




Darksurf
Members
-
Joined
-
Last visited
Everything posted by Darksurf
-
DNS is acting strangely resolving to 127.0.0.1 . My Linux laptop on the exact same network using the exact same DNS 1.0.0.1 (cloudflare) resolves just fine, but Unraid does not. This issue is also passed down to the Dockers as well. Laptop dig bitsearch.to ; <<>> DiG 9.20.13 <<>> bitsearch.to ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 19339 ;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 3 ;; QUESTION SECTION: ;bitsearch.to. IN A ;; ANSWER SECTION: bitsearch.to. 17 IN A 172.67.198.127 bitsearch.to. 17 IN A 104.21.52.117 ;; ADDITIONAL SECTION: inf.portmaster. 0 IN TXT "accepted: allowing dns request" inf.portmaster. 0 IN TXT "freshly resolved by Cloudflare (dot://cloudflare-dns.com:853#config)" inf.portmaster. 0 IN TXT "record valid for 3m17s" ;; Query time: 56 msec ;; SERVER: 1.0.0.1#53(1.0.0.1) (UDP) ;; WHEN: Sat Nov 01 23:43:12 CDT 2025 ;; MSG SIZE rcvd: 287 cat /etc/resolv.conf # Generated by NetworkManager nameserver 1.0.0.1 nameserver 1.1.1.1 ping bitsearch.to 1 ✘ PING bitsearch.to (172.67.198.127) 56(84) bytes of data. 64 bytes from 172.67.198.127: icmp_seq=1 ttl=59 time=14.8 ms 64 bytes from 172.67.198.127: icmp_seq=2 ttl=59 time=13.7 ms ^C --- bitsearch.to ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 1001ms rtt min/avg/max/mdev = 13.747/14.253/14.759/0.506 ms Unraid~# dig bitsearch.to ; <<>> DiG 9.20.13 <<>> bitsearch.to ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 27484 ;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; WARNING: recursion requested but not available ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; MBZ: 0x0900, udp: 1232 ;; QUESTION SECTION: ;bitsearch.to. IN A ;; ANSWER SECTION: bitsearch.to. 2311 IN A 0.0.0.0 ;; Query time: 1 msec ;; SERVER: 1.0.0.1#53(1.0.0.1) (UDP) ;; WHEN: Sat Nov 01 23:47:08 CDT 2025 ;; MSG SIZE rcvd: 69 ~# cat /etc/resolv.conf # Generated by rc.inet1 nameserver 1.0.0.1 # eth0:v4 ~# ping bitsearch.to PING bitsearch.to (127.0.0.1) 56(84) bytes of data. 64 bytes from Unraid (127.0.0.1): icmp_seq=1 ttl=64 time=0.015 ms 64 bytes from Unraid (127.0.0.1): icmp_seq=2 ttl=64 time=0.025 ms 64 bytes from Unraid (127.0.0.1): icmp_seq=3 ttl=64 time=0.019 ms 64 bytes from Unraid (127.0.0.1): icmp_seq=4 ttl=64 time=0.038 ms ^C --- bitsearch.to ping statistics --- 4 packets transmitted, 4 received, 0% packet loss, time 3099ms rtt min/avg/max/mdev = 0.015/0.024/0.038/0.008 ms When testing inside Dockers, they mimic the host and have the same issue.
-
Having those variables themselves won't enable passthrough for nvidia cards. You have to enable "Advanced" view in dockerman and go to "extra parameters' and add "--runtime=nvidia" otherwise you'll get no hw transcode even though you have all the nvidia variables for the docker.
-
I cannot get the onlyoffice-document server docker working for the love of me. I cannot understand how we have Dockers which should make this a very turnkey process and it becomes a very NOT turn-key process. I've followed instructions and there just isn't any comprehensive guide to get this nightmare working. I've tried getting both onlyoffice and collabora working, neither of which I could get working. Neither of which seem to have a very good document explaining how to get it up and working as a docker either. If anyone can break this down for me, I'd appreciate it, because I've fought this for hours and am giving up until someone can explain this to me. I've generated the keys/certs etc but cannot connect on https. nextcloud now requires https for some reason. It feels like someone delivered a produce with some assembly required and no instructions on how to assemble it.
