




eatoff
Members
-
Joined
-
Last visited
Everything posted by eatoff
-
I upgraded this morning, and now have lost access to the web gui. It works for about 20 minutes, then becomes unresponsive. I have sill able to access my docker containers though, but they appear to be laggy now and then, and have problems communicating with each other. I had changed my default port to 5001, but that never made a difference before. I think i might need to downgrade later tonight to see if that resolves my issue. Anyone else experience the same? EDIT: when i ping the unraid server from my PC i get some failures and other times it works just fine. no web gui at all though UPDATE: Rolled back to 7.0.1 and it has been up for an hour now, with no issues. Will update if my issue returns
-
The crowdfunding campaign has finished, and units have been sent out... Anyone know or heard when these will available to purchase? I missed out on the crowdfunding
-
Check out this thread, same issue you are describing and solution -
-
I had noticed the same issue here, and moved the ISOs to the cache to stop it happenning, but yeah, if there is a permanent solution that would be great. When i created a Windows VM, i gave it two ISOs - the Windows.iso and the virtio drivers ISO. Now that the VM is created and running fine, can i just remove those ISOs from the VM (with the little eject button in the unraid web ui)?
-
I'm currently going through trying to put Nginx Proxy Manager (NPM) on a separate IP address from my hose machine. This will (hopefully) allow me to route some traffic internally. but, When i update the ports in the docker page for that container, they dont appear to be updating. Here is my Docker page: after startup: You can see after startup that the ports are still mapped for ports 4443 and 8080 instead of 443 and 80 The port forwarding on my router still works for using ports 4443 and 8080 instead of the new 443 and 80 ports i'm trying to map. Is there a trick to get this to update the mapping correctly? EDIT TO UPDATE: I switched to the official NPM template, and the ports are fine with that one.


-
Done and attached. The only other thing I was considering as a solution was to check which instance of the docker.img was most recent, and delete the other one, then run mover. Might be there is a conflict with there being two versions of the one file. Just checked now and the versions of these files on the disks are from 2022. the versions of the cache are from a few minutes ago (screenshots): unraid-diagnostics-20230519-1853.zip


-
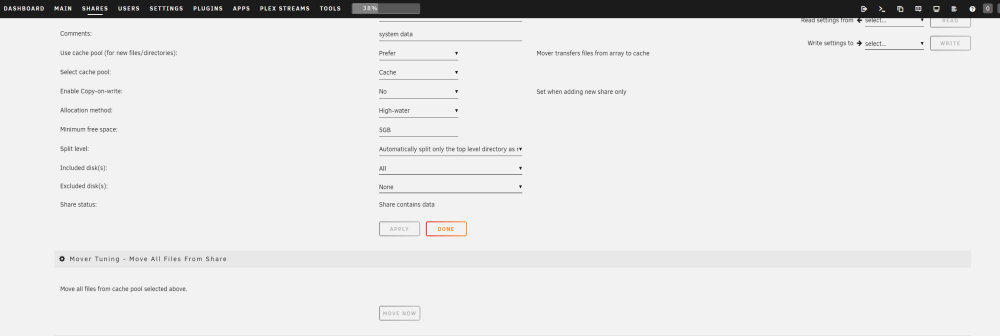
Hi Jorge, I've disabled those services, run the mover for just the system share, but these files are still spread across: Mover run: Still there on the drives:

-
This is a bit of an odd one, but I noticed recently whenever I accessed the web portal for UnRAID, one of my disks would spin up. So I went looking for what was on that disk, and there is a system folder with docker.img in it... But the system share is set to cache prefer. So I went to check the system share again, and it appears both the docker image and VM storage is on both a disk and the cache. Here is the share images: Now I do want to resolve this, but I want to make sure I don't break anything in the process. Those screenshots of the libvert.img and the docker.img appear to show the one file exists on both the cache and disk1/disk2. Can anyone please help me out? I'm not sure when this would have happened, I did add a cache drive to the cache pool a week ago, but not sure how adding a drive would get those files moved to a disk.



