casperse
Members
-
Joined
-
Last visited
Everything posted by casperse
-
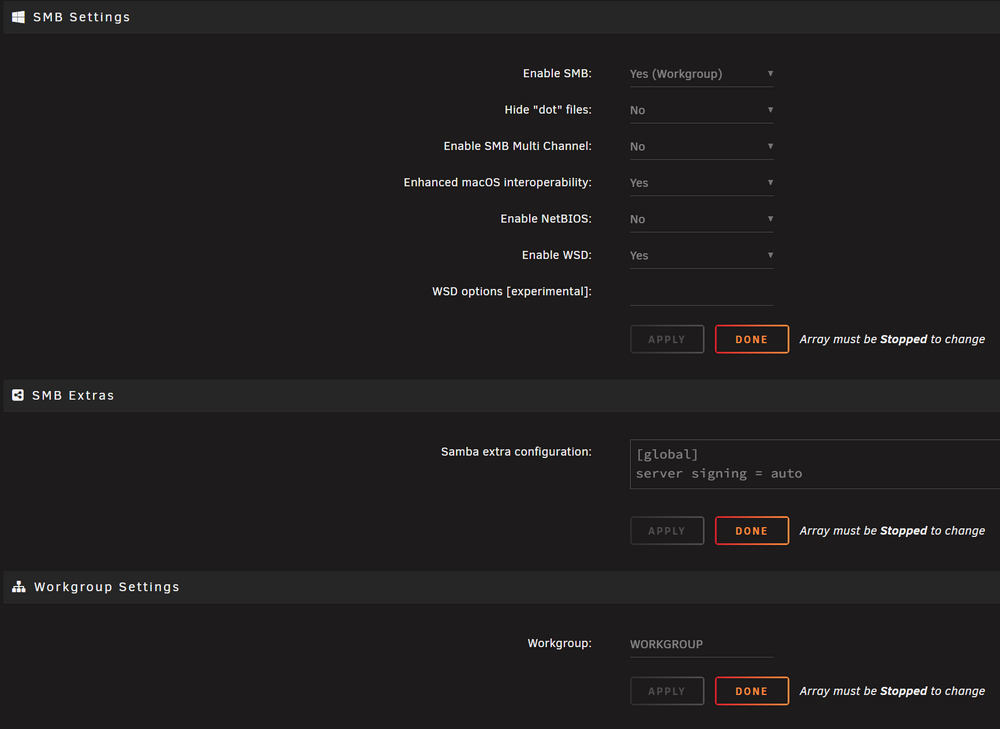
Yes so do I dont define them as a mirror cache? I just create one big ZFS Pool? - I create this for everything and forget about the traditional Unraid server setup ? (Sorry this is so strange to me) (It complain about parity hope that goes away if I remove the one Nvme drive (As this one drive is now listed in my Array) I have never created anything but either a Array with parity drives and some different cache pools
-
But is it correct that with a small server like this that everything is best setup and defined as cache drives maybe in a Raid/mirror setup?
-
Update: When the SATA bracket is installed: ❌ The Gen4 NVMe slot cannot be used for an NVMe drive ✅ The other two NVMe slots (PCIe 3.0 x4 + x2) still work ✅ You can run 2× NVMe + 1× 2.5” SATA When the SATA bracket is not installed: ✅ 3× NVMe (1× Gen4 + 2× Gen3) This is reported to be working if I go with external case.... Broadcom LSI SAS3008 9300-8e ?? ooH this is pretty cool: https://youtu.be/3MDzL2mxYcY?si=qaWH1qmfiPqfokab
-
Okay I might have misunderstod this.... If I use the adapter for the 2.5" I lose the fast 4 gen NVMe drive....
