




thomast_88
Community Developer
-
Joined
-
Last visited
Everything posted by thomast_88
-
Looks like mine. Other users experienced that error aswell. (https://gitlab.com/gitlab-org/omnibus-gitlab/issues/721) Could you try to delete the docker, wipe /mnt/cache/appdata/gitlab-ce and try to install it from stracth? Ok did what you suggested, but I get either "Site can't be reached" or it changes the IP address of my unRAID box to chars. Example: IP is 192.168.1.2 (Gitlab is point to port 45300), opening the webui it takes me to the site but then redirects to http://5a2ef303db9f/users/sign_in. Here's the log http://pastebin.com/L7p6N7Zg. It looks like its the SHA2 key (root@5a2ef303db9f). Any ideas? Use a direct link (like i suggested in a previous post). In Your case http://192.168.1.2:45300/users/sign_in I have yet to figure out why it's changing the ip address to these chars. It started on that 2 days ago when they pushed the last update. The direct link takes me to: http://5a2ef303db9f/users/password/edit?reset_password_token=3yaDdMTpS3DKxbydzfdJ. :o Whenever it inserts those magic chars just replace it with the correct IP/Port. Eventually it will work after all has been setup. Remember to use the root user for the intial login. I will try to figure out why the IP gets replaced with those chars.
-
Looks like mine. Other users experienced that error aswell. (https://gitlab.com/gitlab-org/omnibus-gitlab/issues/721) Could you try to delete the docker, wipe /mnt/cache/appdata/gitlab-ce and try to install it from stracth? Ok did what you suggested, but I get either "Site can't be reached" or it changes the IP address of my unRAID box to chars. Example: IP is 192.168.1.2 (Gitlab is point to port 45300), opening the webui it takes me to the site but then redirects to http://5a2ef303db9f/users/sign_in. Here's the log http://pastebin.com/L7p6N7Zg. It looks like its the SHA2 key (root@5a2ef303db9f). Any ideas? Use a direct link (like i suggested in a previous post). In Your case http://192.168.1.2:45300/users/sign_in I have yet to figure out why it's changing the ip address to these chars. It started on that 2 days ago when they pushed the last update.
-
Looks like mine. Other users experienced that error aswell. (https://gitlab.com/gitlab-org/omnibus-gitlab/issues/721) Could you try to delete the docker, wipe /mnt/cache/appdata/gitlab-ce and try to install it from stracth?
-
And you're not using a user share e.g. /mnt/user/appdata rather than /mnt/cache/appdata for the application files?
-
You've got to give me something in order for me to help. What happens when you try to access the WebUI? Are you trying HTTP or HTTPS? - You should use http unless you've changed the config file to make https work Can you try with this direct link: http://[iP]:[PORT]/users/sign_in Post the output of the log on pastebin so we can see it
-
Can you post the docker run command which is being used or a screenshot of the docker configuration? Mine is working fine with this config: /usr/local/emhttp/plugins/dynamix.docker.manager/scripts/docker run -d --name="GitLab-CE" --net="bridge" -e TZ="Europe/Paris" -e HOST_OS="unRAID" -p 45300:80/tcp -p 45305:443/tcp -p 45310:22/tcp -v "/mnt/cache/appdata/gitlab-ce/config":"/etc/gitlab":rw -v "/mnt/cache/appdata/gitlab-ce/data":"/var/opt/gitlab":rw -v "/mnt/cache/appdata/gitlab-ce/log":"/var/log/gitlab":rw gitlab/gitlab-ce
-
Any progress on this? :-)
-
Which version of unRAID? Can you post a screenshot of your container configuration?
