



(Small).png.20e01e54adf9a0993af949e43e312763.png)
CorneliousJD
Members
-
Joined
-
Last visited
Everything posted by CorneliousJD
-
Makes sense, I figured it would be something like that, but it asked that I post the message here so I looked first and nobody else had, didn't want to ignore the message haha. Thanks Squid!
-
When trying to install Hastebin I get the following. Something really wrong went on during createXML Post the ENTIRE contents of this message in the Community Applications Support Thread <br /> <b>Warning</b>: explode() expects parameter 2 to be string, array given in <b>/usr/local/emhttp/plugins/community.applications/include/exec.php</b> on line <b>1582</b><br /> <br /> <b>Warning</b>: array_filter() expects parameter 1 to be array, null given in <b>/usr/local/emhttp/plugins/community.applications/include/exec.php</b> on line <b>1582</b><br /> <br /> <b>Warning</b>: array_values() expects parameter 1 to be array, null given in <b>/usr/local/emhttp/plugins/community.applications/include/exec.php</b> on line <b>1582</b><br /> {"status":"ok","cache":null}
-
No problem! Same thing got me too a while ago
-
I'm mobile, but *instance* start and *application* start are different. Be sure inside the instance it's set to start the application under config and then I think amp core? Otherwise it will start the instance but not the actual minecraft (or game) server.
-
I'd also suggest just picking a different user and pass too and see if that works if Mitchs suggestion above doesn't.
-
Thanks for posting this. I had always had mine setup when I was doing testing as a public URL that I had Photoview up on for testing reasons and it was loading fine!
-
Interesting, I had that issue for a while but didn't for too long. If your library is huge it might take hours to fill out. But if you have a small collection it shouldn't take but a few minutes to start showing up. This is the official docker container so it may be worth reaching out to them on their GitHub page if it doesn't show up in a few hours time? Sorry I can't be of more help directly, I didn't make the program or container, just the template.
-
Check your appdata photoview folder. Is it actually rendering thumbnails there for you?
-
I successfully tested with Maria DB and used the example string in the template. user:pass@tcp(IP:PORT)/database For example, if your unRAID IP address is 192.168.1.100 and your MariaDB or MySQL container running on unRAID is on port 3306 And you have a user of "photouser" with a pass of "photopass" and a database name of "photoview" then you would enter the following. photouser:photopass@tcp(192.168.1.100:3306)/photoview
-
Awesome, thanks for the update. I'm glad to hear you have everything working! I didn't create the container, just brought it into unRAID as a template so it's easily find-able on CA!
-
@enriquezandrew92 I saw you psoted here and then it looks like it was deleted. Sorry you're having issues, I'm not sure what to suggest at this point, I have the docker up and working flalessly since day one with this - since your post is deleted I can't look into anything on it at this point but when I have more free time I can try to take a deeper look.
-
Container requires a MySQL (MariaDB) database in order to function! Photoview is a simple and user-friendly photo gallery that can easily be installed on personal servers. It's made for photographers and aims to provide an easy and fast way to navigate directories, with thousands of high resolution photos. If you have questions regarding setup or development, feel free to join the Discord server: https://discord.gg/jQ392948u9 Demo site Visit https://photos.qpqp.dk/ Username: demo Password: demo More info here: https://github.com/photoview/photoview
-
Here's my setup screenshots, hope it helps! AMP/Configuration/Networking Valheim Instance Ports Then in Valheim instance, configuration, server, you can set your wold name, seed, and password (must have password from everything I'm reading i think?) Then forward ports 2456-2458 *UDP* through your firewall, or to test locally just connect to your unraid IP running AMP on port 2457 (the actual port it uses to connect). e.g. 192.168.1.100:2457
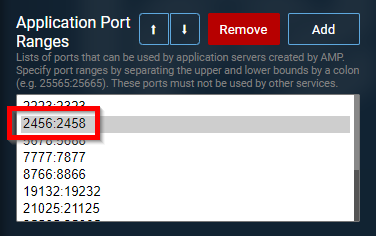
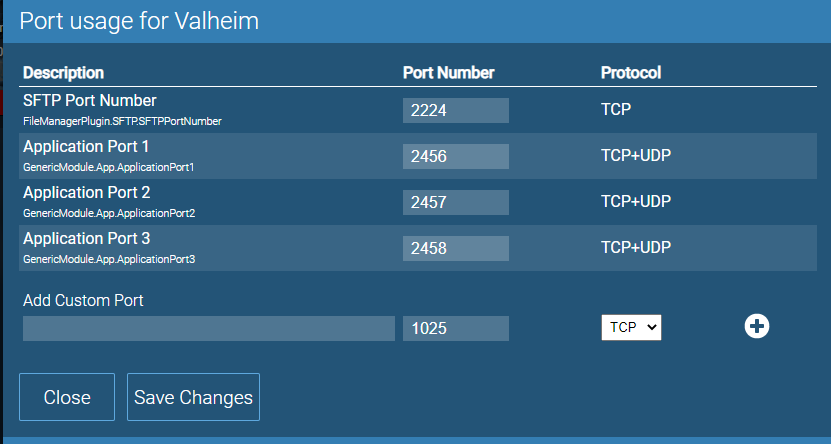
-
This container allows you to have a working Joplin desktop app, reachable via a http noVNC that can be placed behind a reverse proxy. More information about the noVNC baseimage here : https://github.com/jlesage/docker-baseimage-gui More info about Joplin : https://joplinapp.org/ This can also be used with the JoplinServer container as well to have a full Joplin stack runnin on unRAID. NOTE: If you're going to put this behind a reverse proxy be sure to either use the VNC password that you can set in the template or provide your own means of access control via proxy.
