

vakilando
-
Posts
370 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by vakilando
-
Krusader als docker nehme ich an. Zeig doch mal deine Krusader Dockerkonfiguration (>Docker>Kursader>Edit). Nicht vergessen mit Klick auf "Show more settings ..." zu erweitern. "Advanced view" brauchen wir erst mal nicht denke ich. (Meine Beschreibung ist englisch weil ich noch die 6.8.3 habe, du wohl die neue Beta 25?)
-
Kannst du - vom Mac mit dem Finder - dort Dateien in "Bilder" ablegen/speichern? Wenn ja: Siehst du in Unraid - wenn du rechts in der Spalte "Ansicht" im Ordner "Bilder" schaust - auch diese neuen Dateien?
-
Ich schätze es liegt ein Berechtigungsproblem vor, vermutlich hast du mit dem User root die Daten auf das Array kopiert? Oder hast du einfach ein Verzeichnis auf dem Array angelegt? Wo hast du die Daten hinkopiert (/mnt/user/blabla oder /mnt/user0/blabla oder ...) hmmm, da fehlen einige Infos: wie hast du synchronisiert (kopiert, Synctool, ...)? von wo nach wo (ext. HDD an Mac zu Unraid, ext. HDD an Unraid zu Unraid, ...)? wenn von ext. HDD an Unraid zu Unraid, mit welchem User? wohin hast du synchronisiert, spricht stimmen die Freigaberechte? was heißt "Wenn ich aber in Unraid auf die Festplatte zugreife": von wo (Client, ssh, ...) nach wo (Browser, Freigabe (smb/nfs))
-
Hallo, schau mal unter Settings > Network Settings. Dort solltest du beide Karten finden und auch das Gateway eingeben können. DNS Server (bis zu 3 Stück) habe ich nur bei eth0. Weiter unten unter "Interface Rules" kannst du die Zuweisungen der Netzwerkkarten (anhand der MAC Adresse) zu den eth0 / eth1 Port erledigen. Wenn dein Router (DSK/Kabel) DNS macht (und wenn auch nur Forwarding), solltest du diesen als Gateway eintragen - das könnte schon ausreichen. Ansonten Zuweisung unter "Interface Rules" mal ändern. Logisch....achte darauf, dass beide Netzwerkports per Kabel am Router/Switch (im selben VLAN, falls vorhanden) hängen.....
-

[6.8.3] docker image huge amount of unnecessary writes on cache
vakilando commented on S1dney's report in Stable Releases
