




Zxurian
Members
-
Joined
-
Last visited
Everything posted by Zxurian
-
Using through Unraid's native VPN manager would've been nice to counteract those slots. Currently, my Unraid box uses 2, one for qbit directly, and a second through VPN manager where all other containers are funneled through. From what I was able to gather, you might be able to do that with an OpenVPN configuration, but not with a WireGuard, since it's defined entirely through settings within Unraid. Also, I am _definitely_ not an expert, so if anyone else has more to say, by all means.
-
no, I was never able to make it work. I resolved to just running the qbittorrent_vpn container on a regular bridge. Then within the container itself, setup the VPN connection (instructions are there). For every other container I have it using the `wg0` network as described above.
-
When editing the container config, set Network Type to `wg0`. Also make sure that the `wg0` connection is active under your VPN setup.

-
understood. I rebooted two days ago , but got a new warning this morning of Out of Memory again. Based on what you said, it sounds like a reboot should flush the log that was reporting the out of Memory errors, so _after_ a reboot, it shouldn't appear unless another Out of Memory event occurred? Latest diagnostics attached to try and isolate what is causing these all of a sudden. media-1-diagnostics-20231129-1245.zip
-
thanks. Is there a way to tell if it's docker related? (I don't run any VMs). I just rebooted the Unraid server after 5 days straight of getting this warning (latest diagnostics before rebooting attached). Does the warning that Fix Common Problems displays mean that it's been Out of Memory for 5 days straight, or is it just seeing a single entry in the log file of an Out of Memory error, and because I didn't reboot for 5 days, just keeps seeing that same single entry, but displays a warning each day? media-1-diagnostics-20231127-0742.zip
-
Started getting out of memory errors on my Unraid box. Per , I have not restarted yet, and am providing diagnostics here to figure out why suddenly getting Out of Memory errors. System is an R510 that has been running Unraid for ~3 years now(?) without issue. media-1-diagnostics-20231124-2027.zip
-
I have a VPN created through Unraid's native VPN Manger with Peer type of access set to "VPN tunnel for docker containers only", tunnel name `wg0`. VPN tunnel works. I have multiple containers using this `wg0` for network access. They all work, and correctly go out to internet over tunnel (verified by Firefox container and ip check). Note: this is _not_ a question about which port to open the VPN itself on. Using hotio's qbittorrent-vpn container as a test (thanks @Davo1624 for helping), I've established that when the container creates it's _own_ VPN network (container connecting over bridge), then the qbit port is open and can be seen from the outside at the VPN exit address. If I set the container to _not_ use it's own VPN network, but instead use the `wg0` network created by Unraid's own native VPN Manager, then this port is closed. This tells me that while the container itself is reachable, the port itself needs to be open and forwarded on the VPN tunnel created by Unraid in order to pass through to the container. I have googled several hours, but I my google-fu is coming up empty on how to correctly setup a port forward on the VPN created using Unraid's native VPN Manager. I can't see anything within Unraid's native GUI in order to setup Port Forwarding, or what config files / settings do I need to look at?
-
Thanks, that was the key. Ended up double checking my schedules and found I had auto-update scheduled at the same hour as Appdata backup. After fixing schedule conflict, no further errors.
-
Running Unraid 6.11.5, CA Appdata Backup 2023.01.28 so this seems related to other posts I've seen here, but I don't have any exclusions for stopping containers. They're all set to stop, backup, then restart, but I've gotten errors the past two days about `Error while stopping container! Code: Container already started`, on a single different container each time, and then of course a verification difference on the affected container. Logs of past two nights attached. I can stop the containers manually without issue, so not sure why CA Appdata Backup is listing it as "already started" backup.log backup.log
-
So I've had a working Unraid v6.11.5 with wireguard tunnel up (VPN for docker only) until today. Switched from xfinity to fronter, something that should have zero effect as far as Unraid is concerned. Powered down Unraid via GUI first, (needed to power down rack to route some cables), new WAN hooked up to router, powered Unraid server back on. No other changes other than new WAN DHCP IP acquired from router (OPNSense) After waiting for Unraid to fully boot up, my Wireguard Tunnel wg0 would say it was active, but no container set to use wg0 would actually send or receive data. Tried importing a new tunnel to test to see if it was just the wg0 config for some reason, but container also wouldn't work. Unraid itself was exhibiting some odd symptoms as well, Fix Common Problems would report that Unraid couldn't contact github.com (WAN was definitely up during this time). Attempted to just blast wg0 tunnels and start from scratch, I have just a wg0 with a fresh config loaded, and it _looks_ like it's active. The Problem is as soon as I enable docker, network problems start to occur. a basic ping to 1.1.1.1 stops working as soon as docker is enabled (screenshot showing as soon as I activated Docker, and remained unreachable until I disabled Docker), and that's without any containers that use the wg0 Tunnel running. Where should I look to figure out why Unraid networking suddenly went sideways after just switching WAN ips? (everything else on my network works) media-1-diagnostics-20230309-2320.zip

-
Tried using plugin, didn't quite work for me. Went to remove it, but it won't let me fully remove the plugin. Plugin is still listed under Plugins and if I click checkbox to remove, I get the following error: how can I fully remove plugin from system?