-
Hi All Fellow "Unraiders" I am in the process of setting up Unraid on this great little server MS-01 with 32G Ram and a 1TB Nvme drive (Package) So with the limited options on storage and my need to get some security I need some guidance Parity vs Cache Pools? The HW have some limits also: The MS-01 has 3 NVMe slots with different PCIe versions: Left slot (primary) = PCIe 4.0 x4 (max ~7000 MB/s) Middle slot = PCIe 3.0 x4 Right slot = PCIe 3.0 x2 (lower bandwidth) SSD adapter included: The MS-01 supports 1× 2.5” SATA SSD/HDD, and the mounting plate/bracket is included in the box. This is SATA 6 Gb/s (≈ 550 MB/s max). No NVMe speeds here – but stable additional storage. The limitation is only here: If you use the PCIe x16 expansion slot, lanes are shared and one NVMe slot is disabled Without a PCIe card → full configuration is possible Bottom line: Yes: 3× NVMe + 1× 2.5” SATA SSD = the optimal MS-01 setup No: Using a PCIe adapter at the same time = you sacrifice one NVMe What you should NOT do (if you want the most NVMe): Use a PCIe adapter card (it disables an NVMe slot) So that leaves me with 3 x Nvme + 1 x 2.5" SSD Creating 1 Array with parity doesn't make much sence so would it be better to just make one big cache pool with raid? and a SSD UAD assigned drive This would mix fast Gen4 with Gen 3 Nvmes? Or Cache single gen 4 Nvme Array with 1 parity drive 2 x gen3 Nvme and the 2.5" as a ZFS drive having all my snapshots on here? I can see other people have used the MS-01 as a small server, what did you decide on? Cheers Casperse
-
I did the download diag after ssh reboot and the UI came back to live. diagnostics-20251127-1625.zip
-
ok did ssh: reboot Need my UI back....
-
I tried the "old" /etc/rc.d/rc.nginx restart /etc/rc.d/rc.nginx resload But no change....
-
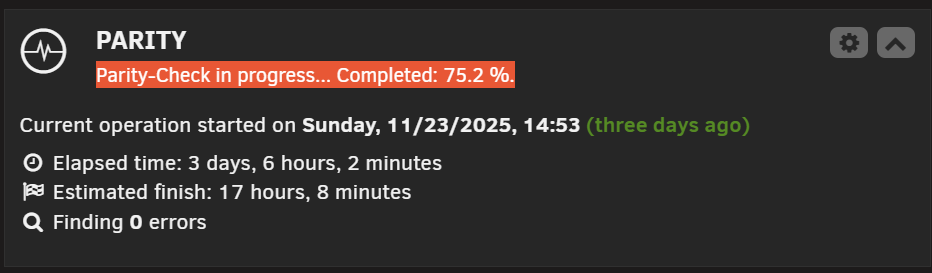
Hi All My unraid is non responsive? But all my docker apps are running fine? Trying to connect from any device locally IP or using connect I just get.... Sorry no logfile cant get one.... No problem with the version before? and no changes or new installs after upgrading? UPDATE: on a tab I can see a frozen UI with parity running: (No way to refresh)

-
Mine was dead doing the reboot not even terminal access locally. I did a power reset and it started up after that, no swapping of USB ports
-
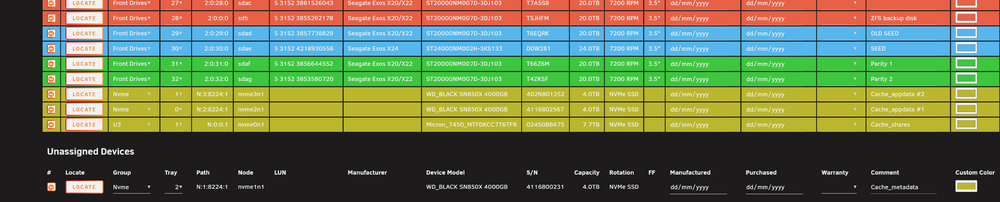
Hi I still have a problem adding a 3 nvme (We talked about this in a older post, problem finding it) I cant add the below nvme as tray 2 above I have the nvme as 0 and 1 and I cant edit these tray either. Pressing save and nothing happens but I can see the NVME below so it is found
-
HAs anyone gotten the gluetunvpn with the Qbittorrent working with PIA? I keep getting stale because port forwarding is a problem with Gluetunvpn.
-
I have a NVME and it is dicovered by scan, but for some reason I can add it to the "bay" Dont know what this error mean?
