




Nexius2
Members
-
Joined
-
Last visited
Everything posted by Nexius2
-
Hello, bad morning for me today. I started rebuilding a disk early this week to upgrade. the data rebuild has not finished yet. during the night, 2 other HDD failed... no luck... I have 2 parity HDD but with the one that was rebuilding, I guess that takes the count to 3.... so my array doesn't like it. my shares don't all show up, for example, I can't see the appdata (wich is on a cache so???) can someone help to get this back up with minimum data loss? thanks nostromo-diagnostics-20231202-1001.zip
-
thanks, I'll give that a try
-
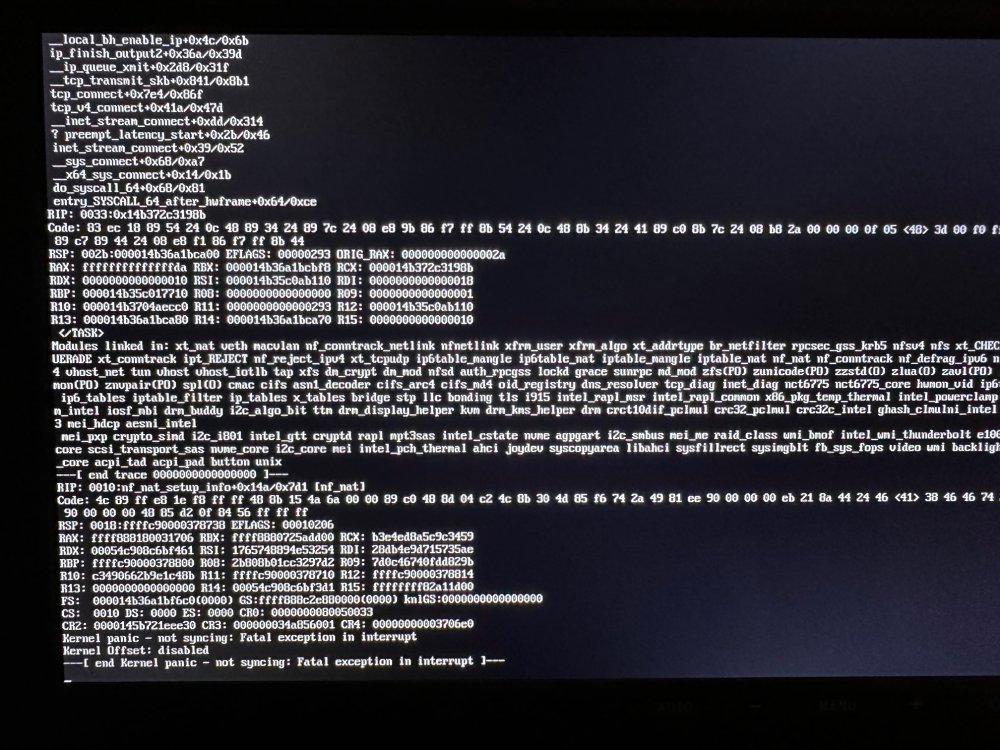
server crashed again 😞 nostromo-diagnostics-20230912-1624.zip syslog-192.168.1.80.log
-
just changed that and it's now ok, thanks my second server crashed this morning. is it me or are we many to have server crash without reason in the last months? I personnaly never had issues and on day both started crashing at a rate of every 10-15 days, sometimes a bit more...
-
thanks, i'll try that. enabled the syslog but nothing in system share, doing something wrong?
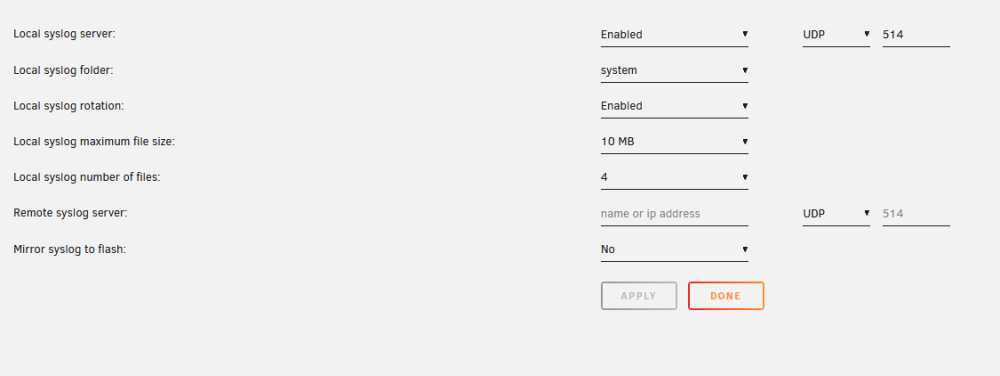
-
Hello, since 2-3 months, my two unraid servers are crashing regularly and both seem the have similar crash. last in date yesterday, around 3AM. on this server, it just stopped answering yesterday, no ping, no gui, no terminal on screen, nothing. but last time, some containers stopped working (I guessed because of a mounted share, that causses me issues everytime I want to reboot), then GUI stopped responding but I managed to make it reboot via terminal. I can't find anything in the logs, maybe could someone help. nostromo-diagnostics-20230827-1200.zip
-
I had a probleme with a card that froz the server (unreachable and no GUI displaying) that explains the unclean shutdown it seemed ok after reboot but I guess not 😕 Thanks for you help
-
seem ok, it started a partity check... nostromo-diagnostics-20230526-0749.zip
-
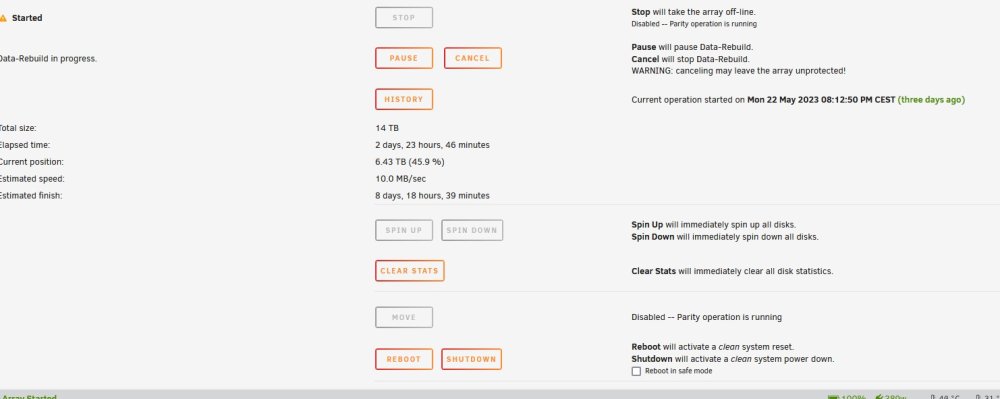
it's been like that since yesterday. I kown it's finished, there is no more disk read / write but I'd like to stop the array and shutdown to change HDD
