exico
Members
-
Joined
-
Last visited
Everything posted by exico
-
I checked, Im starting to understand how the snapshots works. From what I got the snapshots folders are created only when i delete a file/folder from the source that corresponds to that date. For example if I deleted today a file created Jan 13 2024 I will find it in the folder 20240113somethingsomething. With that forget what i said about missing snapshots. With that said it would be nice to have a timestamp in the LastCronLog and maybe an option to cycle the logs
-
Hello, Im using Lucky Backup and my jobs include snapshots. The problem is: If i run the tasks manually LB creates the snapshots, I can see them in .luckybackup-snapshots and in the gui but if i set them on a schedule no snapshots are created, or at least I dont see them. No extra folders created in .luckybackup-snapshots and it isnt listed in manage snapshots in the gui. I know that the schedule works because i placed some files on the source and checked the destination after the scheduled time. There are some logs that I can provide?
-
My 2 cents on the container swap. I dont fully support/understand the decision on why use two dockers but at least the instructions on how to set up the new containers should be more clear for Unraid. In my case the init script didnt want to work. I edited the variables on the mongo container but it didnt want to execute the script on the first boot. I had to enter the container console and: mongo < path_of_the_init_script_in_the_container.js At first i tought it was a problem with the connection between the two containers since i run unifi in its own IP and mongo in bridge. tried to install ping to troubleshoot in the unifi container but apt has broken dependencies and doesnt let me do anything. So, please, expand the instructions on the github for Unraid. [insert instruction not clear joke here]
-
Well I did update the system roughly 1 week after 6.12.4 came out. Thats why its strange. Anyway I can report that no more crashes occured. At least for now.
-
Will do and report back. If it is that its strange. Didnt change it or added containers in a while and happened out of the blue.
-
I've been dealing with this for 2 weeks... I have a very strange random freeze that only a reset or forced shutdown can clear. I had problem with setting up the syslog but now it works. What i did so far: - Remove HBA (LSI 9211) working for 5 years or so - Remove NIC (HP branded Broadcom 10G ethernet) - Remove video card (1050 ti) - Swap PSU - Memtest the RAM - Swap the Motherboard with a Gigabyte X79 UP4 with a 4930K and some ddr3 ram At the moment I have just my motherboard with a NVME adapter and 8 Sata drives and im using the integrated 1G nic (e1000) and sata ports The motherboard is a Supermicro X9SRL-F with a E5-2697 v2 CPU and 64 GB of RAM I attached diagnostics and the last syslog. The last freeze occured at "Nov 13 12:29:29" Checking the syslog I was a "tainted kernel" (you can see one at line 8284 "Nov 13 12:28:29 UNRAIDSRV kernel: CPU: 16 PID: 11248 Comm: kworker/16:1 Tainted: P W O 6.1.49-Unraid #1" After some digging i got this: root@UNRAIDSRV:~# cat /proc/sys/kernel/tainted 4609 root@UNRAIDSRV:~# ./kernel-chktaint Kernel is "tainted" for the following reasons: * proprietary module was loaded (#0) * kernel issued warning (#9) * externally-built ('out-of-tree') module was loaded (#12) For a more detailed explanation of the various taint flags see Documentation/admin-guide/tainted-kernels.rst in the Linux kernel sources or https://kernel.org/doc/html/latest/admin-guide/tainted-kernels.html Raw taint value as int/string: 4609/'P W O ' root@UNRAIDSRV:~# Im not a big linux person so I can go so far. Do you have any suggestion on what i can try before i go mad? syslog-127.0.0.1.zip unraidsrv-diagnostics-20231113-1317.zip
-
Found the problem, I had two interfaces with the same IP but I do not understand why the rc script bind the same ip twice on one interface. I think that a check should be in place for that. Bear in mind that I had one interface disabled I removed the IP from both interfaces and the upgrade has gone smooth
-
I searched but i did not see this problem in another "no webgui" thread. I upgraded from the RC6 to 6.12.0 stable and also tried 6.12.1 but i had to revert on both occasions. I attached the diagnostics but from what i see: Tried to: /etc/rc.d/rc.nginx check Checking configuration for correct syntax and then trying to open files referenced in configuration... nginx: [emerg] a duplicate default server for 192.168.80.105:80 in /etc/nginx/conf.d/servers.conf:43 nginx: configuration file /etc/nginx/nginx.conf test failed I then checked servers.conf and indeed there are various entries duplicated on my eth3. I tried to comment them and check again, some warnings but no [emerg]. Tried to start and these entries reappear and stop nginx. For example: server { listen 192.168.80.105:80 default_server; # eth3 return 302 https://192-168-80-105.c8100b769f7ebe9a046d3c97b75b083b26c4ca45.myunraid.net:443$request_uri; } server { listen 192.168.80.105:80 default_server; # eth3 return 302 https://192-168-80-105.c8100b769f7ebe9a046d3c97b75b083b26c4ca45.myunraid.net:443$request_uri; } somethingsomething server { somethingsomething listen 192.168.80.105:443 ssl http2 default_server; # eth3 listen 192.168.80.105:443 ssl http2 default_server; # eth3 somethingsomething } (somethingsomething is just a placeholder for the other config text, just wanted to highligh the duplicated entries) And there are more. For now i reverted to the RC Since the eth3 is integrated in the MB i cannot even remove it to try if it fix itself, also there is no option in the BIOS to disable it MB is a supermicro X9SRL-F unraidsrv-diagnostics-20230623-2116.zip
-
I have the same problem with the new version My docker was already set to 911:911 as permissions and when i updated it did not work. I tried to set PUID and PGID to 99 and 100, obviously it did not work because it is different from the file permissions. I chown 'ed the folder to 99 100 and still it did not work. I set the version to 2.9.22 as suggested by Tweak91 and it started. Files user:group now is the same as variables on the docker. (99:100, before was 911:911) Mind that I'm still at version 6.11.5 of UNRAID