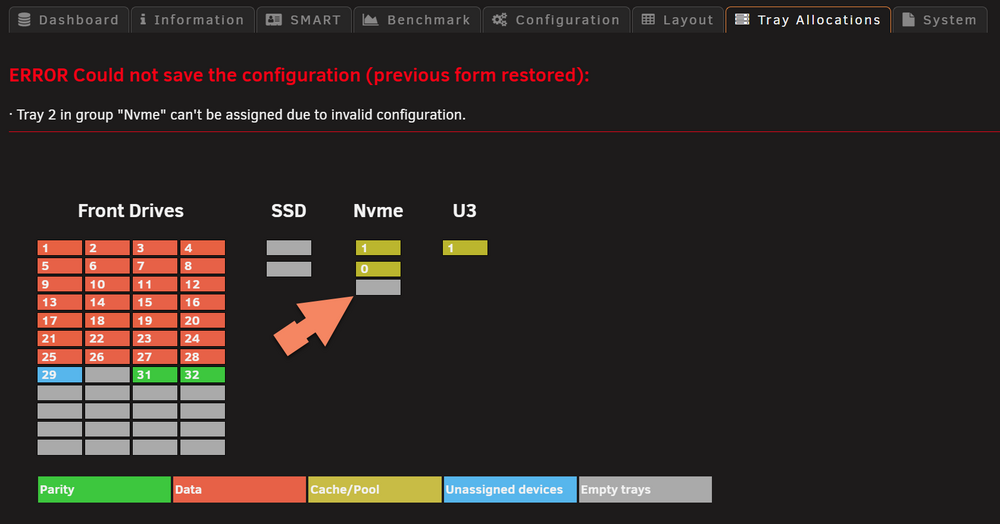
-
Yes but normally I need to access some configuration file, and most of them is not supported by the Unraid filemanager example would be .yml files and others. Its so much easier to just change the values on you PC than logging into the UI. Sofar the only way has ben to use the mastershare-pool and that gives me other problems
-
Hi Gents! I need a little help cant wrap my head around this??? I have SMB shares mapped directly to my laptop and they all work! But when I "read" the same settings to my appdata folder I cant map the drive? I keep getting strange messages like: So I am thinking the only difference is that my appdata is located on its own cachedrive? So something prohibits the access? I have exactly the same settings for shares and users! And I cant remove the master share before I can access the appdata folder must important directory :-)
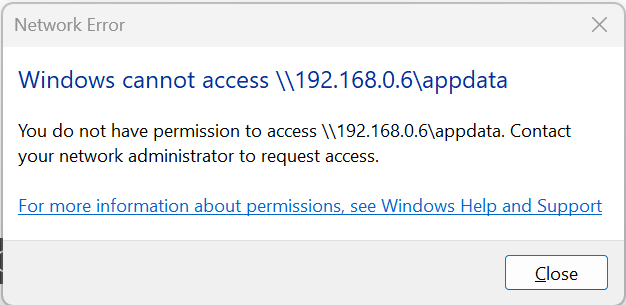
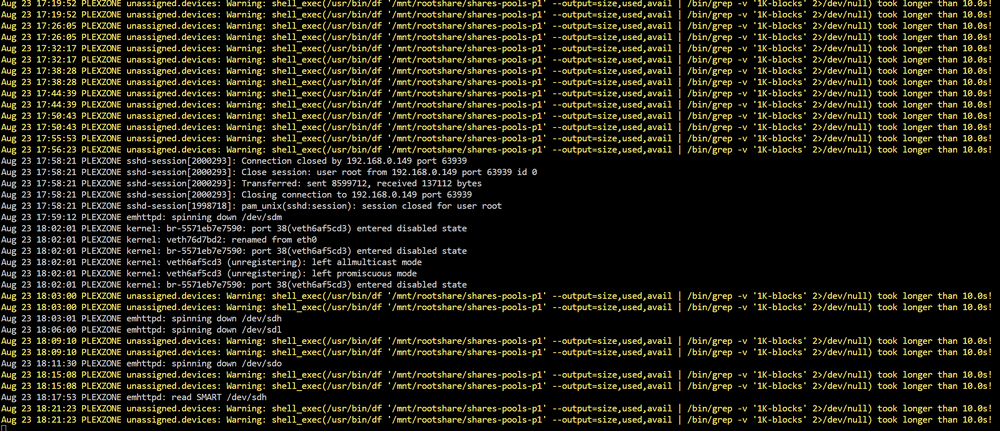
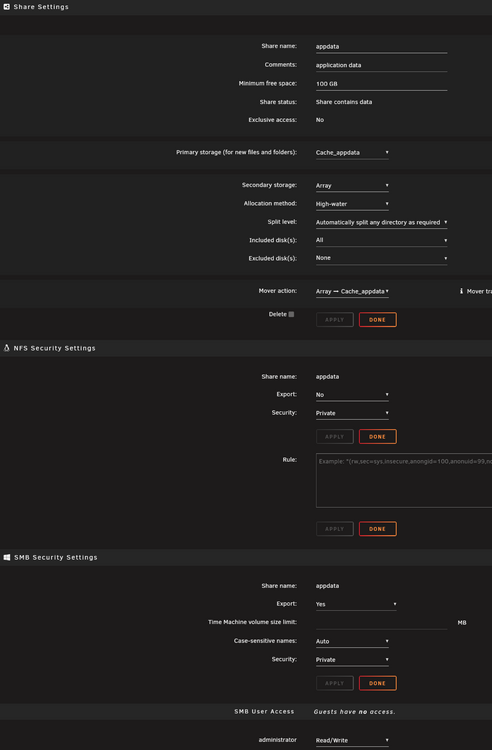
-
The only thing that I really like about the root share is that if you move large files you dont really move them it just changes the source directory (At least it seems like that - instantly moving files)
-
Safeboot and +100G of file transfers... No errors! I will keep the Dynamix Cache Directories plugin for now cant see much RAM usage. And I can see a speedup in listing subdirs and files when looking through the file manager its more snappier on my laptop! safeboot-diagnostics-20250816-1458.zip
