




optiman
Members
-
Joined
-
Last visited
Everything posted by optiman
-
Here you go. tower-diagnostics-20210923-1551.zip
-
When I try to Check For Updates on the Docker page, each docker just spins forever. I see this error in the syslog Sep 23 15:43:25 Tower nginx: 2021/09/23 15:43:25 [error] 8444#8444: *269827 upstream timed out (110: Connection timed out) while reading response header from upstream, client: 10.11.79.248, server: , request: "POST /plugins/dynamix.docker.manager/include/DockerUpdate.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock", host: "10.11.79.162", referrer: "http://10.11.79.162/Docker" Any ideas?
-
Ok, changed it back and restarted the Docker service, and again when I check for updates, same thing, just spins and times out. wtf Sep 23 15:43:25 Tower nginx: 2021/09/23 15:43:25 [error] 8444#8444: *269827 upstream timed out (110: Connection timed out) while reading response header from upstream, client: 10.11.79.248, server: , request: "POST /plugins/dynamix.docker.manager/include/DockerUpdate.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock", host: "10.11.79.162", referrer: "http://10.11.79.162/Docker" As suggested, I started a new topic
-
crap, no I didn't realize I would need to go back and change that file. Will try that right now. Thanks!
-
I ran a parity check and it just finished without any errors. syslog looks good. I would guess that I would already see errors if I was going to have the issue. Thanks!
-
Please - any idea how I can fix the docker update issue? I thought this was supposed to be fixed in the latest version, but clearly it is not. I can force an update and then it will say it's Up to Date. But the auto run check (daily) and hitting the Check For Updates do not work. Is this the wrong place to ask for help for this issue?
-
upgraded to 6.9.2 and still the docker update issue continues Sep 22 19:02:26 Tower nginx: 2021/09/22 19:02:26 [error] 8444#8444: *6597 upstream timed out (110: Connection timed out) while reading response header from upstream, client: 10.11.79.248, server: , request: "POST /plugins/dynamix.docker.manager/include/DockerUpdate.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock", host: "10.11.79.162", referrer: "http://10.11.79.162/Docker"
-
wish me luck, upgraded and praying no issues.....
-
thanks guys! My issue is that the instructions to disable the lowcurrentspinup did not work for me on any of my drives. Even after cold boot, they show that feature is still enabled. Weird because after issuing the command, it says it successfully disabled that feature and a reboot is required, yet the feature is still enabled. I guess I will just have to take a chance and upgrade. So what should I watch for? Errors in the syslog, disk log, SMART log? Will the main screen show the errors counting up? And if I do see errors, what should I do, roll back ASAP. I don't want to loose data. Thanks!
-
I was hoping for some advice here. Anyone running these drives with lowcurrentspinup enabled and have upgraded to 6.9.2 without issues? I cannot figure out how to disable that one. EPC is disabled.
-
shutdown again, unplugged the power cord and waited 15 min. Booted and check all 10 drives, all still have the lowcurrentspinup enabled While the tool seemed to work, it clearly did not and no errors. Should I upgrade to 6.9.2 or not?
-
I decided to try the fix so that I can upgrade to the latest unraid version. I followed the instructions exactly and each time I saw a response saying that lowpowerspinup was disabled. it also says you have to reboot to take effect. I did this on all 10 of my seagate drives. I cold booted and went back to confirm and none of them are disabled, all show lowcurrentspinup enabled. I even turned off my power supply switch. The only thing I didn't try was unplugging the power cord from the power supply. The EPC steps worked fine and all 10 show disabled now. I'm worried about trying the 6.9.2 upgrade while the lowcurrentspinup is still enabled. I didn't get any errors and the seachest version I used was SeaChest_Configure_1170_11923_64 Drive models are ST12000NE0008 and ST8000NM0055 Any ideas?
-
I was able to change the file and copy it over the existing file. I copied to a user share using MC, then to my pc and used Notepad++ Here is what my line 457 looks like" preg_match('@Docker-Content-Digest:\s*(.*)@i', $reply, $matches); I then copied the updated file back to my user share and then again used MC to copy it / overwrite the existing. I then enabled Docker in Settings and tried again. It did not help. Do i need to reboot? Rebooted and it seems to be back to normal now. Thanks!
-
I tried this and I get Access Denied when I try to save it. I've disabled Docker in Settings. How did you get around that?
