

mgutt
-
Posts
11267 -
Joined
-
Last visited
-
Days Won
123
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Report Comments posted by mgutt
-
-
46 minutes ago, itimpi said:
here may be good reasons the maintainer of a particular container has set this up
Yes you are right. Some people use this state inside of the container to check the run status or internet access. Its not how its meant to be, as for example the internet access check is absolutely crazy as 1 million users of the container, would result in 1 million google.com requests every x seconds ^^
I'm also not sure why Plex is doing this every 5 seconds:
https://github.com/plexinc/pms-docker/blob/master/root/healthcheck.sh
They connect to http://tower:32400/identity, which returns an XML file and the content of this file is thrown away. This means they only check, if the internal webserver is running. And this is needed every 5 seconds? Are they crazy? ^^
Besides of that. Are these JSON files really part of an usual docker installation or is this a special Unraid thing? I wonder why only Unraid users are complaining those permanent writes. Ok... maybe it has the most transparent traffic monitoring
")
If these writes are related to Docker only, we should open an issue here. Because only updating a timestamp (or nothing) inside a config file, does not really sound like it's working as it ment to be.
-
4 hours ago, DasMarx said:
You can disable those healthchecks by adding
This solved it!!! 🥳

I had this suspect, too. But renaming healthcheck.sh to healthcheck.delete didn't help, so I gave up

Added to the Plex container as follows:

