




jsebright
Members
-
Joined
-
Last visited
Everything posted by jsebright
-
Sorry, that's something that took me a while to get right, and I couldn't see what was wrong with it. I'd suggest you try to revert to defaults and as simple as possible. Check the drive paths are mapping to where they should be. Can't offer any more help as I don't know enough...
-
@localh0rst I had the internal server error. Logged into the docker and ran "flax init" that seemed to start it for me. May or may not work for you...
-
Ah yes. Why didn't I think of that? Has the advantage that it doesn't get killed if the docker restarts. Watching a few together in just one window is pretty good though, and a bit less to keep track of.
-
Nice. Haven't seen that before. I couldn't seem to open two windows of the unraid docker console, but I did find I could just use the command watch -n10 du -sh /plotting /plotting2 and it watches both folders in one window.
-
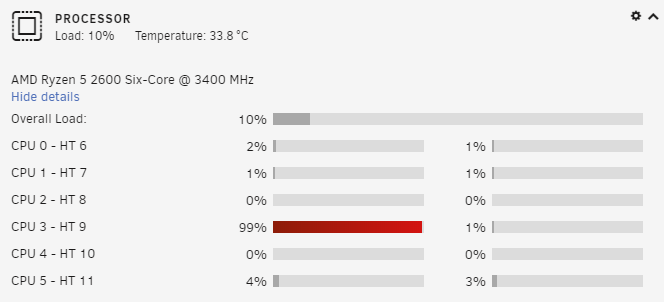
Thanks for your reply. Seems like the runs are crashing sometimes. The tempdirs have files from different runs leftover in them. I've just checked my config against the wiki sample (was doing that as I saw your previous post). I've got max jobs set to 1, but had the staggers set differently - might have been causing the issue. I've got the threads set to 4 - I've only got 5 pairs of cores available (Ryzen 2600 with a pair pinned in case a VM wants a look-in) and it does tend to run them at about 90%. Perhaps this needs taking down from the default? - I'll see how it goes with the default stagger options before reducing it. Thanks again for everything your doing with this.
-
It also took me some time to get MadMax plotting to work. I also think there's an issue that it's not clearing temp folders up. I've got two ssds that I'm using and have one of them as the primary temp, and one as tmp2. They are slowly filling up until plotting stops. After it's all ground to a halt - see plotting and plotting2 : root@Tower:/# df -h Filesystem Size Used Avail Use% Mounted on /dev/nvme0n1p1 932G 673G 259G 73% / tmpfs 64M 0 64M 0% /dev tmpfs 32G 0 32G 0% /sys/fs/cgroup shm 64M 60K 64M 1% /dev/shm shfs 3.7T 893G 2.8T 24% /plots /dev/sde1 447G 313G 135G 70% /plotting /dev/nvme0n1p1 932G 673G 259G 73% /id_rsa /dev/sdf1 447G 447G 24K 100% /plotting2 /dev/sdb1 7.3T 7.2T 153G 98% /plots2 /dev/sdc1 7.3T 7.2T 153G 98% /plots3 tmpfs 32G 0 32G 0% /proc/acpi tmpfs 32G 0 32G 0% /sys/firmware I'm having to stop plotting, clear the files, and start it off again. Don't know if this is a MadMax or Machinaris issue. @guy.davis ?? This is still faster than the chia plotter, I don't have much diskspace left...
-
Just did a "check for updates" and it's available. Just waiting for some plots to finish. Looking forward to the latest version.
-
What's the best way to upgrade the unraid docker if it doesn't show "upgrade available". Will an edit of the settings pull the new images? PS: many thanks to @guy.davis for making and supporting this. Good luck with your farming.
-
Thanks for your reply. I think I'll leave it as is, though I might see if I can restrict it to a single disk and move other shares to other drives. Although perhaps I'm trying to be too neat with it. Beats the pain of trying to copy the files to another disk (which seemed problematic when I tried it briefly).