-
This is due to missing/broken UDEV rules. You can add a tweaked persistent-storage udev rule to /etc/udev/rules.d/ and reload udev to make the issue stop. to fix this, just download the rules, copy rules to server, then in unraid root terminal go to folder where rules were placed and: # mv 60-persistent-storage.rules /etc/udev/rules.d/ # udevadm control --reload-rules && udevadm trigger Now this fix isn't permanent. If you want it to be permanent, you need the user scripts plugin and set the plugin to echo the contents of that file into /etc/udev/rules.d/60-persistent-rules.storage and then run the reload commands. https://forum.makemkv.com/forum/viewtopic.php?t=25357 https://forum.manjaro.org/t/udev-persistent-persistent-storage-rules-for-dev-sr-hangs-udev/108411/2 https://github.com/systemd/systemd/pull/23127 (which was ridiculously ignored and the kernel/media blamed for udev not handling exceptions) I actually use a docker that monitors an external Bluray drive and rips discs the moment they're inserted and it texts my phone when its done so I can move on to the next one. My family loves movies and we're always digging in the bargain bin or buying movies when rental stores sell them off or go out of business. Then I put the media away after ripping it because my children liked to use them like Frisbees. So now they're only allowed to watch movies via the Plex server on their Roku. Optical Storage isn't dead! 60-persistent-storage.rules
-
Interesting, I'm not sure other than that docker also has a webUI? The scripts have similar lines, (they are effectively doing similar/the same thing) but that docker breaks it up into a few scripts rather than 1. If you test it let us know how it works. My only issue with rix docker is that if I try to use a full key, it doesn't work, it only uses the beta key even though I have entered the purchased key. Not really an issue as re-installing/updating the docker fixes the betakey problem.
-
Yes. If you check my post above you'll see ls -al of disks5-10 look like this: I ran unbalance on these drives 3 times to be sure, checked there were no files left, then did a full rm -rf /mnt/disk#/* on each drive I planned to wipe and then mkdir -p /mnt/disk#/clear-me on every disk I planned to wipe. I'm 100% positive the drives were empty besides the clear-me folder. I doubt its a problem, but these drives are all formatted BTRFS not XFS. It could also be some incompatibility with 6.10.3, not sure. I ended up just removing them from the machine and creating a new config for the array and rebuilding the parity drives.
-
What is up with the zero drive script? It immediately gives up. *** Clear an unRAID array data drive *** v1.4 Checking all array data drives (may need to spin them up) ... Checked 10 drives, did not find an empty drive ready and marked for clearing! To use this script, the drive must be completely empty first, no files or folders left on it. Then a single folder should be created on it with the name 'clear-me', exactly 8 characters, 7 lowercase and 1 hyphen. This script is only for clearing unRAID data drives, in preparation for removing them from the array. It does not add a Preclear signature. Script Finished Jul 10, 2022 19:21.37 Full logs for this script are available at /tmp/user.scripts/tmpScripts/ZeroDisks_ShrinkArray/log.txt ^C root@Oceans:~# ls -al /mnt/disk* /mnt/disk1: total 16 drwxrwxrwx 1 nobody users 84 Jul 10 04:30 ./ drwxr-xr-x 18 root root 360 Jul 10 00:12 ../ drwxrwxrwx+ 1 nobody users 190 Jul 10 18:28 Docker/ drwxrwxrwx 1 nobody users 14 Jul 4 22:49 Downloads/ drwxrwxrwx 1 nobody users 60 Jul 6 03:26 ZDRIVE/ drwxrwxrwx 1 nobody users 0 Jul 20 2021 appdata/ drwxrwxrwx 1 nobody users 16 Apr 16 2021 home/ drwxrwxrwx 1 nobody users 1884 Jul 9 04:40 system/ drwxrwxrwx 1 nobody users 138 Dec 31 2017 tftp/ /mnt/disk10: total 16 drwxrwxrwx 1 nobody users 16 Jul 10 