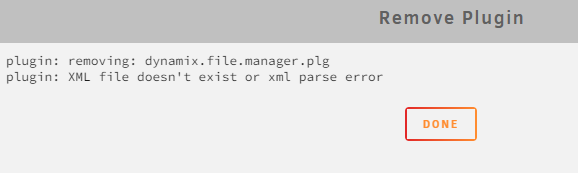
-
thanks for the suggestion @DBJordan, but no dice. For the sake of argument I did add the same ports I had in VPN_INPUT_PORTS on the binhex-privoxyvpn container to VPN_OUTPUT_PORTS, but still negative. I did discover that my prowlarr container can talk to my flaresolverr container, so at least two containers can talk to each other, but other containers still can't talk to each other, even though they're all using the same binhex-privoxy container network and all localhost references. Still at a loss to figure out why there's no communication. I tried leaving the binhex-privoxyvpn container on debug and tailing the log, but didn't see anything where it was blocking any traffic. Some containers are just timing out when trying to talk to each other over the binhex-privoxy container network in 6.10.3, where it was working fine in 6.9.4
-
My environment is setup with binhex-privoxyvpn acting as VPN tunnel, then several containers using that container as it's network for outbound communication. The containers are also setup to talk to each other within the VPN network via localhost references (VPN FAQ #24-26). Everything was working correctly in 6.9.4 in terms of communication, *arr containers could communicate outbound via the VPN, and to each other without issues, I could access the webgui's of all via specified ports on the binhex-provixyvpn container options. I just updated from 6.9.4 to 6.10.3, and after the update (no issues during the update), the containers I have using the binhex-provixyvpn network are no longer able to communicate to each other. They can still communicate out through the VPN, and I can access the web GUI's for the containers, but any attempts for one container to use "localhost:<port>" to communicate to another container within the VPN network do not work. Within the *arr logs, they're all met with a "connection timeout" error. I double checked all of ports required, and they're all setup the way they were previous to 6.10.3. In regard to Q26 of FAQ, i'm not using a proxy connection on the containers so I don't _think_ it applies to me since they're connecting directly through the container network (correct me if I'm wrong). Tried changing Docker Network type from macvlan to ipvlan, but was still unable to get container to container communication working. Any suggestions to restore inter-container communication?
-
Having an issue with replacing episodes with new copies. If it's the first time an episode is grabbed, Sonarr imports it from QBit without issue, this error is only occurring when it tries to replace an existing episode. The mappings work fine as far as I am aware, since new episodes import without issue. It doesn't happen with every episode either, some are replaced without issue, while others get the Destination Already Exists error. Specific error is NzbDrone.Common.Disk.DestinationAlreadyExistsException Full trace log for affected file: https://pastebin.com/PqptSrFc Permissions within Unraid for affected files are previous file: 666 nobody users new file: 666 nobody users Permissions from Docker container for affected files are previous previous file: 666 abc users new file: 666 abc users I also ssh'd into the docker itself, and manually ran cp to copy the new file over the old file, and it worked without issue, so I don't think it's a permission issue either. I did try googling for an answer, but couldn't find anything that fit the problem I'm experiencing, so starting here to see if it's an unraid docker issue before moving to Sonarr direct help.
