

xtrips
-
Posts
309 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by xtrips
-
Hello. I wish I could set a password. I just don't have access to the GUI yet. And the port used by Sickchill is 8081 and is not forwarded in my router. What other option do I have? Forget it! An update solved the problem apparently.
-
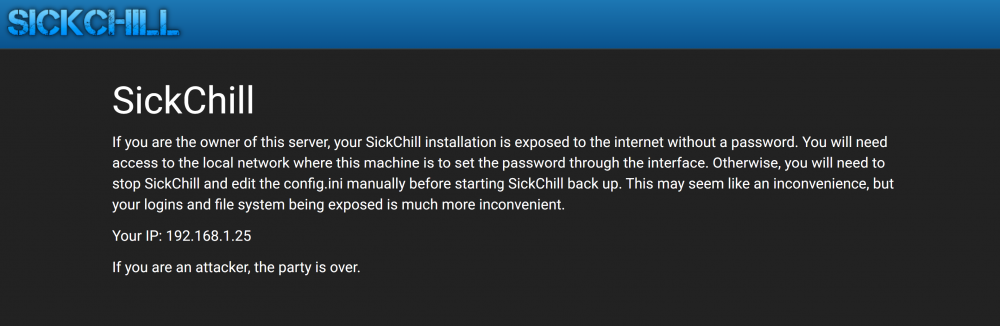
As of this morning Sickchill is blocked
-
Suddenly this morning Sickchill is blocked! Hers is the message appearing on screen. What should I do? I tried the ini file in cache but I don't know how to proceed.
-
Thank you
-
Hello, I know this is not exactly on topic but since people have discussed the apcupsd daemon here and I couldn't find an answer to my question anywhere else, I thought I might try. My apcupsd daemon runs on Windows 10, and it is monitoring an APC UPS on my Unraid server. How do I set once and for all my Unraid's IP address as the target on the apcupsd daemon on Windows? After each reboot on my PC I need to go the the configuration panel and switch from 127.0.0.1 to my Unraid's IP address. After that all is fine until the next reboot. I tried to make sense of the apcupsd.conf file and online help to no avail. Thanks
-
Hello, I plugged an external drive to Unraid as seen in the screen capture. What else should I do to be able to see it in Krusader's panel?

-
Hello, I just had my router upgraded by my network provider and suddenly I cannot access Sabnzbd from the WAN. I can't seem to find the culprit. I didn't change a thing in Sabnzbd on Unraid. Unraid is still getting the same IP as before. I forwarded the same port as before on the router. I checked that my LAN address is still accessible from the Internet and rightly translated at my dynamic DNS provider. I think I checked everything and still no access. Please help. Thanks

-
Ok. Any suggestion about any serious tool to check those 2 HDD? Preferably something that runs on windows Sent from my iPhone using Tapatalk Pro
-
Hello, Last week, as once every month, the Parity job ran, it was stuck at 70% and one of my HDDs started to give errors. I stopped and retried, same thing. Then a second HDD started to give errors too. Still stuck at 70%. I used the forum and sent a diagnostic file. I was told that both HDDs were at the end of their career. They were both WD Green, so I reluctantly went and bought 2 replacement HDDs, WD Red this time. I used ddrescue to clone the 2 drives, no errors at all. After I was done the Parity job ran smooth. I had a doubt because ddrescue didn't show any errors so I used Western Digital Data Lifeguard Diagnostic windows tool to thoroughly check both HDDs (couldn't be bothered to run preclear on the server). Both HDDs finished the extended surface read and write check with flying colors. So what does it mean? Is Unraid Parity unreliable? Did I spend money on new drives with no reason?
-
I got that. I didn’t make myself clear enough. I meant what does it mean for that source disc? is it failing or is it not? What tool do you suggest to use to make that clear once and for all? Sent from my iPhone using Tapatalk Pro
-
Hello, Did you ever use ddrescue? I am asking because I find it weird that I am almost done with the second and last HDD that have raised so many errors while running Parity check, while when used as a source with ddrescue don't raise even 1 error or bad sector or whatever.... What does this means?
-
Hello, I have had these 2 NAS machines for years: - 1 old Readynas with 6 HDDs - 1 large PC tower case converted to a Unraid NAS with 9 HDDs I am willing to merge them into one big Unraid NAS with all the HDDs. I was thinking of buying a 15 bay external enclosure for that and I was wondering how to work with that. I mean what runs Unraid? I suppose I need some external small form factor PC or something right? How would it be connected to the external enclosure? What kind of machine this should be to run 24/7/365 ? Thanks
-
Thanks for checking. Never used ddrescue. Would it be any different than using winscp from Windows and visualizing the source and target drive? Using command lines gives me the bees knees, but I will do it "carefully" if there is a serious advantage.