18:33 ./ drwxr-xr-x 18 root root 360 Jul 10 00:12 ../ drwxrwxrwx 1 nobody users 0 Jul 10 18:33 clear-me/ /mnt/disk2: total 16 drwxrwxrwx 1 nobody users 12 Jul 10 04:30 ./ drwxr-xr-x 18 root root 360 Jul 10 00:12 ../ drwxrwxrwx+ 1 nobody users 260 Jul 9 23:38 Docker/ /mnt/disk3: total 16 drwxrwxrwx 1 nobody users 84 Jul 10 04:30 ./ drwxr-xr-x 18 root root 360 Jul 10 00:12 ../ drwxrwxrwx+ 1 nobody users 188 Jul 9 23:38 Docker/ drwxrwxrwx 1 nobody users 0 Jul 6 22:31 Downloads/ drwxr-xr-x 1 nobody users 0 May 9 09:08 ISOs/ drwxrwxrwx 1 nobody users 32 Jul 6 22:28 ZDRIVE/ drwxrwxrwx 1 nobody users 0 Jul 20 2021 appdata/ drwxrwxrwx 1 nobody users 16 Jul 6 21:50 home/ drwxrwxrwx 1 nobody users 394 Jul 6 22:31 system/ /mnt/disk4: total 16 drwxrwxrwx 1 nobody users 66 Jul 10 04:30 ./ drwxr-xr-x 18 root root 360 Jul 10 00:12 ../ drwxrwxrwx+ 1 nobody users 170 Jul 6 12:48 Docker/ drwxrwxrwx 1 nobody users 8 Jun 5 2021 ZDRIVE/ drwxrwxrwx 1 nobody users 0 Jul 20 2021 appdata/ drwxrwxrwx 1 nobody users 38 Jul 6 12:47 home/ drwxrwxrwx 1 nobody users 96 Jul 6 12:48 system/ drwxrwxrwx 1 nobody users 0 Dec 31 2017 tftp/ /mnt/disk5: total 16 drwxrwxrwx 1 nobody users 16 Jul 10 18:35 ./ drwxr-xr-x 18 root root 360 Jul 10 00:12 ../ drwxrwxrwx 1 nobody users 0 Jul 10 18:35 clear-me/ /mnt/disk6: total 16 drwxrwxrwx 1 nobody users 16 Jul 10 18:35 ./ drwxr-xr-x 18 root root 360 Jul 10 00:12 ../ drwxrwxrwx 1 nobody users 0 Jul 10 18:35 clear-me/ /mnt/disk7: total 16 drwxrwxrwx 1 nobody users 16 Jul 10 18:34 ./ drwxr-xr-x 18 root root 360 Jul 10 00:12 ../ drwxrwxrwx 1 nobody users 0 Jul 10 18:34 clear-me/ /mnt/disk8: total 16 drwxrwxrwx 1 nobody users 16 Jul 10 18:34 ./ drwxr-xr-x 18 root root 360 Jul 10 00:12 ../ drwxrwxrwx 1 nobody users 0 Jul 10 18:34 clear-me/ /mnt/disk9: total 16 drwxrwxrwx 1 nobody users 16 Jul 10 18:33 ./ drwxr-xr-x 18 root root 360 Jul 10 00:12 ../ drwxrwxrwx 1 nobody users 0 Jul 10 18:33 clear-me/ /mnt/disks: total 0 drwxrwxrwt 2 nobody users 40 Jul 10 00:11 ./ drwxr-xr-x 18 root root 360 Jul 10 00:12 ../
-
Lemme know the name of that docker with a link. This could be my solution!
-
I'm running a Ryzen Threadripper 3970X with 128G UECC memory in an ASROCK Creator TRX40 board, latest Beta BIOS, no stability issues. This could be various issues. 1. Are you updated to the latest BIOS version? 2. do you have fTPM disabled or enabled? If enabled, you'll want the latest BIOS update that fixes an fTPM stuttering issue. https://www.amd.com/en/support/kb/faq/pa-410 3. What speed are you running your Unbuffered ECC Memory at? Don't expect greater than 2933mhz for ECC memory on Ryzen 3XXX or lower. Some only work at 2666mhz. 4. If your Memory speeds aren't the problem, check your memory timings. There can be multiple jedec settings for timings or none requiring you to enter them manually to spec. 5. In the BIOS have you disabled all power saving nonsense such as suspend to RAM, aggressive ASPM, ALPM, etc. (I've found aggressive power management implementation in my old supermicro server board was a problem for my HDDs) 6. If you've done all the above, is your motherboard auto overclocking the CPU or RAM? disable auto-overclocking. As for specifics, I need to know the exact hardware in the build including the memory being used and what clock speeds and timings its rated for and what you have configured. Your logs here show normal gskill memory (non-ecc) and its running at the wrong speed and voltage (F4-3600C16-8GVKC running at 2133mhz and 1.2V). I also hope you're using UDIMM and not RDIMM ECC as RDIMM shouldn't work at all. Getting SMBIOS data from sysfs. SMBIOS 3.3.0 present. Handle 0x0018, DMI type 17, 92 bytes Memory Device Array Handle: 0x0010 Error Information Handle: 0x0017 Total Width: Unknown Data Width: Unknown Size: No Module Installed Form Factor: Unknown Set: None Locator: DIMM 0 Bank Locator: P0 CHANNEL A Type: Unknown