-
Did the unassigned device work for you?
-
Yes, in theory, but the problem still exists. That is exactly how mine is setup and the issue persists
-
I think this is the issue you're having - https://github.com/ValveSoftware/Source-1-Games/issues/1685 Seems that some steam games dont like XFS file systems. I'm unsure as best way to fix it, I have just given up on some of those games. Maybe use an unassigned drive for the game storage?
-
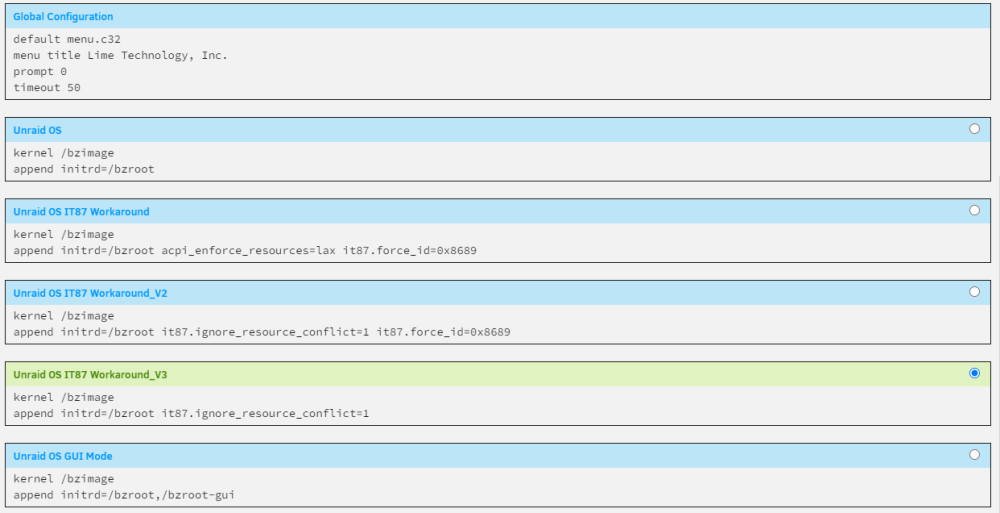
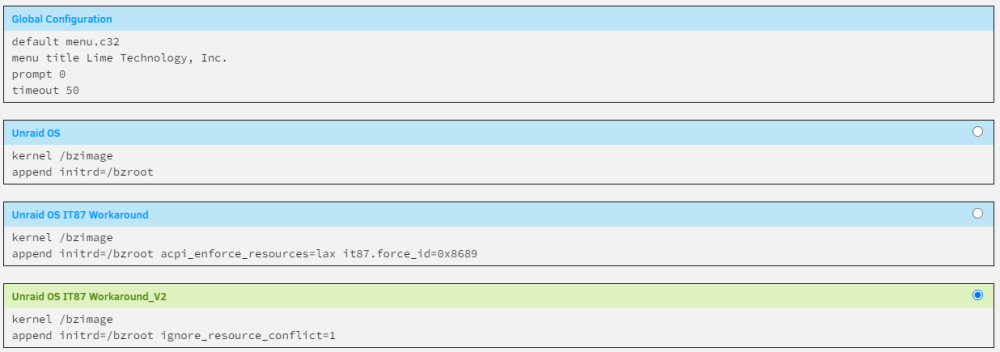
Final update for all those following along at home; I can just use the it87.ignore_resource_conflict=1 and it all works now (screenshot below). No need to force id as per the V2 in that screenshot. Most elegant solution (IMO).
-
Haha, you are correct, I have said it many times in this thread but i will say it again.... my apologies.