Thanks! The procedure "back up, stop array, unassign, blkdiscard, assign back, start and format, restore backup" is no problem and not new for me (except of blkdiscard) as I had to do it as my cache disks died because of those ugly unnecessary writes on btrfs-cache-pool... As said before, I tend changing my cache to xfs with a singel disk an wait for the stable release 6.9.x Meanwhile I'll think about a new concept managing my disks. This is my configuration at the moment: Array of two disks with one parity (4+4+4TB WD red) 1 btrfs cache pool (raid1) for cache, docker appdata, docker and folder redirection for my VMs (2 MX500 1 TB) 1 UD for my VMs (1 SanDisk plus 480 GB) 1 UD for Backup data (6 TB WD red) 1 UD for nvr/cams (old 2 TB WD green) I still have two 1TB and one 480 GB SSDs lying around here..... I have to think about how I could use them with the new disk pools in 6.9 -
[6.8.3] docker image huge amount of unnecessary writes on cache
vakilando commented on S1dney's report in Stable Releases
No, I'm on 6.8.3 and I did not align the parition to 1MiB (its MBR: 4K-aligned). What is the benefit of aligning it to 1MiB? I mus have missed this "tuning" advice... -
[6.8.3] docker image huge amount of unnecessary writes on cache
vakilando commented on S1dney's report in Stable Releases
ok, after I've executed the recommended command: mount -o remount -o space_cache=v2 /mnt/cache this ist the result after 7 hours of iotop -ao The running dockers were the same as my "Test 2" (all my dockers including mariadb and pydio) See the picture: It's better than before (less writes for loop2 and shfs) but it should be even less or what do you think?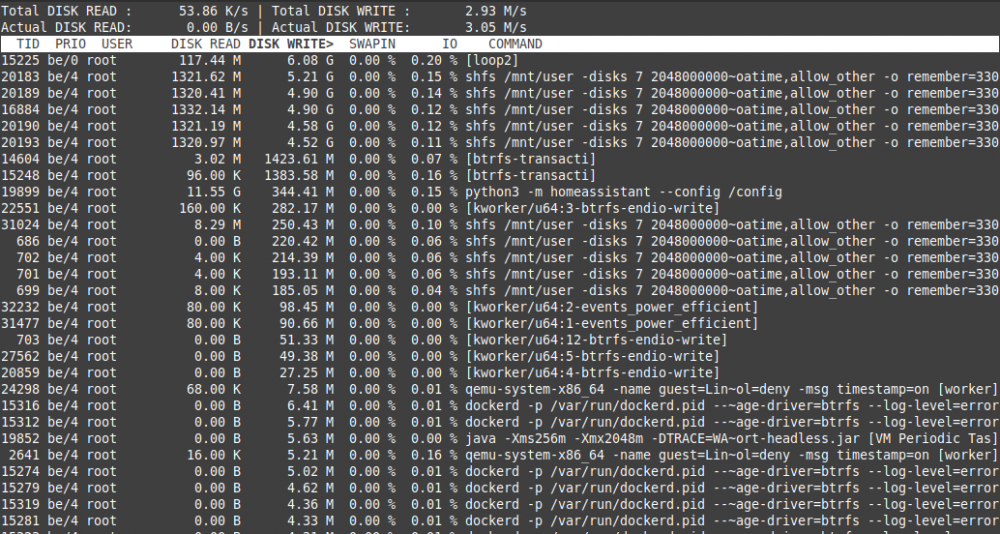
-
[6.8.3] docker image huge amount of unnecessary writes on cache
vakilando commented on S1dney's report in Stable Releases
oh....sorry... I did not read the whole thread... Now I did! I'll try the fix now an do this: mount -o remount -o space_cache=v2 /mnt/cache -
[6.8.3] docker image huge amount of unnecessary writes on cache
vakilando commented on S1dney's report in Stable Releases
perhaps I should mention, that I had my VMs on the cache pool before, but the performance was terrible. Since moving them to an unassigned disk their performance is really fine! Perhaps the poor performance was due to the massive writes on the cache pool....? -
