




optiman
Members
-
Joined
-
Last visited
Everything posted by optiman
-
is there a easy way to check and see what version of perl I have install, if any (without going through the logs)? Not sure what version we should be using with unraid v6 and these plugins. I'm thinking I have the wrong version and perhaps that is why I cannot get the AutoFan to Detect anything.
-
Still no luck in getting the auto fan thing to work. Any ideas?
-
First time ever trying to use AutoFan and I get nothing from the console commands and Detect does not work. Looks like I need the drivers for my mb. Anyone with my same board have the drivers that you can share? Where can I find help with the autofan plugin?
-
Thank you. It's working now. I found in this thread about typing in coretemp --> Save and then it let me configure them. Thanks for the tip on Perl though. Oh well, it's working so Miller Time! I now see the temps at the lower right hand corner. Before upgrading to ver 6, I had the plugin, sensors file, supporting GO file entries - so Temps was working before I upgraded. I thought the upgrade process wiped out all extra packages so I'm curious how come I didn't need to install Perl. Oh well, it's working and nice to see the temps again - especially given it's 101 F outside right now.
-
I installed the system temp plugin, but when I click on Detect, nothing happens. My hw info is in my sig. Any ideas?
-
Nice job! Plugin install worked, once I renamed the script file.
-
nope - the link just takes you back to the thread. There is a video for OwnCould ,which is actually a video. The other link is just that, only a link. Where is the video on how to setup docker?
-
wow, cool that v6 is out and I'm about to upgrade and try docker. This is a great thread. I wasn't able to find a video in this thread for setting up docker. It would be cool to see a video.' Thanks!
-
Bonienl - Can you please tell us if you are planning to update the System Temp plugin to include the new versions that Gary posted? I would rather wait and just use the Update button in the gui.
-
Use Notepad++ and edit your sensors.conf file and swape the temp1 and temp2 labels. For example, right now you have temp1 as mb and temp2 as cpu. Make temp1 cpu and temp 2 mb, save file and reboot. That should switch them in the gui.
-
glad it's working. I assume the temps look correct to you. Some people have to switch the labels around in sensors.conf so cpu is actually the cpu, etc. I didn't have to do that for mine. What is really awesome is the announcement that Dynamix will now be included with V6! That is so cool - this completes unraid IMO.
-
I could be wrong and you will want Bonienl to confirm, but I would not worry about saying YES to creating the config file. If it were me, I would just continue to step 8. Make sure your sensors.conf file is correct, edit your GO file and reboot.
-
Ok, first run sensors-detect on the console nad see if you get anything. if not sure what you are looking at, post the output here so we can see it. Look at my output, about 6 posts above as a reference. If you do get the output you are looking for, then you already have what you need to move to the next step. The reason it tells you to try it first is because other packages may have already installed perl or one of the other packages that will allow senors ro work. If you don't get the output you want, then simple locate the plugin on your boot (flash) drive and use Notepad++ to change the one line - replace don't install with do install. Save and reboot. Go back to step 6 and run sensors-detect again. If it now works, go to step 7. you use Notepadd++ as any other TEXT file editor. Just open Notepad++ and then open the plugin file, then scroll down until you find the line mentioned in step 6 and change it - save it and exit. Reboot and see if it works.
-
Have you read the first post in this thread, which tells you to go read the wiki? I think step 5 talks about what directory the plugin resides. Best if you read and follow the instructions in the wiki. Not sure if the wiki says this or not, but for my Windows rig I use Notepad++ to edit.
-
thanks, I'm on v5 so I guess this will need to wait. Does apache have the openssl conflicts with other packages like the dynamix one?
-
which webserver are you guys running? I was not able to get the dynamix one working and I couldn't get the help I needed to resolve it.
-
well I give up. I can't seem to get the dam web server to work, so I'll never get this plugin to work - just too much feakin effort. bye
-