-
If anyone is interested, I have Valheim running on this without issues as of now.
-
yep, that static MAC is definately needed otherwise when the conatiner is restarted or updated it will get a new MAC address and thus need the license keys again. That should fix it moving forward though, happy to help!
-
Do you have a static MAC address set? What error with the auth URL are you receiving?
-
Brand new Valheim install here, not having any luck... Added --dns=8.8.8.8 already to extra paramaters but making no difference. Tried validate=true as well but still looping over and over. not sure what's going on. Is there other logs you need to see in order to be able to help? Thanks in advance! Valheim.log.txt It just keeps looping every minute or two from here.
-
I don't know the actual answer here, but until then you can just run two instances of the same container, it's super lightweight.
-
Try doing the force update, if it's not pulling any actual update then it's possible that your feature request was closed as it was added/working in DEV but hasn't been actually combined with the master branch yet, meaning you may need to wait a bit longer until the developer of Recipes actually pushes it to part of his master branch of code.
-
Ideally you should be using CA's Auto Update on a schedule, but if you do not want to do that you can just check for updates or force an update from the docker page. Turn on advanced in the top right of hte docker page and then you can force an update for any container you'd like.
-
This container is the HealthChecks dashboard which needs your *view only* API key. Instructions for use should be inside the tempalte itself as follows. If you've ended up here I assume you need more assistance. This is what you need to look for. The line you're looking for to edit looks like this. You should be able to change it to something like the following.
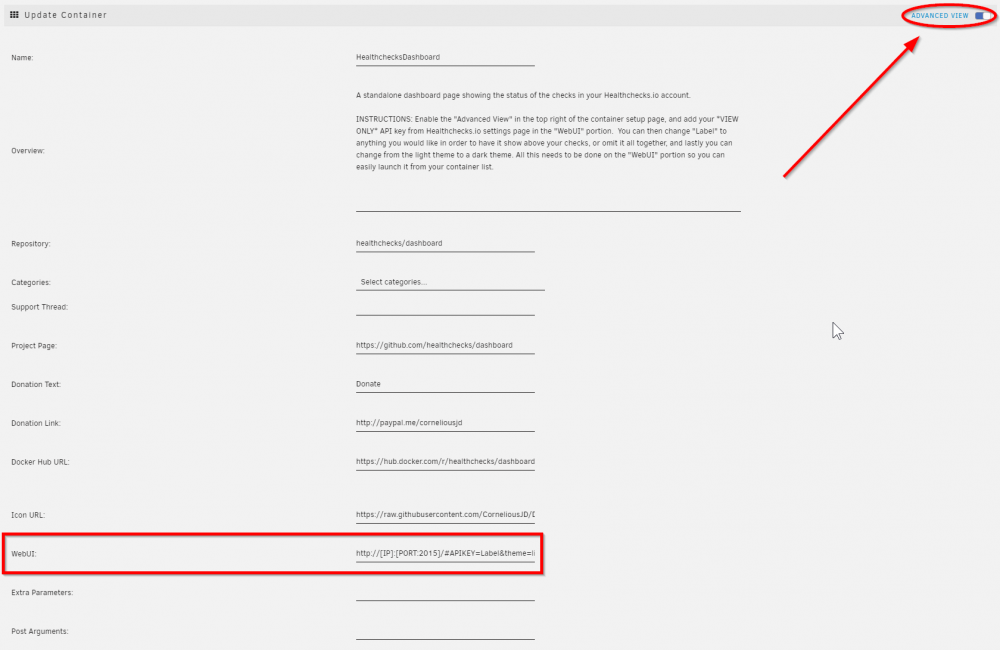
-
The one running br0 should have all ports open to it since you don't have to actually pass any through, does that one still not show up unelss you manually add it in Minecraft? Mitch is saying that bridge networking in docker will at least for sure not allow multicast packets to flow, so you would need to use host networking. I THINK br0 would work simlarly to host networking, which allows any ports requested to flow through to the assigned IP?
-
IIRC Minecraft will bind to an interface and use multicast on that to be discoverable, so this might not be making it out of hte container, or might be bound to the wrong interface? I'm not sure off hand, @MitchTalmadge might know more on this specific aspect. Although, since your unRAID server presumably has a static IP address, you could have people on your LAN just add the server once and have it saved/bookmarked anyways, not exactly what you're looking for but way back when I used to hose MC worlds that's what we all did over WAN and on the LAN regardless.
-
This should be possible. I don't think it *broadcasts* out but as long as the ports are open the clients should scan the network and find it?
(Small).thumb.png.b884b0484e848c502a315fc27b995f59.png)