-
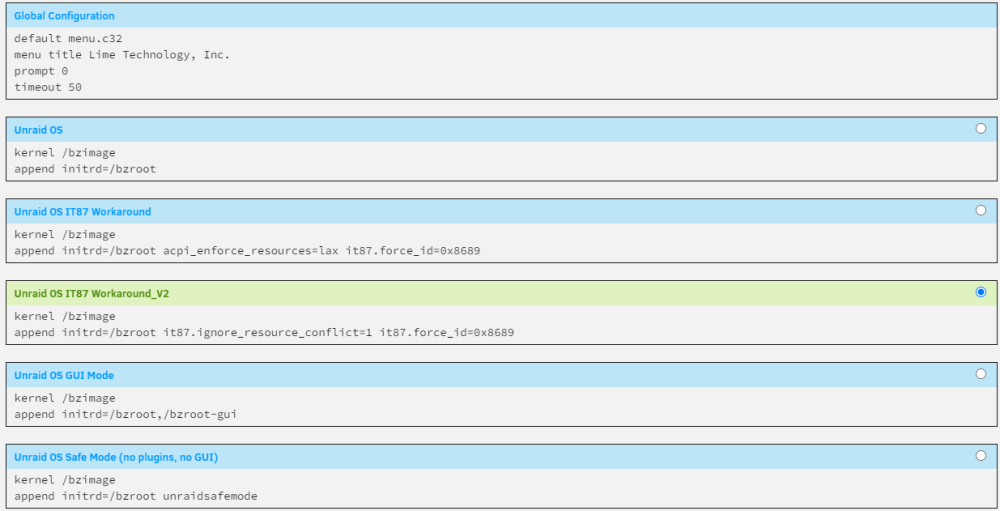
Apologies, somehow I didnt read that last bit in your post. To keep this thread up to speed, that did work. It now looks like: And i now get: Just FYI, your code says if87.force_id=0x8689, should be it87.force_id=0x8689 Thanks again for all your help ich777 EDIT: I realise I wasn't clear, this setup does work for me. got rid of the lax argument
-
Just tried this one with no luck This: Also results in this: Using that Workaround in my image does actually work. But according to Frank it shouldnt be needed, so am trying to work with him to get it resolved.
-
... really, did I miss that somewhere? what I had in the workaround worked. Do you mean change the workaround from: acpi_enforce_resources=lax if87.force_id=0x8689 to only: it87.ignore_resource_conflict=1
-
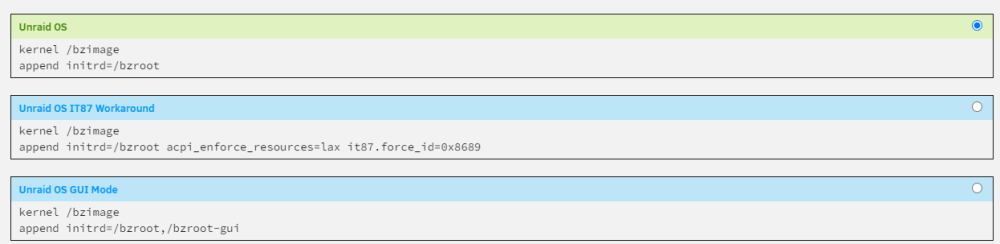
I was sending Frank a PM around driver support for specific hardware, as per his github advice. Doesnt need to be shared with everyone for my specific motherboard. Sorry, It all works now and survives a restart if I use the workaround options in the below screenshot. How i fixed it was by uninstalling the dynamix system temp plugin, rebooting, then re-installing. But according to Frank, I shouldnt need the acpi=lax or the force ID, hence the PM to get this sorted for others with the same hardware. When i get a solution I will share it here.