Type Detail: Unknown Speed: Unknown Manufacturer: Unknown Serial Number: Unknown Asset Tag: Not Specified Part Number: Unknown Rank: Unknown Configured Memory Speed: Unknown Minimum Voltage: Unknown Maximum Voltage: Unknown Configured Voltage: Unknown Memory Technology: Unknown Memory Operating Mode Capability: Unknown Firmware Version: Unknown Module Manufacturer ID: Unknown Module Product ID: Unknown Memory Subsystem Controller Manufacturer ID: Unknown Memory Subsystem Controller Product ID: Unknown Non-Volatile Size: None Volatile Size: None Cache Size: None Logical Size: None Handle 0x001A, DMI type 17, 92 bytes Memory Device Array Handle: 0x0010 Error Information Handle: 0x0019 Total Width: 64 bits Data Width: 64 bits Size: 8 GB Form Factor: DIMM Set: None Locator: DIMM 1 Bank Locator: P0 CHANNEL A Type: DDR4 Type Detail: Synchronous Unbuffered (Unregistered) Speed: 2133 MT/s Manufacturer: Unknown Serial Number: 00000000 Asset Tag: Not Specified Part Number: F4-3600C16-8GVKC Rank: 1 Configured Memory Speed: 2133 MT/s Minimum Voltage: 1.2 V Maximum Voltage: 1.2 V Configured Voltage: 1.2 V Memory Technology: DRAM Memory Operating Mode Capability: Volatile memory Firmware Version: Unknown Module Manufacturer ID: Bank 5, Hex 0xCD Module Product ID: Unknown Memory Subsystem Controller Manufacturer ID: Unknown Memory Subsystem Controller Product ID: Unknown Non-Volatile Size: None Volatile Size: 8 GB Cache Size: None Logical Size: None Handle 0x001D, DMI type 17, 92 bytes Memory Device Array Handle: 0x0010 Error Information Handle: 0x001C Total Width: Unknown Data Width: Unknown Size: No Module Installed Form Factor: Unknown Set: None Locator: DIMM 0 Bank Locator: P0 CHANNEL B Type: Unknown Type Detail: Unknown Speed: Unknown Manufacturer: Unknown Serial Number: Unknown Asset Tag: Not Specified Part Number: Unknown Rank: Unknown Configured Memory Speed: Unknown Minimum Voltage: Unknown Maximum Voltage: Unknown Configured Voltage: Unknown Memory Technology: Unknown Memory Operating Mode Capability: Unknown Firmware Version: Unknown Module Manufacturer ID: Unknown Module Product ID: Unknown Memory Subsystem Controller Manufacturer ID: Unknown Memory Subsystem Controller Product ID: Unknown Non-Volatile Size: None Volatile Size: None Cache Size: None Logical Size: None Handle 0x001F, DMI type 17, 92 bytes Memory Device Array Handle: 0x0010 Error Information Handle: 0x001E Total Width: 64 bits Data Width: 64 bits Size: 8 GB Form Factor: DIMM Set: None Locator: DIMM 1 Bank Locator: P0 CHANNEL B Type: DDR4 Type Detail: Synchronous Unbuffered (Unregistered) Speed: 2133 MT/s Manufacturer: Unknown Serial Number: 00000000 Asset Tag: Not Specified Part Number: F4-3600C16-8GVKC Rank: 1 Configured Memory Speed: 2133 MT/s Minimum Voltage: 1.2 V Maximum Voltage: 1.2 V Configured Voltage: 1.2 V Memory Technology: DRAM Memory Operating Mode Capability: Volatile memory Firmware Version: Unknown Module Manufacturer ID: Bank 5, Hex 0xCD Module Product ID: Unknown Memory Subsystem Controller Manufacturer ID: Unknown Memory Subsystem Controller Product ID: Unknown Non-Volatile Size: None Volatile Size: 8 GB Cache Size: None Logical Size: None
-
Thats a good point! I never really considered RAID0 as a option, but if you think about it, I have an array with dual parity. The likelihood that I'll have an issue there AND with a Backup RAID0 Pool isn't high, and only 1 week worth of revert/recovery if the RAID0 fails isn't that big of a deal. This isn't mission critical business data. Its just my personal tinker toys, Plex server, dockers for wikis, other webservices, etc, and a couple VMs that are actually self configured/deployable via yaml scripts using yip to act as a kubernetes cluster for Linux package building. My cache pool is a RAID0 and the mover runs daily with zero issues. I can see this being a valid option as well for personal use.