-
All of my dockers are no longer able to check for updates and when I chick on the button to Check, they all spin for a long time and then it times out. Something has changed. I can do a Force update and those work fine. Any idea why this is happening? error in syslog: Sep 17 07:48:54 Tower nginx: 2021/09/17 07:48:54 [error] 8396#8396: *911273 upstream timed out (110: Connection timed out) while reading response header from upstream, client: 10.11.79.248, server: , request: "POST /plugins/dynamix.docker.manager/include/DockerUpdate.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock", host: "10.11.79.162", referrer: "http://10.11.79.162/Docker"
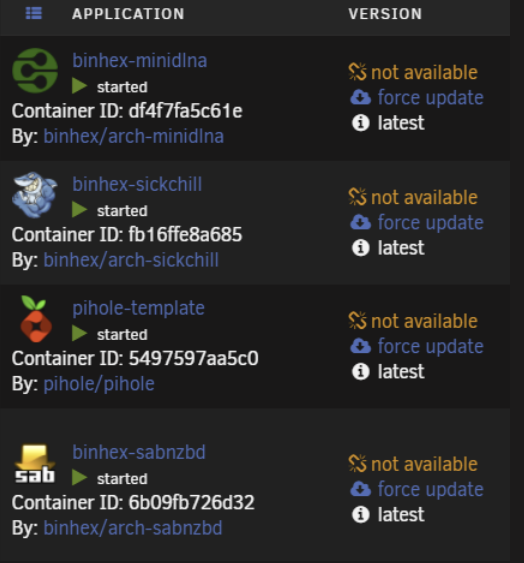
-
@binhex All of my dockers are no longer able to check for updates and when I chick on the button to Check, they all spin for a long time and then it times out. Something has changed. I can do a Force update and those work fine. Any idea why this is happening? error in syslog: Sep 17 07:48:54 Tower nginx: 2021/09/17 07:48:54 [error] 8396#8396: *911273 upstream timed out (110: Connection timed out) while reading response header from upstream, client: 10.11.79.248, server: , request: "POST /plugins/dynamix.docker.manager/include/DockerUpdate.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock", host: "10.11.79.162", referrer: "http://10.11.79.162/Docker" Sep 17 07:48:54 Tower nginx: 2021/09/17 07:48:54 [error] 8396#8396: *911273 upstream timed out (110: Connection timed out) while reading response header from upstream, client: 10.11.79.248, server: , request: "POST /plugins/dynamix.docker.manager/include/DockerUpdate.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock", host: "10.11.79.162", referrer: "http://10.11.79.162/Docker"
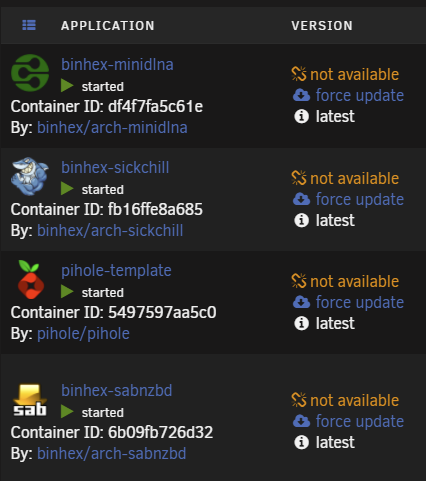
-
I had this docker installed for a long time and it worked great. I had to rebuild my docker image file and re-install my apps and found that this will not install now. When I click on the Install icon, this is what I see; After hitting Apply, I get the follow errors; IMAGE ID [1896728381]: Pulling from binhex/arch-tvheadend. IMAGE ID [3b4c5248da92]: Pulling fs layer. Downloading 100% of 263 B. Verifying Checksum. Download complete. Extracting. Pull complete. IMAGE ID [684482506bb1]: Pulling fs layer. Downloading 100% of 2 KB. Verifying Checksum. Download complete. Extracting. Pull complete. IMAGE ID [039d9be946ba]: Pulling fs layer. Downloading 100% of 656 KB. Verifying Checksum. Download complete. Extracting. Pull complete. IMAGE ID [f0784c3ceec3]: Pulling fs layer. Downloading 100% of 5 KB. Verifying Checksum. Extracting. Pull complete. IMAGE ID [be2ac6bab66e]: Pulling fs layer. Downloading 100% of 170 MB. Verifying Checksum. Download complete. Extracting. Pull complete. IMAGE ID [e554bfb17b98]: Pulling fs layer. Downloading 100% of 292 B. Verifying Checksum. Download complete. Extracting. Pull complete. IMAGE ID [bf5a1987e1d2]: Pulling fs layer. Downloading 100% of 2 KB. Download complete. Extracting. Pull complete. IMAGE ID [7c4efb200f59]: Pulling fs layer. Downloading 100% of 187 MB. Verifying Checksum. Download complete. Extracting. Pull complete. Status: Downloaded newer image for binhex/arch-tvheadend:latest TOTAL DATA