




-Daedalus
Members
-
Joined
-
Last visited
Everything posted by -Daedalus
-
Share "backup". 1TB cache drive + 10TB HDD. Set min free to 500 GB > Size set is 285.5 GB. I can go a little above this, but around 380 GB or so, it'll revert to 285.5 GB. Nothing super in the logs, just: Jul 22 21:41:59 backup emhttpd: Starting services... Jul 22 21:41:59 backup emhttpd: shcmd (534): /etc/rc.d/rc.samba reload Jul 22 21:41:59 backup emhttpd: shcmd (537): exportfs -ra Jul 22 21:41:59 backup emhttpd: shcmd (539): /etc/rc.d/rc.avahidaemon reload It's quite irritating because It means OS drive backups from my desktop (typically ~450 GB) will clog the cache, causing the Proxmox backup VM I have there to pause, ruining backup jobs for the cluster, on top of my desktop not getting backed up. Last attempt was made at 21:44:30. Syslog is flooded with a bluetooth device warning, that's just me forgetting to disable the device on a replacement board that got swapped in yesterday, can ignore that. Diags attached. backup-diagnostics-20250722-2145.zip
-
At the moment it looks like colours are assigned alphabetically, which leads to different things having different colours from system to system, if certain things aren't enabled. First we have a system with only "System" and "ZFS cache", with ZFS being orange: But then, we have another system with a VM, meaning (I assume) that because V is before Z, the VM is orange, and ZFS here is yellow: My suggestion is that each thing should have an assigned colour so orange is always ZFS, yellow is always VM, etc. It's intuitive, consistent, and much more glancable for those of us with more than one machine.
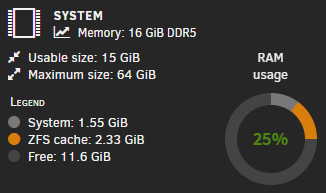
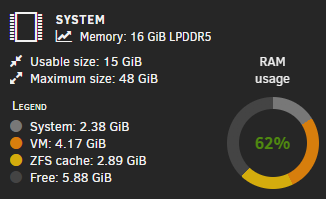
-
Sorry for the delay on this. Same behaviour as before. May 26 11:48:52 storage shfs: /usr/sbin/zfs rename 'ssd/games' 'ssd/games4' 2>&1 storage-diagnostics-20250526-1149.zip
-
Ah, should have more clearly pointed that out, apologies. I was actually able to create a new share, move data into it, and delete the old one, but that's not really a feasable solution for TB+ sized shares. I hadn't mentioned it before, but the only manual change I've made to the datasets is to change compression from lz4 to zstd. I can't see ths affecting things, as the ZFS part of this seems to work, the part outside of that doesn't. In this one, I've renamed "games" to "games3", and now we have: root@storage:~# zfs list NAME USED AVAIL REFER MOUNTPOINT ssd 2.56T 974G 92.9G /mnt/ssd ssd/games3 11.3G 974G 11.3G /mnt/ssd/games root@storage:~# zfs get all ssd/games3 NAME PROPERTY VALUE SOURCE ssd/games3 type filesystem - ssd/games3 creation Sat Sep 23 10:23 2023 - ssd/games3 used 11.3G - ssd/games3 available 974G - ssd/games3 referenced 11.3G - ssd/games3 compressratio 1.08x - ssd/games3 mounted yes - ssd/games3 quota none local ssd/games3 reservation none default ssd/games3 recordsize 128K local ssd/games3 mountpoint /mnt/ssd/games local ssd/games3 sharenfs off default ssd/games3 checksum on default ssd/games3 compression zstd local ssd/games3 atime off local ssd/games3 devices on default ssd/games3 exec on default ssd/games3 setuid on default ssd/games3 