-
Ok thanks again for helping me out! I just did a manual SMB mapping to my movie drive and I get an error? The funny thing is that I have copied SMB access to this folder from other folders and they all work! ALL OTHER FOLDERS IS WORKING and I can map them to my PC except this one Example if I try to access any of the other folders as a direct mapped share it WORKS! Only movies is giving this error, also if I go to the root share I have access to all folders. UPDATE: Okay I might have found the "Culprit" I am stupid!, for some reason my Tailscale client on my laptop works perfectly for all folders except the Movie folder? Turning the Tailscale connection off and I got access to the share instantly , I don't know if this has anything to do with the transfer dropouts? But I cant rule it out NOTE I did have the Allow local network enabled on Tailscale! Anyway I will do the safeboot and test again from multiple PC's and do the diagnostic
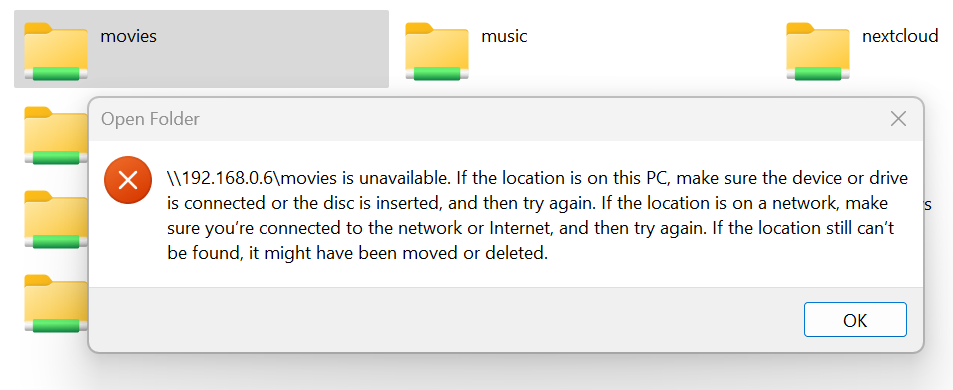
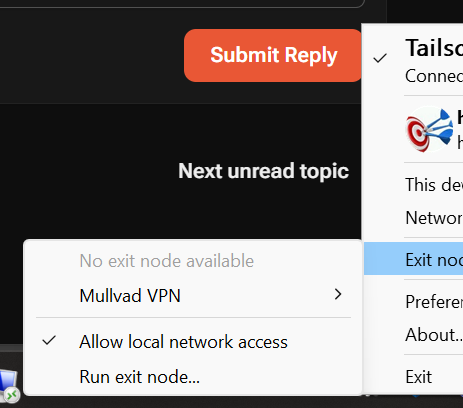
-
Thanks JorgeB - But I really like the root share feature :-( So I need to remove it completely? (Had a hard time setting that up between to Unraid servers) Cant I just do the test on a normal share? Thanks Frank1940 I installed the plugin again (Cant hurt) and I only selected the media folders (I don't know if my RAM can handle that?)