Ok, put it back to 127.... still doesn't work. so I guess I got the phpvirtualbox unzipped correctly - meaning it shoudl be in a sub folder and not at the root of my web folder - right? for webserver, port 85. It looks like I stil have a issue with webserver, which is most likely why I can't get to vbox. on my console says I'm missing the php.ini file and I can't get to the webserver on any port. I've posted in that thread, asking for help. I'm sure I need to resolve the webserver issues before doing anything else. By the way, thank you very much for the work you've done and for the killer support - I really appreciate your help. Cheers
-
Ok, so my plugin wasn't setup all the way. For the plugin, what should the IP address be? I tried going to 127.0.0.1:18083 didn't work. Changed the IP to my server address, still didn't work. For the phpvirtualbox zip file, I unzipped here - which means it's in a sub folder in the web server directory - is that correct? cache/mnt/appdata/web/phpvirtualbox-4.3-1/
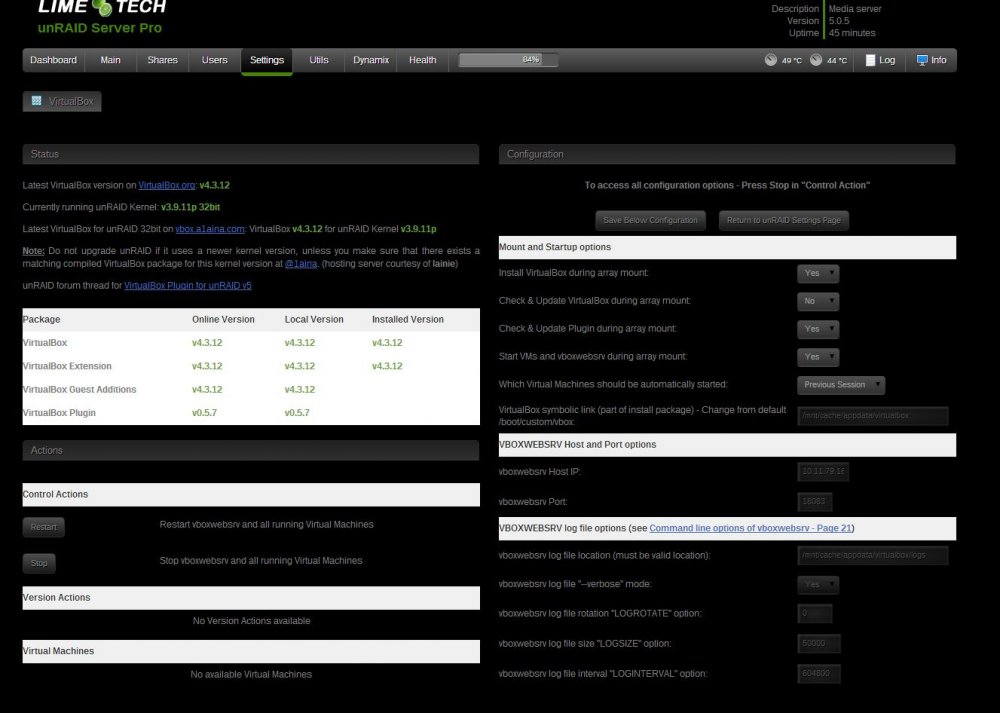
-
got it, thank you sir! in case anyone is looking for it, here is the link for 4.3.1 http://sourceforge.net/projects/phpvirtualbox/files/
-
Thanks theone! I didn't see that version on the site - can you kindly provide link? How about the instructions for installing it?
-
I got some time to play with this more, and I now have the plugin installed, of course that part is easy. I downloaded phpvirtualbox version 4.2-8 from here (haven't installed this yet, as I was not able to find instructions) http://sourceforge.net/projects/phpvirtualbox/ I'm running Dynamix so next I was going to install the webserver from the Dynamix tab. Looks like the current version is 2.1.0. I'm assuming this webserver will get the job done. Assuming I get the webserver installed next, how should I install phpvirtualbox? Should I just drop it in my /boot/packages/ directory and add the install line to my GO file? Once I get the above steps done, I'll then look for pre-setup vm for Win7.
-
I'm just getting started with setting up the sensors.conf file for my new rig. I have the Gigabyte GA-X58A-UD3R_rev2 motherboard. Does anyone else have this same MB and perhaps can share the config file to save me some time? Update: I was able to get this working. I've attached my sensors.conf file, in case anyone has my same MB. In addition, I share the output, in case I have done anything incorrectly. That said, the temps are showing up and they look to be correct. my sensors.conf: # sensors config for Gigabyte GA-X58A-UD3R_rev2 chip "it8720-isa-0290" label temp1 "CPU Temp" label temp2 "MB Temp" ignore temp3 chip "coretemp-isa-0000" My Go file: #!/bin/bash # Start the Management Utility /usr/local/sbin/emhttp & # Update Sensors Config cp /boot/custom/sensors.d/sensors.conf /etc/sensors.d/sensors.conf modprobe coretemp modprobe it87 /usr/bin/sensors -s sensors command line output: root@Tower:~# sensors coretemp-isa-0000 Adapter: ISA adapter Core 0: +46.0 C (high = +80.0 C, crit = +100.0 C) Core 1: +47.0 C (high = +80.0 C, crit = +100.0 C) Core 2: +48.0 C (high = +80.0 C, crit = +100.0 C) Core 3: +45.0 C (high = +80.0 C, crit = +100.0 C) it8720-isa-0290 Adapter: ISA adapter in0: +0.93 V (min = +0.00 V, max = +4.08 V) in1: +1.58 V (min = +0.00 V, max = +4.08 V) in2: +3.38 V (min = +0.00 V, max = +4.08 V) +5V: +3.01 V (min = +0.00 V, max = +4.08 V) in4: +0.34 V (min = +0.00 V, max = +4.08 V) in5: +3.10 V (min = +0.00 V, max = +4.08 V) in6: +0.08 V (min = +0.00 V, max = +4.08 V) 5VSB: +2.98 V (min = +0.00 V, max = +4.08 V) Vbat: +3.17 V fan1: 1885 RPM (min = 10 RPM) fan2: 1250 RPM (min = 0 RPM) fan3: 1730 RPM (min = 0 RPM) fan4: 1394 RPM (min = 0 RPM) CPU Temp: +48.0 C (low = +127.0 C, high = +127.0 C) sensor = thermistor MB Temp: +45.0 C (low = +127.0 C, high = +60.0 C) sensor = thermal diode intrusion0: ALARM root@Tower:~# Very nice to see temps again. sensors.conf
-
ah...ok. Please help me connect the dots here. Do complete instructions exist to fully setup and configure this plugin and VM's? I'm new to this, so if this will require a ton of time, I may have to pass on this for now. I was looking for a quick win so I could run a win7 vm on my unraid server, where I would host plex and other stuff.
-
It looks like the instructions I followed were not complete. I didn't know about having to install anything else to make this work. Can you kindly point me in the direction of the instructions you followed to set this up and location of other downloads? As you can easily see, I'm brand new to VM world.