-
Sent you a PM
-
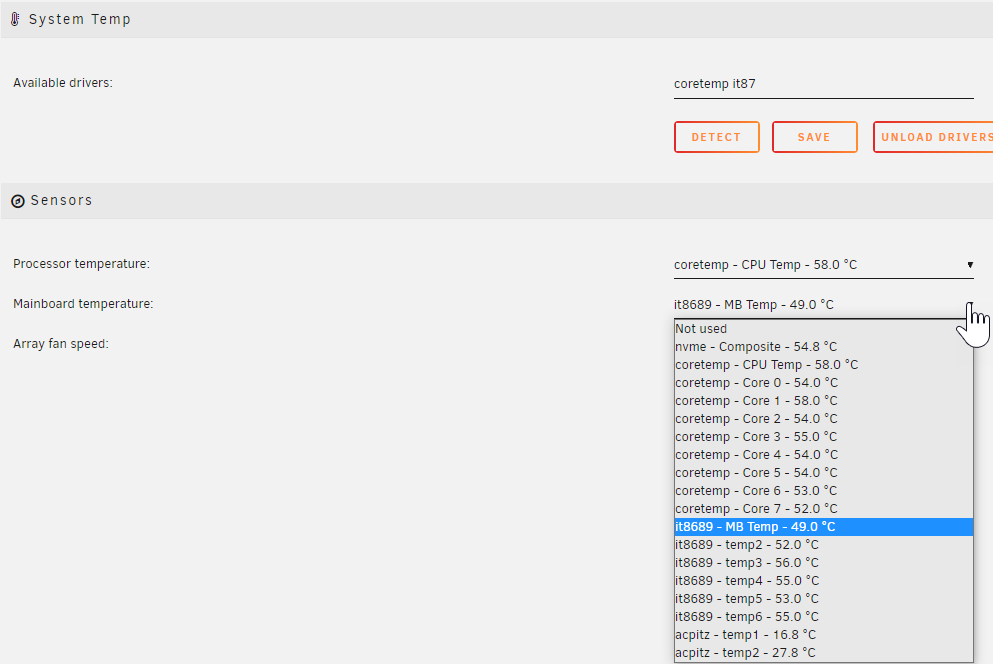
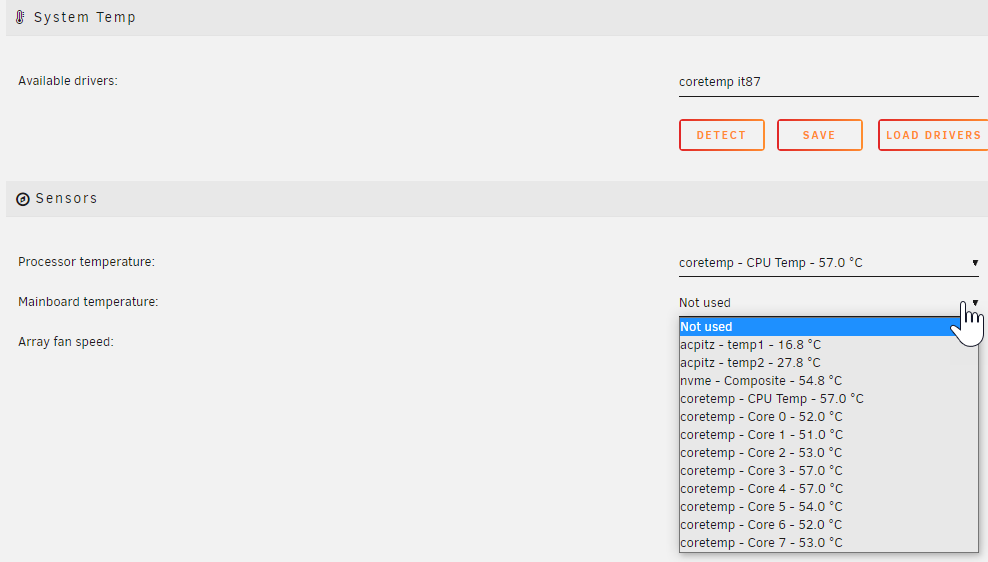
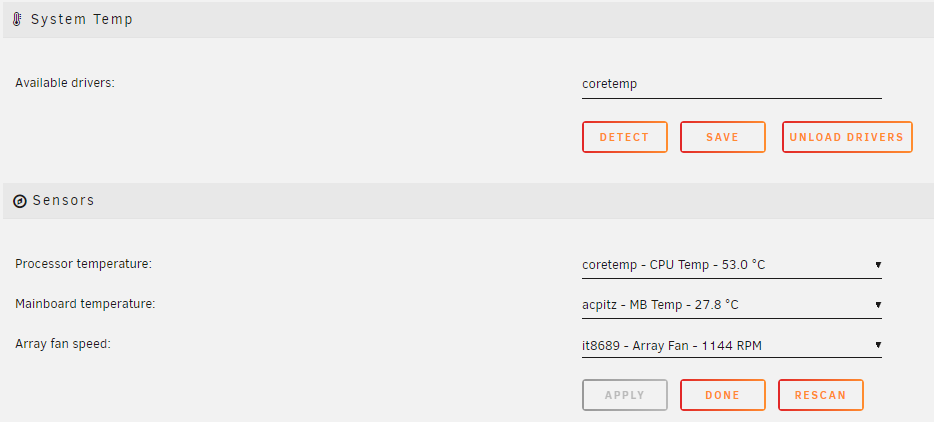
Yeah, I have rebooted after every change to the sysconfig file. This is my result: This now does have the fans available in the system temp: When i Detect for available drivers, nothing comes up apart from coretemp. Am I going to have to modprobe at startup each time to get this working? Or maybe this was working previously, but i was expecting it to come up with the detect button. I'll admit i didnt check the fan speed options since i saw it wasnt picking up the driver module in the available drivers section. EDIT: After a reboot, I DO need to modprobe it87 otherwise all the sensors disappear on a reboot. Follow up EDIT: REMOVED, modprobe is required after a reboot
-
Done. Also done. Thanks for all the help ich777. unraid-diagnostics-20220913-1529.zip
-
Just keeping everyone in the loop on this one, @ich777 the legend has added a driver module -