-
Disk 5 SMART report novanas2-smart-20191016-1830.zip
-
That's it? No answer? Anybody please?
-
I aborted the Parity Check In for the second time now. It was not worth it. Diskspeed is running now. Crashed before because it couln't run alongside with Parity I guess. The amount of errors on Disk 5 are 1008 up until now. And Disk 1 showed around 70 errors yesterday. I won't hold my breadth for Diskspeed. I suppose the diagnosis is bad. What is the recommended procedure for me now? I suppose those 2 HDDs are nearly dead. I still can access the files on each of them disks. I was thinking: - stop parity completely - remove 1 and 5 - replace 1 and 5 with new ones - connect old 1 and then old 5 as external and mount - copy old 1/5 to new 1/5 - after checking that all is fine, enable parity and run Parity check in. What do you think?
-
Crashed? Is that so? I thought this was its output 😂😂😂
-
What container?
-
just got a pop up saying Disk 5 has errors now
-
DiskSpeed - Disk Diagnostics & Reporting tool Version: 2.3 Scanning Hardware 10:21:19 Spinning up hard drives 10:21:19 Scanning system storage Lucee 5.2.9.31 Error (application) Messagetimeout [90000 ms] expired while executing [/usr/sbin/hwinfo --pci --bridge --storage-ctrl --disk --ide --scsi] StacktraceThe Error Occurred in /var/www/ScanControllers.cfm: line 243 241: <CFOUTPUT>#TS()# Scanning system storage<br></CFOUTPUT><CFFLUSH> 242: <CFFILE action="write" file="#PersistDir#/hwinfo_storage_exec.txt" output=" /usr/sbin/hwinfo --pci --bridge --storage-ctrl --disk --ide --scsi" addnewline="NO" mode="666"> 243: <cfexecute name="/usr/sbin/hwinfo" arguments="--pci --bridge --storage-ctrl --disk --ide --scsi" variable="storage" timeout="90" /><!--- --usb-ctrl --usb --hub ---> 244: <CFFILE action="delete" file="#PersistDir#/hwinfo_storage_exec.txt"> 245: <CFFILE action="write" file="#PersistDir#/hwinfo_storage.txt" output="#storage#" addnewline="NO" mode="666"> called from /var/www/ScanControllers.cfm: line 242 240: 241: <CFOUTPUT>#TS()# Scanning system storage<br></CFOUTPUT><CFFLUSH> 242: <CFFILE action="write" file="#PersistDir#/hwinfo_storage_exec.txt" output=" /usr/sbin/hwinfo --pci --bridge --storage-ctrl --disk --ide --scsi" addnewline="NO" mode="666"> 243: <cfexecute name="/usr/sbin/hwinfo" arguments="--pci --bridge --storage-ctrl --disk --ide --scsi" variable="storage" timeout="90" /><!--- --usb-ctrl --usb --hub ---> 244: <CFFILE action="delete" file="#PersistDir#/hwinfo_storage_exec.txt"> Java Stacktracelucee.runtime.exp.ApplicationException: timeout [90000 ms] expired while executing [/usr/sbin/hwinfo --pci --bridge --storage-ctrl --disk --ide --scsi] at lucee.runtime.tag.Execute._execute(Execute.java:241) at lucee.runtime.tag.Execute.doEndTag(Execute.java:252) at scancontrollers_cfm$cf.call_000006(/ScanControllers.cfm:243) at scancontrollers_cfm$cf.call(/ScanControllers.cfm:242) at lucee.runtime.PageContextImpl._doInclude(PageContextImpl.java:933) at lucee.runtime.PageContextImpl._doInclude(PageContextImpl.java:823) at lucee.runtime.listener.ClassicAppListener._onRequest(ClassicAppListener.java:66) at lucee.runtime.listener.MixedAppListener.onRequest(MixedAppListener.java:45) at