




Jokerigno
Members
-
Joined
-
Last visited
Everything posted by Jokerigno
-
I rebooted but it's still there. If you remember me I'm the say guy who noticed that there's a warning message in HA. I think there are spare pieces in my config and I would like to delete them and start all over. Can you suggest me how to remove all traces in HA and Unraid?
-
Hi, It is possible to use a secret.yaml that is not in container folder (but is in HA folder?)
-
Hi, it is "normal" that even if I removed this docker (because it cause cpu peak) I still can see a process unraid-api consuming 10% of my cpu?
-
Done. So I guess auth is mandatory now for safety reason. I readded the cameras with buffer settings but cpu usage is still high!
-
Hi, I tried also to redo everything from scratch so I renamed appdata folder as zoneminder_bk, deleted image and started over with new template. I was expection that everything was ok now but at boot with NO cameras CPU is again 100% and in logs I found this ERR [OPT_USE_AUTH is turned off. Tokens will be null] over and over. So I added NO_START_ZM="1" and this is the brand new error causing cpu peak. FAT [Failed db connection to ] I really don't know what else I can do
-
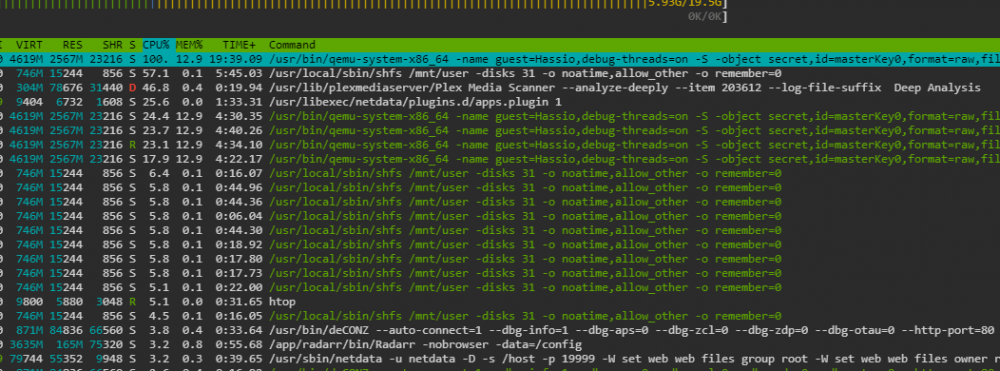
Hi, as shown in the screenshot I noticed that process /USR/LOCAL/SBIN/SHFS /MNT/USER -DISK is demanding A LOT of my CPU. Reading on the forum I found that folder caching plugin could be the reason so I removed it before posting it: As you can se the issue is still present. Can anyone please support me? Attached also the diagnostics joshua-diagnostics-20210410-1243.zip
-
Hi, It's me, again. So last update (for now). SSD is now half full and situation slightly changed. Now 100% is not all the time but most of the time. diagnostic ssd half full.zip
-
qemu can be related to the only VM running? I make some other test: 1 diagnostic with dockers and vm disabled in settings. Nothing changed 2 redo ALL the dockers using another img (xfs image) using same data in appdata. Nothing changed I really don't know what else I can do. diagnostics no vm yes docker.zip diagnostics no vm no docker.zip
-
What are the main changes when switching Docker data-root? In help there's no explanation.
-
@dlandon another update. I formatted ssd to xfs and removed appdata to cache prefer. Nothing changed. Below once again 2 diagnostics pre and post ZM start. One thing I found in docker settings is that Docker data-root is btfs. It can be changed to XFS. Should I? PS: I tried to find a way to reduce appdata dimension but didn't find anything except CA clean appdata plugin diagnostics post running v2.zip diagnostics pre running v2.zip
-
I removed dev/dri from go and plex container and reboot. Zoneminder docker still has issue. So now I'm moving all contents (appdata, system, iso, etc) from cache prefer to cache yes. Let's see what happens. I just reformat ssd drive after 6.9.1 upgrade for another issue on MBR. It suggested me to use btrfs and that's what I thought was the best solution. I will keep you posted after mover ends (if it's enough). Thank you
-
Hi, I updated Swag container and now my bitwarden instance is not working anymore. Checking swag log I found a message asking me to update nginx conf files so I update conf file inside nginx folder with new template, renamed container as requested in that file from bitwardenrs to bitwarden and set true to WEBSOCKET_ENABLED in bitwarden container. Still can't access from outside. Any hint? Previous conf file #BITWARDEN # make sure that your domain has dns has a cname or a record set for the subdomain bitwarden # This config file will work as is when using a custom docker network the same as letesencrypt (proxynet). # However the container name is expected to be "bitwardenrs" as it is by default the template as this name is used to resolve. # If you are not using the custom docker network for this container then change the line "server bitwardenrs:80;" to "server [YOUR_SERVER_IP]:8086;" Also remove line 7 resolver 127.0.0.11 valid=30s; upstream bitwarden { server bitwardenrs:80; } server { listen 443 ssl; server_name bitwarden.*; include /config/nginx/ssl.conf; client_max_body_size 128M; location / { proxy_pass http://bitwarden; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; } location /notifications/hub { proxy_pass http://bitwarden; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "upgrade"; } location /notifications/hub/negotiate { proxy_pass http://bitwarden; } } New Conf file ## Version 2020/12/09 # make sure that your dns has a cname set for bitwarden and that your bitwarden container is not using a base url # make sure your bitwarden container is named "bitwarden" # set the environment variable WEBSOCKET_ENABLED=true on your bitwarden container server { listen 443 ssl; listen [::]:443 ssl; server_name bitwarden.