-
thanks for the answer. when the hdd are offline, we can't see smart so I didn't see that. anyway, if i wanted to check cable or so, i would need to turn server off. and rebuild prevents from shutting down.
-
Hello, I've had a HDD failure, no big deal, I replace it and rebuild starts. during the rebuild, second HDD fails (lets hope no other on fail). no big deal, I ordered a new one and will change it when the rebuild of the first hdd will be over. but the rebuild process is stuck at 45.9%... I have seen it continue because hdd are reading and writting but the % doesn't change. now it looks like it is finished because no more read / writes, but process still going. so I can't stop array or reboot. any help? thanks nostromo-diagnostics-20230525-1448.zip
-
On a first attempt, all disk where all encrypted and unmounted (like it didn't un-encrypt at start) and nothing talks about that in the online manual. so I prefere asking. but it seems I had the right process. I'll try again. I'm putting 2 18To parity so I can upgrade other disks to that capacity, that's why I have to
-
Hello, I have a parity disk on my server and I want to add a second one. what is the process knowing that I can stop / restart array but it must not be offline for hours. meaning during rebuild, the array MUST be online with all VMs and dockers running. I also will have to change the actual parity disk with a bigger one thanks
-
Great question same conf on my side and about to do the same thing. what I have tested for know: - stop array - remove parity dsk 1 - start array - stop array - add parity disk 1 - start array My array is encrypted so it might be the cause (or the parity disk 2 but I doubt), but while rebuilt, the shares are not mounted so array not usable. if you find a way to keep the array usable (and VM and Docker) while rebuild / add parity, I'll take it
-
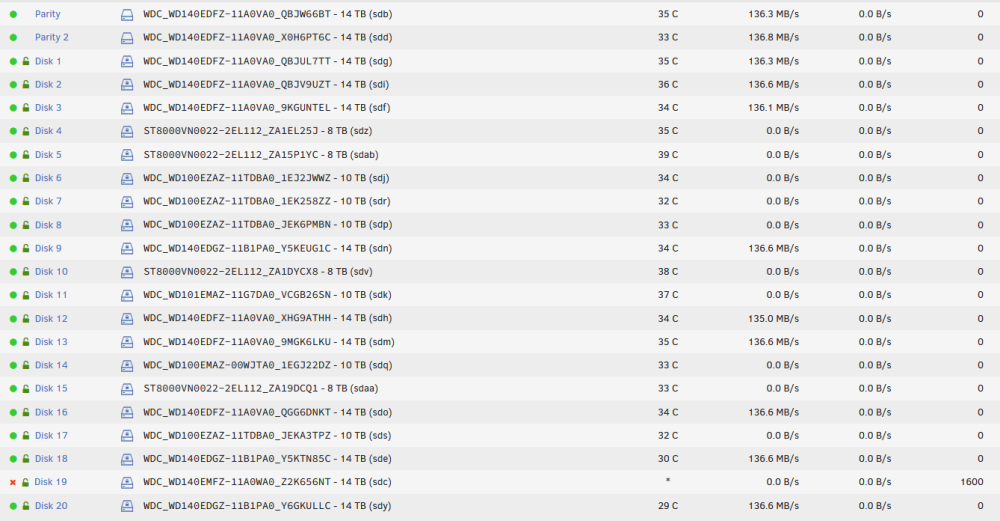
I noticed today everything is ok (8To HDD are not spinning anymore), parity continues to work normaly. it seems to be a bug with the display in the array operation.
