
realies
-
Posts
174 -
Joined
-
Last visited
-
Days Won
1
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by realies
-
@cen you might have swapped the container/host ports. https://docs.docker.com/config/containers/container-networking/ Also, the folder mapping seems wrong. Please refer to the README.
-
@cen, are you sure you are trying to access the container at the configured port?
-
Upon a manual stop/start, the disks had lost their assignments. This is the second time disk assignments have been lost due to a hang. The hardware is: AMD Ryzen 1700 @ 3.8GHz AsRock X370 Taichi Crucial 4 x 16GB ECC @ 2400MHz NVIDIA GeForce GTX 1050 Ti AMD Radeon RX 580 Kingston SV300 120GB Samsung 850 EVO 500GB Samsung 960 PRO 512GB 32TB Mixed Drive Array Corsair HX1000i Fractal Design Define R5 The RX 580 and NVME drive are assigned to the Windows 10 VM, could the AMD card be related?
-
@iilied, you might want to reduce the auto-save period to a lower value than the default 60 to make Soulseek save its config. @ridge, just pushed an new build allowing for correct ownership using the pgid/puid environment variable pattern. Volume mount mapping and File Sharing settings within Soulseek need to be updated.
-
@limetech any plans for something like this to be implemented?
-
@jonathanm, apologies for using the wrong unRAID terminology and flooding the topic unnecessarily. At the bottom of my last post there's also: Updating all posts accordingly.
-
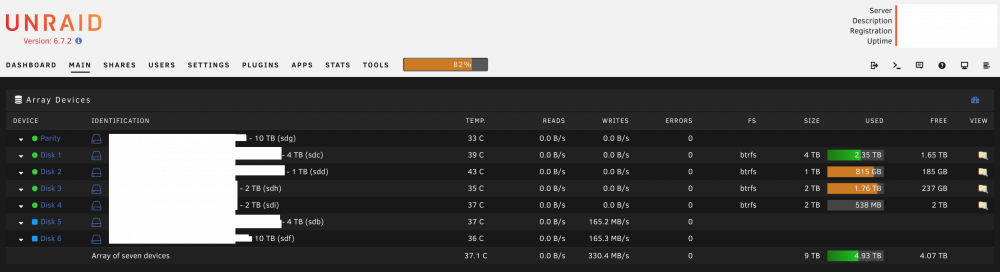
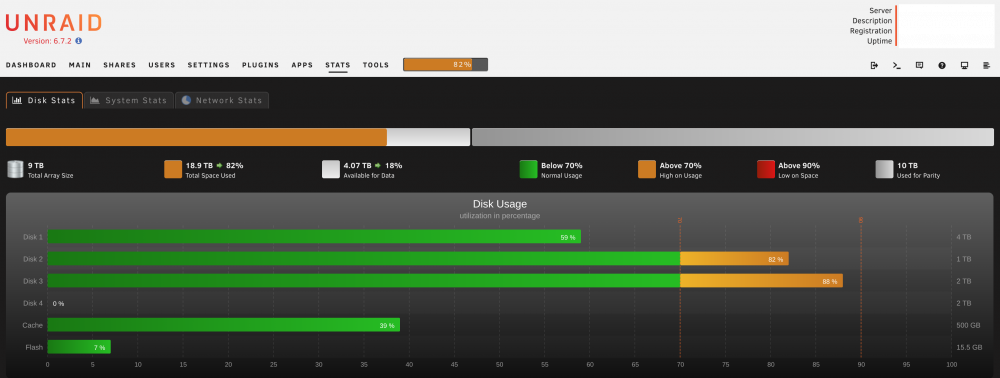
Thanks for pointing out the correct unRAID terminology. I have not used 82% of the available space and it is impossible to use 18.9 TB of a 9 TB total array size. Before adding the new drives the total space used percentage was at 55%, when the new drives were added it jumped to 82% during the clearing stage.

-
@Benson, nice generalisation, although for this use case it would be great if disks are pre-cleared at maximum speed. It would stress each drive to its full potential and maximise the chance of reporting early drive mortality that can happen during this stage. @BRiT, the writes are fluctuating up and down and during the clearing stage when new drives are added to the array, nothing is being written to the parity drive (0.0 B/s). @itimpi, absolutely sure I mean pre-clearing*. This occurs automatically when a new drive is added to the disk array. Another thing that can be observed is that drives that have underwent the clearing step are still waiting for the remaining new drives to finish clearing before they are mounted to the array (Disk 5). In my view drives that have successfully been pre-cleared have to be mounted to the array without waiting for remaining drives to complete. *seems like people refer to pre-clearing when the drive is cleared before being assigned to the array, so in unRAID terms, I mean clearing

-
Just added two new drives, one of them is 5400rpm and the other 7200rpm. Noticed that the clearing write speed fluctuates identically between the new drives (±0.5 MB/s). Wondering if this is a bug, a feature or just the current state of the clearing component. Is it not possible to max out the write speed of each drive independently?