After that I verified it as follows:
Docker -> Plex Icon -> Console:
find /config/*/ -mmin -1 -ls > /config/recent_modified_files$(date +"%Y%m%d_%H%M%S").txt
Results: Empty, which means no modified files in /mnt/user/appdata/Plex-Media-Server)
WebGUI -> Webterminal:
inotifywait -e create,modify,attrib,moved_from,moved_to --timefmt %c --format '%T %_e %w %f' -mr /var/lib/docker > /mnt/user/system/docker/recent_modified_files_$(date +"%Y%m%d_%H%M%S").txt
Result: Empty, which means no writes in docker.img at all!!!
Whats next?
How should @limetech use this information to solve the issue? Add --no-healthcheck to all containers by default? I think something similar is needed as most people do not know how to monitor their disk traffic. They will only conclude "hey Unraid does not send this disk to sleep!" or "Unraid produces really much traffic on my SSD". ^^
-
 2
2
-
-
Found the source of the writes (they still exist, even if SSD has been reformatted to XFS):
-
1
-
-
@ptr727 (and all other users)
I have a theory regarding this problem. I guess its the same thing that causes different transfers speeds for different unraid users with 10G connections. Unraid uses a "layer" for all user shares with the process "shfs". This process is single-threaded and by that limited through the performance of a single cpu core/thread.
You are using the E3-1270 v3 and it reaches 7131 passmark points. As your CPU uses hyperthreading I'm not sure if the shfs process is able to use the maximum of a single core or splits the load. If its using 8 different thread, one has only ≈891 passmark points. Since a few days I'm using the i3-8100 and with its 6152 passmark points its weaker than yours, but as it has only 4 cores/threads its core performance is guaranteed at ≈1538 points. Since I have this CPU I'm able to max out 10G and have much better SMB performance.
I would be nice if we could test my theory. At first you need to create many random files on your servers cache (replace the two "Music" with one of your share names):
# create random files on unraid server mkdir /mnt/cache/Music/randomfiles for n in {1..10000}; do dd status=none if=/dev/urandom of=/mnt/cache/Music/randomfiles/$( printf %03d "$n" ).bin bs=1 count=$(( RANDOM + 1024 )) doneThen you create a single 10GB file on the cache (again replace "Music"):
dd if=/dev/urandom iflag=fullblock of=/mnt/cache/Music/20GB.bin bs=1GiB count=20
Now you use your Windows Client to download the file "20GB.bin" through the Windows Explorer.
While the download is running you open in Windows the command line (cmd) and execute the following (replace "tower" against your servers name and "Music" against your sharename):
start robocopy \\tower\Music\randomfiles\ C:\randomfiles\ /E /ZB /R:10 /W:5 /TBD /IS /IT /NP /MT:128
This happened as long I had the Atom C3758 (≈584 core passmark points😞
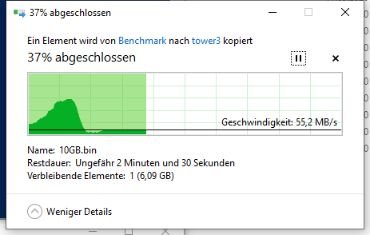
And this with my new i3-8100:
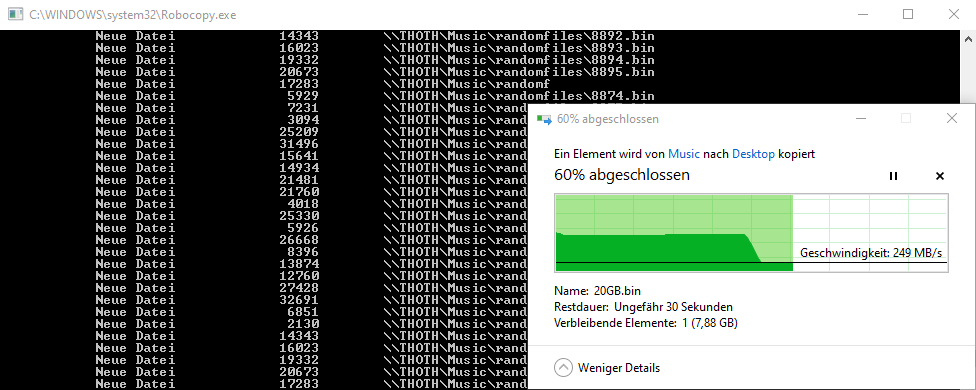
Finally you could retry this test after you disabled Hyperthreading in the BIOS. By that we could be sure how relevant it is or not.
-
2
-
-
Please check how many parallel SMB connections are open while the backup is running. Open PowerShell and enter this command:
Get-smbconnection
Regarding my testing Unraid has a really bad scalability of SMB sessions ("NumOpens"). This causes that a running backup completely kills the transfer speed for the SMB connection. The interesting part is that a parallel running second SMB connection is able to transfer with full speed (as long it does not open many sessions, too).
-
35 minutes ago, Womabre said:
noticed CloudMounter uses a local cache.
SMB should usually use a cache as well, but does not happen with my Unraid server on downloading the same file multiple times (32GB RAM installed, but never maxes out 10G).
-
I never used a version lower than 6.8.3 so I'm not able to compare, but the speed through SMB is super slow compared to NFS or FTP:
@bonienl
You made two tests and in the first one you were able to download from one HDD with 205 MB/s. Wow, I never reach trough SMB > 110 MB/s after enabling the parity disk! Do you have one? Are you sure you used the HDDs? A re-downloaded file comes from the SMB cache (RAM), but then 205 MB/s would be really slow (re-downloading a file from my Unraid server hits 700 MB/s through SMB).
In your second test you reached 760 MB/s on your RAID10 SSD pool and you think this value is good? With your setup you should easily reach more than 1 GB/s!
With my old Synology NAS I downloaded with 1 GB/s without problems (depending on the physical location of the data on the hdd plattern), especially if the file was cached in the RAM. This review shows the performance of my old NAS. And it does not use SSDs at all!
I tested my SSD cache (a single NVMe) on my Unraid server and its really slow (compared to the 10G setup and the constant SSD performance):
FTP Download:

FTP Upload:

A 1TB 970 Evo should easily hit the 10G limits for up- and downloads.
I think there is something really wrong with Unraid. And SMB is even worse.







[6.8.3] Unnecessary overwriting of JSON-files in docker.img every 5 seconds
in Stable Releases
Posted
As the JSON files are overwritten by docker and not the container, it shouldn't be an issue of the maintainer. I'll try my luck ^^