readonly off local ssd/games3 zoned off default ssd/games3 snapdir hidden default ssd/games3 aclmode discard default ssd/games3 aclinherit restricted default ssd/games3 createtxg 5814 - ssd/games3 canmount on default ssd/games3 xattr dir local ssd/games3 copies 1 default ssd/games3 version 5 - ssd/games3 utf8only on - ssd/games3 normalization formD - ssd/games3 casesensitivity sensitive - ssd/games3 vscan off default ssd/games3 nbmand off default ssd/games3 sharesmb off default ssd/games3 refquota none default ssd/games3 refreservation none default ssd/games3 guid 2049888916364074011 - ssd/games3 primarycache all local ssd/games3 secondarycache all default ssd/games3 usedbysnapshots 952K - ssd/games3 usedbydataset 11.3G - ssd/games3 usedbychildren 0B - ssd/games3 usedbyrefreservation 0B - ssd/games3 logbias latency default ssd/games3 objsetid 4485 - ssd/games3 dedup off default ssd/games3 mlslabel none default ssd/games3 sync standard local ssd/games3 dnodesize auto inherited from ssd ssd/games3 refcompressratio 1.08x - ssd/games3 written 56K - ssd/games3 logicalused 12.2G - ssd/games3 logicalreferenced 12.2G - ssd/games3 volmode default default ssd/games3 filesystem_limit none default ssd/games3 snapshot_limit none default ssd/games3 filesystem_count none default ssd/games3 snapshot_count none default ssd/games3 snapdev hidden default ssd/games3 acltype posix inherited from ssd ssd/games3 context none default ssd/games3 fscontext none default ssd/games3 defcontext none default ssd/games3 rootcontext none default ssd/games3 relatime on default ssd/games3 redundant_metadata all default ssd/games3 overlay on default ssd/games3 encryption off default ssd/games3 keylocation none default ssd/games3 keyformat none default ssd/games3 pbkdf2iters 0 default ssd/games3 special_small_blocks 0 default ssd/games3 snapshots_changed Sat May 17 8:47:35 2025 - ssd/games3 prefetch all default ssd/games3 direct standard default ssd/games3 longname off default
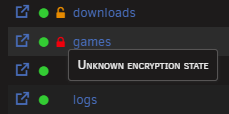

-
Behaviour is the same on 7.1.2. The share now shows as "unkown encrpytion state" as well. storage-diagnostics-20250515-1933.zip
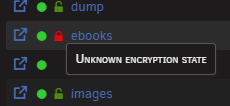
-
I made sure during all of this to have no sessions open. I can rename the datasets back to the share name, so that they match. But trying the share rename from the GUI still fails, though the dataset does take the new name.
-
Now we're getting somehere. These looks to be the names of the very first renames I tried. root@storage:~# zfs list NAME USED AVAIL REFER MOUNTPOINT ssd 1.86T 1.66T 92.9G /mnt/ssd ssd/books 41.0G 1.66T 41.0G /mnt/ssd/ebooks ssd/documents 70.5G 1.66T 70.5G /mnt/ssd/documents ssd/downloads 194G 1.66T 194G /mnt/ssd/downloads ssd/games2 11.3G 1.66T 11.3G /mnt/ssd/games ssd/iso 151G 1.66T 151G /mnt/ssd/iso ssd/logs 192K 1.66T 192K /mnt/ssd/logs ssd/movies 413G 1.66T 413G /mnt/ssd/movies ssd/music 32.8G 1.66T 32.8G /mnt/ssd/music ssd/pictures 59.5G 1.66T 57.5G /mnt/ssd/pictures ssd/podcasts 42.7G 1.66T 42.7G /mnt/ssd/podcasts ssd/system 8.19M 1.66T 8.19M /mnt/ssd/system ssd/tv 791G 1.66T 791G /mnt/ssd/tv What's the thinking: Rename the dataset, or change the mountpoint?
