




mihcox
Members
-
Joined
-
Last visited
Everything posted by mihcox
-
root@BigRig:~# /usr/bin/upsc [email protected] Error: Unknown UPS
-
does not show for me:


 I have updated to the new plugin, restaretd both by settings to no, then yes again and dont see any stats for the UPS in controlr. Where should they be?OUT OF MEMORY ERRORS detected on my server, diagnostics attached as recommended from fix common problems tool precisionrig-diagnostics-20240306-1556.zipEven though it didnt show up, i was still able to access it with the correct ip. all is good now, thanks againThis resolved the issue of them being seen by unraid, thanks for that. I can now ping the machines from each other, but i cannot find them in unassigned devices. Any suggestions for how to resolve this? They only see themselves in the unassigned devices list using smb.
I have updated to the new plugin, restaretd both by settings to no, then yes again and dont see any stats for the UPS in controlr. Where should they be?OUT OF MEMORY ERRORS detected on my server, diagnostics attached as recommended from fix common problems tool precisionrig-diagnostics-20240306-1556.zipEven though it didnt show up, i was still able to access it with the correct ip. all is good now, thanks againThis resolved the issue of them being seen by unraid, thanks for that. I can now ping the machines from each other, but i cannot find them in unassigned devices. Any suggestions for how to resolve this? They only see themselves in the unassigned devices list using smb.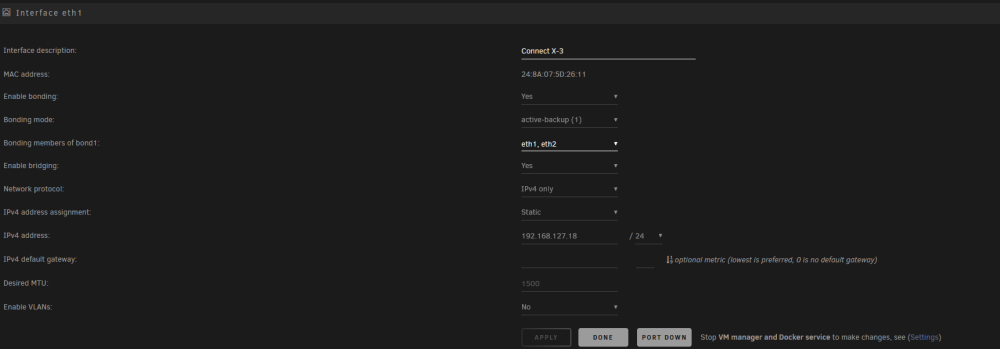
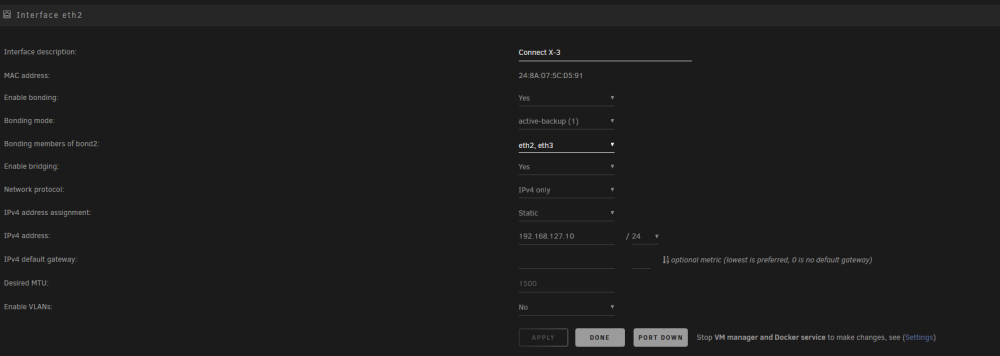
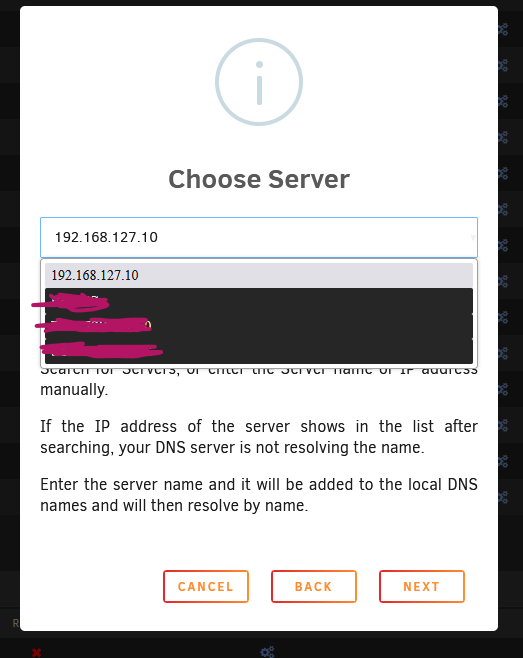
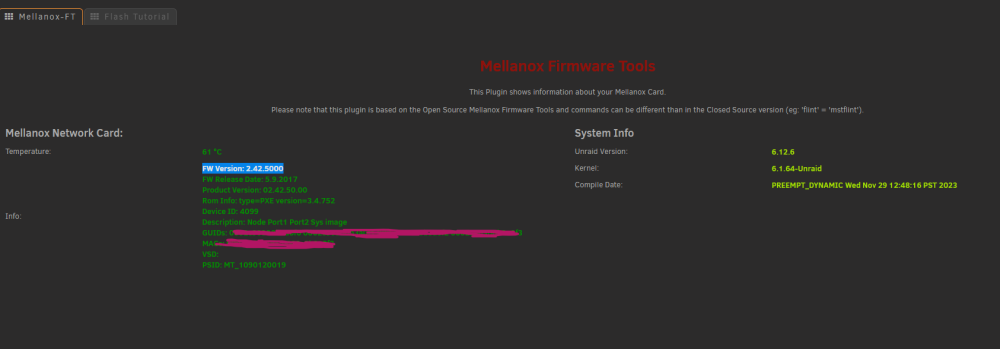
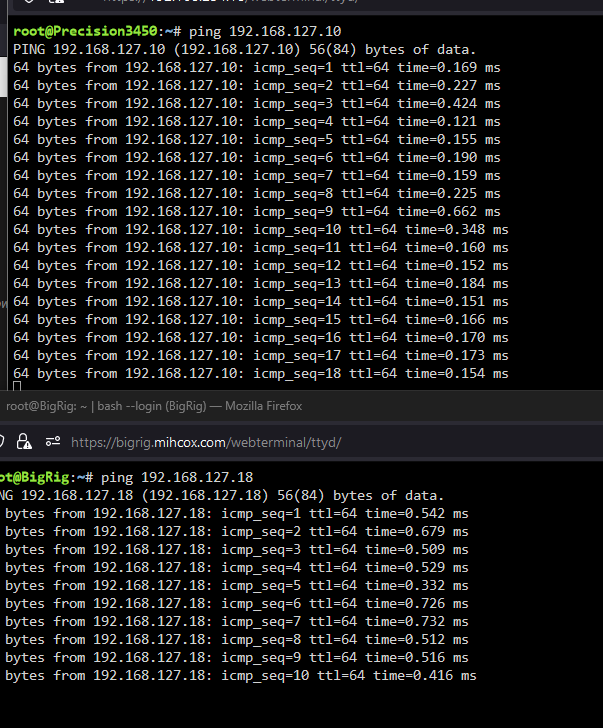 I just bought a couple of connect x-3 cards, MCX354A-FCBT, which report as [15b3:1003] 01:00.0 Network controller: Mellanox Technologies MT27500 Family [ConnectX-3] in unraid, and Mellanox connect x-3 IPoIB adapter in windows. I have updated the firmwares to the latest FW Version: 2.42.5000. But i cannot seem to change them to ethernet mode. When runing mst status on windows i get No MST devices found, and when running the mstconfig -d 62:00.0 q, i get Unsupported device Any suggestions on how to resolve this? precision3450-diagnostics-20240203-0214.zip