-
Thank you for the slap. Wasn't actually an OPNSense issue, but seeing you list the failure of DHCPv6 lead me to investigate some other things and went down a rabbit hole. For those that encounter this in the future. My OPNSense was setup with the following: * WAN - IPv6 Configuration Type: DHCPv6 * * also requesting a prefix delegation size of 60 and sent IPv6 prefix hint * LAN - IPv6 Configuration Type: Track Interface * * Tracked IPv6 Interface is the WAN interface * * checked Allow manual adjustment of DHCPv6 and Router Advertisements * Services -> Router Advertisement, LAN * * Router Advertisements set to Stateless (This sets O + A flags, which is what I want for Stateless DHCPv6. for clients, IPv6 is gotten from SLAAC, but then looks for a DHCPv6 server for additional information like DNS servers & suffix. This setup was working (see initial post). RAs (Router Advertisements) were being sent out correctly with the correct information. The Problem was my DHCPv6 server was _not_ working, so while clients would get an IPv6 & gateway from the RA's, when they sent out a DHCPv6 request, they weren't getting a reply. This is apparently why Unraid was able to get an IPv6 address and _use_ it, but it would not show up under Settings -> Network because the DHCPv6 request never completed (I'm guessing). This was verified from Wireshark and seeing DHCPv6 Information Request packets, but no replies. My DHCPv6 server is a Windows Server 2019 acting as AD, DHCP, DNS. DHCPv4 has been working without issue for years, this was only when I started getting into IPv6 that I noticed issues. Within Windows Server DHCP Service, when you're not using it to hand out IPv6 address, you do _NOT_ want to setup a scope. Instead only set the Server Options under IPv6 with what you want. It was only after playing around that I found that when right-clicking on IPv6, and going to Properties -> Advanced -> Bindings, that I saw that there were no interfaces listed. Some extended digging later, apparently Windows Server DHCP service will _only_ bind to an interface with a static IP. Okay then. I then went to set a static IPv6 on my adapter, which I set to the same address it had gotten with SLAAC (whether this is correct or not, I don't know, someone else can overrule me). Set the gateway for the OPNSense IPv6, then set the DNS for the same as the static IPv6. Hit OK, OK. Go back to DHCP Service Bindings, aaand, still no interface. Went back into Network Adapter settings and discovered that the IPv6 Properties had reset itself _back_ to "Obtain IPv6 address automatically", but did keep the DNS server, and the Default Gateway was still there, just greyed out. Some more extended digging, and apparently you need to manually disable _Router Discovery_ (not Advertisement) on the Network Interface, otherwise no matter what you do, Windows will reset the IPv6 Properties back to "Obtain an IPv6 address automatically", even though it'll let you fill in the fields. After running `netsh interface ipv6 set interface "<your adapter>" routerdiscovery=disabled`, I was able to finally set a static IPv6 on the adapter, and it actually saved it. Then went back into DHCP Service Bindings and my IPv6 interface was finally listed. After that DHCPv6 answers started flowing. Wireshark confirmed that both DHCPv6 Information Requests AND answers were flowing. Went back into Unraid, and boom, there was the IPv6 information on the Settings -> Network page. IPv6 has been a wild ride. Thank you @bonienl for your patience and giving me a hint towards what was the actual issue. Now to resume your other tutorial on docker IPv6.