*; include /config/nginx/ssl.conf; client_max_body_size 128M; # enable for ldap auth, fill in ldap details in ldap.conf #include /config/nginx/ldap.conf; # enable for Authelia #include /config/nginx/authelia-server.conf; location / { # enable the next two lines for http auth #auth_basic "Restricted"; #auth_basic_user_file /config/nginx/.htpasswd; # enable the next two lines for ldap auth #auth_request /auth; #error_page 401 =200 /ldaplogin; # enable for Authelia #include /config/nginx/authelia-location.conf; include /config/nginx/proxy.conf; resolver 127.0.0.11 valid=30s; set $upstream_app bitwarden; set $upstream_port 80; set $upstream_proto http; proxy_pass $upstream_proto://$upstream_app:$upstream_port; } location /admin { # enable the next two lines for http auth #auth_basic "Restricted"; #auth_basic_user_file /config/nginx/.htpasswd; # enable the next two lines for ldap auth #auth_request /auth; #error_page 401 =200 /ldaplogin; # enable for Authelia #include /config/nginx/authelia-location.conf; include /config/nginx/proxy.conf; resolver 127.0.0.11 valid=30s; set $upstream_app bitwarden; set $upstream_port 80; set $upstream_proto http; proxy_pass $upstream_proto://$upstream_app:$upstream_port; } location /notifications/hub { include /config/nginx/proxy.conf; resolver 127.0.0.11 valid=30s; set $upstream_app bitwarden; set $upstream_port 3012; set $upstream_proto http; proxy_pass $upstream_proto://$upstream_app:$upstream_port; } location /notifications/hub/negotiate { include /config/nginx/proxy.conf; resolver 127.0.0.11 valid=30s; set $upstream_app bitwarden; set $upstream_port 80; set $upstream_proto http; proxy_pass $upstream_proto://$upstream_app:$upstream_port; } }
-
I restored it. But I'm still struggling to have the same performance as before.
-
Attached 2 files: first server running before starting the container. second with zoneminder on and cpu 100%. I hope that helps. diagnostics post running.zip diagnostics pre running.zip
-
Nope. I added then --device /dev/dri:/dev/dri in Extra Parameters but unfortunately I see no differences (cpu 100% + errors in logs...a lot).
-
I changed camera buffer based on your data. Now Load: is 10.04 and /dev/shm is 38%. CPU (all of them) are still at 100% to the whole time container is running.
-
If you are referring to shm I setup docker with 5G --shm-size="5G" andi inside the container I see this /dev/shm: 18% Far below the 50% that dlandon suggested.
-
Because it happens (mainly) when I switch it on
-
Hi, does anyone else has issue with this container after updating to 6.9.1? I now have CPU at 100% constantly while inside the container everything seems ok: ending_up Load: 8.96 storage DB:16/151 Storage: Default: 91% /dev/shm: 9% In the logs I found a lot of this error:
-
Hi, well I didn't know that restoring a container with same appdata could lead to this. Just for anyone who can be interested in this using staging true and setting cloudflare Full SSL instead of Full SSL (Strict) allow nginx to start and services become available again. I will remember to revert staging and SSL in a week.
-
Hi, I had issue with my unraid server (lost docker image). I restored all my containers but I don't know why swag become problematic (more than other). Looking at the logs I see this: It seems that I've been temporary banned and I have to wait a week to rehave a working certificate (doh!). But I was wondering if this has consequencies for nginx because I cannot longer login from outside world to my services. Can someone confirm or disconfirm? There's some workaround for this? I "need" access to some services (nextcloud for example) and waiting a week can be problematic. Thank you all in advance!
-
On another post s guy told me that in my case could be related to my SAMSUNG SSD cache drive. I had to reformat it but I lost docker.img and libvirt.img so I’m still trying to fix everything (so annoying!). Just for curiosity do you have a ssd evo 860 too? Inviato dal mio iPhone utilizzando Tapatalk
-
Hi, I want to start my new job seeking project with a CRM in order to track everything. I’ve found suiteCRM that is open source. It is suggested in different topics but somehow no one has ever created a template (even if it has been requested multiple time). I’m not a programmer but I’ve already tried with different containers in docker hub but without success. I want to simply deploy it next to my mariadb container already used by others containers (Nextcloud for example). Can someone PLEASE support me in this? Thank you in advance
-
Thank you I've done what you suggest me but the again I receive no messages. I checked here https://api.telegram.org/botaaaaaaaaaaaa:aaaaaaaaaaa/getUpdates and can se my tentatives to write to the bot but it does not send anything.
-
Good question. I have no error in logs but I do not receive any message. It never worked for me.