lucee.runtime.PageContextImpl.execute(PageContextImpl.java:2464) at lucee.runtime.PageContextImpl._execute(PageContextImpl.java:2454) at lucee.runtime.PageContextImpl.executeCFML(PageContextImpl.java:2427) at lucee.runtime.engine.Request.exe(Request.java:44) at lucee.runtime.engine.CFMLEngineImpl._service(CFMLEngineImpl.java:1090) at lucee.runtime.engine.CFMLEngineImpl.serviceCFML(CFMLEngineImpl.java:1038) at lucee.loader.engine.CFMLEngineWrapper.serviceCFML(CFMLEngineWrapper.java:102) at lucee.loader.servlet.CFMLServlet.service(CFMLServlet.java:51) at javax.servlet.http.HttpServlet.service(HttpServlet.java:729) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:292) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:207) at org.apache.tomcat.websocket.server.WsFilter.doFilter(WsFilter.java:52) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:240) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:207) at org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.java:212) at org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:94) at org.apache.catalina.authenticator.AuthenticatorBase.invoke(AuthenticatorBase.java:492) at org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:141) at org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:80) at org.apache.catalina.valves.AbstractAccessLogValve.invoke(AbstractAccessLogValve.java:620) at org.apache.catalina.valves.RemoteIpValve.invoke(RemoteIpValve.java:684) at org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:88) at org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:502) at org.apache.coyote.http11.AbstractHttp11Processor.process(AbstractHttp11Processor.java:1152) at org.apache.coyote.AbstractProtocol$AbstractConnectionHandler.process(AbstractProtocol.java:684) at org.apache.tomcat.util.net.AprEndpoint$SocketWithOptionsProcessor.run(AprEndpoint.java:2464) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61) at java.lang.Thread.run(Thread.java:748) Timestamp10/16/19 10:22:49 AM IDT
-
oooops novanas2-diagnostics-20191016-0708.zip
-
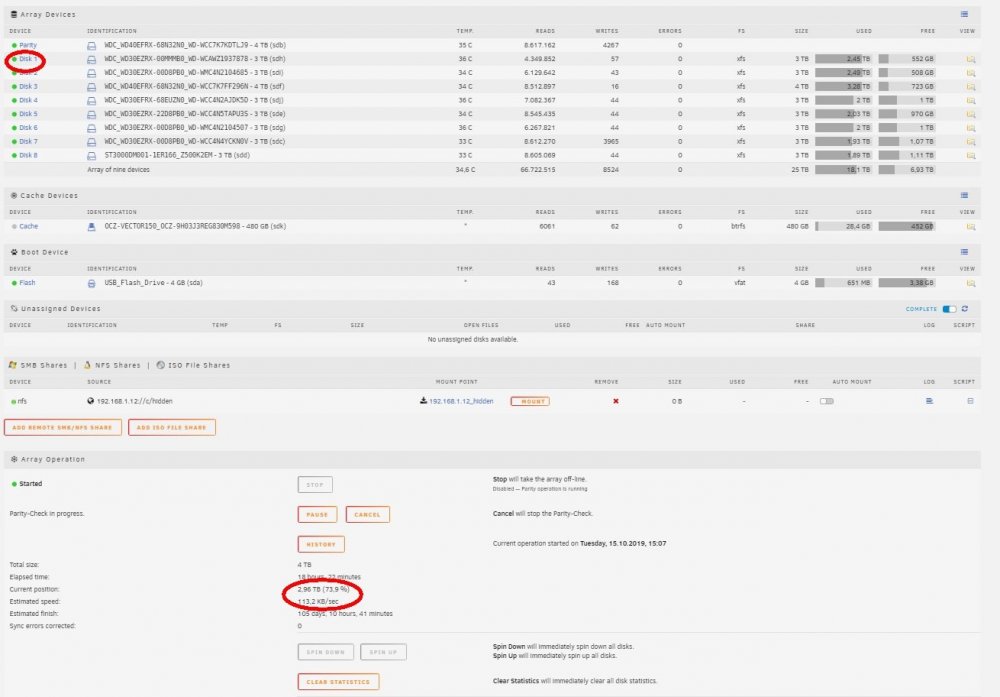
Hello, This is my second run of Parity Check-in since yesterday. The one before I aborted and rebooted. When it reaches about 70% it slows to a crawl as you can see in the screenshot. Note that in the first run Disk 1 gave some errors. After reboot they don't show up, yet. I stopped the Dockers engine to ease up on the server. What can I do now? I don't know it it is a coincidence but 2 days ago I upgraded to 6.8.0 rc1.
-
Still no solution .......
-
Thanks but I don’t have the knowledge nor the interest to decipher that whole discussion. What I did get from it is that the team is aware of the problem and something is coming up, right? Sent from my iPhone using Tapatalk Pro
-
Hello, It's been a week already that Unraid is updating these same 3 docker apps (Sabnzbd, Sickchill and Transmission) over and over and over again. Every time after the updates every thing looks ok with the green up-to-date V and a few minutes later it shows the blue apply update again. Never ending. What is it gonna be? novanas2-diagnostics-20190901-1546.zip




