




fr05ty
Members
-
Joined
-
Last visited
-
@khaneliman thanks for this, just setup a win11 pc and couldn't figure out where I was going wrong
-
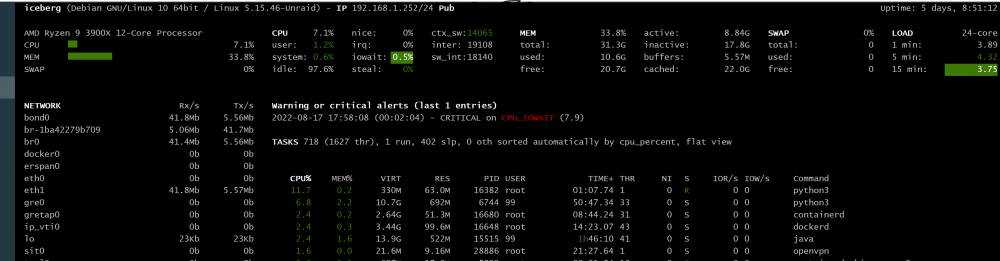
thanks for having a look, that error block was right after I installed netdata and it started up, I have export on the flash drive and just browsed to \flash in windows and it shows the plugin folder, to check the usb is there any particular program to use, I have a win and a linux pc if you have a fav program I don't think the system would be to busy its a 3900x and most of the time sits at around 5-10% usage and looking at glances iowait is around 1-5%

-
hello all hopefully someone much smarter than me can tell me why I'm getting this error in my syslogs and if there is a way to fix it unassigned.devices: Warning: shell_exec(/usr/bin/cat /proc/mounts | awk '{print $1 ',' $2}') took longer than 1s! been having a few random lockup lately trying to narrow down causes iceberg-diagnostics-20220816-1456.zip
-
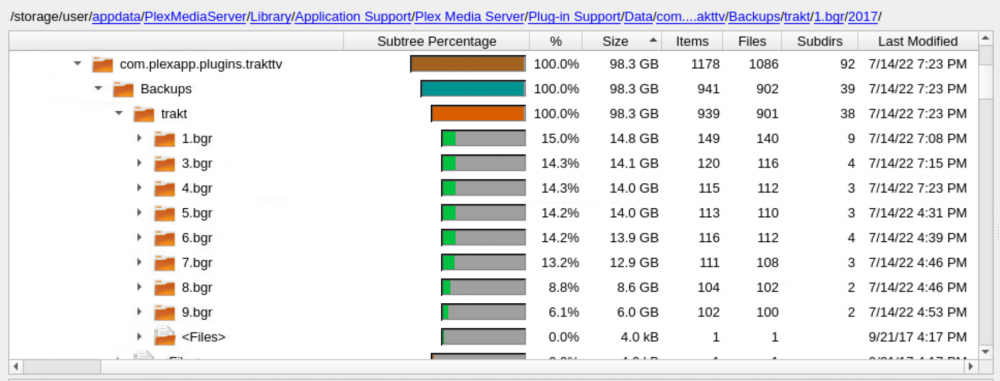
I have been using plex with the trakt tv plugin for the longest time and never knew why my appdata backups were taking 2Hrs to complete so i installed the QDirStat docker and let it scan all my appdata folders and found mnt/user/appdata/PlexMediaServer/Library/Application Support/Plex Media Server/Plug-in Support/Data/com.plexapp.plugins.trakttv/Backups was nearly 100GB am i safe to delete this dir and let it start fresh. I have just added it to my excluded folders for back ups and will let it do a backup tomorrow so i know how much time i will save not backing it up
-
@neow scroll back to page 11 for screen fix info and you may need to change your network adapter to 'e1000-82545em' to get appleid working
-
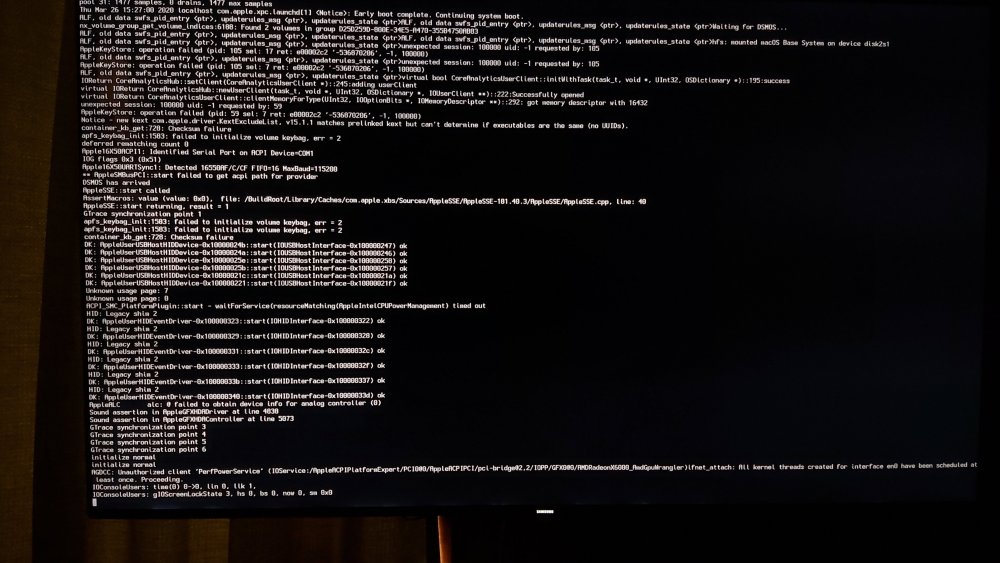
@Leoyzen Sorry I got distracted last night was going to post a pic of the -v , but I will have a look tonight at the log method you suggested, where will I find the log after I try to boot?
-
@Leoyzen i added the agdpmod=pikera and the AppleMCEReporterDisabler.kext and changed id to iMacPro1,1 but i still get stuck with the loading bar half way, in the vm logs i see this: 2020-03-25T07:33:28.814709Z qemu-system-x86_64: vfio: Unable to power on device, stuck in D3 2020-03-25T07:33:28.820691Z qemu-system-x86_64: vfio: Unable to power on device, stuck in D3