I just bought a couple of connect x-3 cards, MCX354A-FCBT, which report as [15b3:1003] 01:00.0 Network controller: Mellanox Technologies MT27500 Family [ConnectX-3] in unraid, and Mellanox connect x-3 IPoIB adapter in windows. I have updated the firmwares to the latest FW Version: 2.42.5000. But i cannot seem to change them to ethernet mode. When runing mst status on windows i get No MST devices found, and when running the mstconfig -d 62:00.0 q, i get Unsupported device Any suggestions on how to resolve this? precision3450-diagnostics-20240203-0214.zip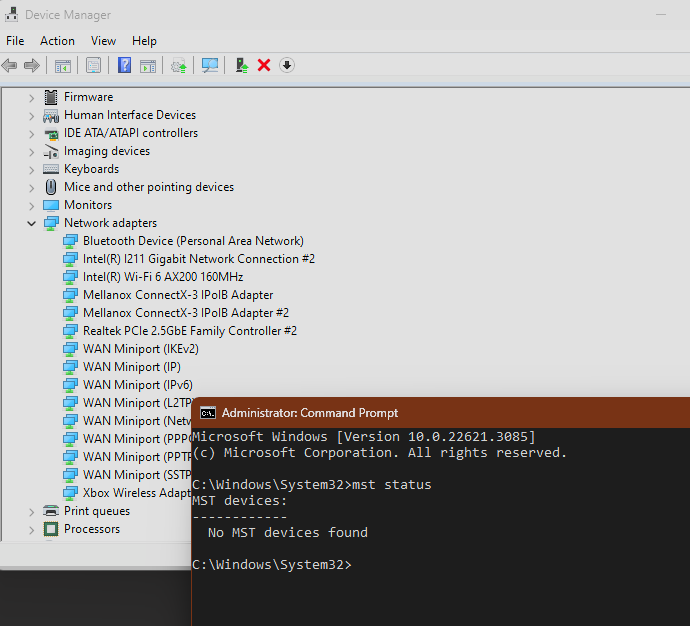
 Thank you, ill look into purchasing a few of theseresolved by resetting the settings from inside the gui from tower.localI am having an issue where logging in via the gui doesnt work, nor does logging in via SSH, but logging in via the console directly or via tower.local works without issue. Diagnostics attached. tower-diagnostics-20240123-1426.zipYes, so the difference is in the machines where it is working, i have an I217-LM intel NIC as the main connection, but in the ones where its failing its an I219-LM NIC. This means it is some sort of kernel/driver issue i guess? I had purchased an x520-DA2 because it was seemed to work easily. Is there another suggestion for cheap 10GB NICs, with 1 and 2 ports?ubuntu 20.04.3
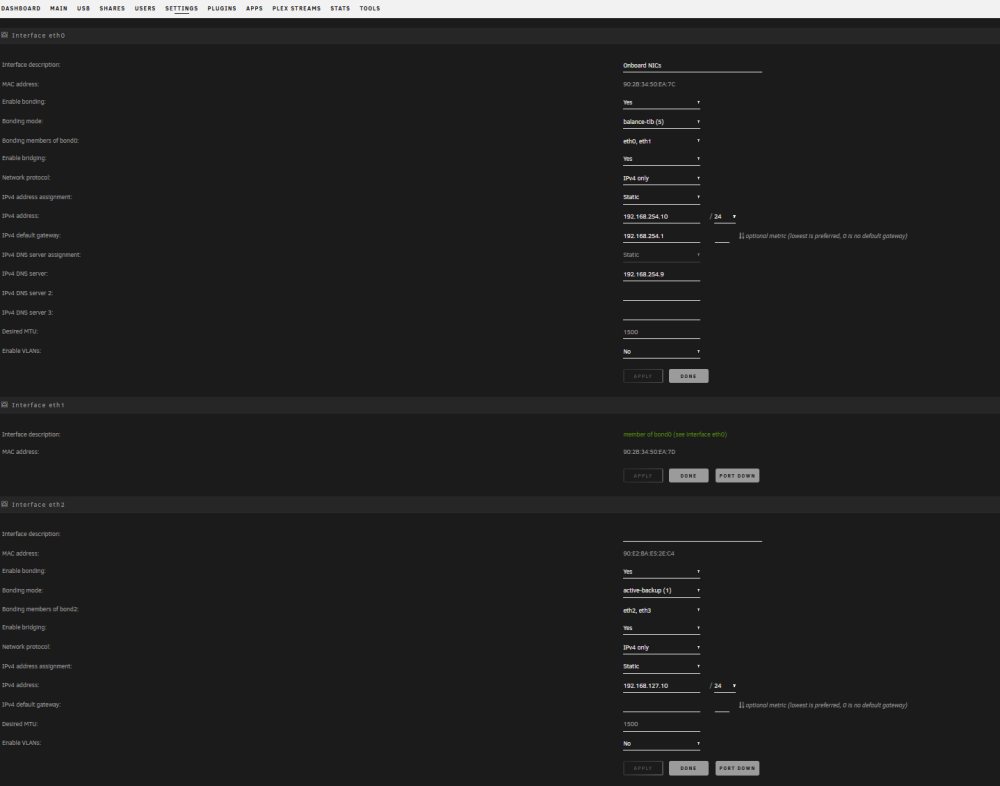
Thank you, ill look into purchasing a few of theseresolved by resetting the settings from inside the gui from tower.localI am having an issue where logging in via the gui doesnt work, nor does logging in via SSH, but logging in via the console directly or via tower.local works without issue. Diagnostics attached. tower-diagnostics-20240123-1426.zipYes, so the difference is in the machines where it is working, i have an I217-LM intel NIC as the main connection, but in the ones where its failing its an I219-LM NIC. This means it is some sort of kernel/driver issue i guess? I had purchased an x520-DA2 because it was seemed to work easily. Is there another suggestion for cheap 10GB NICs, with 1 and 2 ports?ubuntu 20.04.3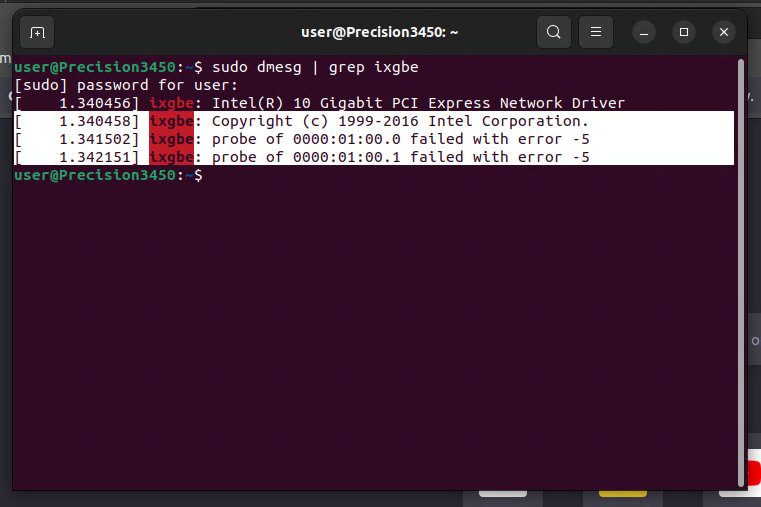 Same issue in ubuntu 20.04.3, what does that indicate? I tried that with mine, but when the server restarts it deletes the file. How are you generating it?Just installed windows on the same