

servidude
-
Posts
76 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by servidude
-
-
On 10/10/2022 at 1:03 PM, whiteatom said:
It seems this plugin is being flagged in the 6.11 upgrade assistant as deprecated. Is there are upgrade available or alternative to track where each disk physically is within my case?
Disk Location (although I still prefer the look of this plugin).
-
@theone (or anyone else), does anyone still have the icons this plugin seems to rely on? It is looking in /usr/local/emhttp/webGui/images/, but the .png files no longer exist in there... looking for ones like blue-on.png for example. Thanks for any pointers!
-
6 minutes ago, dlandon said:
I'm not finding it in my archive. What was it used for?
The (now deprecated, but still working) "Server Layout" plugin uses these icons. Do you remember where you found the last one?
-
-
Hi, does anyone still happen to have a copy of the old status icon, blue-on.png lying around? It should live in /usr/local/emhttp/webGui/images/ which in my version (6.10.3) is symlinked to /usr/local/emhttp/plugins/dynamix/images/. I tried downloading some older releases, but couldn't find anything in the archives. Would be grateful for any pointers. Thanks!
-
Running 6.10.3 here. I have an old 1TB SSD that, surprise surprise, has started failing. I tried rsyncing all the data off it, and did a ddrescue as well, but in both cases I got a number of read errors. So while I have most of the data still, some of it is corrupted.
For now I have switched off Docker and VMs in order to not stress it any further.
I would like to ultimately replace the cache with a mirrored pool of two 1TB SSDs. I believe (correct me if I'm wrong) that it will be easiest to replace the failed drive with a single new one first, and after that's working, install the additional drive and add it to the pool.So how would I go about doing that? I found some instructions for Replacing or upgrading your Cache drive but that seems to assume the original drive is error-free. A link on Reddit gives instructions that seem straightforward enough, but once again they don't seem to account for the fact that I am replacing a drive with some file corruption on it.
So how would you proceed? Write the ddrescue image to a new drive, and then install that as the new cache? The problem is, there will be some files that are corrupted on it - I don't care about downloads, but if it's a Telegraf database, then that might be more of an issue.
I found a utility called ddru_findbad that parses the ddrescue log and tells you which files were affected by the read errors - this might give me an idea of what to look out for.
Note I do have "Appdata Backup" installed so could roll back from a previous version if any of my Dockers/VMs are FUBARed.
Thanks for any suggestions!
-
2 hours ago, Mcklaren said:
The libffi package was updated and fixes this problem.
Thank you, @Mcklaren!
-
 1
1
-
-
Does anyone know if the libffi.so.7 problem with borgbackup has been fixed with version 6.12? I know it was still an issue with v6.11.5.
-
Wonderful. Thank you @dlandon!!
-
Hi, does anyone still happen to have a copy of the old status icon, green-blink.png lying around? It should live in /usr/local/emhttp/webGui/images/ which in my version (6.8.3) is symlinked to /usr/local/emhttp/plugins/dynamix/images/. I tried downloading some older releases, but couldn't find anything in the archives. Would be grateful for any pointers. Thanks!
-
3 minutes ago, Squid said:
Look in /usr/local/emhttp/plugins/dynamix/images
Thanks, but no luck. green-on.png is in there, but not green-blink.png.
-
On 5/28/2015 at 8:30 AM, limetech said:
The idea is that 'color' would be used to generate the name of an icon image file to display for the corresponding state. For example, orignally "green-on.png" was a green solid ball and "green-blink.png" was a green blinking ball. Similarly, "red-on.png" was a bright solid red ball and "red-off.png" was a dim solid red ball.
Several years later.....
Is there still a way to get my hands on some of these assets? In particular, green-blink.png which is still required by the (outdated) Server Layout plugin. I tried downloading some old unRAID releases (I'm using v.6.8.3), but couldn't find these image files within any of the archives. I don't suppose anyone still might have them lying around?
Thanks!
-
I realize this plugin has been marked as "deprecated", but it's still working fine for me in v6.8.3.....with a few small cosmetic errors. One of them are icons that fail to load properly - see attached. Looks like it's looking for green-blink.png in /webGui/images/ (symlinked to /plugins/dynamix/images/). green-on.png is still in that folder, but no sign of green-blink.png. Does anyone still happen to have it lying around?
Thanks!
.png.eb28c1815396a622a1eb457f5f3bb4ef.png)
-
35 minutes ago, jakami99 said:
Btw, I'm using the "Auto Update Applications"-Plugin.
Sounds like an unexpected update to v2 maybe. How long have you had the "Auto Update" switched on?
-
Hate to reply to myself, but... I think I've figured out what's going on. Looking through my Telegraf logs I get lots of messages like:
E! [inputs.docker] Error in plugin: Got permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock: Get "http://%2Fvar%2Frun%2Fdocker.sock/v1.24/containers/json?filters=%7B%22status%22%3A%7B%22running%22%3Atrue%7D%7D&limit=0": dial unix /var/run/docker.sock: connect: permission deniedThe permissions seem OK though:
# ls -l /var/run/docker.sock srw-rw---- 1 root docker 0 Mar 29 00:04 /var/run/docker.sock=I've seen some advice about doing a chmod 666, but that seems a bit insecure...
root is a member of the docker group, so I'm not sure why I'm getting "permission denied". Which user is Telegraf trying to run as?
Edit: Problem solved!! Turns out Telegraf 1.20.3 (and beyond) breaks some things by no longer running as root. The simplest solution is to just pin your repo to telegraf:1.20.2-alpine. Thanks @axipher for your helpful post!
-
 1
1
-
-
My InfluxDB/Telegraf setup has stopped producing any docker-related statistics (e.g. docker_container_cpu), since some time late last October. Any ideas what could be going on?
I didn't change the configuration and I did not upgrade to InfluxDB v2 - repo points at influxdb:1.8-alpine.
I checked my telegraf.conf, [[inputs.docker]] is not commented out.
I used Chronograf to do some data exploration and got the same lack of results, see attached screenshot.
Any suggestions for what else I could check? My dockers themselves are still working just fine.
unRAID version is 6.8.3, I tried rebooting but the problem persists.
Thanks for any tips!
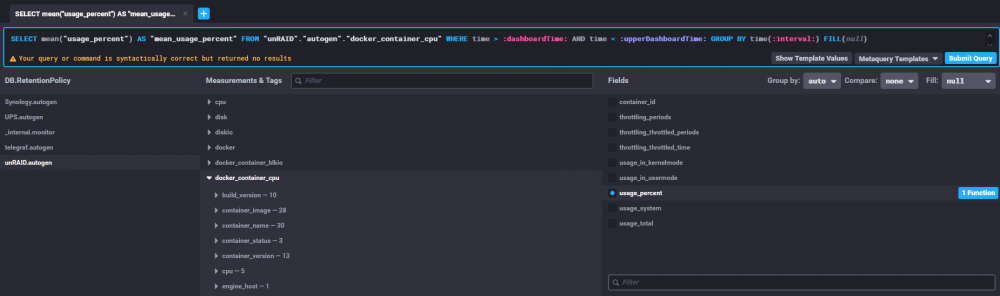
-
30 minutes ago, cinereus said:
Thanks all, this fixed it. What will cause a proper fix to be made so I can remove the line from my gofile? Do I have the upgrade the unraid version entirely?
Look at @HyperV's post above:
The problem is that the format changed slightly in the docker repository, v.6.9.2 has adjusted to it, but if you are using older versions you will have to manually fix the file (and keep the bit in the go file).
-
1
-
-
23 hours ago, Ford Prefect said:
What @Ford Prefect said! I too am still using 6.8.3 (still waiting for another point release or two before moving to 6.9) and very grateful to you all for your help with fixing this issue.
-
19 hours ago, jbrodriguez said:
Can you heck if it's crashing, in Chrome, it's in View > Developer > Javascript console
Thanks, I'm using Firefox where it's Tools | Browser Tools | Web Developer Tools, then click on Console.
-
On 4/23/2021 at 12:53 AM, qasde said:
Im trying to consolodate my data from many small 3-4 TB drives onto a new 14TB drive. After selecting the drive in Unbalance and the folders and choosing the disk, I pressed plan. Then nothing happens. The unbalance logo still animates but nothing works it like its frozen
Same issue here. unRAID 6.8.3 with v5.6.3 of the plugin.
-
I'm seeing similar notifications about 3 supposedly corrupted files, but no names!
BLAKE2 hash key mismatch, is corrupted BLAKE2 hash key mismatch, is corrupted BLAKE2 hash key mismatch, is corruptedThe corresponding syslog entries are also missing file info, for example:
Feb 28 18:17:44 Tower bunker: error: BLAKE2 hash key mismatch, is corruptedWhat is the cause of this (apparently I'm not the only one seeing it), and how can I fix it - is there a way to reset the file hashes?
-
8 hours ago, jbartlett said:
1. I don't think there would be any difference in speeds regardless of file system in reading of existing files. The creation & deletion of files, the file system can play an impact in the speed of the operations but that is also highly variable such as tree depth, number of files in a directory, even drive utilization percentage. I haven't thought about trying to benchmark that, not sure if there's enough value to the results to warrant it.
Thanks for your thoughts on this. I've tried, somewhat naively, to time a file copy from /mnt/diskX to /mnt/diskY (and /mnt/diskZ) and compare the results. They weren't particularly illuminating (nor consistent). If I understand this correctly, the write speed would be affected by where on the drive's platter the data is being deposited, which is usually something beyond the user's control. Is my assumption correct?
-
6 hours ago, Squid said:
ALL writes to /mnt/diskX will always involve the parity disk.
Besides, your thought process is wrong. If you were really going to purposely bypass the parity system (and there is a way to do it)
OK then, thanks for clearing that up. What would you suggest as a better way for testing read/write speeds of individual drives?
-
Thanks, @jbartlett, for the WIP updates!
I've been using your excellent docker for some time now and have a couple of questions:- Would you expect these speed tests to show up any difference in file system performance? I'm trying to see if I can measure a quantifiable difference between my XFS and BTRFS formatted drives (the graphs don't show anything obvious).
- Any possibility or plans to measure write (not just read) speeds?
Thanks again, and happy holidays!

.png.eb28c1815396a622a1eb457f5f3bb4ef.png)


Looking for old version of blue "colored balls" icon
in Lounge
Posted
Yeah, I tried looking through some old tarballs but it seems the plugin just used the regular unRAID icons (which have since changed). In the .plg file changelog I found a reference to using unRAID's status icons in mid-2015 - which version was unRAID at back then and can I still find an old version of it somewhere?
Thanks!