[6.8.3] docker image huge amount of unnecessary writes on cache
vakilando commented on S1dney's report in Stable Releases
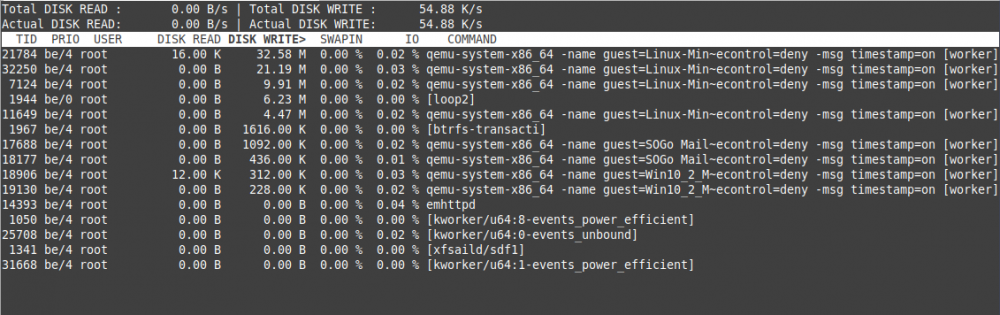
Damn! My Server seems also to be affected... I had an unencrypted BTRFS RAID 1 with two SanDisk Plus 480 GB. Both died in quick succession (mor or less 2 weeks) after 2 year of use! So I bought two 1 TB Crucial MX500. As I didn't know about the problem I again made a unencrypted BTRFS RAID 1 (01 July 2020). As I found it strange that they died in quick succession I did some researches and found all those threads about massive writes on BTRFS cache disks. I made some tetst and here are the results. ### Test 1: running "iotop -ao" for 60 min: 2,54 GB [loop2] (see pic1) Docker Container running: The docker containers running during this test are the most important for me. I stopped Pydio and mariadb though its also important for me - see other tests for the reason... - ts-dnsserver - letsencrypt - BitwardenRS - Deconz - MQTT - MotionEye - Homeassistant - Duplicacy shfs writes: - Look pic1, are the shfs writes ok? I don't know... VMs running (all on Unassigned disk): - Linux Mint (my primary Client) - Win10 - Debian with SOGo Mail Server /usr/sbin/smartctl -A /dev/sdg | awk '$0~/LBAs/{ printf "TBW %.1f\n", $10 * 512 / 1024^4 }' => TBW 10.9 /usr/sbin/smartctl -A /dev/sdh | awk '$0~/LBAs/{ printf "TBW %.1f\n", $10 * 512 / 1024^4 }' => TBW 10.9 ### Test 2: running "iotop -ao" for 60 min: 3,29 GB [loop2] (see pic2) Docker Container running (almost all of my dockers): - ts-dnsserver - letsencrypt - BitwardenRS - Deconz - MQTT - MotionEye - Homeassistant - Duplicacy ---------------- - mariadb - Appdeamon - Xeoma - NodeRed-OfficialDocker - hacc - binhex-emby - embystat - pydio - picapport - portainer shfs writes: - Look pic2, there are massive shfs writes too! VMs running (all on Unassigned disk) - Linux Mint (my primary Client) - Win10 - Debian with SOGo Mail Server /usr/sbin/smartctl -A /dev/sdg | awk '$0~/LBAs/{ printf "TBW %.1f\n", $10 * 512 / 1024^4 }' => TBW 11 /usr/sbin/smartctl -A /dev/sdh | awk '$0~/LBAs/{ printf "TBW %.1f\n", $10 * 512 / 1024^4 }' => TBW 