machine, and had no issues adding the drivers for the x520. It seems like it isnt a hardware issue, but is unraid specific as it works with windows.yes, thats probably why the one i was creating was getting deleted. Tried in both slots, x16 and x4 with the same result. Seen in the bios, and in devices, but not on the network tab. This is unfortunately not very helpfulThis did not help, after formatting it like the below, it was deleted after rebooting. SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="b0:4f:13:11:06:70", ATTR{dev_id}=="0x0", ATTR{type}=="1", KERNEL=="eth*", NAME="eth0" SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="90:e2:ba:ea:71:18", ATTR{dev_id}=="0x0", ATTR{type}=="1", KERNEL=="eth*", NAME="eth1" SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="90:e2:ba:ea:71:19", ATTR{dev_id}=="0x0", ATTR{type}=="1", KERNEL=="eth*", NAME="eth2"Any suggestion on how to get them to initialize? I have the same 10gb nic working in another unraid server without issueattaching diagnosticsprecision3450-diagnostics-20240118-2301.zipBumping this. I noticed that the server with the issue does not have a network-rules.cfg file generated while the server that is working does. Any suggestions on how to fix this?I have installed 2 10gb nics, both in different unraid servers, to try and directly connect them. My older box shows the new nics in the network panel, but the precision3450 does something different. It show the devices in system devices: But they do not show up on the network page as expected: Working computer same views:
Same issue in ubuntu 20.04.3, what does that indicate? I tried that with mine, but when the server restarts it deletes the file. How are you generating it?Just installed windows on the same machine, and had no issues adding the drivers for the x520. It seems like it isnt a hardware issue, but is unraid specific as it works with windows.yes, thats probably why the one i was creating was getting deleted. Tried in both slots, x16 and x4 with the same result. Seen in the bios, and in devices, but not on the network tab. This is unfortunately not very helpfulThis did not help, after formatting it like the below, it was deleted after