



Ford Prefect
Members
-
Joined
-
Last visited
Everything posted by Ford Prefect
-
...hast Du denn sowas in Deinem System? Kein LAN, nur WLAN? Könnte man ja mal deaktivieren...so als Ausschluss-Prinzip.
-
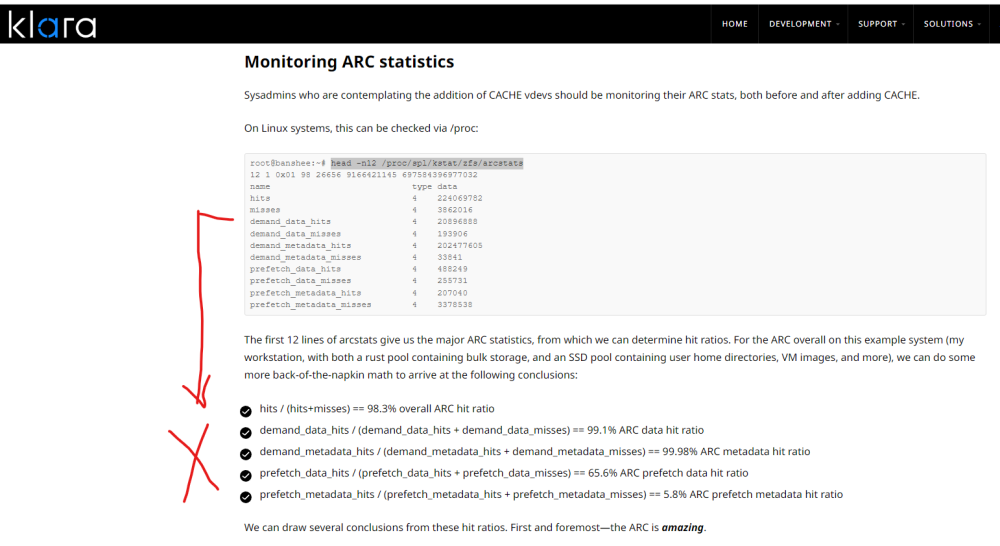
With ZFS being made available, I'd suggest to give more information in current ZFS ARC size and usage/performance, in order to help the user making informed decisions on how to maybe tweak ARC settings (size). Based on info from here: https://klarasystems.com/articles/openzfs-all-about-l2arc/ I'd suggest to fetch and process the output from "head -n12 /proc/spl/kstat/zfs/arcstats" and provide statistics in the Memory Stats in the dashboard (maybe with an additional info-icon on the ZFS bar). The Statistics are also given in the link above: many thanks in advance for considering. regards, Ford
-
...alles in einzelnen Schritten machen. Du hast das im Prinzip schon richtig analysiert. zuerst mal alle Disks physisch einbauen die alte Parity aus der Konfig rausnehmen (Array stop, Parity raus, Array start) dann die neue(n) Daten-Disks hinein konfigurieren (Arry stop, neue Daten-Disk(s) inkl. der Ex-Parity hinzu,Edit: und die 1TB raus, Array start) Hier kommt der knifflige Part - neue, frische Disks, die nie im Array als daten-Disks waren müssen formatiert werden...da gibt es "nur" eine Checkbox vor dem Array Start. Wenn Du Dich hier vertust und nicht erkennst, das nur frische Disks als unmountable da im Array stehen, geht das in die Hose -> Du kannst diese vorher mit dem Unassinged Devices Plugin vorbereiten (auch evtl. preclear) und formatieren...dann gibt es kein Gemecker beim Array Start. die neue Parity hinein konfigurieren (Array stop, Parity hinein, Array start) -> Parity wird neu gebaut.
-
Ja, kann auch sein. Ich bezog mich aber nicht auf den Stick selbst, sondern auf die Access Violation...das kommt doch aus dem Microcode der CPU... ob das also RAM-Fehler sind? Mein Verdacht ging auf ein Plugin oder eben etwas, was da nicht hingehört...daher die Idee mal ohne alte Config - damit ohne Plugins und Extras nur den Kernel zu booten.
-
Ja, L2ARC ist da sicher auch schwierig. ... muss man evtl. aaich pro zpool machen. Mehr RAM ist einfacher und evtl. ausreichend....siehe: https://klarasystems.com/articles/openzfs-all-about-l2arc/
-
...also der beste Tipp wäre natürlich vorher von der vdisk eine Kopie zu machen. Mit qemu image kannst Du den typ von raw nach qemu2 konvertieren...evtl. geht es dann? Natürlich keine Garantie das hinter die vdisk ein Briefbeschwerer ist.