-
Ok this is extra weird. Tried creating a new share to move the data into, and... May 13 17:28:19 storage shfs: /usr/sbin/zfs create 'ssd/books' 2>&1 May 13 17:28:19 storage emhttpd: error: shfs_mk_share, 6455: Invalid argument (22): ioctl: /books May 13 17:28:19 storage emhttpd: shcmd (130): rm '/boot/config/shares/books.cfg' May 13 17:28:19 storage emhttpd: Starting services... May 13 17:28:20 storage emhttpd: shcmd (134): /etc/rc.d/rc.samba restart
-
Nothing unexpected, so far as I can tell. You can ignore the folders owned by Proxmox, that's an annoying artefact of how Proxmox handles shares for ISO mounts, and was part of the reason I was reorganizing shares in the first place. root@storage:~# ls -lah /mnt/user total 144K drwxrwxrwx 1 nobody users 130 May 13 16:40 ./ drwxr-xr-x 11 root root 220 May 13 16:46 ../ drwxrwxrwx 1 nobody users 11 Mar 30 22:10 documents/ drwxrwxrwx 1 nobody users 9 Apr 22 06:19 downloads/ drwxrwxrwx 1 proxmox users 6 Feb 11 11:51 dump/ drwxrwxrwx 1 nobody users 51 Mar 3 17:24 ebooks/ drwxrwxrwx 1 nobody users 4 Mar 3 17:51 games/ drwxrwxrwx 1 proxmox users 6 Feb 11 12:06 images/ drwxrwxrwx 1 nobody users 8 Apr 28 21:30 iso/ lrwxrwxrwx 4 nobody users 4 Apr 25 22:29 logs -> ../ssd/logs/ drwxrwxrwx 1 nobody users 46 Apr 13 21:06 movies/ drwxrwxrwx 1 nobody users 87 Mar 29 22:53 music/ drwxrwxrwx 1 nobody users 15 Mar 29 22:03 pictures/ drwxrwxrwx 1 nobody users 15 Feb 25 04:00 podcasts/ drwxrwxrwx 1 proxmox users 6 Feb 11 11:51 private/ lrwxrwxrwx 5 nobody users 6 Apr 30 20:18 system -> ../ssd/system/ drwxrwxrwx 1 nobody users 56 Apr 13 21:22 tv/ drwxrwxrwx 1 nobody users 4.0K Mar 19 2019 zz/
-
Removed the array as a storage option from Proxmox. Disabled autostart for mounting a second unRAID array (backup server) via UD. Disabled autostart for mounting the root share used for Proxmox via UD. Rebooted, started array, confirmed no extra shares present. Renamed "ebooks" > "diffsharename" > Failed. Booted into safe mode just for giggles. Renamed "ebooks" > "ihopethisworks" > Failed. Docker and VM service are not used on this server, no This is getting a little annoying. I wouldn't mind, but it's a very simple thing. Any other suggestions? I'd prefer not upgrading to 7.x as there seem to be other sets of issues there that may or may not be ironed out, but I'm not bothered taking the risk at the moment. storage-diagnostics-20250513-1640-gui.zip storage-diagnostics-20250513-1647-gui-safemode.zip
-
That was the very next thing I did. The next line in my message above. Since switched to UD for it (not sure why I didn't originally), same thing.
-
I didn't realize I'd anonymized the diags. Those shares are "documents/downloads" and "podcasts/pictures". To give a little more possibly relevant detail here: This array is only used for storage. I'm passing a root share (via SMB extras) through to Proxmox for the compute. [all] path = /mnt/user comment = browseable = yes follow symlinks = yes wide links = yes valid users = proxmox write list = proxmox force user = nobody force group = users create mask = 0775 directory mask = 0775 vfs objects = I tried disabling the share from Proxmox > rename "ebooks" to "somethingdifferent" > Fail Stopping the array, removing the entry in SMB Extras, restarting > rename "ebooks" to "somethingdifferent2" > Fail storage-diagnostics-20250512-1713.zip
-
Well that's a handy button I had no idea existed! I'd been manually clearing them out usually any time I'd create diags for whatever reason. Cleared, ebooks > books. Rename still fails. This time share config settings aren't trashed though. storage-diagnostics-20250512-1649.zip
-
I am. Share is only on cache pool, so I tried renaming /mnt/ssd/ebooks and games, but got the old 'resource is busy' bit.