rebooting. SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="b0:4f:13:11:06:70", ATTR{dev_id}=="0x0", ATTR{type}=="1", KERNEL=="eth*", NAME="eth0" SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="90:e2:ba:ea:71:18", ATTR{dev_id}=="0x0", ATTR{type}=="1", KERNEL=="eth*", NAME="eth1" SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="90:e2:ba:ea:71:19", ATTR{dev_id}=="0x0", ATTR{type}=="1", KERNEL=="eth*", NAME="eth2"Any suggestion on how to get them to initialize? I have the same 10gb nic working in another unraid server without issueattaching diagnosticsprecision3450-diagnostics-20240118-2301.zipBumping this. I noticed that the server with the issue does not have a network-rules.cfg file generated while the server that is working does. Any suggestions on how to fix this?I have installed 2 10gb nics, both in different unraid servers, to try and directly connect them. My older box shows the new nics in the network panel, but the precision3450 does something different. It show the devices in system devices: But they do not show up on the network page as expected: Working computer same views:
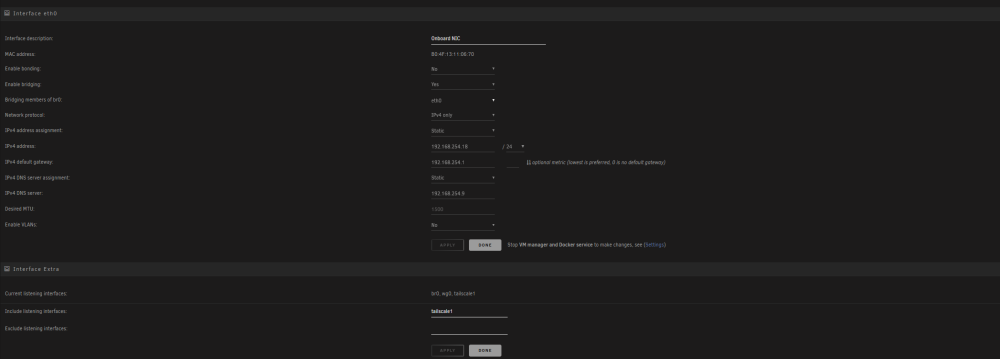
 is this near expected speeds. Supermicro 846 with a collection of 4-18TB drives
is this near expected speeds. Supermicro 846 with a collection of 4-18TB drives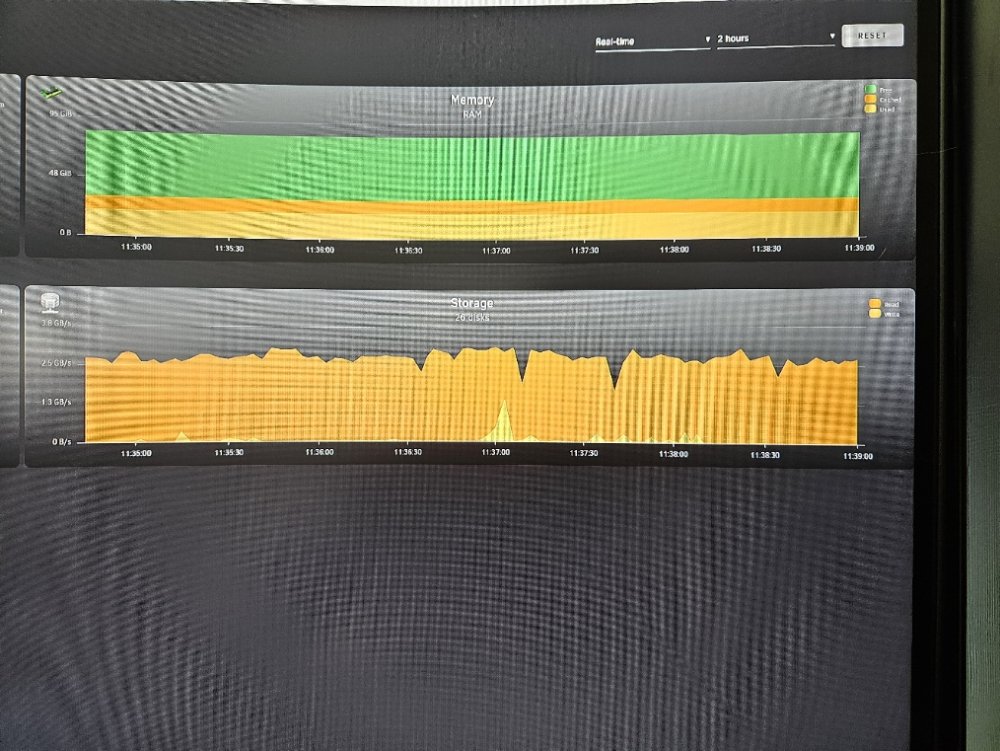 I found the command, but I am still seeing a downgraded rating. Any suggestions? lspci -d 1000: -vv 05:00.0 Serial Attached SCSI controller: Broadcom / LSI SAS3008 PCI-Express Fusion-MPT SAS-3 (rev 02) Subsystem: Broadcom / LSI SAS3008 PCI-Express Fusion-MPT SAS-3 Control: I/O+ Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr+ Stepping- SERR+ FastB2B- DisINTx+ Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- INTx- Latency: 0, Cache Line Size: 64 bytes Interrupt: pin A routed to IRQ 218 NUMA node: 0 IOMMU group: 52 Region 0: I/O ports at 6000 Region 1: Memory at dec40000 (64-bit, non-prefetchable) Region 3: Memory at dec00000 (64-bit, non-prefetchable) Expansion ROM at deb00000 [disabled] Capabilities: [50] Power Management version 3 Flags: PMEClk- DSI- D1+ D2+ AuxCurrent=0mA PME(D0-,D1-,D2-,D3hot-,D3cold-) Status: D0 NoSoftRst+ PME-Enable- DSel=0 DScale=0 PME- Capabilities: [68] Express (v2) Endpoint, MSI 00 DevCap: MaxPayload 4096 bytes, PhantFunc 0, Latency L0s <64ns, L1 <1us ExtTag+ AttnBtn- AttnInd- PwrInd- RBE+ FLReset+ SlotPowerLimit 0W DevCtl: CorrErr- NonFatalErr+ FatalErr+ UnsupReq- RlxdOrd+ ExtTag+ PhantFunc- AuxPwr- NoSnoop+ FLReset- MaxPayload 256 bytes, MaxReadReq 512 bytes DevSta: CorrErr- NonFatalErr- FatalErr- UnsupReq- AuxPwr- TransPend+ LnkCap: Port #0, Speed 8GT/s, Width x8, ASPM not supported ClockPM- Surprise- LLActRep- BwNot- ASPMOptComp+ LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+ ExtSynch- ClockPM- AutWidDis- BWInt- AutBWInt- LnkSta: Speed 8GT/s, Width x4 (downgraded) TrErr- Train- SlotClk+ DLActive- BWMgmt- ABWMgmt- DevCap2: Completion Timeout: Range BC, TimeoutDis+ NROPrPrP- LTR- 10BitTagComp- 10BitTagReq- OBFF Not Supported, ExtFmt- EETLPPrefix- EmergencyPowerReduction Not Supported, EmergencyPowerReductionInit- FRS- TPHComp- ExtTPHComp- AtomicOpsCap: 32bit- 64bit- 128bitCAS- DevCtl2: Completion Timeout: 50us to 50ms, TimeoutDis- LTR- 10BitTagReq- OBFF Disabled, AtomicOpsCtl: ReqEn- LnkCap2: Supported Link Speeds: 2.5-8GT/s, Crosslink- Retimer- 2Retimers- DRS- LnkCtl2: Target Link Speed: 8GT/s, EnterCompliance- SpeedDis- Transmit Margin: Normal Operating Range, EnterModifiedCompliance- ComplianceSOS- Compliance Preset/De-emphasis: -6dB de-emphasis, 0dB preshoot LnkSta2: Current De-emphasis Level: -6dB, EqualizationComplete+ EqualizationPhase1+ EqualizationPhase2+ EqualizationPhase3+ LinkEqualizationRequest- Retimer- 2Retimers- CrosslinkRes: unsupported Capabilities: [a8] MSI: Enable- Count=1/1 Maskable+ 64bit+ Address: 0000000000000000 Data: 0000 Masking: 00000000 Pending: 00000000 Capabilities: [c0] MSI-X: Enable+ Count=96 Masked- Vector table: BAR=1 offset=0000e000 PBA: BAR=1 offset=0000f000 Capabilities: [100 v2] Advanced Error Reporting UESta: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- UnxCmplt- RxOF- MalfTLP- ECRC- UnsupReq- ACSViol- UEMsk: DLP+ SDES- TLP- FCP+ CmpltTO+ CmpltAbrt+ UnxCmplt+ RxOF+ MalfTLP+ ECRC+ UnsupReq+ ACSViol- UESvrt: DLP+ SDES+ TLP- FCP+ CmpltTO- CmpltAbrt- UnxCmplt- RxOF+ MalfTLP+ ECRC- UnsupReq- ACSViol- CESta: RxErr- BadTLP- BadDLLP- Rollover- Timeout- AdvNonFatalErr- CEMsk: RxErr+ BadTLP+ BadDLLP+ Rollover+ Timeout+ AdvNonFatalErr+ AERCap: First Error Pointer: 00, ECRCGenCap+ ECRCGenEn- ECRCChkCap+ ECRCChkEn- MultHdrRecCap- MultHdrRecEn- TLPPfxPres- HdrLogCap- HeaderLog: 00000000 00000000 00000000 00000000 Capabilities: [1e0 v1] Secondary PCI Express LnkCtl3: LnkEquIntrruptEn- PerformEqu- LaneErrStat: 0 Capabilities: [1c0 v1] Power Budgeting <?