PULLED: 358 MB root@localhost:# /usr/local/emhttp/plugins/dynamix.docker.manager/scripts/docker run -d --name='binhex-tvheadend' --net='bridge' --privileged=true -e TZ="America/Los_Angeles" -e HOST_OS="Unraid" -e 'UMASK'='000' -e 'PUID'='99' -e 'PGID'='100' -p '9981:9981/tcp' -p '9982:9982/tcp' -v '/mnt/user/HDHomeRun/':'/data':'rw' -v '/mnt/user/Automation/Apps/binhex-tvheadend':'/config':'rw' --device=/dev/tuner type 'binhex/arch-tvheadend:latest' Unable to find image 'type:latest' locally /usr/bin/docker: Error response from daemon: pull access denied for type, repository does not exist or may require 'docker login': denied: requested access to the resource is denied. See '/usr/bin/docker run --help'. The command failed. Help please
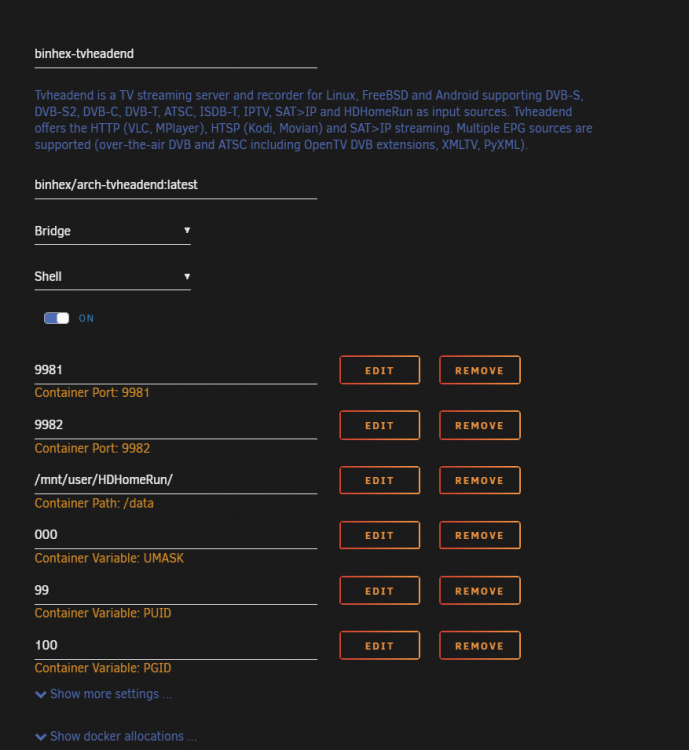
-
I tried to start the Docker, and again it says it cannot start. I went ahead and grabbed the diag file again so you can see that part in the log. tower-diagnostics-20210910-1725.zip
-
rebuild complete and it looks like everything is ok. Should I check or test anything else? I never did find any route cause as to why both of those drives were disabled. Diag file attached. The weird thing is it took forever to collect the diag info, so I hit Done and did it again, and it worked normal, took 10 seconds. I'll now try to sort out what is going on with my docker not starting. Thanks again! tower-diagnostics-20210910-1722.zip
-
ok that's great to news! I've followed those instructions and it is rebuilding both disk2 and the parity drives right now. Once finished, I will post the diag file again and report back. Thank you!!!
-
diag file attached. I downloaded it right after I booted up the server. tower-diagnostics-20210909-1631.zip
-
we lost power and my server auto shutdown when the ups got low. So I just booted it back up. I lost the system log. Next time I will dl the diag file right after each step. I'm guessing you don't want the current one, as I just booted up. What is the next step? Thank you so much for helping!
-
Ok, ran the repair and this was the output Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... ALERT: The filesystem has valuable metadata changes in a log which is being destroyed because the -L option was used. - scan filesystem freespace and inode maps... sb_icount 34816, counted 480192 sb_ifree 243, counted 251 sb_fdblocks 245643713, counted 791827383 - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 2 - agno = 1 - agno = 6 - agno = 5 - agno = 4 - agno = 3 - agno = 7 - agno = 8 - agno = 9 - agno = 10 Phase 5 - rebuild AG headers and trees... - reset superblock... Phase 6 - check inode connectivity... - resetting contents of realtime bitmap and summary inodes - traversing filesystem ... - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify and correct link counts... Maximum metadata LSN (2:880019) is ahead of log (1:2). Format log to cycle 5. done I did have to use the -L I then restarted and the drive was still disabled What should I try next?
-
dam, the file overwrote the first one, not my day. I will try to Repair disk 2 as you suggested
-
I dl the diag file first thing in the morning before I rebooted, so I have the previous logs, see attached. tower-diagnostics-20210907-0859.zip