-
I really like what it's doing, having de-duped backups of a number of systems is great. Thanks @binhex for building and maintaining this docker. Now, a few questions... I am noticing that when a backup is running (full image backup in this case) that urbackup maxes out one cpu core. It alternates every minute or so which one it is, but it 's unusual in doing this. Also, I initially allocated a single disk for backups, outside of the array. Then I thought I might run out of space, so set it to be inside the array instead (avoiding cache). Due to the number of links (I believe) if I run "Compute All" on the shares then the size of the urbackup share can't be calculated. Would I be better off putting this back onto a dedicated disk instead, and is there a good way to move the backups or do I have to start over again?
-
As soon as I visit Settings > CPU Pinning I get the banner with the title "CPU Isolation: A reboot is required to apply changes" The banner persists even though I make no changes. It shows itself when logging into the dashboard on another browser. It clears when the server is rebooted. I'm not expecting this banner to show unless I make changes to the "CPU Isolation" section. I should be able to make and apply VM or docker pinning changes without a reboot. Don't think diagnostics should be necessary but including them anyway. Note that I've recently made some hardware changes, but spotted this both before and after the change. tower-diagnostics-20200421-0955.zip
-
Sorry, can't remember. Assuming you mean Windows drivers in the guest VM, then I would have updated to the latest ones ASAP. I keep changing things around to suit other family members, and am moving at least one (what will be a heavily used gaming based machine) back to physical. Keep the virtual for remote desktopping into and an occasional, low use KVM machine.
-
The test preclear was a success, but at the top of the Log file there is a line (just under Preclear Disk Version: 1.0.6) that says: Disk /dev/sdd is a SSD, disabling head stress test. The disk is not an SSD, but is connected to a cheap PCIE SATA board. I think it's this: [1095:3132] 06:00.0 RAID bus controller: Silicon Image, Inc. SiI 3132 Serial ATA Raid II Controller (rev 01) I'm going to assume the SSD identification won't cause any problems and start another PreClear run. @gfjardim - Thanks for the updates and the excellent support.
-
I've just had a similar error to Simon above. A new "shucked" WD 6tb drive. Unassigned devices shows: Near the end of the preclear log I see these lines: Nov 24 14:25:56 preclear_disk_WD-WX21D690LD9T_12518: syslog: sd 3:0:0:0: [sdc] Attached SCSI disk Nov 24 14:25:56 preclear_disk_WD-WX21D690LD9T_12518: syslog: WDC_WD60EDAZ-11U78B0_WD-WX21D690LD9T (sdc) 512 11721045168 Nov 24 14:25:56 preclear_disk_WD-WX21D690LD9T_12518: syslog: excluded disks=sda sda2 sdb sdc sdf Nov 24 14:25:56 preclear_disk_WD-WX21D690LD9T_12518: syslog: Command: /usr/local/emhttp/plugins/preclear.disk/script/preclear_disk.sh --notify 1 --frequency 4 --cycles 1 --no-prompt /dev/sdc Nov 24 14:25:56 preclear_disk_WD-WX21D690LD9T_12518: syslog: Disk /dev/sdc is a SSD, disabling head stress test. Note that the disk is not an SSD. Only thing I can think of is that during the zeroing run I added a USB drive to the server (an old drive in the donor USB case). That seemed to pause the zeroing whilst it formatted, but is working as a UD attached disk. Preclear logs attached. What do I do now. I was going to use it as a replacement parity disk, but wanted to give it a try out. Is it unreasonable to just go ahead and swap it with the existing parity? Thanks, Jon. TOWER-preclear.disk-20191124-1934.zip

-
That worked for me. Thanks. Been having issues for a few days, trying multiple installs with issues when the driver installs. Right pain in the wotsit. Also using Seabios - that's what I was on when I tried the Q35, not going to change either if it works.
-
Latest update has fixed this. Many thanks.
-
I'm not currently running PiHole, but I am running an adblocker on my router. Have just tried switching that off along with suspending adblock and ublock in the browser, but it makes no difference. Have tried a few browsers - the only one to show anything is Edge (and IE) on Windows which show "Undefined" so something is happening at the client end. If you look at "System Stats" you will see network activity (as long as you're not in a VM on the Unraid server!), so it's likely it's just the display widgets which are broken client side.
-
I think this is broken at the moment. Just tried uninstalling and reinstalling the container, but when running the test the speeds don't change and the IP Address is blank. In W10 on Edge, the speed counters and IP show "undefined". When I click "Start" there's definitely network traffic though.