-
This fast? Thank you, really.
-
Just a question, would be possible to add curl to LuckyBackup docker? For now I console'd in and apt installed it into the container but it's not ideal since it will vanish with the next update. I'm asking this because I'm using curl in the Also Execute section in the tasks to power on a machine, wait and then start the backup.
-
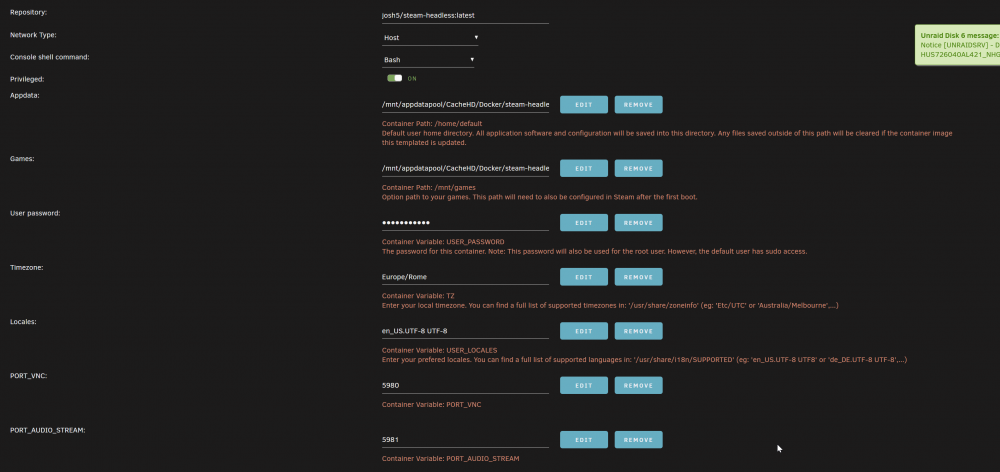
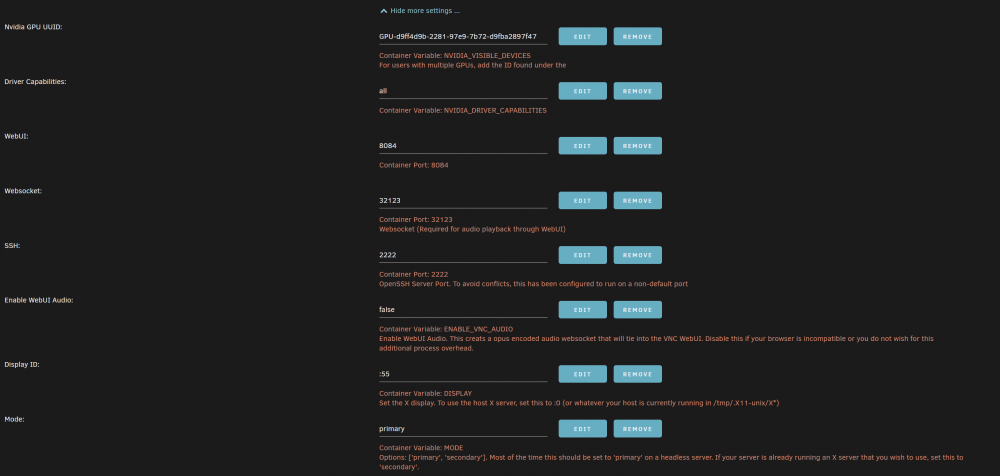
I just updated UNRAID from 6.10.1 to 6.10.3 and now steam headless wont work. On the log console i get a spam of this: 2022-06-22 20:56:06,396 INFO spawned: 'x11vnc' with pid 566 2022-06-22 20:56:07,408 INFO success: x11vnc entered RUNNING state, process has stayed up for > than 1 seconds (startsecs) 2022-06-22 20:56:07,409 INFO exited: x11vnc (exit status 1; not expected) 2022-06-22 20:56:08,412 INFO spawned: 'x11vnc' with pid 567 2022-06-22 20:56:09,425 INFO success: x11vnc entered RUNNING state, process has stayed up for > than 1 seconds (startsecs) 2022-06-22 20:56:09,426 INFO exited: x11vnc (exit status 1; not expected) 2022-06-22 20:56:10,429 INFO spawned: 'x11vnc' with pid 568 etc... What should i check? Attached, my config
-
Tried again today and now it finds the 6.10 release and I upgraded with no issues Thank you!
-
Unfortunately I can't seem to update from rc8 to stable. When i try from Tools -> update OS it doesnt find any new release in Next or Stable. If i try to install it manually like told in the first post in Plugins -> Install Plugin i get this: plugin: installing: https://unraid-dl.sfo2.cdn.digitaloceanspaces.com/stable/unRAIDServer.plg plugin: downloading https://unraid-dl.sfo2.cdn.digitaloceanspaces.com/stable/unRAIDServer.plg plugin: downloading: https://unraid-dl.sfo2.cdn.digitaloceanspaces.com/stable/unRAIDServer.plg ... done plugin: not installing older version
-
NVM I removed the docker, ssh keys etc Restarted both towers Re-followed the guid and now works No idea of what was creating the problem Now works, cheers
-
What do you mean by "which keys"? I did copy the public one and if i use the cli and "ssh root@IP" it doesnt ask for password so it is working and reading the key. I copied and added the correct key to the destination box authorized_keys I did try to run it both in normal and as root user I followed this guide: https://unraid.net/blog/unraid-server-backups-with-luckybackup
-
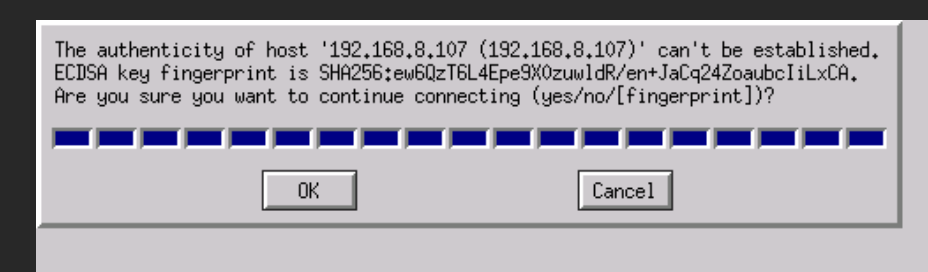
Hello, I'm trying to setup luckybackup and i followed the guide but when i try to start a task i get this: When i try to connect from the cli of the docker it did ask to confirm the first time, as usual for ssh, but then it goes no problem without asking. If i try to launch the same command that the gui uses (you can check it on the validate button) it works without asking for the authenticity of host. I already tried to remove the docker and remove all files in the /luckbackup folder but the problem persists. Obviously pressing OK on this box does nothing, it asks again 2/3 times and then fails