-
yes, disk20 was formated and data is written to it. If I decide to re use disk19, it will be as a new hdd anyways. I'd guess rebuild is as usal, stop server, plug hdd, with array stop replace hdd and restart array.... it should do it's thing
-
thanks, I'll let it do it's thing until I receive the new HDD and will stop it then to replace HDD and check connections.
-
nothing has changed since last night
-
every time I had this, it was written emulated but not this time.... but it seems to be.

-
is this what you want?
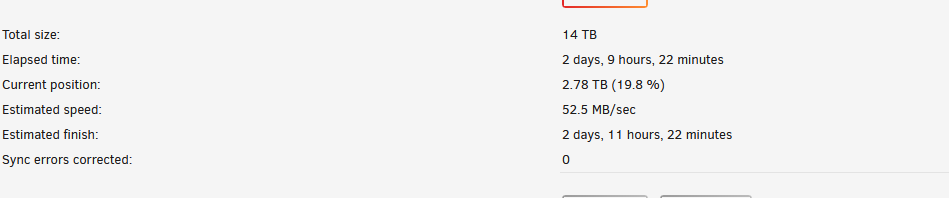
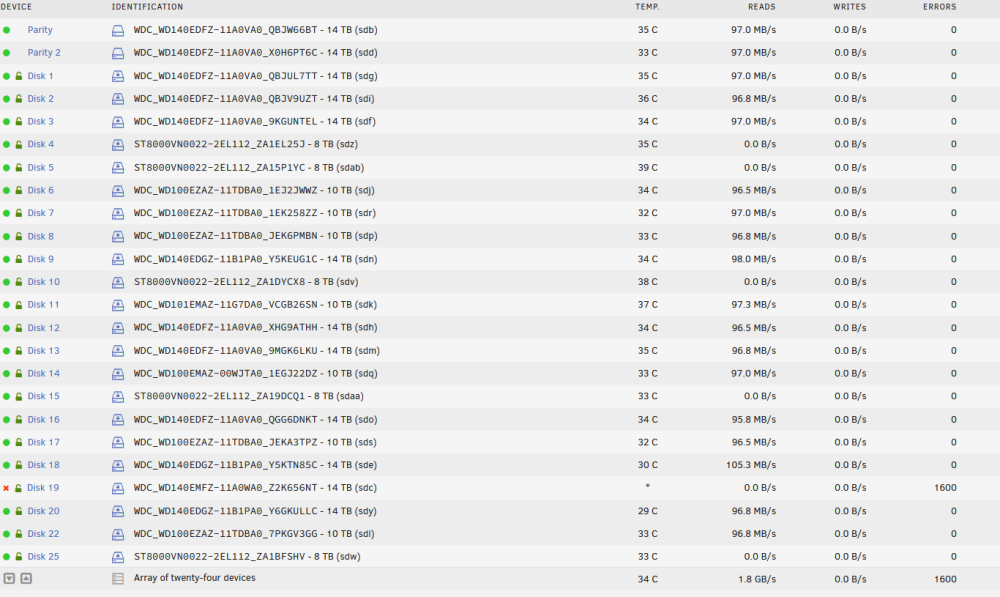 so, I added disk20 a couple days ago. no hot plug so I stoppd the server to add it. array was fine nothing to notice after array growth. and 1 or 2 days after the parity check started (it stops at 18h and starts back at midnight). during the check it seems to have found errors on disk 19. since then, parity check has stopped, but I can see data move between all the HDD as if it was still going on. I just notice sdac has appeared (thanks to you) don't know if it's good, it will be changed anyways. maybe some power plug has moved while adding disk20.... but nothing realy explains why parity is stuck at 19.8%Hello, a parity check started Monday morning and it detected a HDD failure. no problem, I have 2 parity drives and I ordered a new HDD for replacement. but I have noticed the parity check stays at 19.8% since last night. since I'll have to stop the array to replace the HDD is it something normal? will it end eventually or no chances? thanks nostromo-diagnostics-20221220-1500.ziplatest version of unraid and cleared cach (new computer) didn't change anything. I'll stay on old version until correction thanks
so, I added disk20 a couple days ago. no hot plug so I stoppd the server to add it. array was fine nothing to notice after array growth. and 1 or 2 days after the parity check started (it stops at 18h and starts back at midnight). during the check it seems to have found errors on disk 19. since then, parity check has stopped, but I can see data move between all the HDD as if it was still going on. I just notice sdac has appeared (thanks to you) don't know if it's good, it will be changed anyways. maybe some power plug has moved while adding disk20.... but nothing realy explains why parity is stuck at 19.8%Hello, a parity check started Monday morning and it detected a HDD failure. no problem, I have 2 parity drives and I ordered a new HDD for replacement. but I have noticed the parity check stays at 19.8% since last night. since I'll have to stop the array to replace the HDD is it something normal? will it end eventually or no chances? thanks nostromo-diagnostics-20221220-1500.ziplatest version of unraid and cleared cach (new computer) didn't change anything. I'll stay on old version until correction thanks