-
...na da bin ich aber froh! Weiterhin viel Erfolg und Freude mit dem neuen Spielzeug
-
...mach ein Ticket bei Gigabyte auf....steht doch da, das man es deaktivieren kann. Hast Du auf das neueste BIOS geupdated? Ich hab leider kein moderners Gigabyte Board, das ich booten kann ohne den WAF zu gefährden Edit: evtl. auch mal mit dem Jumper auf dem MB das CMOS löschen...bei NULL anfangen...evtl. ist es ja ab Werk deaktiviert?
-
Du willst einen Cache Pool haben, der auch lesenden Zugriff "puffert"/beschleunigt. das kann unraid nicht. Seit unraid 6.12RC gibt es ZFS nativ....Möglichjeit/Idee: den unraid cache auf ZFS, statt BTRFS umstellen. Damit gibt es dann schonmal Lese-Cache (ARC/RAM) über das Dateisystem...zum vergrössern, damit man statistisch gesehen genug "hits" hat, kann man natürlich mehr RAM oder Second Level SSD/NVME (L2ARC) nehmen. Das unraid Konzept Array <-> Pool bleibt dabei wie es ist...ZFS Cache hilft ohne Script/transparent....wie gut/viel?..keine Ahnung....ausprobieren / wird vom UseCase abhängen. Edit: mal lesen: https://schroederdennis.de/dateisystem/zfs-cache-arc-l2arc-log-zil-performance-guide/ Edit2: die Frage ist, wo Du diesen L2ARC einhängst....evtl. dann auch das Array auf ZFS umstellen, damit der früher greift. Wenn der Mover aufs array verschiebt, liest der die Daten...damit landet das auch im L2ARC eines zpools vom unraid-pool. Sind Array Disks auf ZFS formatiert, landen auch lesende Zugriffe von da im Lesecache...wird neu geschrieben, geht es wieder über den Write-Cache / unraid-Pool usw...
-
Der unraid "Cache" ist ein write Cache. Evtl. eher dann doch etwas generisches für ZFS mit ARC und L2ARC, als zpool im unraid-Cche Pool / primary storage, wie es jetzt heisst... ARC (RAM) und L2ARC kann man ja einstellen. Was kostet ne 2TB SSD?
-
Hast Du den Stick neu gemacht und auch Deine Confg wieder drauf gepackt? Probier es mal ohne Deine Config...nimm die "leere" config, nach dem Stick Neubau....nur der .key-File Deiner Lizenz da mit rein. Bootet er dann?
-
Das hat nix direkt mit UEFI und dem Stick zu tun, sondern mit einer Einstellung der Sicherheits-Features im BIOS. Für Win11 braucht es das, in Verbindung Zugriff auf das TPM Modul. Probier mal diese Option im BIOS zu finden. Evtl. ist die versteckt und taucht erst auf, wenn Du CMS-Feature deaktivierst? -> https://www.mauricewoitzyk.de/gigabyte-mainboards-so-aktivierst-du-den-sicheren-start-fur-windows-11/ ...hier musst DU dann latürnich deaktivieren Hier: https://download.gigabyte.com/FileList/Manual/mb_manual_intel700series-bios_e.pdf?v=aceb9fb3f69cc73ea6b2fddd6a6f34ed Seite 26ff...CMS-Support deaktiveren
-
...probier bitte die manuelle Methode, wie im Link oben angeführt, von @ich777
-
nein, das ist nicht normal....10min-15min oder so, dann sollte es vorbei sein....selbst bei USB2.0.... Die Samsungs sind eigentlich OK...wie alt ist der Stick?...USB3 wird heiss und bedeutet mehr Verschleiss. Es gibt noch die manuellle Methode, aber schau erstmal mal hier...auch "Dein Stick?":
-
...und hier ist noch eine, von @serx gemessen
-
...meine Eaton kommt in die Jahre und der Netzwerk-Schrank saugt immer mehr, da inzwischen alles im Haus auf PoE umgestellt ist. daher bin ich mal wieder auf den Faden gestossen... Ich muss für die Gosund SP1, mit Tasmota Firmware nochmal eine Lanze brechen...habe von denen einige im Einsatz. Edit: die SP1 ist das "dickere Modell", ich habe die SP-111, hier: https://www.idealo.de/preisvergleich/OffersOfProduct/200966203_-smart-wi-fi-plug-ep2-sp111-gosund.html Edit2: der Firmware cross-flash auf Tasmota kann eine Herausforderung sein, da das Tool Tuya-Convert, wleches das über die WLAn Schnittstelle kann, von der orignal-Tuya-Firmware - je nach Version - blockiert werden kann. Auch hat das aktuelle Modell der SP111, die EP2 kein verschraubtes Gehäuse mehr und den flash mit Bordmitteln, Makerstyle, durchzuführen. Hier gibt es einen Satz, pre-flashed mit Tasmota: https://www.amazon.de/Tasmota-Steckdose-NOUS-A1T-stromverbrauch/dp/B0054PSI46/ref=sr_1_1_sspa?