-
@bonienlany ideas as to why IPv6 info isn't showing up? I've attached diagnostics in case it'll help. Haven't made any changes to the system since the last post. media-1-diagnostics-20220316-1247.zip
-
A: That was me being dumb. Will reset to 2. I have no VLANs on my network yet, so the one on Unraid to get Docker IPv6 is the only VLAN I'd be running. In order to diagnose the IPv6 issue, I'm going to just get rid of all VLANs for the time being. However... when I removed the VLAN, waited for it to refresh, lost the IPv6 information again. (I did see it briefly, however I'm unable to explain what triggered it) * no IPv6 information on Settings -> Network page 28: bond0: <BROADCAST,MULTICAST,PROMISC,MASTER,UP,LOWER_UP> mtu 1500 qdisc noqueue master br0 state UP group default qlen 1000 link/ether **:**:**:**:**:** brd ff:ff:ff:ff:ff:ff inet6 fe80::21b:21ff:fe3d:5460/64 scope link valid_lft forever preferred_lft forever 29: br0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000 link/ether **:**:**:**:**:** brd ff:ff:ff:ff:ff:ff inet 10.0.0.14/24 brd 10.0.0.255 scope global dynamic noprefixroute br0 valid_lft 690882sec preferred_lft 604482sec inet6 ****:****:****:****:9c23:e7ff:fe43:6916/64 scope global dynamic mngtmpaddr noprefixroute valid_lft 86351sec preferred_lft 14351sec inet6 fe80::9c23:e7ff:fe43:6916/64 scope link valid_lft forever preferred_lft forever this is confirmed when I run `curl https://ifconfig.co` I get the reply of my Global IPv6 address (issued via SLAAC) that's listed under `br0` so IPv6 looks like it's working from Unraid, but no IPv6 information is showing under Settings -> Network
-
so attempting to get to the bottom of this br0 is getting IPv4 and IPv6, however bond0 is showing as as only getting an IPv6 ULA, not a SLAAC address. 20: bond0: <BROADCAST,MULTICAST,PROMISC,MASTER,UP,LOWER_UP> mtu 1500 qdisc noqueue master br0 state UP group default qlen 1000 link/ether **:**:**:**:**:** brd ff:ff:ff:ff:ff:ff inet6 fe80::21b:21ff:fe3d:5460/64 scope link valid_lft forever preferred_lft forever 21: bond0.1@bond0: <BROADCAST,MULTICAST,PROMISC,UP,LOWER_UP> mtu 1500 qdisc noqueue master br0.1 state UP group default qlen 1000 link/ether **:**:**:**:**:** brd ff:ff:ff:ff:ff:ff 22: br0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000 link/ether **:**:**:**:**:** brd ff:ff:ff:ff:ff:ff inet 10.0.0.14/24 brd 10.0.0.255 scope global dynamic noprefixroute br0 valid_lft 684484sec preferred_lft 598084sec inet6 ****:****:****:****:c38:5dff:fe00:4362/64 scope global dynamic mngtmpaddr noprefixroute valid_lft 86060sec preferred_lft 14060sec inet6 fe80::c38:5dff:fe00:4362/64 scope link valid_lft forever preferred_lft forever 23: br0.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000 link/ether 00:1b:21:3d:54:60 brd ff:ff:ff:ff:ff:ff Actually following your how-to here and in those screenshots it shows an address under IPv6 entries (greyed out), but on mine, there's no values at all.
-
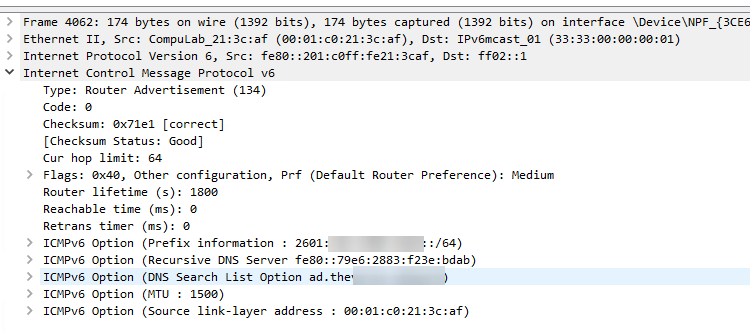
sorry, typed too fast. Okay, `br0` is the main interface, I was wrong. bond0 is a member of br0. (which explains why I could get ipv6 traffic). What lead me to believe I wasn't getting an address is on the Unraid Network Settings page, it's showing eth0's IPv4 address, but under IPv6, everything is blank.