-
Wow, I've not looked at backblaze pricing, but $70/year for unlimited personal seems pretty amazing and $5/TB/Month for Backblaze B2 is pretty good too when looking from a business perspective! Thats definitely one option considering I'd have to buy multiple (5-6) drives at $250 each minimum to have a local backup and I'd most likely go with the personal backup option if that were allowed. Thanks for the input!
-
So its been a dream of mine to get an LTO Tape Drive one day and run backups. In reality, my wife will never let me spend that kind of money for a drive. HDDs on the other hand are far cheaper for the same amount of storage (~30T). So I've been upgrading my cute Original WD Red 3T drives to Seagate EXOS 3x14T and 3x8T drives. But newer larger drives don't exactly have the same level of reliability in my experience in Datacenters. So I'd like to make use of the extra drive bays I'm freeing up. I have 12 bays. I plan to use 6 for my array with dual parity. I'd like to use the other 4-6 bays for a weekly backup. Evidently you cannot create 2 arrays in Unraid so my 2nd Array for weekly backup idea isn't going to work. What do you recommend here? Should I just create a "pool" for backups with no parity? should I risk BTRFS RAID6 pool as a backup solution, or just go the more expensive route to BTRFS RAID10 pool? Something else? The server is on a 1500Watt UPS. Risk of unclean shutdown is low. writes would only be weekly and incremental. No need to completely rewrite the entire backup.
-
Unfortunately, no. The Dependency Hell threw a wrench in it. I've not tried since. Dealing with such deps on a static system is risky. This kind of power is really needed on the hypervisor side. You would also have to script/add/install all the deps and tool itself on every install due to the static nature of unraid (which is fair). That being said, if all the deps and the tool were installed from the beginning, this would be far less of a problem.
-
I too am interesting in this!
-
I can't get the onlyoffice docker to work. its just a permanently loading bar. I only wanted to try this locally via local IP, but its stuck.
-
I have linux VMs. They are actually build nodes used to build packages for a linux distribution. So my VMs accept jobs to compile and packages inside containers, upload said packages, then delete everything and start another job. I'm not sure if your suggestion works in this scenario does it?
-
You might be able to perform a pull request to update the main project is you have through testing and proof of stability.
-
It would be nice to have virt-sparsify to reduce VM disks size when they have zeros/unused space. https://libguestfs.org/virt-sparsify.1.html
-
I really could use this. I use my personal server for an OpenSource Linux project so giving my team members access would be really handy. I'd like to see 1. Multiple users enabled for WebUI (simple checkbox within the user profile would be nice) 2. Different levels of access. (Example: Restart VMs, VM Access, but not Creation/Deletion or root host shell access) 3. Log Users login and change actions (VM/docker reboot, deletion, creation, etc) Just some SMB features could be handy.
-
@rix Something has broken the docker here very recently makemkvcon is missing from the container which breaks the docker entirely.
-