__mk_de_DE=ÅMÅŽÕÑ&crid=1TRRCMTPIKNDP&keywords=gosund%2Bep2%2Btasmota&qid=1683362256&sprefix=gosund%2Bep2%2Btasmota%2Caps%2C76&sr=8-1-spons&sp_csd=d2lkZ2V0TmFtZT1zcF9hdGY&smid=A3PSSM362NEL6G&th=1 ...also China-Cloud frei. Integration mit MQTT und HomeAssistant, openHAB usw. kein Problem....und sie sind so klein, dass sie nebeneinander in eine Mehrfach-Steckdose passen. Laufen prima und mit der Glühbirne kalibrieren ist IMHO genau die richtige Methode. Die Smarten-Dinger messen natürlich auch Wirk- und Blindleistung. Eine Glühbirne hat nur Wirkleistung und auch nur diese wird in DE am Zähler gemessen und bezahlt. Die Blindleistung kommt ins Spiel, wenn die Kabel zu heiss werden oder die Spannungshaltung nicht passt - dafür sind aber die Verbräuche zu klein, die Blindleistung nicht veränderbar...eine grosse, 3-phasige Wärmepumpe, ein Pressluft-Kompressor oder ein Holzspalter kann da mehr Schaden oder Nutzen (an)richten Demzufolge ist die Vergleichsmessung und Betrachtung für den (idle-)Verbrauch mit Wirkleistung genau richtig. Ausserdem kann man mit den kleinen Hellfern mal den Ernstfall vom Sofa aus simulieren 😁
-
...habe ich auch so, allerdings bin ich noch auf RC2. Mein zpool im unraid-pool schläft einwandfrei....Array mit xfs auch. Äh...OK, ja, dann ist das der "Indikator", dass die Platte geweckt wurde. Ein "spinning up Disk vorher gibt es ja nicht" . Der Effekt ist aber der Gleiche und beim TE viel zu häufig...da muss ja ein Grund vorliegen, wenn vor RCx alles ruhig(er) war.
-
Filesync? -> https://freefilesync.org/tutorials.php ... gibt es in den Community Apps. Kann wohl auch Scheduled Tasks. Ich kann aber zu den weiteren möglichen, benötigten Regeln für Deinen UseCase nix sagen.
-
Na dann ist ja alles gut. Wahrscheinlich hast Du einen Molex-SATA Adapter der Luxusklasse der auch intern für 3.3V Notebook-SSDs geeignet ist und diese über einen Spannungsteiler aus den 5V intern mitmacht.
-
Ah, Du warst schneller...hast Du jetzt doch den Adapter gefunden oder den Pin abgeklebt oder was genau?
-
OK, dann hat sie ziemlich sicher das 3.3V Pin "Problem". In einen normalen SATA-Stromkabel/Stecker sind 12V, 5V und 3.3V drin....diese Disk schaltet sich nicht voll ein, wenn der 3.3V pin anliegt. Eigentlich sollte der Molex Adapter das lösen, weil der nur 12V und 5V liefert...mehr braucht die Disk auch nicht. Hast Du noch einen anderen SATA zu Molex Adapter - das ist hier die beste Methode...zweitbeste: 3.3v Pin abkleben Schau mal hier: ...und hier: https://www.computerbase.de/forum/threads/wd-my-book-8tb-in-ein-nas-bauen.1818270/#post-21608921
-
OK, kannst Du fühlen, dass die anläuft beim Start ? Was ist mit dem SATA-Daten Kabel und dem Port am MB ... gleich wie bei dem test mit WD Green? Wo ist die Disk originär her...aus einem USB Gehäuse, WD myBook o.ä. ausgebaut?
-
...dann gehen so 4.5-6W auf die USV selbst.
-
...mach den Stick mal neu, vorher den "config" Ordner sichern (inkl. der .key Datei für Deine Lizenz). Wenn Du das un-get Plugin installiert has,t auch den "extra" sichern (gleiche Ebene wie der config ordner, direkt auf dem Stick). Beim USB-Creator EFI-Boot aktivieren/erlauben. Nach dem Erstellen, den config (und extra) Ordner wieder drauf/überschreiben.
-
Ja, das weckt die Disks auf. Mach mal einen Bug Report im rc5 Faden auf -> https://forums.unraid.net/bug-reports/prereleases/ ...Diagnostics nicht vergessen.