11 ### Test 3: running "iotop -ao" for 60 min: 3,04 GB [loop2] (see pic3) Docker Container running (almost all my dockers except mariadb/pydio!): - ts-dnsserver - letsencrypt - BitwardenRS - Deconz - MQTT - MotionEye - Homeassistant - Duplicacy ---------------- - Appdeamon - Xeoma - NodeRed-OfficialDocker - hacc - binhex-emby - embystat - picapport - portainer shfs writes: - Look at pic3, the shfs writes are clearly less without mariadb! (I also stopped pydio as it needs mariadb...) VMs running (all on Unassigned disk) - Linux Mint (my primary Client) - Win10 - Debian with SOGo Mail Server /usr/sbin/smartctl -A /dev/sdg | awk '$0~/LBAs/{ printf "TBW %.1f\n", $10 * 512 / 1024^4 }' => TBW 11 /usr/sbin/smartctl -A /dev/sdh | awk '$0~/LBAs/{ printf "TBW %.1f\n", $10 * 512 / 1024^4 }' => TBW 11 ### Test 4: running "iotop -ao" for 60 min: 6,23 M [loop2] (see pic4) Docker Container running: - none, but docker service is started shfs writes: - none VMs running (all on Unassigned disk) - Linux Mint (my primary Client) - Win10 - Debian with SOGo Mail Server /usr/sbin/smartctl -A /dev/sdg | awk '$0~/LBAs/{ printf "TBW %.1f\n", $10 * PLEASE resolve this problem in next stable release!!!!!!! Next weenkend I will remove the BTRFS RAID 1 Cache and go with one single XFS cache disk. If I ca do more analysis and research, please let me know. I'll do my best!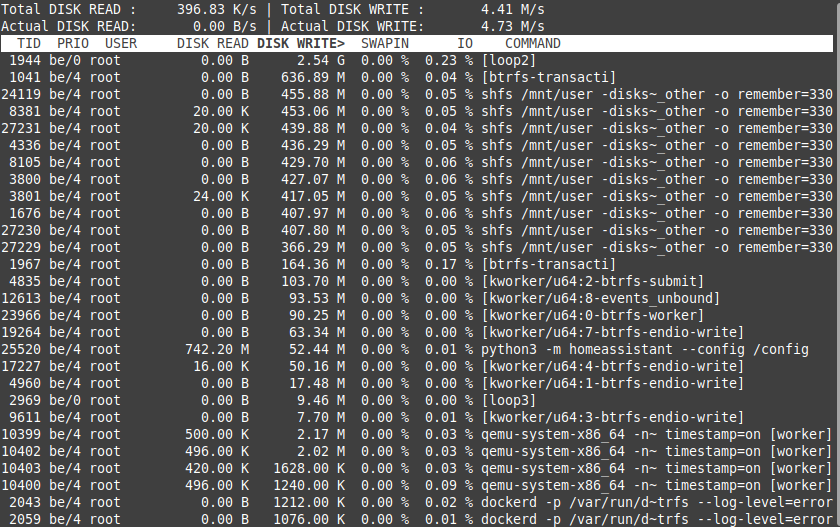
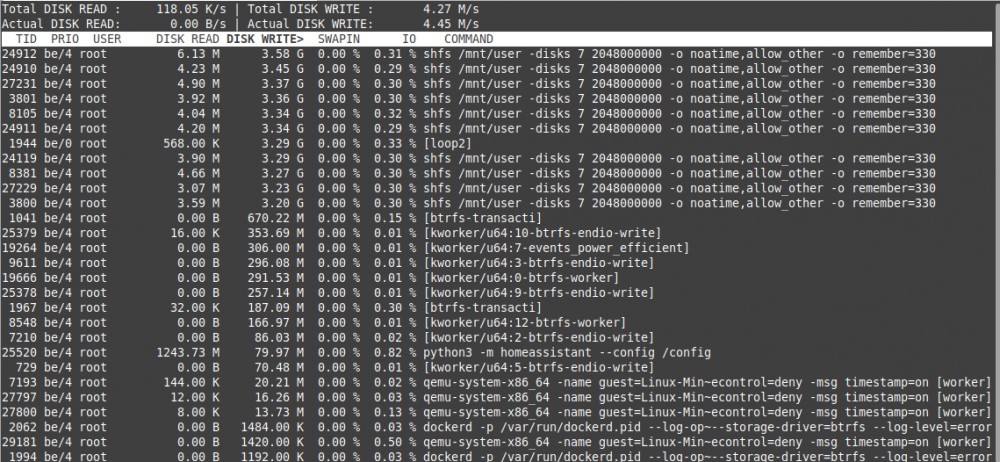
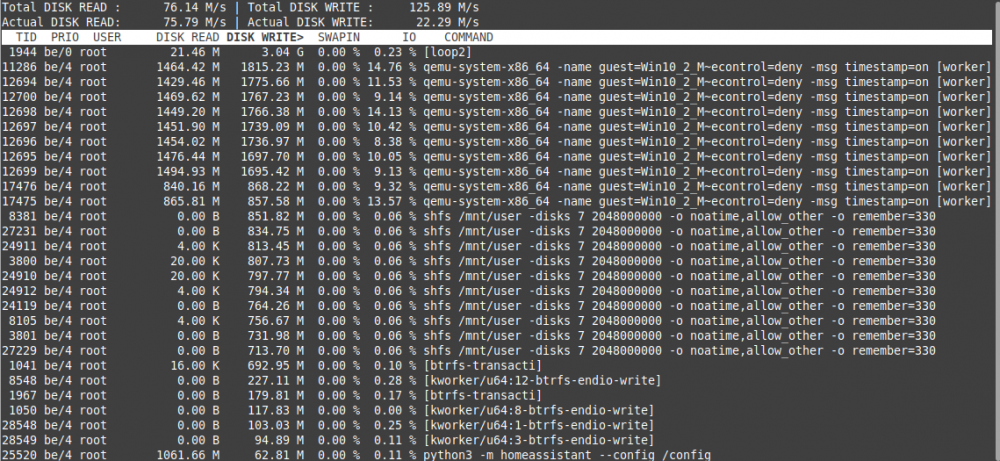
-
I can and confirm that setting "Settings => Global Share Settings => Tunable (support Hard Links)" to NO resolves the problem. Strange thing is that I never had a problem with nfs shares before. The problems started after I upgraded my Unraid Server (mobo, cpu, ...) and installed a Linux Mint VM as my primary Client. I "migrated" the nfs settings (fstab) from my old Kubuntu Client (real hardware, no VM) to the new Linux Mint VM and the problems started. The old Kubuntu Client does not seem to have those problems... Perhaps also a client problem? kubuntu vs mint, nemo vs dolphin? I do not agree that NFS is an outdated archaic protocol, it works far better than SMB if you have Linux Clients!