I can't seem to update the plugin even though it tells me there's an update. I tried removing the plugin to reinstall it, and now it still fails so it never installs. plugin: updating: vmbackup.plg Removing package: xmlstarlet-1.6.1-x86_64-1_slonly Removing files: Removing package: pigz-2.3-x86_64-2_slonly Removing files: +============================================================================== | Installing new package /boot/config/plugins/vmbackup/packages/xmlstarlet-1.6.1-x86_64-1_slonly.txz +============================================================================== Verifying package xmlstarlet-1.6.1-x86_64-1_slonly.txz. Installing package xmlstarlet-1.6.1-x86_64-1_slonly.txz: PACKAGE DESCRIPTION: # xmlstarlet (command line xml tool) # # XMLStarlet is a command line XML toolkit that can be used to # transform, query, validate, and edit XML documents and files using # a simple set of shell commands, which work similarly to 'grep', # 'sed', 'awk', 'tr', 'diff', or 'patch' on plain text files. # # Homepage https://sourceforge.net/projects/xmlstar/ # Executing install script for xmlstarlet-1.6.1-x86_64-1_slonly.txz. Package xmlstarlet-1.6.1-x86_64-1_slonly.txz installed. +============================================================================== | Installing new package /boot/config/plugins/vmbackup/packages/pigz-2.3-x86_64-2_slonly.txz +============================================================================== Verifying package pigz-2.3-x86_64-2_slonly.txz. Installing package pigz-2.3-x86_64-2_slonly.txz: PACKAGE DESCRIPTION: # pigz (Parallel gzip) # # pigz, which stands for parallel implementation of gzip, is a fully # functional replacement for gzip that exploits multiple processors and # multiple cores to the hilt when compressing data. pigz was written by # Mark Adler, and uses the zlib and pthread libraries. # # Home page: http://www.zlib.net/pigz/ # Package pigz-2.3-x86_64-2_slonly.txz installed. +============================================================================== | Skipping package vmbackup-v0.2.2-2021.02.03 (already installed) +============================================================================== plugin: run failed: /bin/bash retval: 1 After upgrade to stable 6.9.0 from RC1, I tried to install the plugin again. Still Fails: plugin: installing: https://raw.githubusercontent.com/jtok/unraid.vmbackup/master/vmbackup.plg plugin: downloading https://raw.githubusercontent.com/jtok/unraid.vmbackup/master/vmbackup.plg plugin: downloading: https://raw.githubusercontent.com/jtok/unraid.vmbackup/master/vmbackup.plg ... done No such package: xmlstarlet*. Can't remove. No such package: pigz*. Can't remove. +============================================================================== | Installing new package /boot/config/plugins/vmbackup/packages/xmlstarlet-1.6.1-x86_64-1_slonly.txz +============================================================================== Verifying package xmlstarlet-1.6.1-x86_64-1_slonly.txz. Installing package xmlstarlet-1.6.1-x86_64-1_slonly.txz: PACKAGE DESCRIPTION: # xmlstarlet (command line xml tool) # # XMLStarlet is a command line XML toolkit that can be used to # transform, query, validate, and edit XML documents and files using # a simple set of shell commands, which work similarly to 'grep', # 'sed', 'awk', 'tr', 'diff', or 