-
Does the same thing happen if you run the command in command line? Just go edit the container, remove the problem variable and hit save. Then you will have the docker run command in the last command box. Copy it and ssh into your server and issue the command with the added problem variable. If that works, use the full path from /usr/local/emhttp/etc... and see if that works. If not, it's a bug in dockerman. Ok i tried both things, this is the result: docker run (works fine): root@unRAID:/mnt/user/appdata# docker run -d --name="GitLab-CE" --net="bridge" -e TZ="Europe/Paris" -e HOST_OS="unRAID" -p 45300:80/tcp -p 45305:443/tcp -p 45310:22/tcp -v "/mnt/cache/appdata/gitlab-ce/config":"/etc/gitlab":rw -v "/mnt/cache/appdata/gitlab-ce/data":"/var/opt/gitlab":rw -v "/mnt/cache/appdata/gitlab-ce/log":"/var/log/gitlab":rw --env GITLAB_OMNIBUS_CONFIG="external_url 'http://my.domain.com/'; gitlab_rails['lfs_enabled'] = true;" gitlab/gitlab-ce 724e403bc962631a9aa773d24f8657055f6d18f6db854a38794916e4bcf7680e docker run full path (works fine): root@unRAID:/mnt/user/appdata# /usr/local/emhttp/plugins/dynamix.docker.manager/scripts/docker run -d --name="GitLab-CE" --net="bridge" -e TZ="Europe/Paris" -e HOST_OS="unRAID" -p 45300:80/tcp -p 45305:443/tcp -p 45310:22/tcp -v "/mnt/cache/appdata/gitlab-ce/config":"/etc/gitlab":rw -v "/mnt/cache/appdata/gitlab-ce/data":"/var/opt/gitlab":rw -v "/mnt/cache/appdata/gitlab-ce/log":"/var/log/gitlab":rw --env GITLAB_OMNIBUS_CONFIG="external_url 'http://my.domain.com/'; gitlab_rails['lfs_enabled'] = true;" gitlab/gitlab-ce 7b3c680e8609383b4d28d9f134d4735c162acfd6a1811e5ca0dcbe5ba8c9604b So it must be something in the WebUI i suppose? Looks like a webgui bug then. You should file a defect report so it gets picked up. I'm confused who this should be filed to. The unRAID team or Squid (creator of CA) ? It's not CA. So go to the defect reports board and read the sticky on how to report a defect and then make the defect report accordingly. Ok thanks for the help. For reference i filed in a defect report about this bug: https://lime-technology.com/forum/index.php?topic=50385.0
-
Does the same thing happen if you run the command in command line? Just go edit the container, remove the problem variable and hit save. Then you will have the docker run command in the last command box. Copy it and ssh into your server and issue the command with the added problem variable. If that works, use the full path from /usr/local/emhttp/etc... and see if that works. If not, it's a bug in dockerman. Ok i tried both things, this is the result: docker run (works fine): root@unRAID:/mnt/user/appdata# docker run -d --name="GitLab-CE" --net="bridge" -e TZ="Europe/Paris" -e HOST_OS="unRAID" -p 45300:80/tcp -p 45305:443/tcp -p 45310:22/tcp -v "/mnt/cache/appdata/gitlab-ce/config":"/etc/gitlab":rw -v "/mnt/cache/appdata/gitlab-ce/data":"/var/opt/gitlab":rw -v "/mnt/cache/appdata/gitlab-ce/log":"/var/log/gitlab":rw --env GITLAB_OMNIBUS_CONFIG="external_url 'http://my.domain.com/'; gitlab_rails['lfs_enabled'] = true;" gitlab/gitlab-ce 724e403bc962631a9aa773d24f8657055f6d18f6db854a38794916e4bcf7680e docker run full path (works fine): root@unRAID:/mnt/user/appdata# /usr/local/emhttp/plugins/dynamix.docker.manager/scripts/docker run -d --name="GitLab-CE" --net="bridge" -e TZ="Europe/Paris" -e HOST_OS="unRAID" -p 45300:80/tcp -p 45305:443/tcp -p 45310:22/tcp -v "/mnt/cache/appdata/gitlab-ce/config":"/etc/gitlab":rw -v "/mnt/cache/appdata/gitlab-ce/data":"/var/opt/gitlab":rw -v "/mnt/cache/appdata/gitlab-ce/log":"/var/log/gitlab":rw --env GITLAB_OMNIBUS_CONFIG="external_url 'http://my.domain.com/'; gitlab_rails['lfs_enabled'] = true;" gitlab/gitlab-ce 7b3c680e8609383b4d28d9f134d4735c162acfd6a1811e5ca0dcbe5ba8c9604b So it must be something in the WebUI i suppose? Looks like a webgui bug then. You should file a defect report so it gets picked up. I'm confused who this should be filed to. The unRAID team or Squid (creator of CA) ?