-
Tried to rename as follows: ebooks > books games > games2 In both cases, the rename didn't take, and array settings got changed to Primary: Array, Secondary: None, Min free space: 0. Changing settings to previous, with the original name restored the share. Any idea what's going on? Diags attached. storage-diagnostics-20250512-1009.zip
-
To be honest I've since removed the plugin; I changed it to (I think) your version, because I'd seen the 'prime/drain to x%' feature which was exactly what I was looking for for quite some time, but I was using 2025.03.01.
-
Can you post a link to the github? There isn't anything on the first post, and I'm not 100% sure which mover plugin is yours from CA.
-
I'm running into an issue here, which I think has to do with "smart caching". I have several shares set as primary cache, secondary array. Mover action is to move from array to cache (ie, to keep on the cache as much as possible, and only overflow to array if cache is full) However, all of these shares now have their data on the array, because there are other shares that are set to flush to array, but only after a long time. The expected behaviour here would be for the shares where cache is perferred to always be there, not to be moved out for other data. (Yes, cache-only could be used, but in that case writes will fail in the event of cache being full, rather than succeeding to the array) Let me know if anything is unclear from the above. Settings attached.
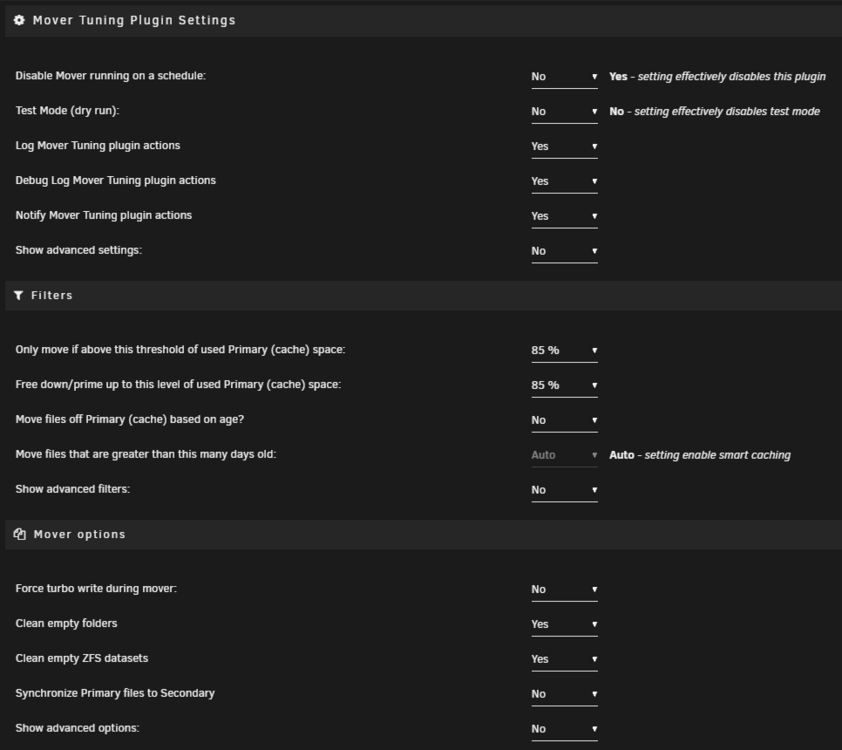
-
Long time user here, though I've just come across the following: Does this do what it sounds like? Traditionally we were always told to never have files in mutlipe places as it can screw up fuse. Is this safe to use?