'patch' on plain text files. # # Homepage https://sourceforge.net/projects/xmlstar/ # Executing install script for xmlstarlet-1.6.1-x86_64-1_slonly.txz. Package xmlstarlet-1.6.1-x86_64-1_slonly.txz installed. +============================================================================== | Installing new package /boot/config/plugins/vmbackup/packages/pigz-2.3-x86_64-2_slonly.txz +============================================================================== Verifying package pigz-2.3-x86_64-2_slonly.txz. Installing package pigz-2.3-x86_64-2_slonly.txz: PACKAGE DESCRIPTION: # pigz (Parallel gzip) # # pigz, which stands for parallel implementation of gzip, is a fully # functional replacement for gzip that exploits multiple processors and # multiple cores to the hilt when compressing data. pigz was written by # Mark Adler, and uses the zlib and pthread libraries. # # Home page: http://www.zlib.net/pigz/ # Package pigz-2.3-x86_64-2_slonly.txz installed. +============================================================================== | Installing new package /boot/config/plugins/vmbackup/vmbackup-v0.2.2-2021.02.03.txz +============================================================================== Verifying package vmbackup-v0.2.2-2021.02.03.txz. Installing package vmbackup-v0.2.2-2021.02.03.txz: PACKAGE DESCRIPTION: Package vmbackup-v0.2.2-2021.02.03.txz installed. plugin: run failed: /bin/bash retval: 126
-
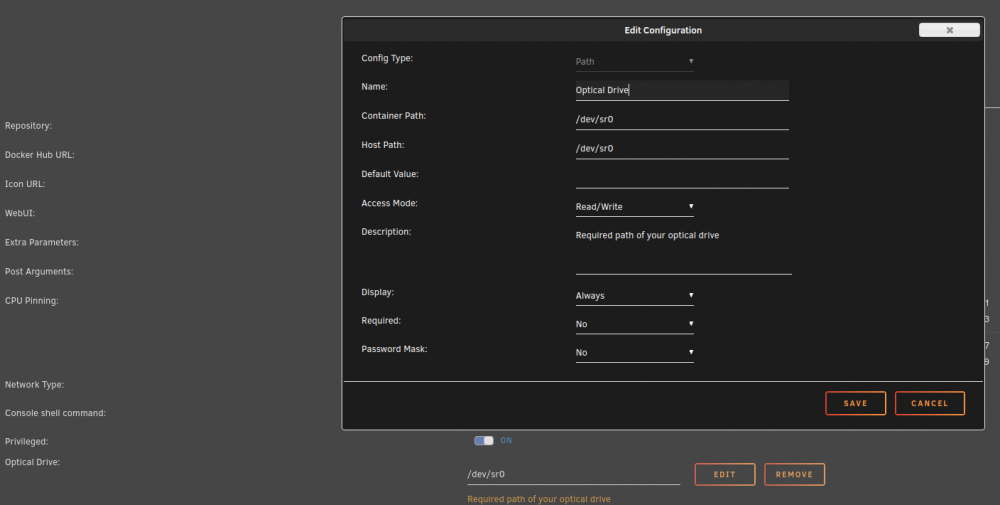
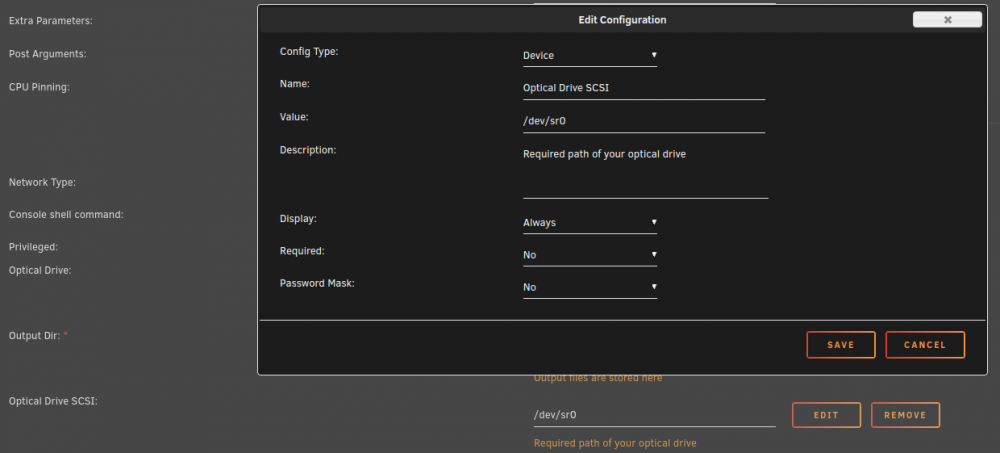
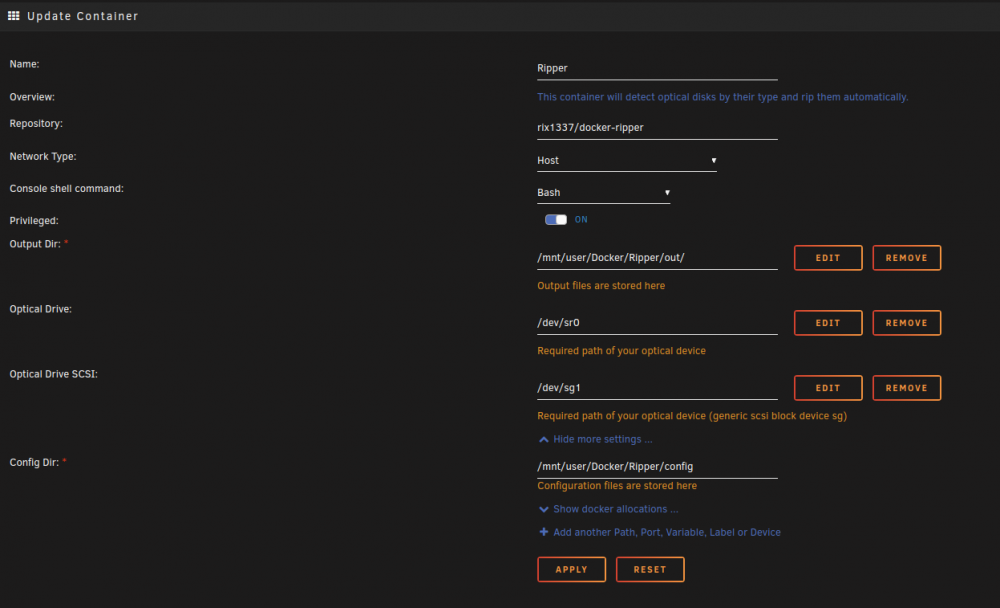
The ccextractor thing is still an issue as the location settings do not match. ccextractor wasn't installed in /usr/bin/ccextractor. Its been installed in /usr/local/bin/ccextractor . So the errors still exist. I've not added that settings.conf. MSG:5015,131072,4,"Saving 1 titles into directory file:///out/DVD/ADDAMSFAMILY using profile 'Default' from file '/config/default.mmcp.xml'","Saving %1 titles into directory %2 using profile '%3' from file '%4'","1","file:///out/DVD/ADDAMSFAMILY","Default","/config/default.mmcp.xml" MSG:4040,0,1,"Unable to execute external program 'ccextractor' as its path is not set in preferences","Unable to execute external program '%1' as its path is not set in preferences","ccextractor" MSG:4040,0,1,"Unable to execute external program 'ccextractor' as its path is not set in preferences","Unable to execute external program '%1' as its path is not set in preferences","ccextractor" MSG:4040,0,1,"Unable to execute external program 'ccextractor' as its path is not set in preferences","Unable to execute external program '%1' as its path is not set in preferences","ccextractor" Side note unrelated to ccextractor: I've been noticing sometimes the docker will lockup (its rare overall, but I have it running 24/7 whether its in use or not, I mean why not?). Well sometimes after ripping a few discs, the docker will just peg once CPU core and has a hard time progressing. I couldn't really figure out what was going on. I just know that attempting to kill/stop the docker would result in the docker just being hard locked and refusing to stop. Showing the log from WebUI fails and you cannot access the terminal either. Unplugging the optical drive would allow the docker to stop (its an external USB3 bluray drive). After plugging the drive back in