-
Does the same thing happen if you run the command in command line? Just go edit the container, remove the problem variable and hit save. Then you will have the docker run command in the last command box. Copy it and ssh into your server and issue the command with the added problem variable. If that works, use the full path from /usr/local/emhttp/etc... and see if that works. If not, it's a bug in dockerman. Ok i tried both things, this is the result: docker run (works fine): root@unRAID:/mnt/user/appdata# docker run -d --name="GitLab-CE" --net="bridge" -e TZ="Europe/Paris" -e HOST_OS="unRAID" -p 45300:80/tcp -p 45305:443/tcp -p 45310:22/tcp -v "/mnt/cache/appdata/gitlab-ce/config":"/etc/gitlab":rw -v "/mnt/cache/appdata/gitlab-ce/data":"/var/opt/gitlab":rw -v "/mnt/cache/appdata/gitlab-ce/log":"/var/log/gitlab":rw --env GITLAB_OMNIBUS_CONFIG="external_url 'http://my.domain.com/'; gitlab_rails['lfs_enabled'] = true;" gitlab/gitlab-ce 724e403bc962631a9aa773d24f8657055f6d18f6db854a38794916e4bcf7680e docker run full path (works fine): root@unRAID:/mnt/user/appdata# /usr/local/emhttp/plugins/dynamix.docker.manager/scripts/docker run -d --name="GitLab-CE" --net="bridge" -e TZ="Europe/Paris" -e HOST_OS="unRAID" -p 45300:80/tcp -p 45305:443/tcp -p 45310:22/tcp -v "/mnt/cache/appdata/gitlab-ce/config":"/etc/gitlab":rw -v "/mnt/cache/appdata/gitlab-ce/data":"/var/opt/gitlab":rw -v "/mnt/cache/appdata/gitlab-ce/log":"/var/log/gitlab":rw --env GITLAB_OMNIBUS_CONFIG="external_url 'http://my.domain.com/'; gitlab_rails['lfs_enabled'] = true;" gitlab/gitlab-ce 7b3c680e8609383b4d28d9f134d4735c162acfd6a1811e5ca0dcbe5ba8c9604b So it must be something in the WebUI i suppose?
-
Hi I'm trying to pass in a variable which contains a ';' in the value (it's a convention when using the official GitLab docker and you want to change some configuration key/value pairs: http://docs.gitlab.com/omnibus/docker/) However i encounter an issue as soon as i click "Add Container" or try to update the container with this particular variable. Variable name: GITLAB_OMNIBUS_CONFIG Variable value: external_url 'http://my.domain.com/'; gitlab_rails['lfs_enabled'] = true; I also tried adding it directly into the "Extra Parameters" like this: --env GITLAB_OMNIBUS_CONFIG="external_url 'http://my.domain.com/'; gitlab_rails['lfs_enabled'] = true;" but i still get the same error: The command failed. sh: /usr/local/emhttp: Is a directory Attached some screenshots as well
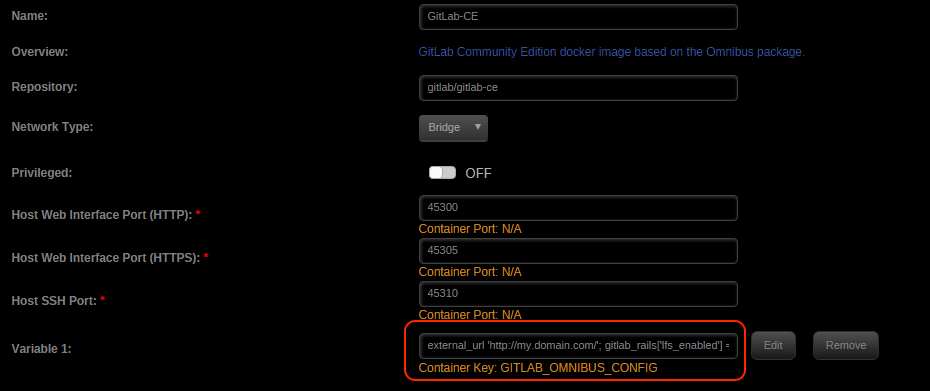
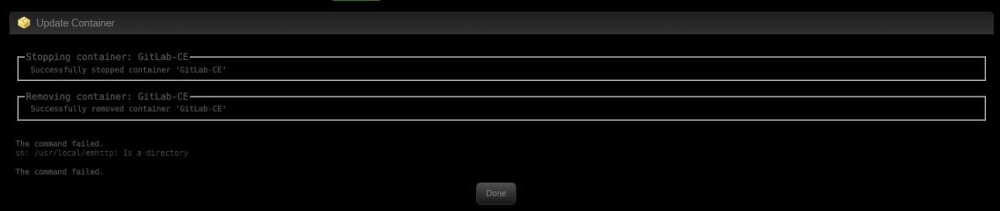
-
GitLab Community Edition docker image based on the Omnibus package. I just created a template for this. It's pretty easy to get up and running, as this docker contains all necessary dependencies already (Redis, PostgreSQL, Nginx etc.). Application Name: GitLab-CE Application Site: https://gitlab.com/ Docker Hub: https://hub.docker.com/r/gitlab/gitlab-ce/ Github: https://github.com/gitlabhq/gitlabhq unRAID Template: https://github.com/tynor88/docker-templates Setup/Configuration: http://docs.gitlab.com/omnibus/docker/ Feel free to post any questions/issues/requests relating to this docker in this thread.