-
Yeah. mine too. I was wondering why one of the services just died and i checked the db connection... Not sure why it worked but i changed the repo from linuxserver/mariadb to linuxserver/mariadb:alpine-version-10.5.12-r0 (an older version) and then changed it to linuxserver/mariadb:latest and works. Not ideal i know but works. Logs for the error points to a fail in innodb 210825 18:56:18 mysqld_safe Starting mariadbd daemon with databases from /config/databases Warning: World-writable config file '/etc/my.cnf.d/custom.cnf' is ignored 2021-08-25 18:56:18 0 [Note] /usr/bin/mariadbd (mysqld 10.5.12-MariaDB) starting as process 4703 ... 2021-08-25 18:56:18 0 [Note] InnoDB: Uses event mutexes 2021-08-25 18:56:18 0 [Note] InnoDB: Compressed tables use zlib 1.2.11 2021-08-25 18:56:18 0 [Note] InnoDB: Number of pools: 1 2021-08-25 18:56:18 0 [Note] InnoDB: Using crc32 + pclmulqdq instructions 2021-08-25 18:56:18 0 [Note] mariadbd: O_TMPFILE is not supported on /var/tmp (disabling future attempts) 2021-08-25 18:56:18 0 [Note] InnoDB: Using Linux native AIO 2021-08-25 18:56:18 0 [Note] InnoDB: Initializing buffer pool, total size = 134217728, chunk size = 134217728 2021-08-25 18:56:18 0 [Note] InnoDB: Completed initialization of buffer pool 2021-08-25 18:56:18 0 [ERROR] InnoDB: Upgrade after a crash is not supported. The redo log was created with MariaDB 10.4.21. 2021-08-25 18:56:18 0 [ERROR] InnoDB: Plugin initialization aborted with error Generic error 2021-08-25 18:56:18 0 [Note] InnoDB: Starting shutdown... 2021-08-25 18:56:18 0 [ERROR] Plugin 'InnoDB' init function returned error. 2021-08-25 18:56:18 0 [ERROR] Plugin 'InnoDB' registration as a STORAGE ENGINE failed. 2021-08-25 18:56:18 0 [Note] Plugin 'FEEDBACK' is disabled. 2021-08-25 18:56:18 0 [ERROR] Unknown/unsupported storage engine: InnoDB 2021-08-25 18:56:18 0 [ERROR] Aborting 210825 18:56:18 mysqld_safe mysqld from pid file /var/run/mysqld/mysqld.pid ended
-
Fvtt docker is on port 30000. Is a web application based on nodejs for D&D and more
-
Im having a problem where i can access fine fvtt trough a domain but when i paste the key and get to the configuration to start a world the "play" button goes grey and do nothing. If i access directly trough unraid:port everything works. Im using this proxy manager: As options i enable Cache assets, Websocket support, Force SSL (letsencrypt) and i added in the custom configuration this bit: add_header Referrer-Policy "same-origin" always; add_header Access-Control-Allow-Origin https://domain.redacted always; client_max_body_size 1024M; fastcgi_buffers 64 4K; set $upstream_app FoundryVTT; proxy_max_temp_file_size 1024m; The complete automated config file looks like this: # ------------------------------------------------------------ # domain.redacted # ------------------------------------------------------------ server { set $forward_scheme http; set $server "192.168.8.105"; set $port 30000; listen 80; listen [::]:80; listen 443 ssl http2; listen [::]:443; server_name domain.redacted; # Let's Encrypt SSL include conf.d/include/letsencrypt-acme-challenge.conf; include conf.d/include/ssl-ciphers.conf; ssl_certificate /etc/letsencrypt/live/npm-2/fullchain.pem; ssl_certificate_key /etc/letsencrypt/live/npm-2/privkey.pem; # Force SSL include conf.d/include/force-ssl.conf; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection $http_connection; proxy_http_version 1.1; access_log /data/logs/proxy-host-2_access.log proxy; error_log /data/logs/proxy-host-2_error.log warn; add_header Referrer-Policy "same-origin" always; add_header Access-Control-Allow-Origin https://domain.redacted always; client_max_body_size 1024M; fastcgi_buffers 64 4K; set $upstream_app FoundryVTT; proxy_max_temp_file_size 1024m; location / { proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection $http_connection; proxy_http_version 1.1; # Proxy! include conf.d/include/proxy.conf; } # Custom include /data/nginx/custom/server_proxy[.]conf; } proxy.conf: add_header X-Served-By $host; proxy_set_header Host $host; proxy_set_header X-Forwarded-Scheme $scheme; proxy_set_header X-Forwarded-Proto $scheme; proxy_set_header X-Forwarded-For $remote_addr; proxy_set_header X-Real-IP $remote_addr; proxy_pass $forward_scheme://$server:$port; options.json { "port": 30000, "upnp": false, "fullscreen": false, "hostname": "domain.redacted", "routePrefix": null, "sslCert": null, "sslKey": null, "awsConfig": null, "dataPath": "/foundry/data", "proxySSL": true, "proxyPort": 443, "minifyStaticFiles": true, "updateChannel": "release", "language": "it.FoundryVTT - it-IT", "world": null } On this proxy i have all sort of hosts: plex, wikijs (that runs on nodejs and has no problems of sorts), my firm site, a gitlab etc and foundryvtt is the only one I am having problems with. What Im doing wrong?
-
Disabled "Host access to custom networks" and now i can access everything except one docker but i will figure it later
-
I did not, just tried and nothing changed. Just an hypotesis, can the setting "Host access to custom networks" set to enable in the docker settings be a problem? I will have to wait to stop dockers to test this atm cause there is a task running
-
Im using 192.168.10.171
-
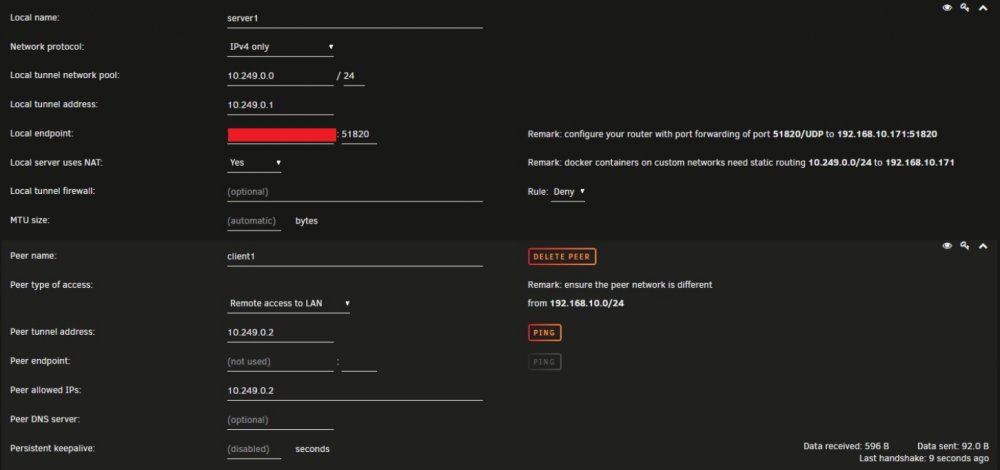
Yeah, my config includes allowed ips: [Interface] PrivateKey = REDACTED Address = 10.249.0.2/32 [Peer] PublicKey = REDACTED PresharedKey = REDACTED AllowedIPs = 10.249.0.1/32, 192.168.10.0/24 Endpoint = REDACTED:51820 NAT is on Yes as per screenshot What I'm trying to access is something. I tried the server ipmi, the web interface of the switch, pfsense interface on the router. Nothing pops up, just the unraid works and shows up Everything worked fine before...
-
Well it was already on Remote access to LAN I can connect but i can access only the unraid server and nothing on the lan