-
Disk array size and free size calculation seems to be wrong during the pre-clearing of new drives in the array.
-
Not sure what do you mean with the hub, but the PSU has to be connected to the system via USB in some way.
-
@LintHart, generally all PSUs that work with Corsair Link should work with this plugin as long as their hardware ID is added to the supported devices.
-
Win10 VM graphics pass-through broke after AMD BIOS update
realies replied to mattz's topic in VM Engine (KVM)
Can confirm that using the CLI tool I have reverted the bios on Asrock Taichi X370 back to 5.10 successfully. Don't think many of the comments about flashing new bios via bare metal Windows is not safe because the tool prepares the bios for flashing within Windows and upon restart the bios if validated and flashed via a component from the existing bios. -
Win10 VM graphics pass-through broke after AMD BIOS update
realies replied to mattz's topic in VM Engine (KVM)
This does not work for Asrock x370 Taichi that is at BIOS 5.50 when trying to downgrade to 5.10.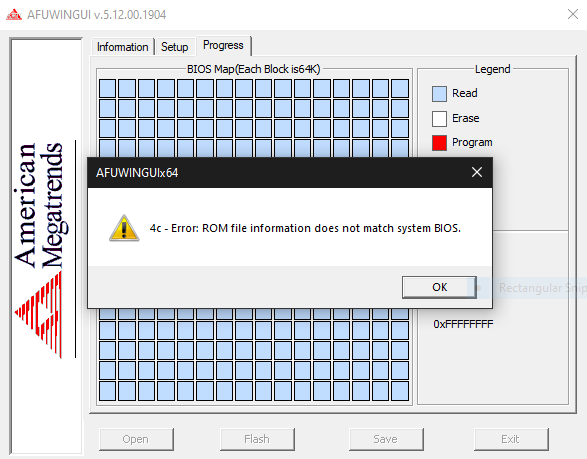
-
I was only able to downgrade from 5.60 to 5.50 on X370 Taichi (https://www.asrock.com/mb/AMD/X370 Taichi/index.asp#BIOS) and it did not change the situation. Downgrading to a lower BIOS version is not possible and is described here https://forum.level1techs.com/t/attention-amd-vfio-users-do-not-update-your-bios/142685 @limetech is it possible that the next version of unRAID has the patch mentioned in the topic above? The diff can be seen here https://clbin.com/VCiYJ. According to the users from the L1 forums, this is a fully working fix. Any tips on applying this before a new unRAID release ware welcomed.
-
While 'btrfs restore -v /dev/sdX1 /mnt/disk2/restore' managed to recover most of the data, it seems 'btrfs check --repair /dev/sdX1' managed to restore everything. Yet to validate for any data corruption, so far it looks all good. Many thanks @johnnie.black!
-
@limetech can you please have a look? I have seen the same error (device [1022:1453] error status/mask=00200000/04400000) being reported by other users in the forum and this article states that downgrading the kernel makes everything work fine - https://www.micropissed.com/2018/05/amd-vi-completion-wait-loop-timed-out Will attempt downgrading the BIOS in case the newest one broke something.
-
Can't get this GPU to work with a Windows 10 VM. Using X370 Taichi with the latest 5.60 BIOS. The VM is set to use Q35 3.1. After a boot attempt unRAID can't be stopped or restarted via the usual ways and a hard restart or shutdown is necessary. PCI-stubbing and ACS override modes don't change the situation. Any suggestions on a fix? Libvirt logs Kernel logs:
-
Stopping the array, un-assigning the failed disk and starting the array a few times made unRAID think that re-assinging the same disk is a replacement disk... 🤦
-
Sounds like the data is lost. Is 'btrfs restore' the only hope? Why is the emulated disk not showing the missing data? Is parity corrupted, e.g. two device corruption?
-
Is it worth recovering the failed disk filesystem instead of wiping the drive and restoring the data via parity? Or because the filesystem is corrupted parity is also corrupted?
-
Only shares from the failed disk are not visible which makes me think the filesystem is not corrupted. I remember that i have killed wget that was downloading virtio iso drivers and that caused cd /mnt/user to return 'Transport endpoint is not connected'. Rebooting the system made everything work, but later the disk wget was downloading the virtio drivers died. Getting other suggestions from the #btrfs channel that it could also be a kernel bug considering the above.
-
Sounds like recovery is not as straight forward as replacing the drive with a new one and rebuilding it from parity.
-
Good to know, will convert them to DUP once everything becomes operational. Is it normal that 'data is emulated' and not visible? Can't see any shares or data that was on the problematic drive.
-
I've also got these suggestions, which I am not sure would interfere with what unRAID expects, @limetech might have an idea?