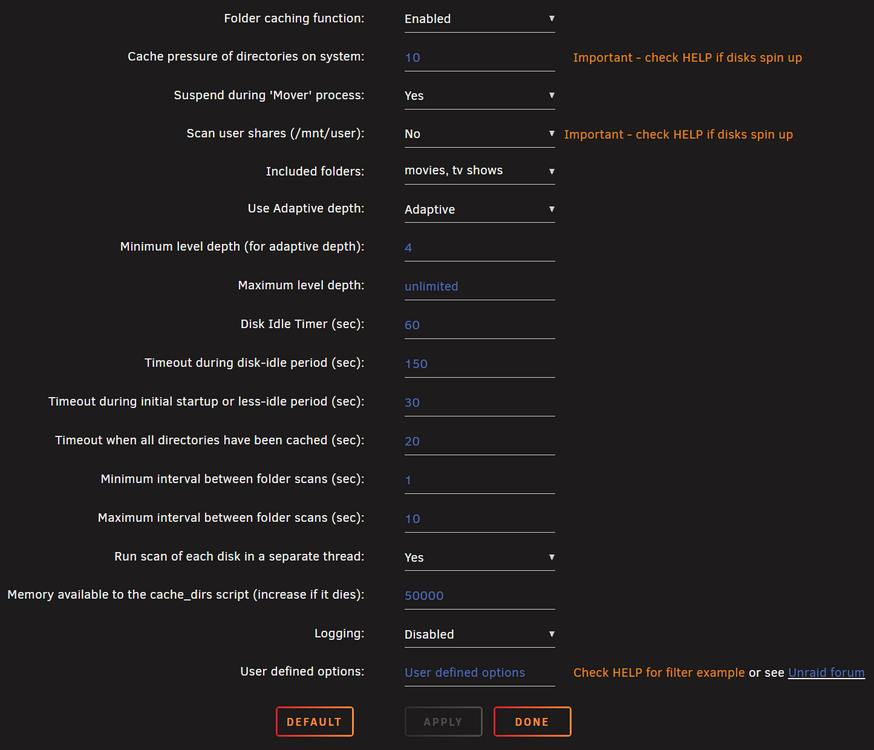
-
Hi Frank1940 Yes in my last upgrade I got carried away got myself a special case that could max out the 30 drives Unraid supports :-) and then some extra for ZFS in the future. Before Unraid many years ago I had a Synology with 24 drives that ran on a very small CPU. The current Unraid server have run anything I have thrown at it - the i9 is a beast even downclocked to avoid any problems it runs everything. So far Unraid have been great even if I have all these drives the source folder of any file is collected in the same subdir, so copying a folder is from a single drive. I thought the plugin to help list your files cached the drives listings of the Root drive? (Maybe that got lost in the latest update of Unraid ?) Cant remember the name of it? it would help index and list your root folders quickly but yes I cant see that gone an not anymore had it on my old server I just noticed this in my error log while transferring I access the shared drives through the Unassigned plugin: And I can see the rootshare is taking longer (Freezes). Sure JorgeB I can do that tomorrow, safemode transfer large files and do a new diagnostic when it freezes....