-
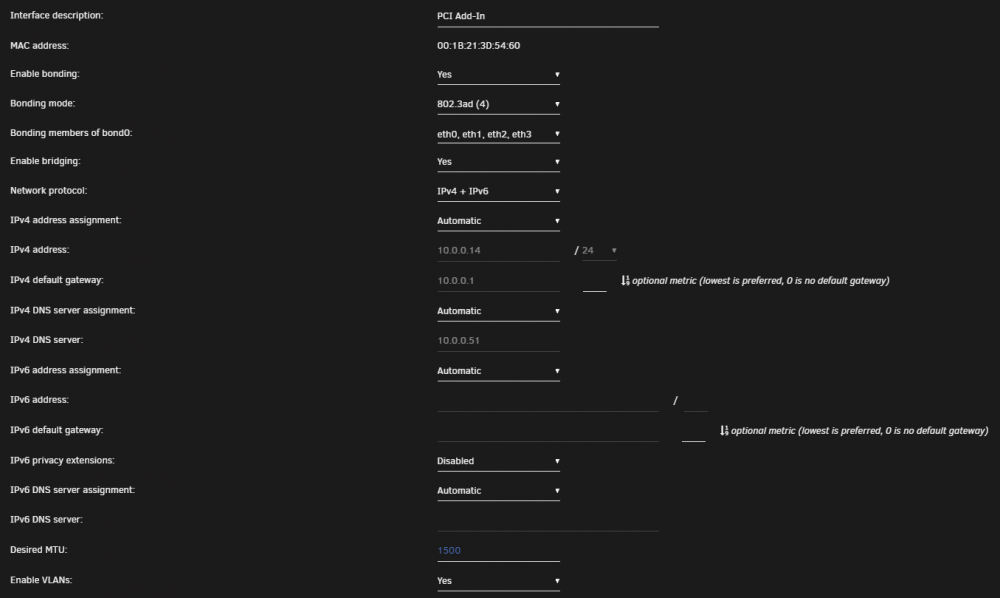
Trying to get home network up and running with IPv6 (SLAAC + DHCPv6 [O+A]). Still new, so please correct me if I'm wrong about something. OPNSense is the router. radvd is running with advanced options handing out DNS server. Wireshark capture on another box seem to show that the Router Advertisements are working. my ISP is Comcast, and I've requested a /60 from them, which OPNSense has gotten and listed and is handing out. Other machines on my network are getting an IPv6 from the /60 subnet. I'm running Unraid with 4 interface bonded together on eth0. When I changed Unraid fom `IPv4` to `IPv4 + IPv6`. The Network settings refresh with the DHCP v4 address, but the IPv6 address and default gateway are both blank. If I SSH in, then it shows br0 getting an IPv6 address from the same subnet, but not the bond0 interface. root@media-1:~# ip -6 addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 state UNKNOWN qlen 1000 inet6 ::1/128 scope host valid_lft forever preferred_lft forever 24: bond0: <BROADCAST,MULTICAST,PROMISC,MASTER,UP,LOWER_UP> mtu 1500 state UP qlen 1000 inet6 fe80::21b:21ff:fe3d:5460/64 scope link valid_lft forever preferred_lft forever 25: br0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 state UP qlen 1000 inet6 2601:****:****:****:7c63:e8ff:feac:ade5/64 scope global dynamic mngtmpaddr noprefixroute valid_lft 86384sec preferred_lft 14384sec inet6 fe80::7c63:e8ff:feac:ade5/64 scope link valid_lft forever preferred_lft forever What am I missing?
-
much obliged for the help. Using that link I tailed the log myself for a bit and found it was AUTH_FAILing. Not sure what happened on AirVPN's side, but I just created a new ovpn config, replaced the existing one, and now everything is working again. For my own knowledge, (and I could be misunderstanding), does this container prevent outbound traffic if the VPN isn't connected? ie, if I was pinging, should that have been prevented if it was AUTH_FAILing against the VPN?
-
Thanks for the quick reply! no change unfortunately. Those were the same DNS that were defaulted on the binhex-privoxyvpn container. In that vein, I also tried just setting NAME_SERVERS on container options to 1.1.1.1,1.0.0.1 to isolate, still couldn't resolve anything. I did test the six provided name servers you listed against my normal machine, and they all gave answers.
-
My googling has failed for this particular problem. I cannot get DNS to resolve from binhex-privoxyvpn anymore. I am setting up the container, and I know it _was_ working as I was using spaceinvaders tutorial, checking curl ifconfig.io, checking IP, routed a few containers through this one, `curl ifconfig.io` was working on those containers as well returning the VPN IP, but somewhere along the line, I stopped being able to resolve DNS through binhex-privoxyvpn. I've checked that I can ping the name servers IP from binhex-privoxyvpn, and they all (the ones specified in container config) come back without issue, but now when trying a curl ifconfig.io, I get curl: (6) Could not resolve host: ifconfig.io Trying a dig shows the following results. sh-5.1# dig google.com ; <<>> DiG 9.16.22 <<>> google.com ;; global options: +cmd ;; connection timed out; no servers could be reached sh-5.1# dig @1.1.1.1 google.com ; <<>> DiG 9.16.22 <<>> @1.1.1.1 google.com ; (1 server found) ;; global options: +cmd ;; connection timed out; no servers could be reached sh-5.1# Any help trying to get DNS working over the VPN again would be appreciated. For reference, I am using AirVPN, with an ovpn profile newly generated.
-
Keep loosing Config after every update. List of torrents and VPN config don't change, but after every update, I lose my Transmission config settings. Any way to keep them from resetting to default after every update?