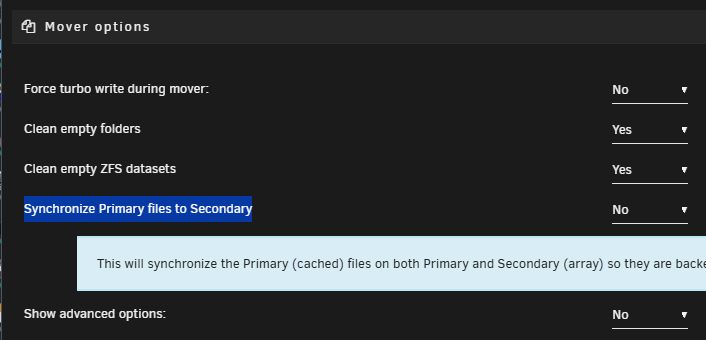
-
Good shout. Done.
-
Hi all, I've got a second unRAID share mounted to my primary storage server via UD's remote SMB share. The remote is a backup server, so I have the target's "backup" share mounted on the source at /mnt/remotes/backup. I can't read or write to this dir from the source. On the target everything is fine. Source array: 6.12.15, target 7.0.0. All of this hardware has been running fine for several months with no issues. The target was recently reimaged with unRAID from Proxmox. Target syslog shows nothing of note. Source syslog shows lots of: Feb 20 16:32:25 server kernel: traps: lsof[525] general protection fault ip:1475962a7c6e sp:b96ee9d3b65e2e1d error:0 in libc-2.37.so[14759628f000+169000] As well as: Feb 20 16:32:02 server kernel: CIFS: VFS: reconnect tcon failed rc = -2 Feb 20 16:32:04 server kernel: CIFS: VFS: \\BACKUP.LOCAL\backup BAD_NETWORK_NAME: \\BACKUP.LOCAL\backup Diags attached. Anything jumping out? Thanks in advance! source.zip target.zip
-
Hi all, I've got a second unRAID share mounted to my primary storage server via UD's remote SMB share. The remote is a backup server, so I have the target's "backup" share mounted on the source at /mnt/remotes/backup. I can't read or write to this dir from the source. On the target everything is fine. Source array: 6.12.15, target 7.0.0. Target syslog shows nothing of note. Source syslog shows lots of: Feb 20 16:32:25 server kernel: traps: lsof[525] general protection fault ip:1475962a7c6e sp:b96ee9d3b65e2e1d error:0 in libc-2.37.so[14759628f000+169000] As well as: Feb 20 16:32:02 server kernel: CIFS: VFS: reconnect tcon failed rc = -2 Feb 20 16:32:04 server kernel: CIFS: VFS: \\BACKUP.LOCAL\backup BAD_NETWORK_NAME: \\BACKUP.LOCAL\backup Diags attached. Anything jumping out? Thanks in advance! source.zip target.zip
-
You could, sure, that would be cheapest. for tidiness, I'd be leaning more towards a box with PSU and backplane (because hot-swap is great, and throw one of these in the back. You can link that to your server with an external HBA.
-
What you're looking for is a JBOD, or disk shelf. The idea is that you could have another HBA in your existing server, but instead of internal SATA or SAS connections, is has external ones*. Something like this, for example. Then, you'd connect that to something like this, which would pass the drives through to your server as additional disks. There are also ways to DIY this though. The main reason to buy the disk shelf is because of the dual SAS controllers - this means that if one controller dies, the other one can still access the drives. If you're not using SAS though that won't be an option anyway, and you'd need an OS that supporsts this, which as far as I'm aware, unRAID does not. So, if you don't need the controllers, all you really need is a box to put the hard drives in, a PSU to power them, and cables to connect them to your server. Here is an example of someone doing that with off-the-shelf parts. Hope that helps! * The only real difference is that external cables are rated for more insertions, etc and are generally easier to work with. You could actually use one that has internal connections, and route them outside the case to the other hard drives, but it's cleaner this way.
-
While it would require fundemental changes, and probably won't happen for that reason, it's quite a nice idea. It doesn't really make the data any more vulernable - outside of edits - if the cache drive were to die before the mover triggered, but it has a bunch of performance and energy advantages. +1, fwiw