-
How are you removing the files? This is just for files you delete over the network using SMB. Doh! Mostly through SSH (rm command) and FTP. But thanks for the clarification. Is there any way you can have like a recycle bin for rm commands?
-
I cannot get this plugin to work. I've attached a screenshot of my configuration, but for some reason no files i remove are inside the .Recycle.Bin folder (it's not even created). The only thing i see is some shortcuts inside /mnt/RecycleBin (but the the shortcuts points to nothing as there are no .Recycle.Bin folders in any of my shares).
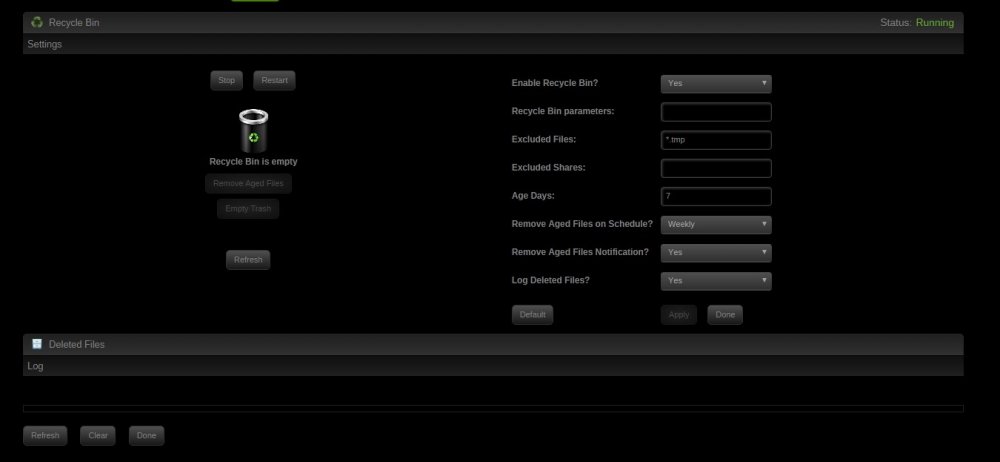

-
I am getting something similar on 6.2.0-beta21 Warning: file_get_contents(/boot/config/smb-extra.conf): failed to open stream: No such file or directory in /usr/local/emhttp/plugins/dynamix/include/DefaultPageLayout.php(300) : eval()'d code on line 16
-
root@HYDRA:/mnt/disk1/DockerApps# ifconfig bond0: flags=5443<UP,BROADCAST,RUNNING,PROMISC,MASTER,MULTICAST> mtu 1500 ether 10:c3:7b:6f:43:ae txqueuelen 0 (Ethernet) RX packets 376918292 bytes 545599728025 (508.1 GiB) RX errors 0 dropped 213548 overruns 0 frame 0 TX packets 35516033 bytes 6243595662 (5.8 GiB) TX errors 0 dropped 12 overruns 0 carrier 0 collisions 0 br0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.0.101 netmask 255.255.255.0 broadcast 192.168.0.255 ether 10:c3:7b:6f:43:ae txqueuelen 0 (Ethernet) RX packets 85104066 bytes 554801007870 (516.6 GiB) RX errors 0 dropped 13916 overruns 0 frame 0 TX packets 39609148 bytes 126332393253 (117.6 GiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 docker0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 172.17.42.1 netmask 255.255.0.0 broadcast 0.0.0.0 ether 46:e0:a9:09:01:15 txqueuelen 0 (Ethernet) RX packets 52898 bytes 14164401 (13.5 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 53867 bytes 30521239 (29.1 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 eth0: flags=6211<UP,BROADCAST,RUNNING,SLAVE,MULTICAST> mtu 1500 ether 10:c3:7b:6f:43:ae txqueuelen 1000 (Ethernet) RX packets 376704744 bytes 545585615783 (508.1 GiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 35516033 bytes 6243595662 (5.8 GiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 eth1: flags=6211<UP,BROADCAST,RUNNING,SLAVE,MULTICAST> mtu 1500 ether 10:c3:7b:6f:43:ae txqueuelen 1000 (Ethernet) RX packets 213548 bytes 14112242 (13.4 MiB) RX errors 0 dropped 213548 overruns 0 frame 0 TX packets 0 bytes 0 (0.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 device interrupt 18 memory 0xfbf00000-fbf20000 lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536 inet 127.0.0.1 netmask 255.0.0.0 loop txqueuelen 0 (Local Loopback) RX packets 137464 bytes 25960421 (24.7 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 137464 bytes 25960421 (24.7 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 veth17b05fb: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 ether 