-
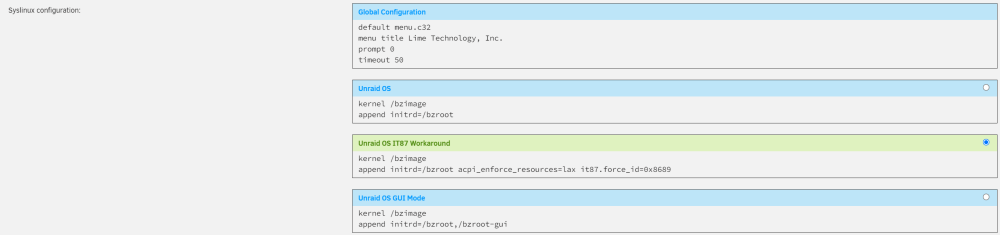
Done this, I had already removed anything from the go file, but changed the syslinux.conf to 8628 Unfortunately, still the same result: Did I have it in the correct place in my first screenshot? straight after "resources=lax"? EDIT FOR CLARITY: I have now tried it87.force_id=0x8628 and it87.force_id=0x8689 with the same result.
-
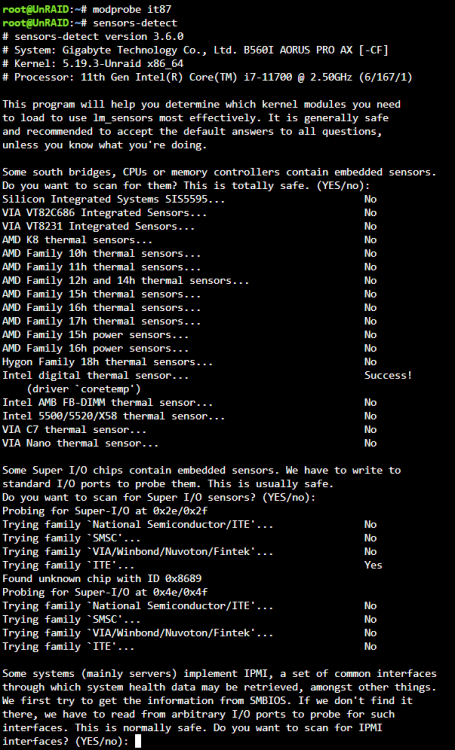
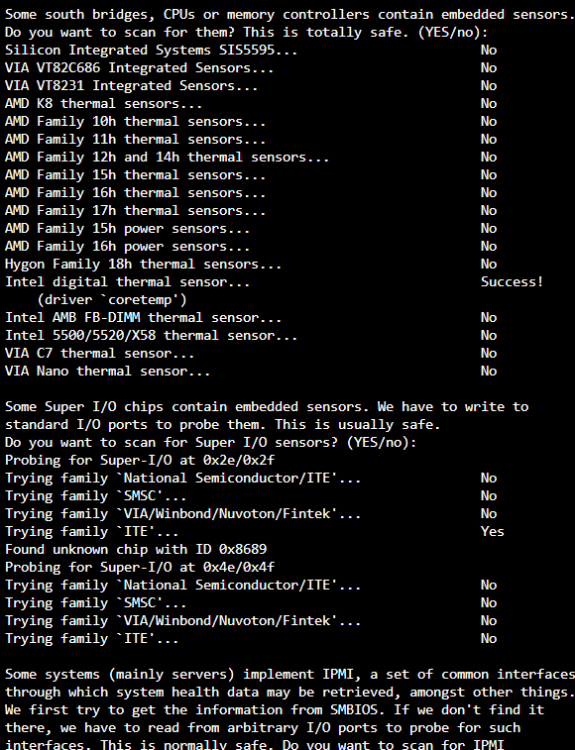
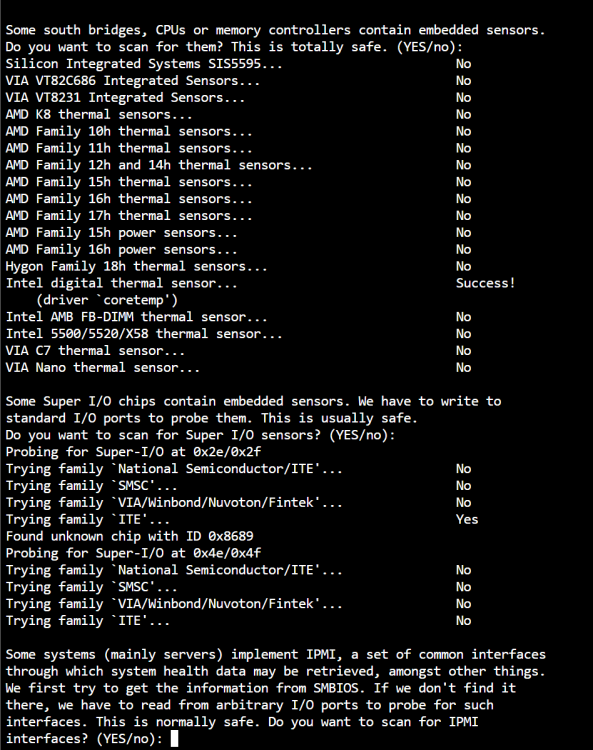
I'm running a Gigabyte Aorus B560I, I have set the same parameters as you in the syslinux, but my Dynamix System Temps still only has coretemp. When I run sensors-detect I get this: I had a previous workaround where I added "modprobe it87 force_id=0x8628" to the go file, which gave me the fan speeds, but no fan control. Instead of using force_id=0x8689 should I be using 8628? I cant actually remember where i found 8628, it was some time ago. I figured when looking at the sensors detect showing 8689 then that should be what I used...
-
Ive been having issues with fan control on my Gigabyte B560, it uses it87, will the update sort some of the issues? What Linux kernel has the updated drivers?
-
So this one is a bit of an odd one - I can detect the rpm of my fans, and it will spin them up and down when i rum pwmconfig. But if I try manually set the fan speed (command line or script) the fan stays on full speed. I tried the dynamix auto fan plugin, but that spun the fan down to idle and drives heated up very quickly. This is a brand new GIGABYTE B560I motherboard. Some more background, I had to use the workaround listed in this comment here to get the fans to be detected - This is the command I am using to get the PWM set for the fan to stop to check the correlation - "echo 0 > /sys/class/hwmon/hwmon3/pwm2" Anyone have any ideas? Logs are attached. unraid-syslog-20220826-1405.zip




