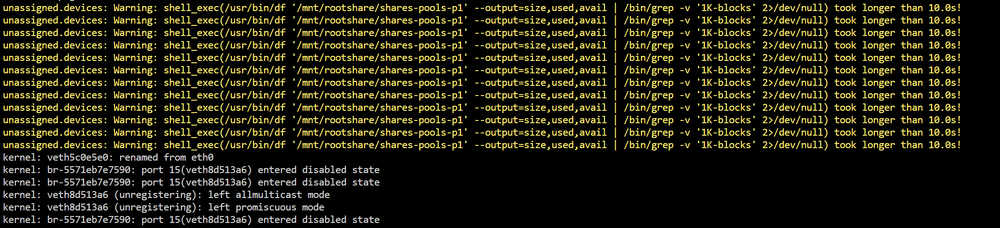
-
I tried setting up the Gluetun as "normal" with the linuxserver QBittorrent docker and every torrent I started would be status "stale" I found this: IMPORTANT PORT FORWARDING WITH PIA DOES NOT SEEM TO WORK! Would this fix this? - Portforwarding with PIA works in the "QBittorrentVPN docker" GitHubgluetun-wiki/setup/providers/private-internet-access.md a...Home to the Markdown Wiki page for Gluetun. Contribute to qdm12/gluetun-wiki development by creating an account on GitHub.
-
On a sidenote, "In the old days" I remember that you usual keept CPU 0 for the Unraid OS to use. But looking at the pinned options I can only exclude CPU 0 from everything and then set it to a App/Docker? What is the correct way to always keep one of the power cores to the Unraid OS? (I was just thinking this could help?)
-
Thanks Frank1940 ! - I actually thought about this:" "One more thing to try. Spin up all the disks in the array (MAIN tab of GUI) before you start file managing." But I changed the performance settings on Unraid to performance from powersavings (I thought that would spin up drives when initiating a file transfer or accessing the server?) So you mean manually go to the UI and press the spin up all drives? before initiating a file transfer? sometimes its just using filemanager to find a file... (Not a good thing on a file server LOL) Yes I see the confusion and I probably just butchered my security adding these settings - I did have access before to the SMB shares just not reliable. The funny thing is that I know I am running many dockers and they are all on fast nvme's and my RAM usage is 50-60% and my i9 is keeping up with everything so I invested in 10G card and a 10/2.5G switch beliving that would solve it :-) diagnostics-20250815-1102.zip
-
I actually always used the internal File manager until now. (Like today it was my way of trying to create a workaround) Its copying a large file (Large 20G) its playback of a media file over the network, its listing folders in a share and a "frozen" windows window not reacting over time.... I don't want to just drop a logfile what can I do to test this? in a good way? Any docker I can install to monitor network to and from the machine? I have a Unifi UDM pro as a router and many switches 24 ports could Unifi be the problem? My network from the server is a collection of 10G + 2.5G + 2.5G all placed in a switch supporting these speeds. Sorry if I am rambling... its just becoming a big problem when you want to move some data or just haven a open share on your windows PC Any special setup in regards to win 11 and the user setup? (It just worked) UPDATE: I just found this.. (Trying this out to see if it makes a difference - already have access and mapped shared drives though?) Select Start, type gpedit.msc, and select Edit group policy. In the left pane under Local Computer Policy, navigate to Computer Configuration\Administrative Templates\Network\Lanman Workstation. "my edit find the SMB over QUIC and enable it" Open Enable insecure guest logons, select Enabled, then select OK. found if you are using a local account and not a Microsoft account then maybe you need this instead i used like 4 hrs to find a fix a. On the Start Menu search, type gpedit and start the Edit Group Policy app (i.e. Local Group Policy Editor). If you are using Home edition, skip to step 8. b. In the console tree, select Computer Configuration > Windows Settings > Security Settings> Local Policies > Security Options. c. Double-click Microsoft network client: Digitally sign communications (always). d. Select Disabled > OK. And the command: Set-SmbClientConfiguration -EnableInsecureGuestLogons $true -Force
-
Hi All I still see drop outs from SMB shares and management of files (Using the file manager Opus it can delay operation until it reconnects). But transferring files is a nightmare. Anything I can change in the SMB special config?