-
Ja, bin auch auf Github (Vakilando)
-
Moin, ich würde auch gerne mithelfen. Kann aber auch meist nur abends ran. Auf github in der main.txt ist übrigens ein lustiger Fehler: "Array Operation=Array Aufgraben"... Gesendet von meinem ONEPLUS A6003 mit Tapatalk
-
unRAID 6 NerdPack - CLI tools (iftop, iotop, screen, kbd, etc.)
vakilando replied to jonp's topic in Plugin Support
BorgMatic and/or Emborg in Nerd Pack would be great! Did you manage to install it? -
Also great would be to choose between: No notification detailed notification detailed summary at the end of a backup I chose detailed an have a hole bunch of mails in my inbox...
-
Thank you so much for this fantastic plugin!! Crazy, I just wrote down my biggest wish to be a vm-backup solution in the Unraid Forum 100K Giveaway thread.... and now it's coming! My tests all fished flawlessly and without any problems. I found a very minor error in the help section of "Set backup location": Point 3: "To choose a folder in /mnt/ instead of /mnt/users/, disable restrictive validation." In fact I chose an unassigned disk (/mnt/disks/Backup/) and I had not to disable the "restrictive validation". I also have a little wish list / ideas... I slightly modified your old script and added these features: My server beeps when finishing backup steps To do this I use the "beep" command with different parameters, so I know if thomething went wrong or right. Warning: beep -f 350 -l 700 Error: beep -f 250 -l 600 Success: beep -f 530 -l 300 -D 100 Perhaps you can integrate this feature as an option? I mount my unassigned disk before the backup and unmount it afterwards So nothing can happen to the backed up data (my vm's and documents) if a virus/ransomware hits my server. To achieve this have these steps: 1. find out what drive has to be mounted and if it's mounted 2. mount it if it's not mounted 3. send a notification 4. backup starts 5. unmount the disk 6. send a notification Perhaps you coud integrate a "pre-script" and a "post-script" feature, so one can make "things" before and after the vm-backups? Here are my script snippets 1. - 3. How it works: To be sure that the correct drive is mounted I use the UUID of the disk that I found out before manually with "ls -l /dev/disk/by-uuid". Then I get the device name (e.g. /dev/sdd1) on the basis of the UUID and write it in the variable "UDBACKUPDEV". Then I define a second variable "UDBACKUPSIZE" to store the size of the disk. Finally I check if the size is correct and then mount the disk to start the backup. As I'm writing this I really ask myself why I do so complicated (useless?) tests (in particular concerning the size), but I do remember that I had problems mounting the right disk because sometimes I change the disks in my removable disk bay... 