> Capabilities: [190 v1] Dynamic Power Allocation <?> Capabilities: [148 v1] Alternative Routing-ID Interpretation (ARI) ARICap: MFVC- ACS-, Next Function: 0 ARICtl: MFVC- ACS-, Function Group: 0 Kernel driver in use: mpt3sas Kernel modules: mpt3sasI just installed a new 9300 HBA in my server. I had found a command that can be run from the command line that will output the link speed of the HBA to ensure its connection is not degraded. But i dont seem to be able to locate that forum. It helped me find out that my oboard SAS was running a degraded link, was hoping to ensure thats not the ase now Output looked something like this: # fcinfo hba-port HBA Port WWN: 10000000c6789451 OS Device Name: /dev/cfg/c2 Manufacturer: Emulex Model: LPe11000-S Firmware Version: 2.80a4 (Z3D2.80A4) FCode/BIOS Version: ......... Serial Number: ........................... Driver Name: emlxs Driver Version: 2.31o (2008.10.20.14.00) Type: unknown State: offline Supported Speeds: 1Gb 2Gb 4Gb Current Speed: not established Node WWN: ........................... HBA Port WWN: 10000000c7643890 OS Device Name: /dev/cfg/c1 Manufacturer: Emulex Model: LPe11000-S Firmware Version: 2.80a4 (Z3D2.80A4) FCode/BIOS Version: ......... Serial Number: ...................... Driver Name: emlxs Driver Version: 2.31o (2008.10.20.14.00) Type: unknown State: offline Supported Speeds: 1Gb 2Gb 4Gb Current Speed: not established Node WWN: ..............................Would another solution be to keep all my "import files" or downloads on the evocachepool ONLY, then use the my regular process to move them to the movies folder structure, then let them offload to the array?
I found the command, but I am still seeing a downgraded rating. Any suggestions? lspci -d 1000: -vv 05:00.0 Serial Attached SCSI controller: Broadcom / LSI SAS3008 PCI-Express Fusion-MPT SAS-3 (rev 02) Subsystem: Broadcom / LSI SAS3008 PCI-Express Fusion-MPT SAS-3 Control: I/O+ Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr+ Stepping- SERR+ FastB2B- DisINTx+ Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- INTx- Latency: 0, Cache Line Size: 64 bytes Interrupt: pin A routed to IRQ 218 NUMA node: 0 IOMMU group: 52 Region 