8e:b6:70:ea:a8:35 txqueuelen 0 (Ethernet) RX packets 2115 bytes 859529 (839.3 KiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 1924 bytes 1218400 (1.1 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 veth638c205: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 ether a6:2a:88:78:4c:66 txqueuelen 0 (Ethernet) RX packets 19556 bytes 2062340 (1.9 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 21441 bytes 9256959 (8.8 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 vetha052b41: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 ether 46:e0:a9:09:01:15 txqueuelen 0 (Ethernet) RX packets 699 bytes 548224 (535.3 KiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 897 bytes 705751 (689.2 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 virbr0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500 inet 192.168.122.1 netmask 255.255.255.0 broadcast 192.168.122.255 ether 52:54:00:fb:a4:f1 txqueuelen 0 (Ethernet) RX packets 0 bytes 0 (0.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 0 bytes 0 (0.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 vnet0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 ether fe:54:00:7c:e6:b8 txqueuelen 500 (Ethernet) RX packets 12455171 bytes 31394587093 (29.2 GiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 89716902 bytes 129283508307 (120.4 GiB) TX errors 0 dropped 5018 overruns 0 carrier 0 collisions 0 I'm a noob, but guessing from the ifconfig my docker needs to be pointed at br0 and not eth0 (default)? And if correct, I don't know how to go about doing that but I guess I can keep digging. I suspect it's down to the fact you've got bonding enabled on your Unraid machine as that's the only difference I see between my setup and yours. I went into webUI - edit page for docker; added a variable INTERFACE with a value of bond0 -- I can now access port 943. So I think my issue is resolved, but before I get too comfortable I just want to ask is this fix kosher? Also before this, I didn't realize I could do this. I.e. is there a technical reason it's mapped to eth0, or it's just default (you have to start somewhere)? Again, thank you for your assistance and time (not to mention patience to deal with this noob). Can I ask you how you added this interface? I'm also using a bond connection and cannot figure out how to set this up. I can currently only access the VPN web interface if I change the connection type to Bridge. [*]Click "Add another Path, Port or Variable" in the container configuration. [*]Name = Variable 3 [*]Target = INTERFACE [*]Value = bond0 Save and it should work.I'm experiencing that the GUI is unresponsive with this Docker. For instance clicking on "Settings" takes about 5 seconds to load the settings menu - sometimes it's even timing out. In other situations everything is running smoothly. Hardware shouldn't be the issue, as the CPU is not even running above 10%, and i have > 10 GB of rams free. I have already tried reinstalling, and stopping + starting the container several times. Any suggestions to this issue?