😕 export BACKUPDISKSHARE='/mnt/disks/Backup' if ! [ -d "$BACKUPDISKSHARE" ] ; then ### Mail Notification /usr/local/emhttp/webGui/scripts/notify -e "VM-Backup" -s "VM-Backup begins." -d "Backup disk not yet mounted" -i "warning" -m "`date` \\n The backup disk is not yet mounted. Trying to mount it as $BACKUPDISKSHARE in the system." # Ensure to mount the right disk! # 1. got the UUID beforehand with "ls -l /dev/disk/by-uuid" # 2. get the device name (e.g. /dev/sdd1) on the basis of the UUID and write it in a variable "UDBACKUPDEV" UDBACKUPDEV=`findfs UUID=29bb9c6d-a1ee-4189-8146-1c898e314cb2` # 3. write the size of the partition in a variable UDBACKUPSIZE=`lsblk --output SIZE -n -d $UDBACKUPDEV` # 4. if it is 5.5T then mount it if [[ "$UDBACKUPSIZE" == " 5.5T" ]] ; then /usr/local/sbin/rc.unassigned mount $UDBACKUPDEV fi sleep 5 if ! [ -d "$BACKUPDISKSHARE" ] ; then # beep beep -f 250 -l 600 sleep 1 beep -f 250 -l 600 ### Mail Notification /usr/local/emhttp/webGui/scripts/notify -e "VM-Backup" -s "VM-Backup stopped!" -d "VM-Backup-HDD mount $UDBACKUPDEV failed" -i "alert" -m "`date` \\n VM-Backup stopped, because the backup disk $UDBACKUPDEV could not be mounted." exit else ### Mail Notification /usr/local/emhttp/webGui/scripts/notify -e "VM-Backup" -s "VM-Backup disk mounted." -d "VM-Backup-HDD mount $UDBACKUPDEV was successfull, $BACKUPDISKSHARE is ready to use!" -i "normal" -m "`date` \\n The VM-Backup disk $UDBACKUPDEV was mounted successfully!" fi else ### Mail Notification /usr/local/emhttp/webGui/scripts/notify -e "VM-Backup" -s "VM-Backup disk mounted." -d "VM-Backup-HDD mount $UDBACKUPDEV was successfull, $BACKUPDISKSHARE is ready to use!" -i "normal" -m "`date` \\n The VM-Backup disk $UDBACKUPDEV was mounted successfully!" fi 5. - 6. ###### # unmount VM-Backup HDD /usr/local/sbin/rc.unassigned umount $UDBACKUPDEV # hdparm -y : Standby Mode of the disk hdparm -y $UDBACKUPDEV #check if drive mounted if ! [ -d "$BACKUPDISKSHARE" ] ; then ### Mail Notification /usr/local/emhttp/webGui/scripts/notify -e "VM-Backup" -s "VM-Backup disk $UDBACKUPDEV unmounted." -d "The VM-Backup disk $UDBACKUPDEV was successfully unmounted." -i "normal" -m "`date` \\n The VM-Backup-Routine is finished and the Backup disk was successfully unmounted and removed from the system." else ### Mail Notification /usr/local/emhttp/webGui/scripts/notify -e "VM-Backup" -s "VM-Backup HDD $UDBACKUPDEV could not be unmounted." -d "The VM-Backup disk $UDBACKUPDEV could not be unmounted." -i "warning" -m "`date` \\n The VM-Backup-Routine has finished, but the Backup-HDD could not be unmounted and removed from the system. Pleas remove it manually." fi I hope you dont' find too much spelling errors because I'm german and translated all the comments and notification texts in the script, so you understand what I'm doing...😊
-
Unraid Forum 100K Giveaway
vakilando replied to SpencerJ's topic in Unraid Blog and Uncast Show Discussion
What I like: It was really easy to install and is easy to use. I've got more storage out of my disks than with raid and can easyly extend it. I began using docker and I love how easy it is with unraid. What I wish: I replaced my proxmox with unraid and while I love the uncomplicated usage of docker on unraid I really, really miss a possibility to make live snapshots/backups of my vm's. I use jtok's script but I think something like this must be integrated in unraid.