0: I/O ports at 6000 Region 1: Memory at dec40000 (64-bit, non-prefetchable) Region 3: Memory at dec00000 (64-bit, non-prefetchable) Expansion ROM at deb00000 [disabled] Capabilities: [50] Power Management version 3 Flags: PMEClk- DSI- D1+ D2+ AuxCurrent=0mA PME(D0-,D1-,D2-,D3hot-,D3cold-) Status: D0 NoSoftRst+ PME-Enable- DSel=0 DScale=0 PME- Capabilities: [68] Express (v2) Endpoint, MSI 00 DevCap: MaxPayload 4096 bytes, PhantFunc 0, Latency L0s <64ns, L1 <1us ExtTag+ AttnBtn- AttnInd- PwrInd- RBE+ FLReset+ SlotPowerLimit 0W DevCtl: CorrErr- NonFatalErr+ FatalErr+ UnsupReq- RlxdOrd+ ExtTag+ PhantFunc- AuxPwr- NoSnoop+ FLReset- MaxPayload 256 bytes, MaxReadReq 512 bytes DevSta: CorrErr- NonFatalErr- FatalErr- UnsupReq- AuxPwr- TransPend+ LnkCap: Port #0, Speed 8GT/s, Width x8, ASPM not supported ClockPM- Surprise- LLActRep- BwNot- ASPMOptComp+ LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+ ExtSynch- ClockPM- AutWidDis- BWInt- AutBWInt- LnkSta: Speed 8GT/s, Width x4 (downgraded) TrErr- Train- SlotClk+ DLActive- BWMgmt- ABWMgmt- DevCap2: Completion Timeout: Range BC, TimeoutDis+ NROPrPrP- LTR- 10BitTagComp- 10BitTagReq- OBFF Not Supported, ExtFmt- EETLPPrefix- EmergencyPowerReduction Not Supported, EmergencyPowerReductionInit- FRS- TPHComp- ExtTPHComp- AtomicOpsCap: 32bit- 64bit- 128bitCAS- DevCtl2: Completion Timeout: 50us to 50ms, TimeoutDis- LTR- 10BitTagReq- OBFF Disabled, AtomicOpsCtl: ReqEn- LnkCap2: Supported Link Speeds: 2.5-8GT/s, Crosslink- Retimer- 2Retimers- DRS- LnkCtl2: Target Link Speed: 8GT/s, EnterCompliance- SpeedDis- Transmit Margin: Normal Operating Range, EnterModifiedCompliance- ComplianceSOS- Compliance Preset/De-emphasis: -6dB de-emphasis, 0dB preshoot LnkSta2: Current De-emphasis Level: -6dB, EqualizationComplete+ EqualizationPhase1+ EqualizationPhase2+ EqualizationPhase3+ LinkEqualizationRequest- Retimer- 2Retimers- CrosslinkRes: unsupported Capabilities: [a8] MSI: Enable- Count=1/1 Maskable+ 64bit+ Address: 0000000000000000 Data: 0000 Masking: 00000000 Pending: 00000000 Capabilities: [c0] MSI-X: Enable+ Count=96 Masked- Vector table: BAR=1 offset=0000e000 PBA: BAR=1 offset=0000f000 Capabilities: [100 v2] Advanced Error Reporting UESta: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- UnxCmplt- RxOF- MalfTLP- ECRC- UnsupReq- ACSViol- UEMsk: DLP+ SDES- TLP- FCP+ CmpltTO+ CmpltAbrt+ UnxCmplt+ RxOF+ MalfTLP+ ECRC+ UnsupReq+ ACSViol- UESvrt: DLP+ SDES+ TLP- FCP+ CmpltTO- CmpltAbrt- UnxCmplt- RxOF+ MalfTLP+ ECRC- UnsupReq- ACSViol- CESta: RxErr- BadTLP- BadDLLP- Rollover- Timeout- AdvNonFatalErr- CEMsk: RxErr+ BadTLP+ BadDLLP+ Rollover+ Timeout+ AdvNonFatalErr+ AERCap: First Error Pointer: 00, ECRCGenCap+ ECRCGenEn- ECRCChkCap+ ECRCChkEn- MultHdrRecCap- MultHdrRecEn- TLPPfxPres- HdrLogCap- HeaderLog: 00000000 00000000 00000000 00000000 Capabilities: [1e0 v1] Secondary PCI Express LnkCtl3: LnkEquIntrruptEn- PerformEqu- LaneErrStat: 0 Capabilities: [1c0 v1] Power Budgeting <?> Capabilities: [190 v1] Dynamic Power Allocation <?> Capabilities: [148 v1] Alternative Routing-ID Interpretation (ARI) ARICap: MFVC- ACS-, Next Function: 0 ARICtl: MFVC- ACS-, Function Group: 0 Kernel driver in use: mpt3sas Kernel modules: mpt3sasI just installed a new 9300 HBA in my server. I had found a command that can be run from the command line that will output the link speed of the HBA to ensure its connection is not degraded. But i dont seem to be able to locate that forum. It helped me find out that my oboard SAS was running a degraded link, was hoping to ensure thats not the ase now Output looked something like this: # fcinfo hba-port HBA Port WWN: 10000000c6789451 OS Device Name: /dev/cfg/c2 Manufacturer: Emulex Model: LPe11000-S Firmware Version: 2.80a4 (Z3D2.80A4) FCode/BIOS Version: ......... Serial Number: ........................... Driver Name: emlxs Driver Version: 2.31o (2008.10.20.14.00) Type: unknown State: offline Supported Speeds: 1Gb 2Gb 4Gb Current Speed: not established Node WWN: ........................... HBA Port WWN: 10000000c7643890 OS Device Name: /dev/cfg/c1 Manufacturer: Emulex Model: LPe11000-S Firmware Version: 2.80a4 (Z3D2.80A4) FCode/BIOS Version: ......... Serial Number: ...................... Driver Name: emlxs Driver Version: 2.31o (2008.10.20.14.00) Type: unknown State: offline Supported Speeds: 1Gb 2Gb 4Gb Current Speed: not established Node WWN: ..............................Would another solution be to keep all my "import files" or downloads on the evocachepool ONLY, then use the my regular process to move them to the movies folder structure, then let them offload to the array?
