and starting the docker again I noticed that sometimes the output files in /out are not being placed there as the root folder but in another folder called "," and inside that folder is another folder that is the drive name "DRV:0,2,999,12,"BD-RE ASUS BW-12D1S-U E401"" and in that folder is where the output is being placed during the RIP. I couldn't figure this out for the longest time. I'd have to reboot the server to fix it and force it to rip in the correct location. Well I think I finally discovered it today. The issue occurred again last night, I started doing some investigating of the script (no issues found), started looking for any issues and eventually jumped into the host servers /dev folder only to find /dev/sr0 was not a block device but a FOLDER! I couldn't think of why this would happen so I stopped the docker, removed the drive, deleted that folder, connected the drive back and now /dev/sr0 is a block device again! This explains what's probably happening when I reboot the machine as the block device gets recreated then. I started a new rip and surprise, its ripping like it's supposed to in the correct folder now! OK, time to investigate the docker. Now I noticed something interesting. Its passing optical drive configuration AS A PATH! What is should be doing is passing /dev/sr0 as a DEVICE. would it be possible to tweak the docker to do that? Or is it possibly my old config is being kept in place during updates? Just figured I'd pass on this info. Thanks for everything you do! this Docker is GOLD. Here is my current config and it seems to be working without extra parameters or anything: [2415694.831852] usb 8-4: new SuperSpeed Gen 1 USB device number 4 using xhci_hcd [2415694.845100] usb-storage 8-4:1.0: USB Mass Storage device detected [2415694.845260] usb-storage 8-4:1.0: Quirks match for vid 174c pid 55aa: 400000 [2415694.845331] scsi host1: usb-storage 8-4:1.0 [2415695.868323] scsi 1:0:0:0: CD-ROM ASUS BW-12D1S-U E401 PQ: 0 ANSI: 0 [2415695.876630] sr 1:0:0:0: Power-on or device reset occurred [2415695.899356] sr 1:0:0:0: [sr0] scsi3-mmc drive: 125x/125x writer dvd-ram cd/rw xa/form2 cdda tray [2415695.905593] sr 1:0:0:0: Attached scsi CD-ROM sr0 [2415695.905667] sr 1:0:0:0: Attached scsi generic sg1 type 5
-
Thanks, this was a blueray, but I've seen it with DVDs as well. I'll give it a test and see how it goes!
-
@rix Did something change with makemkv? It seems the logs shows an attempt to reach an application called ccextractor which isn't in the docker? MSG:5015,131072,4,"Saving 1 titles into directory file:///out/Ripper/DVD/ARCHIVE using profile 'Default' from file '/config/default.mmcp.xml'","Saving %1 titles into directory %2 using profile '%3' from file '%4'","1","file:///out/Ripper/DVD/ARCHIVE","Default","/config/default.mmcp.xml" MSG:4040,0,1,"Unable to execute external program 'ccextractor' as its path is not set in preferences","Unable to execute external program '%1' as its path is not set in preferences","ccextractor"
-
It could be the script ripper.sh. special characters tend to need to be broken out with a "\" before they're allowed to be used in bash/shell scripts etc. You might take a look and see if you can edit the script by copying the cd ripping line that creates the folder and statically name the folder and comment out the original line.




