ich komme nur nicht mehr beim unraid an den rsync. Wenn ich versuche das vom OMV aufzubauen, mit Passwort erhalte ich dies: Please wait, syncing </srv/dev-disk-by-uuid-bfe765fc-90f2-4315-9750-1d5468000bf9/christian/> to <[email protected]:/mnt/user/christian> ... Permission denied, please try again. Received disconnect from 10.10.10.200 port 22:2: Too many authentication failures Disconnected from 10.10.10.200 port 22 rsync: connection unexpectedly closed (0 bytes received so far) [sender] rsync error: unexplained error (code 255) at io.c(232) [sender=3.2.7] ERROR: The synchronisation failed. END OF LINE Ich kann mich aber mit ssh ohne Probleme einloggen. Ich verstehe nicht wo das Received disconnect from 10.10.10.200 port 22:2: Too many authentication failures Disconnected from 10.10.10.200 port 22 herkommt oder wie ich das abstellen kann.
-
Nein, das ist vom Unraid Log. Ich komme auch absolut nicht weiter leider. Vielleicht mounte ich den Unraid Share kurz rein und versuche dann den rsync. Die Maschinen laufen aus Energiegründen nicht dauerhaft durch, da war die Lösung vorher einfacher umzusetzen.
-
Ich habe die Anfrage neuim Supportthread zum rsync docker gestellt. Das hier kann dann eigentlich geschlossen werden.
-
Ich schreibe es hier noch mal rein. Seit Unraid 7 kann ich den rsync Server nicht mehr nutzen. Ich habe noch mal neue Schlüssel generiert, wie es bei dem Docker steht mit: ssh-keygen -t rsa -b 4096 Dann habe ich den Schlüssel in dem Dockercontainer eingepflegt und den Container gestartet. Vom Clientsystem versuche ich dann rsync --dry-run --itemize-changes --archive -e 'ssh -p 5533' [email protected]:/mnt/user/system/ /tmp Und erhalte als Antwort: [email protected]: Permission denied (publickey,keyboard-interactive). rsync: connection unexpectedly closed (0 bytes received so far) [Receiver] rsync error: unexplained error (code 255) at io.c(232) [Receiver=3.2.7] root@openmediavault:~#