-
hello i have a 5700xt that i would like to pass through to Mac Catalina i have setup macinabox and the vnc works but when i tried to pass through my gfx card it gets to the apple logo the loading bar gets halfway and stops, i have dl'd WG/LILU latest versions and added them to the K/O dir, do i have to add some other boot args to get it working/loading the 5700xt if i change the id to iMacPro1,1 I would also have to add AppleMCEReporterDisabler.kext if i have read this sub correct i also came across an opencore page that says to add agdpmod=pikera for a navi 10 cards is this added in the Clover Configurator somewhere?
-
i know when i had the error 43 i had to change my bios booting the unraid usb from the "uefi: sandisk" to just "sandisk" and the just reinstall the drivers again
-
nothing was being used at the time i had my game pc turned off only my phone and lounge pc turned on (osx) then stopped the container changed my router primary dns to pi-hole ip the unraid scrub had returned to normal speeds and if i started SCB again the speed of the scrub dropped again, i used "docker exec -it SteamCacheBundle tail -f /data/logs/access.log" this to check the logs and there was no activity and the memory usage was sitting at about 80MB not 1.8GB, like when i had SCB set as my primary dns
-
i have noticed a problem with my SteamCacheBundle on the first of every month i start a scrub on unraid and today it was running at 40-60MB/s per drive usually its around 145MB/s i only found it was this docker by shutting them all down 1x1 and when i had them all running and just shutting down SCB everything was running fine, i changed the docker tab to advanced view and noticed that the memory usage was also high and it kept grown in size by about a MB every second it was open, it was running for maybe half hour and was up near 2gb
-
I was having an issue with the code 43 i tried the hyper-visor on/off didn't make a difference, but i did read on a reddit post to check to see if the unraid OS boot usb was booting in uefi mode in the motherboard bios if so change to legacy mode or equivalent and that fixed my problem, card is all passed through now just had to do a driver reinstall edit: unraid OS boot usb




